 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Model-based Reinforcement Learning with Large State Spaces
Sep 05, 2023Three major challenges in reinforcement learning are the complex dynamical systems with large state spaces, the costly data acquisition processes, and the deviation of real-world dynamics from the training environment deployment. To overcome these issues, we study distributionally robust Markov decision processes with continuous state spaces under the widely used Kullback-Leibler, chi-square, and total variation uncertainty sets. We propose a model-based approach that utilizes Gaussian Processes and the maximum variance reduction algorithm to efficiently learn multi-output nominal transition dynamics, leveraging access to a generative model (i.e., simulator). We further demonstrate the statistical sample complexity of the proposed method for different uncertainty sets. These complexity bounds are independent of the number of states and extend beyond linear dynamics, ensuring the effectiveness of our approach in identifying near-optimal distributionally-robust policies. The proposed method can be further combined with other model-free distributionally robust reinforcement learning methods to obtain a near-optimal robust policy. Experimental results demonstrate the robustness of our algorithm to distributional shifts and its superior performance in terms of the number of samples needed.
Multitask Learning with No Regret: from Improved Confidence Bounds to Active Learning
Aug 03, 2023



Multitask learning is a powerful framework that enables one to simultaneously learn multiple related tasks by sharing information between them. Quantifying uncertainty in the estimated tasks is of pivotal importance for many downstream applications, such as online or active learning. In this work, we provide novel multitask confidence intervals in the challenging agnostic setting, i.e., when neither the similarity between tasks nor the tasks' features are available to the learner. The obtained intervals do not require i.i.d. data and can be directly applied to bound the regret in online learning. Through a refined analysis of the multitask information gain, we obtain new regret guarantees that, depending on a task similarity parameter, can significantly improve over treating tasks independently. We further propose a novel online learning algorithm that achieves such improved regret without knowing this parameter in advance, i.e., automatically adapting to task similarity. As a second key application of our results, we introduce a novel multitask active learning setup where several tasks must be simultaneously optimized, but only one of them can be queried for feedback by the learner at each round. For this problem, we design a no-regret algorithm that uses our confidence intervals to decide which task should be queried. Finally, we empirically validate our bounds and algorithms on synthetic and real-world (drug discovery) data.
Model-based Causal Bayesian Optimization
Jul 31, 2023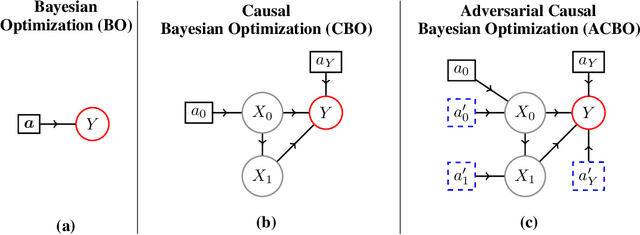
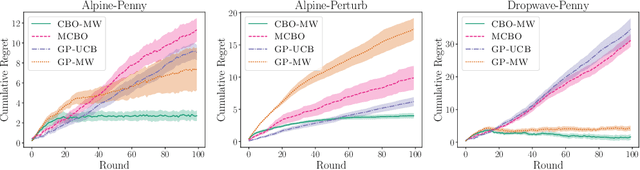
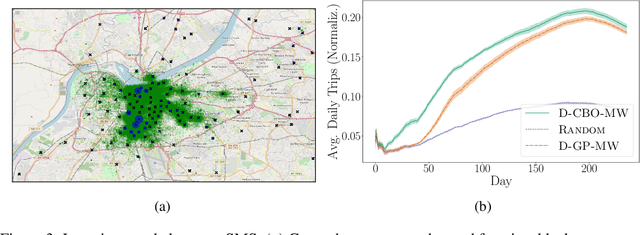
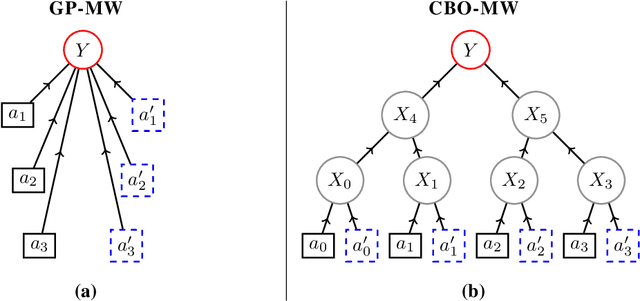
In Causal Bayesian Optimization (CBO), an agent intervenes on an unknown structural causal model to maximize a downstream reward variable. In this paper, we consider the generalization where other agents or external events also intervene on the system, which is key for enabling adaptiveness to non-stationarities such as weather changes, market forces, or adversaries. We formalize this generalization of CBO as Adversarial Causal Bayesian Optimization (ACBO) and introduce the first algorithm for ACBO with bounded regret: Causal Bayesian Optimization with Multiplicative Weights (CBO-MW). Our approach combines a classical online learning strategy with causal modeling of the rewards. To achieve this, it computes optimistic counterfactual reward estimates by propagating uncertainty through the causal graph. We derive regret bounds for CBO-MW that naturally depend on graph-related quantities. We further propose a scalable implementation for the case of combinatorial interventions and submodular rewards. Empirically, CBO-MW outperforms non-causal and non-adversarial Bayesian optimization methods on synthetic environments and environments based on real-word data. Our experiments include a realistic demonstration of how CBO-MW can be used to learn users' demand patterns in a shared mobility system and reposition vehicles in strategic areas.
Submodular Reinforcement Learning
Jul 25, 2023In reinforcement learning (RL), rewards of states are typically considered additive, and following the Markov assumption, they are $\textit{independent}$ of states visited previously. In many important applications, such as coverage control, experiment design and informative path planning, rewards naturally have diminishing returns, i.e., their value decreases in light of similar states visited previously. To tackle this, we propose $\textit{submodular RL}$ (SubRL), a paradigm which seeks to optimize more general, non-additive (and history-dependent) rewards modelled via submodular set functions which capture diminishing returns. Unfortunately, in general, even in tabular settings, we show that the resulting optimization problem is hard to approximate. On the other hand, motivated by the success of greedy algorithms in classical submodular optimization, we propose SubPO, a simple policy gradient-based algorithm for SubRL that handles non-additive rewards by greedily maximizing marginal gains. Indeed, under some assumptions on the underlying Markov Decision Process (MDP), SubPO recovers optimal constant factor approximations of submodular bandits. Moreover, we derive a natural policy gradient approach for locally optimizing SubRL instances even in large state- and action- spaces. We showcase the versatility of our approach by applying SubPO to several applications, such as biodiversity monitoring, Bayesian experiment design, informative path planning, and coverage maximization. Our results demonstrate sample efficiency, as well as scalability to high-dimensional state-action spaces.
Anytime Model Selection in Linear Bandits
Jul 24, 2023Model selection in the context of bandit optimization is a challenging problem, as it requires balancing exploration and exploitation not only for action selection, but also for model selection. One natural approach is to rely on online learning algorithms that treat different models as experts. Existing methods, however, scale poorly ($\text{poly}M$) with the number of models $M$ in terms of their regret. Our key insight is that, for model selection in linear bandits, we can emulate full-information feedback to the online learner with a favorable bias-variance trade-off. This allows us to develop ALEXP, which has an exponentially improved ($\log M$) dependence on $M$ for its regret. ALEXP has anytime guarantees on its regret, and neither requires knowledge of the horizon $n$, nor relies on an initial purely exploratory stage. Our approach utilizes a novel time-uniform analysis of the Lasso, establishing a new connection between online learning and high-dimensional statistics.
Safe Model-Based Multi-Agent Mean-Field Reinforcement Learning
Jun 29, 2023



Many applications, e.g., in shared mobility, require coordinating a large number of agents. Mean-field reinforcement learning addresses the resulting scalability challenge by optimizing the policy of a representative agent. In this paper, we address an important generalization where there exist global constraints on the distribution of agents (e.g., requiring capacity constraints or minimum coverage requirements to be met). We propose Safe-$\text{M}^3$-UCRL, the first model-based algorithm that attains safe policies even in the case of unknown transition dynamics. As a key ingredient, it uses epistemic uncertainty in the transition model within a log-barrier approach to ensure pessimistic constraints satisfaction with high probability. We showcase Safe-$\text{M}^3$-UCRL on the vehicle repositioning problem faced by many shared mobility operators and evaluate its performance through simulations built on Shenzhen taxi trajectory data. Our algorithm effectively meets the demand in critical areas while ensuring service accessibility in regions with low demand.
Safe Risk-averse Bayesian Optimization for Controller Tuning
Jun 23, 2023Controller tuning and parameter optimization are crucial in system design to improve both the controller and underlying system performance. Bayesian optimization has been established as an efficient model-free method for controller tuning and adaptation. Standard methods, however, are not enough for high-precision systems to be robust with respect to unknown input-dependent noise and stable under safety constraints. In this work, we present a novel data-driven approach, RaGoOSE, for safe controller tuning in the presence of heteroscedastic noise, combining safe learning with risk-averse Bayesian optimization. We demonstrate the method for synthetic benchmark and compare its performance to established BO-based tuning methods. We further evaluate RaGoOSE performance on a real precision-motion system utilized in semiconductor industry applications and compare it to the built-in auto-tuning routine.
Optimistic Active Exploration of Dynamical Systems
Jun 21, 2023



Reinforcement learning algorithms commonly seek to optimize policies for solving one particular task. How should we explore an unknown dynamical system such that the estimated model allows us to solve multiple downstream tasks in a zero-shot manner? In this paper, we address this challenge, by developing an algorithm -- OPAX -- for active exploration. OPAX uses well-calibrated probabilistic models to quantify the epistemic uncertainty about the unknown dynamics. It optimistically -- w.r.t. to plausible dynamics -- maximizes the information gain between the unknown dynamics and state observations. We show how the resulting optimization problem can be reduced to an optimal control problem that can be solved at each episode using standard approaches. We analyze our algorithm for general models, and, in the case of Gaussian process dynamics, we give a sample complexity bound and show that the epistemic uncertainty converges to zero. In our experiments, we compare OPAX with other heuristic active exploration approaches on several environments. Our experiments show that OPAX is not only theoretically sound but also performs well for zero-shot planning on novel downstream tasks.
Unbalanced Diffusion Schrödinger Bridge
Jun 15, 2023



Schr\"odinger bridges (SBs) provide an elegant framework for modeling the temporal evolution of populations in physical, chemical, or biological systems. Such natural processes are commonly subject to changes in population size over time due to the emergence of new species or birth and death events. However, existing neural parameterizations of SBs such as diffusion Schr\"odinger bridges (DSBs) are restricted to settings in which the endpoints of the stochastic process are both probability measures and assume conservation of mass constraints. To address this limitation, we introduce unbalanced DSBs which model the temporal evolution of marginals with arbitrary finite mass. This is achieved by deriving the time reversal of stochastic differential equations with killing and birth terms. We present two novel algorithmic schemes that comprise a scalable objective function for training unbalanced DSBs and provide a theoretical analysis alongside challenging applications on predicting heterogeneous molecular single-cell responses to various cancer drugs and simulating the emergence and spread of new viral variants.
Provably Learning Nash Policies in Constrained Markov Potential Games
Jun 13, 2023



Multi-agent reinforcement learning (MARL) addresses sequential decision-making problems with multiple agents, where each agent optimizes its own objective. In many real-world instances, the agents may not only want to optimize their objectives, but also ensure safe behavior. For example, in traffic routing, each car (agent) aims to reach its destination quickly (objective) while avoiding collisions (safety). Constrained Markov Games (CMGs) are a natural formalism for safe MARL problems, though generally intractable. In this work, we introduce and study Constrained Markov Potential Games (CMPGs), an important class of CMGs. We first show that a Nash policy for CMPGs can be found via constrained optimization. One tempting approach is to solve it by Lagrangian-based primal-dual methods. As we show, in contrast to the single-agent setting, however, CMPGs do not satisfy strong duality, rendering such approaches inapplicable and potentially unsafe. To solve the CMPG problem, we propose our algorithm Coordinate-Ascent for CMPGs (CA-CMPG), which provably converges to a Nash policy in tabular, finite-horizon CMPGs. Furthermore, we provide the first sample complexity bounds for learning Nash policies in unknown CMPGs, and, which under additional assumptions, guarantee safe exploration.