 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Polar Encodings for Arbitrary-Oriented Ship Detection in SAR Images
Mar 24, 2021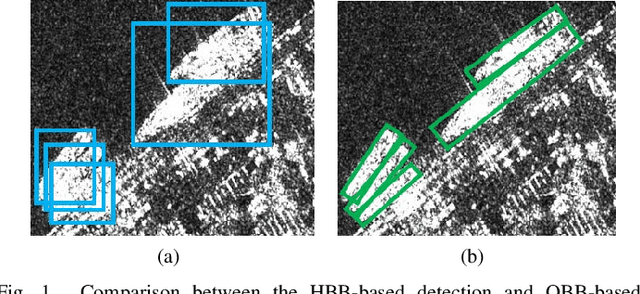

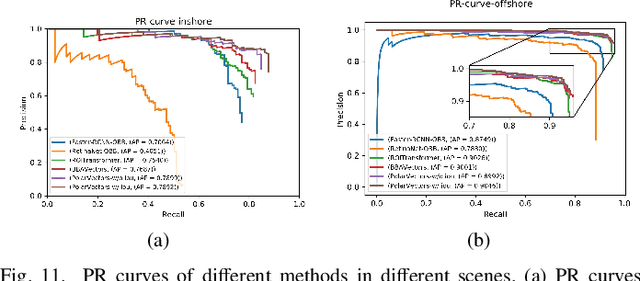

Common horizontal bounding box (HBB)-based methods are not capable of accurately locating slender ship targets with arbitrary orientations in synthetic aperture radar (SAR) images. Therefore, in recent years, methods based on oriented bounding box (OBB) have gradually received attention from researchers. However, most of the recently proposed deep learning-based methods for OBB detection encounter the boundary discontinuity problem in angle or key point regression. In order to alleviate this problem, researchers propose to introduce some manually set parameters or extra network branches for distinguishing the boundary cases, which make training more diffcult and lead to performance degradation. In this paper, in order to solve the boundary discontinuity problem in OBB regression, we propose to detect SAR ships by learning polar encodings. The encoding scheme uses a group of vectors pointing from the center of the ship target to the boundary points to represent an OBB. The boundary discontinuity problem is avoided by training and inference directly according to the polar encodings. In addition, we propose an Intersect over Union (IOU) -weighted regression loss, which further guides the training of polar encodings through the IOU metric and improves the detection performance. Experiments on the Rotating SAR Ship Detection Dataset (RSSDD) show that the proposed method can achieve better detection performance over other comparison algorithms and other OBB encoding schemes, demonstrating the effectiveness of our method.
A novel multimodal fusion network based on a joint coding model for lane line segmentation
Mar 20, 2021
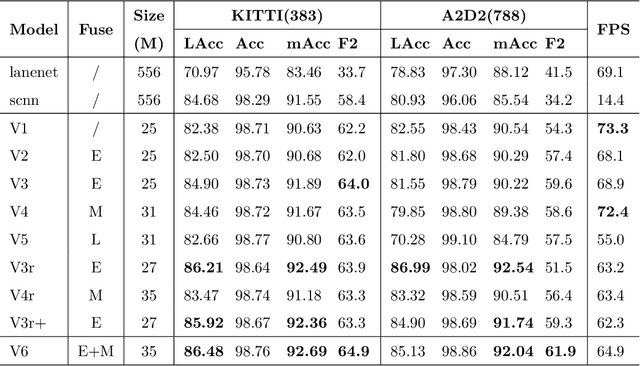
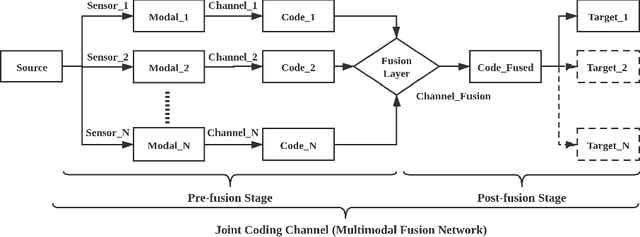
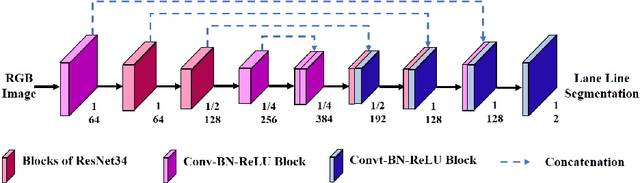
There has recently been growing interest in utilizing multimodal sensors to achieve robust lane line segmentation. In this paper, we introduce a novel multimodal fusion architecture from an information theory perspective, and demonstrate its practical utility using Light Detection and Ranging (LiDAR) camera fusion networks. In particular, we develop, for the first time, a multimodal fusion network as a joint coding model, where each single node, layer, and pipeline is represented as a channel. The forward propagation is thus equal to the information transmission in the channels. Then, we can qualitatively and quantitatively analyze the effect of different fusion approaches. We argue the optimal fusion architecture is related to the essential capacity and its allocation based on the source and channel. To test this multimodal fusion hypothesis, we progressively determine a series of multimodal models based on the proposed fusion methods and evaluate them on the KITTI and the A2D2 datasets. Our optimal fusion network achieves 85%+ lane line accuracy and 98.7%+ overall. The performance gap among the models will inform continuing future research into development of optimal fusion algorithms for the deep multimodal learning community.
Conceptual Text Region Network: Cognition-Inspired Accurate Scene Text Detection
Mar 16, 2021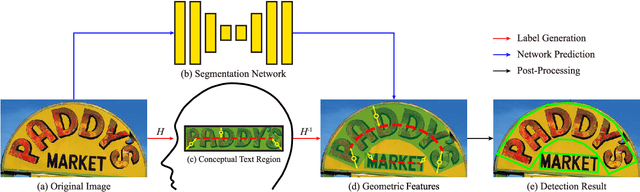
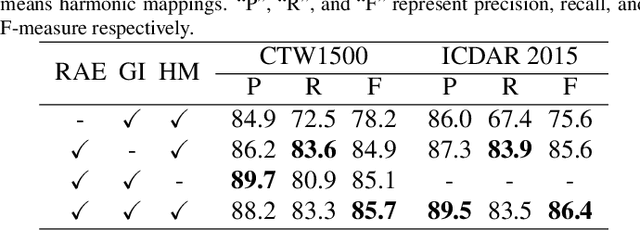
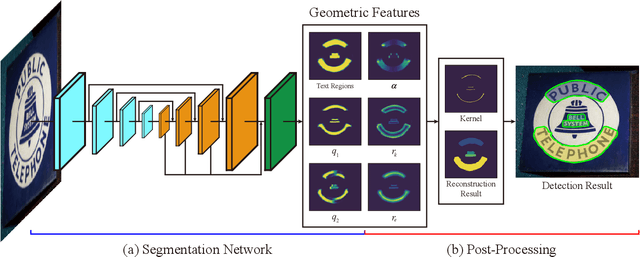
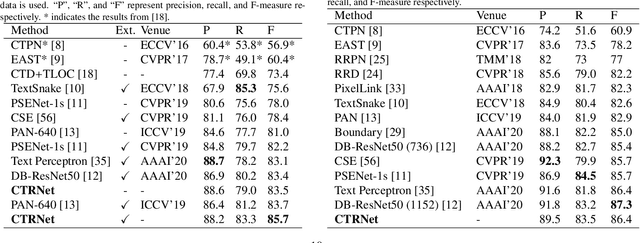
Segmentation-based methods are widely used for scene text detection due to their superiority in describing arbitrary-shaped text instances. However, two major problems still exist: 1) current label generation techniques are mostly empirical and lack theoretical support, discouraging elaborate label design; 2) as a result, most methods rely heavily on text kernel segmentation which is unstable and requires deliberate tuning. To address these challenges, we propose a human cognition-inspired framework, termed, Conceptual Text Region Network (CTRNet). The framework utilizes Conceptual Text Regions (CTRs), which is a class of cognition-based tools inheriting good mathematical properties, allowing for sophisticated label design. Another component of CTRNet is an inference pipeline that, with the help of CTRs, completely omits the need for text kernel segmentation. Compared with previous segmentation-based methods, our approach is not only more interpretable but also more accurate. Experimental results show that CTRNet achieves state-of-the-art performance on benchmark CTW1500, Total-Text, MSRA-TD500, and ICDAR 2015 datasets, yielding performance gains of up to 2.0%. Notably, to the best of our knowledge, CTRNet is among the first detection models to achieve F-measures higher than 85.0% on all four of the benchmarks, with remarkable consistency and stability.
A Novel Context-Aware Multimodal Framework for Persian Sentiment Analysis
Mar 03, 2021
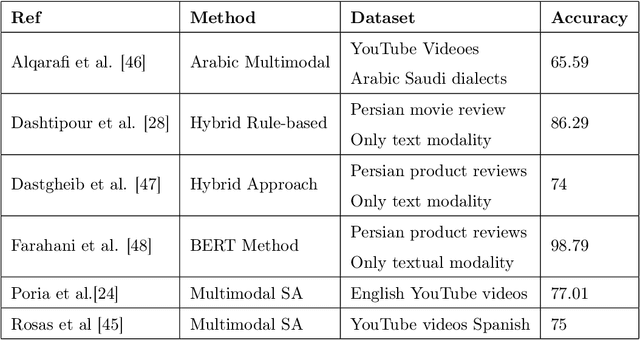
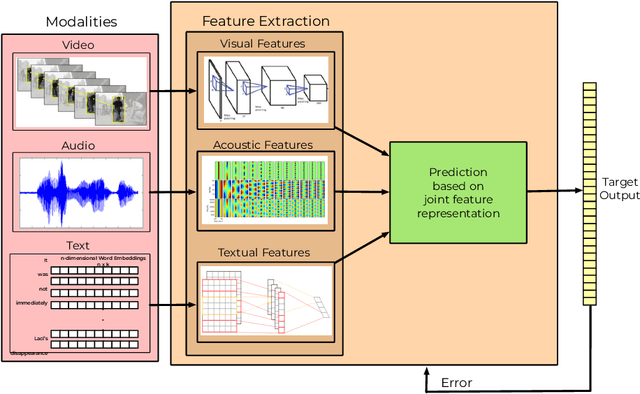
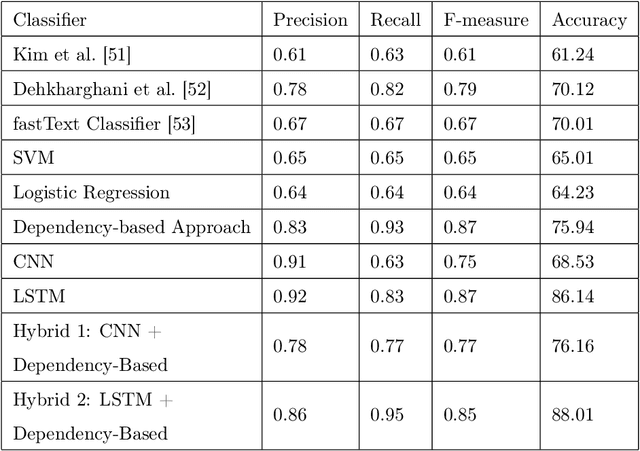
Most recent works on sentiment analysis have exploited the text modality. However, millions of hours of video recordings posted on social media platforms everyday hold vital unstructured information that can be exploited to more effectively gauge public perception. Multimodal sentiment analysis offers an innovative solution to computationally understand and harvest sentiments from videos by contextually exploiting audio, visual and textual cues. In this paper, we, firstly, present a first of its kind Persian multimodal dataset comprising more than 800 utterances, as a benchmark resource for researchers to evaluate multimodal sentiment analysis approaches in Persian language. Secondly, we present a novel context-aware multimodal sentiment analysis framework, that simultaneously exploits acoustic, visual and textual cues to more accurately determine the expressed sentiment. We employ both decision-level (late) and feature-level (early) fusion methods to integrate affective cross-modal information. Experimental results demonstrate that the contextual integration of multimodal features such as textual, acoustic and visual features deliver better performance (91.39%) compared to unimodal features (89.24%).
Persuasive Dialogue Understanding: the Baselines and Negative Results
Nov 22, 2020
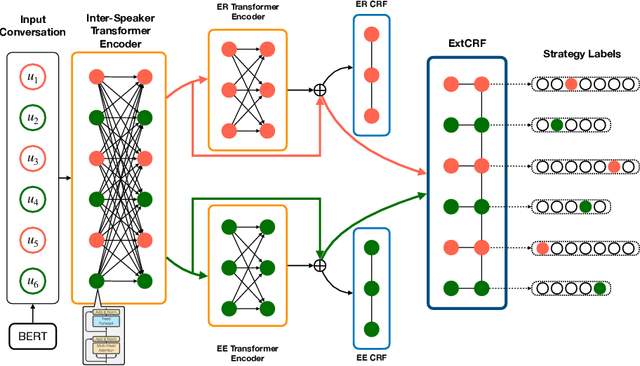
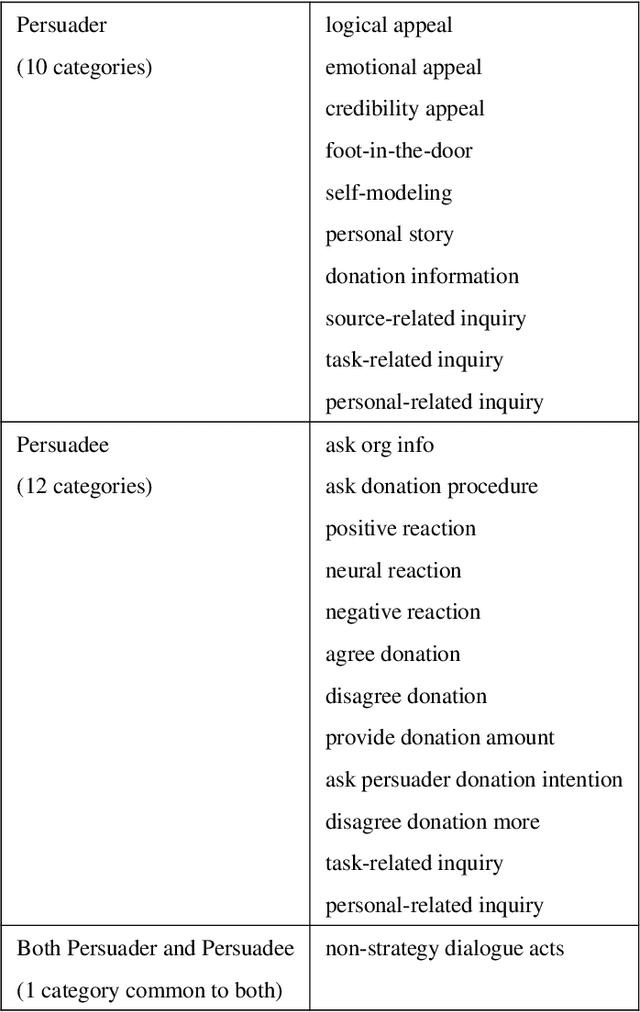
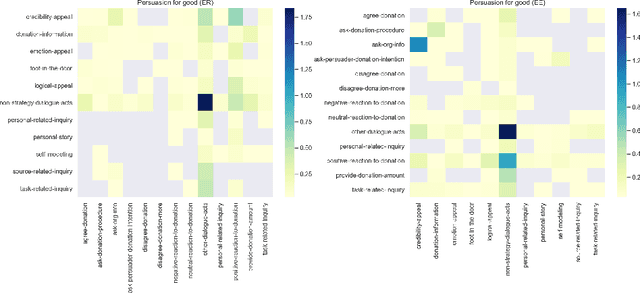
Persuasion aims at forming one's opinion and action via a series of persuasive messages containing persuader's strategies. Due to its potential application in persuasive dialogue systems, the task of persuasive strategy recognition has gained much attention lately. Previous methods on user intent recognition in dialogue systems adopt recurrent neural network (RNN) or convolutional neural network (CNN) to model context in conversational history, neglecting the tactic history and intra-speaker relation. In this paper, we demonstrate the limitations of a Transformer-based approach coupled with Conditional Random Field (CRF) for the task of persuasive strategy recognition. In this model, we leverage inter- and intra-speaker contextual semantic features, as well as label dependencies to improve the recognition. Despite extensive hyper-parameter optimizations, this architecture fails to outperform the baseline methods. We observe two negative results. Firstly, CRF cannot capture persuasive label dependencies, possibly as strategies in persuasive dialogues do not follow any strict grammar or rules as the cases in Named Entity Recognition (NER) or part-of-speech (POS) tagging. Secondly, the Transformer encoder trained from scratch is less capable of capturing sequential information in persuasive dialogues than Long Short-Term Memory (LSTM). We attribute this to the reason that the vanilla Transformer encoder does not efficiently consider relative position information of sequence elements.
Discriminative Dictionary Design for Action Classification in Still Images and Videos
Jun 06, 2020



In this paper, we address the problem of action recognition from still images and videos. Traditional local features such as SIFT, STIP etc. invariably pose two potential problems: 1) they are not evenly distributed in different entities of a given category and 2) many of such features are not exclusive of the visual concept the entities represent. In order to generate a dictionary taking the aforementioned issues into account, we propose a novel discriminative method for identifying robust and category specific local features which maximize the class separability to a greater extent. Specifically, we pose the selection of potent local descriptors as filtering based feature selection problem which ranks the local features per category based on a novel measure of distinctiveness. The underlying visual entities are subsequently represented based on the learned dictionary and this stage is followed by action classification using the random forest model followed by label propagation refinement. The framework is validated on the action recognition datasets based on still images (Stanford-40) as well as videos (UCF-50) and exhibits superior performances than the representative methods from the literature.
Improving Aspect-Level Sentiment Analysis with Aspect Extraction
May 03, 2020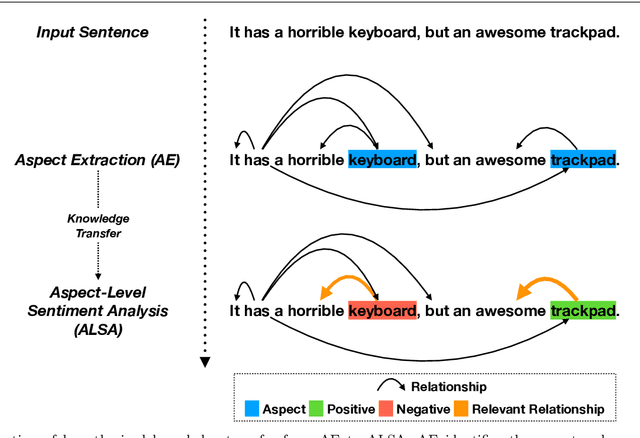
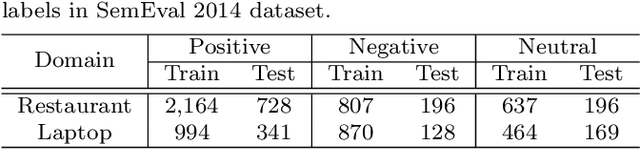
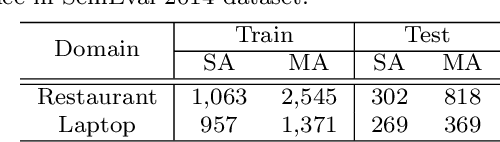
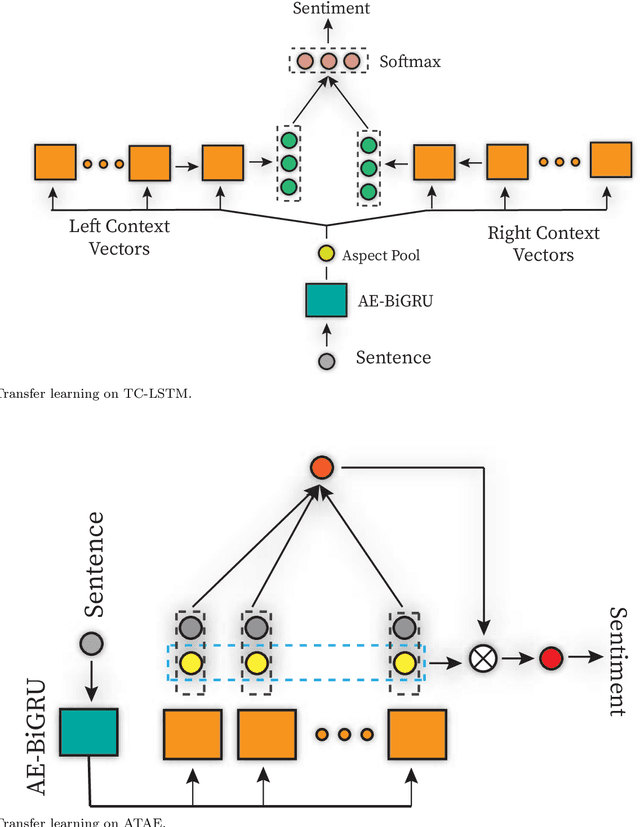
Aspect-based sentiment analysis (ABSA), a popular research area in NLP has two distinct parts -- aspect extraction (AE) and labeling the aspects with sentiment polarity (ALSA). Although distinct, these two tasks are highly correlated. The work primarily hypothesize that transferring knowledge from a pre-trained AE model can benefit the performance of ALSA models. Based on this hypothesis, word embeddings are obtained during AE and subsequently, feed that to the ALSA model. Empirically, this work show that the added information significantly improves the performance of three different baseline ALSA models on two distinct domains. This improvement also translates well across domains between AE and ALSA tasks.
Deep Learning in Mining Biological Data
Feb 28, 2020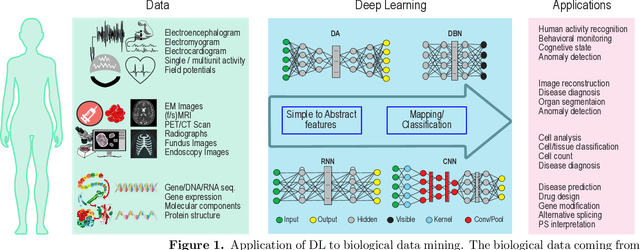
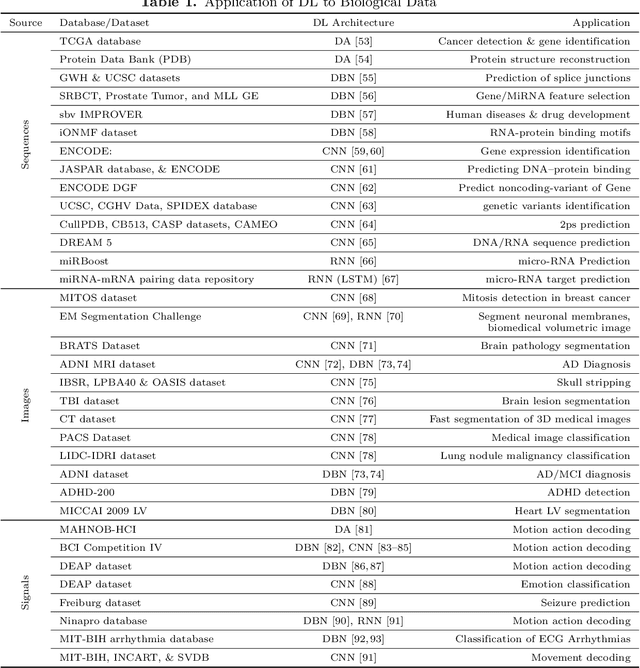
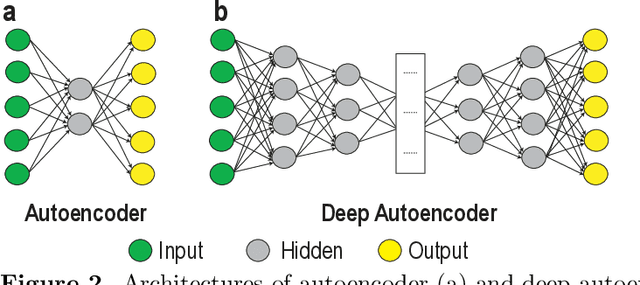
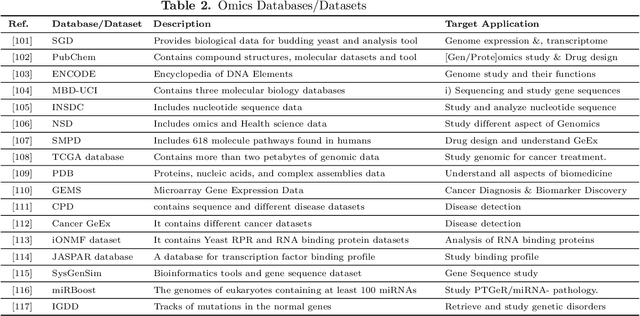
Recent technological advancements in data acquisition tools allowed life scientists to acquire multimodal data from different biological application domains. Broadly categorized in three types (i.e., sequences, images, and signals), these data are huge in amount and complex in nature. Mining such an enormous amount of data for pattern recognition is a big challenge and requires sophisticated data-intensive machine learning techniques. Artificial neural network-based learning systems are well known for their pattern recognition capabilities and lately their deep architectures - known as deep learning (DL) - have been successfully applied to solve many complex pattern recognition problems. Highlighting the role of DL in recognizing patterns in biological data, this article provides - applications of DL to biological sequences, images, and signals data; overview of open access sources of these data; description of open source DL tools applicable on these data; and comparison of these tools from qualitative and quantitative perspectives. At the end, it outlines some open research challenges in mining biological data and puts forward a number of possible future perspectives.
Comprehensive Taxonomies of Nature- and Bio-inspired Optimization: Inspiration versus Algorithmic Behavior, Critical Analysis and Recommendations
Feb 20, 2020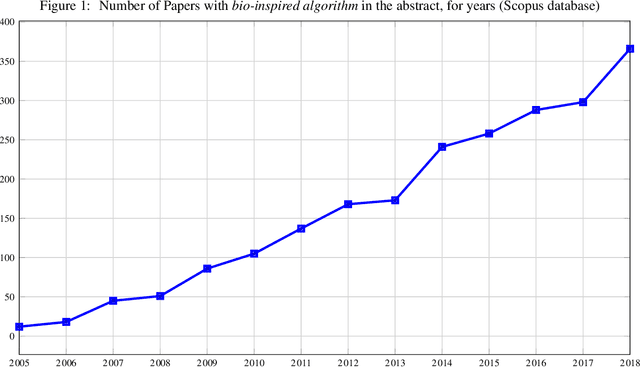
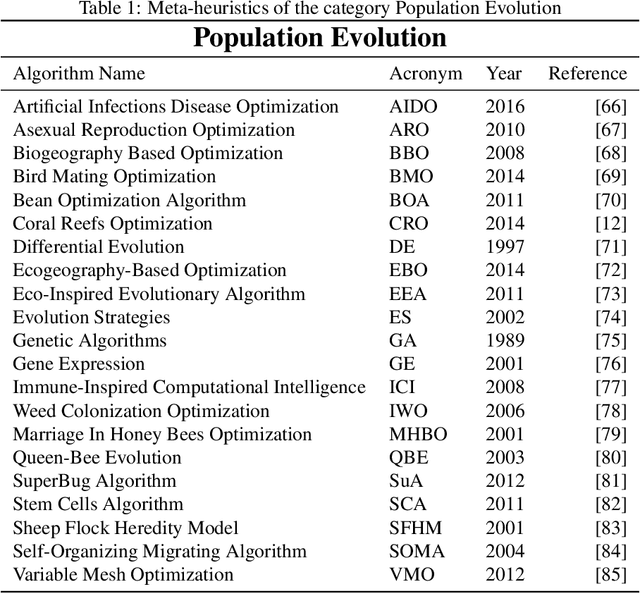
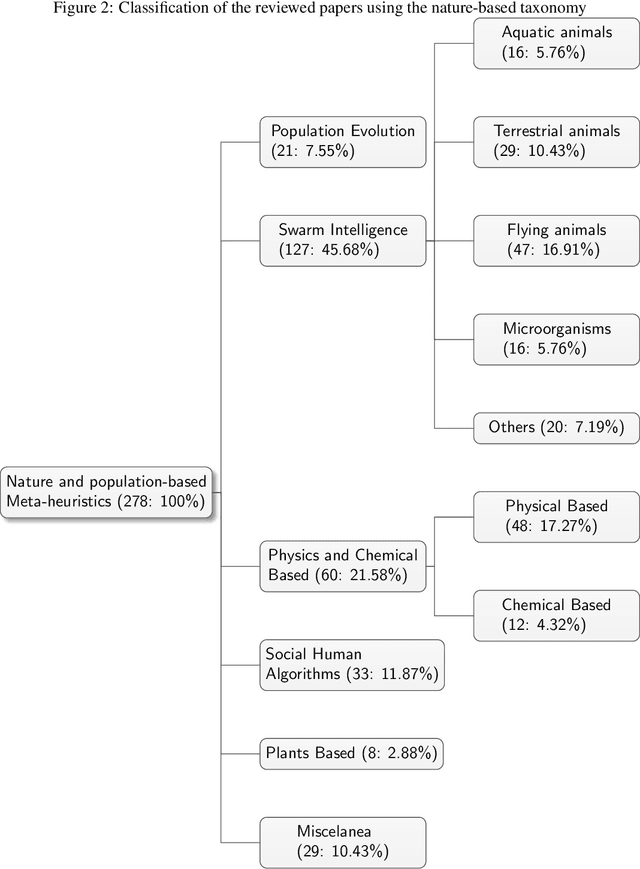
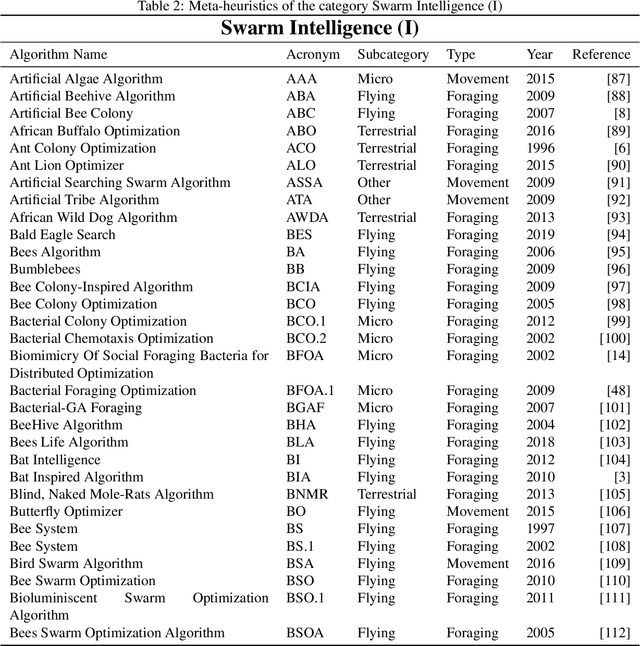
In recent years, a great variety of nature- and bio-inspired algorithms has been reported in the literature. This algorithmic family simulates different biological processes observed in Nature in order to efficiently address complex optimization problems. In the last years the number of bio-inspired optimization approaches in literature has grown considerably, reaching unprecedented levels that dark the future prospects of this field of research. This paper addresses this problem by proposing two comprehensive, principle-based taxonomies that allow researchers to organize existing and future algorithmic developments into well-defined categories, considering two different criteria: the source of inspiration and the behavior of each algorithm. Using these taxonomies we review more than three hundred publications dealing with nature-inspired and bio-inspired algorithms, and proposals falling within each of these categories are examined, leading to a critical summary of design trends and similarities between them, and the identification of the most similar classical algorithm for each reviewed paper. From our analysis we conclude that a poor relationship is often found between the natural inspiration of an algorithm and its behavior. Furthermore, similarities in terms of behavior between different algorithms are greater than what is claimed in their public disclosure: specifically, we show that more than one-third of the reviewed bio-inspired solvers are versions of classical algorithms. Grounded on the conclusions of our critical analysis, we give several recommendations and points of improvement for better methodological practices in this active and growing research field.
AV Speech Enhancement Challenge using a Real Noisy Corpus
Sep 30, 2019

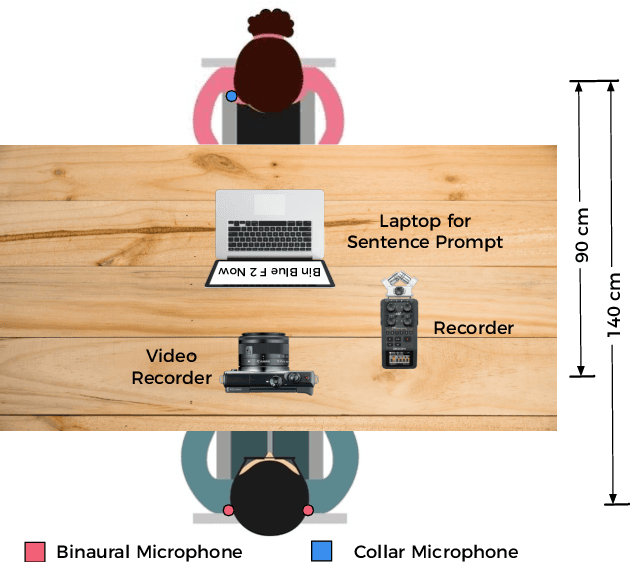
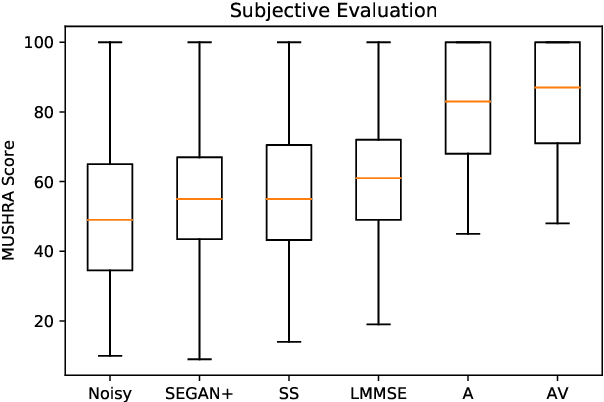
This paper presents, a first of its kind, audio-visual (AV) speech enhacement challenge in real-noisy settings. A detailed description of the AV challenge, a novel real noisy AV corpus (ASPIRE), benchmark speech enhancement task, and baseline performance results are outlined. The latter are based on training a deep neural architecture on a synthetic mixture of Grid corpus and ChiME3 noises (consisting of bus, pedestrian, cafe, and street noises) and testing on the ASPIRE corpus. Subjective evaluations of five different speech enhancement algorithms (including SEAGN, spectrum subtraction (SS) , log-minimum mean-square error (LMMSE), audio-only CochleaNet, and AV CochleaNet) are presented as baseline results. The aim of the multi-modal challenge is to provide a timely opportunity for comprehensive evaluation of novel AV speech enhancement algorithms, using our new benchmark, real-noisy AV corpus and specified performance metrics. This will promote AV speech processing research globally, stimulate new ground-breaking multi-modal approaches, and attract interest from companies, academics and researchers working in AV speech technologies and applications. We encourage participants (through a challenge website sign-up) from both the speech and hearing research communities, to benefit from their complementary approaches to AV speech in noise processing.