 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent imitation learning with function approximation: Linear Markov games and beyond
Feb 26, 2026In this work, we present the first theoretical analysis of multi-agent imitation learning (MAIL) in linear Markov games where both the transition dynamics and each agent's reward function are linear in some given features. We demonstrate that by leveraging this structure, it is possible to replace the state-action level "all policy deviation concentrability coefficient" (Freihaut et al., arXiv:2510.09325) with a concentrability coefficient defined at the feature level which can be much smaller than the state-action analog when the features are informative about states' similarity. Furthermore, to circumvent the need for any concentrability coefficient, we turn to the interactive setting. We provide the first, computationally efficient, interactive MAIL algorithm for linear Markov games and show that its sample complexity depends only on the dimension of the feature map $d$. Building on these theoretical findings, we propose a deep MAIL interactive algorithm which clearly outperforms BC on games such as Tic-Tac-Toe and Connect4.
MAVRL: Learning Reward Functions from Multiple Feedback Types with Amortized Variational Inference
Feb 16, 2026Reward learning typically relies on a single feedback type or combines multiple feedback types using manually weighted loss terms. Currently, it remains unclear how to jointly learn reward functions from heterogeneous feedback types such as demonstrations, comparisons, ratings, and stops that provide qualitatively different signals. We address this challenge by formulating reward learning from multiple feedback types as Bayesian inference over a shared latent reward function, where each feedback type contributes information through an explicit likelihood. We introduce a scalable amortized variational inference approach that learns a shared reward encoder and feedback-specific likelihood decoders and is trained by optimizing a single evidence lower bound. Our approach avoids reducing feedback to a common intermediate representation and eliminates the need for manual loss balancing. Across discrete and continuous-control benchmarks, we show that jointly inferred reward posteriors outperform single-type baselines, exploit complementary information across feedback types, and yield policies that are more robust to environment perturbations. The inferred reward uncertainty further provides interpretable signals for analyzing model confidence and consistency across feedback types.
Optimal Sample Complexity for Single Time-Scale Actor-Critic with Momentum
Feb 02, 2026We establish an optimal sample complexity of $O(ε^{-2})$ for obtaining an $ε$-optimal global policy using a single-timescale actor-critic (AC) algorithm in infinite-horizon discounted Markov decision processes (MDPs) with finite state-action spaces, improving upon the prior state of the art of $O(ε^{-3})$. Our approach applies STORM (STOchastic Recursive Momentum) to reduce variance in the critic updates. However, because samples are drawn from a nonstationary occupancy measure induced by the evolving policy, variance reduction via STORM alone is insufficient. To address this challenge, we maintain a buffer of small fraction of recent samples and uniformly sample from it for each critic update. Importantly, these mechanisms are compatible with existing deep learning architectures and require only minor modifications, without compromising practical applicability.
Fine-tuning Behavioral Cloning Policies with Preference-Based Reinforcement Learning
Sep 30, 2025Deploying reinforcement learning (RL) in robotics, industry, and health care is blocked by two obstacles: the difficulty of specifying accurate rewards and the risk of unsafe, data-hungry exploration. We address this by proposing a two-stage framework that first learns a safe initial policy from a reward-free dataset of expert demonstrations, then fine-tunes it online using preference-based human feedback. We provide the first principled analysis of this offline-to-online approach and introduce BRIDGE, a unified algorithm that integrates both signals via an uncertainty-weighted objective. We derive regret bounds that shrink with the number of offline demonstrations, explicitly connecting the quantity of offline data to online sample efficiency. We validate BRIDGE in discrete and continuous control MuJoCo environments, showing it achieves lower regret than both standalone behavioral cloning and online preference-based RL. Our work establishes a theoretical foundation for designing more sample-efficient interactive agents.
Learning Real-World Acrobatic Flight from Human Preferences
Aug 26, 2025



Preference-based reinforcement learning (PbRL) enables agents to learn control policies without requiring manually designed reward functions, making it well-suited for tasks where objectives are difficult to formalize or inherently subjective. Acrobatic flight poses a particularly challenging problem due to its complex dynamics, rapid movements, and the importance of precise execution. In this work, we explore the use of PbRL for agile drone control, focusing on the execution of dynamic maneuvers such as powerloops. Building on Preference-based Proximal Policy Optimization (Preference PPO), we propose Reward Ensemble under Confidence (REC), an extension to the reward learning objective that improves preference modeling and learning stability. Our method achieves 88.4% of the shaped reward performance, compared to 55.2% with standard Preference PPO. We train policies in simulation and successfully transfer them to real-world drones, demonstrating multiple acrobatic maneuvers where human preferences emphasize stylistic qualities of motion. Furthermore, we demonstrate the applicability of our probabilistic reward model in a representative MuJoCo environment for continuous control. Finally, we highlight the limitations of manually designed rewards, observing only 60.7% agreement with human preferences. These results underscore the effectiveness of PbRL in capturing complex, human-centered objectives across both physical and simulated domains.
Policy Gradient with Tree Search: Avoiding Local Optimas through Lookahead
Jun 08, 2025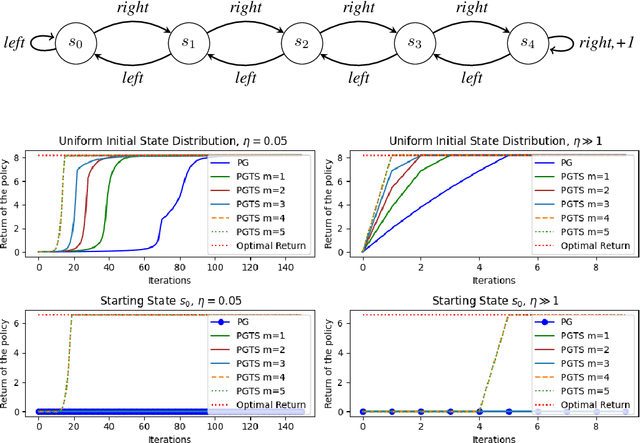
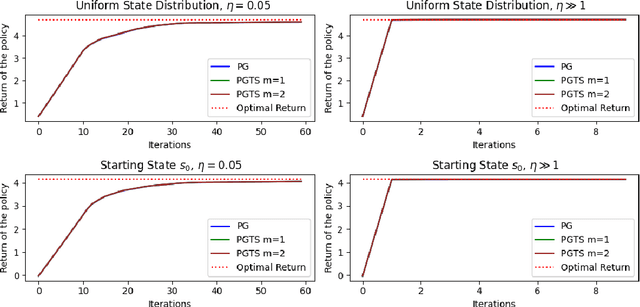

Classical policy gradient (PG) methods in reinforcement learning frequently converge to suboptimal local optima, a challenge exacerbated in large or complex environments. This work investigates Policy Gradient with Tree Search (PGTS), an approach that integrates an $m$-step lookahead mechanism to enhance policy optimization. We provide theoretical analysis demonstrating that increasing the tree search depth $m$-monotonically reduces the set of undesirable stationary points and, consequently, improves the worst-case performance of any resulting stationary policy. Critically, our analysis accommodates practical scenarios where policy updates are restricted to states visited by the current policy, rather than requiring updates across the entire state space. Empirical evaluations on diverse MDP structures, including Ladder, Tightrope, and Gridworld environments, illustrate PGTS's ability to exhibit "farsightedness," navigate challenging reward landscapes, escape local traps where standard PG fails, and achieve superior solutions.
Learning Equilibria from Data: Provably Efficient Multi-Agent Imitation Learning
May 23, 2025This paper provides the first expert sample complexity characterization for learning a Nash equilibrium from expert data in Markov Games. We show that a new quantity named the single policy deviation concentrability coefficient is unavoidable in the non-interactive imitation learning setting, and we provide an upper bound for behavioral cloning (BC) featuring such coefficient. BC exhibits substantial regret in games with high concentrability coefficient, leading us to utilize expert queries to develop and introduce two novel solution algorithms: MAIL-BRO and MURMAIL. The former employs a best response oracle and learns an $\varepsilon$-Nash equilibrium with $\mathcal{O}(\varepsilon^{-4})$ expert and oracle queries. The latter bypasses completely the best response oracle at the cost of a worse expert query complexity of order $\mathcal{O}(\varepsilon^{-8})$. Finally, we provide numerical evidence, confirming our theoretical findings.
Clustered KL-barycenter design for policy evaluation
Mar 04, 2025In the context of stochastic bandit models, this article examines how to design sample-efficient behavior policies for the importance sampling evaluation of multiple target policies. From importance sampling theory, it is well established that sample efficiency is highly sensitive to the KL divergence between the target and importance sampling distributions. We first analyze a single behavior policy defined as the KL-barycenter of the target policies. Then, we refine this approach by clustering the target policies into groups with small KL divergences and assigning each cluster its own KL-barycenter as a behavior policy. This clustered KL-based policy evaluation (CKL-PE) algorithm provides a novel perspective on optimal policy selection. We prove upper bounds on the sample complexity of our method and demonstrate its effectiveness with numerical validation.
Dual Formulation for Non-Rectangular Lp Robust Markov Decision Processes
Feb 13, 2025



We study robust Markov decision processes (RMDPs) with non-rectangular uncertainty sets, which capture interdependencies across states unlike traditional rectangular models. While non-rectangular robust policy evaluation is generally NP-hard, even in approximation, we identify a powerful class of $L_p$-bounded uncertainty sets that avoid these complexity barriers due to their structural simplicity. We further show that this class can be decomposed into infinitely many \texttt{sa}-rectangular $L_p$-bounded sets and leverage its structural properties to derive a novel dual formulation for $L_p$ RMDPs. This formulation provides key insights into the adversary's strategy and enables the development of the first robust policy evaluation algorithms for non-rectangular RMDPs. Empirical results demonstrate that our approach significantly outperforms brute-force methods, establishing a promising foundation for future investigation into non-rectangular robust MDPs.
On Multi-Agent Inverse Reinforcement Learning
Nov 22, 2024In multi-agent systems, the agent behavior is highly influenced by its utility function, as these utilities shape both individual goals as well as interactions with the other agents. Inverse Reinforcement Learning (IRL) is a well-established approach to inferring the utility function by observing an expert behavior within a given environment. In this paper, we extend the IRL framework to the multi-agent setting, assuming to observe agents who are following Nash Equilibrium (NE) policies. We theoretically investigate the set of utilities that explain the behavior of NE experts. Specifically, we provide an explicit characterization of the feasible reward set and analyze how errors in estimating the transition dynamics and expert behavior impact the recovered rewards. Building on these findings, we provide the first sample complexity analysis for the multi-agent IRL problem. Finally, we provide a numerical evaluation of our theoretical results.