 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeCtrl-RL: Inference-Time Adaptive Behaviour Control for LLM Dialogue via RL-Driven Prompt Optimisation
May 25, 2026Ensuring safe and contextually appropriate behaviour in Large Language Models (LLMs) remains a critical challenge for real-world deployment. We present \textbf{SafeCtrl-RL}, an inference-time behavioural control framework that enables adaptive safety regulation without model retraining or parameter modification. The method formulates dialogue generation as a sequential decision process, where a reinforcement learning agent dynamically selects prompt adjustment strategies based on contextual feedback. This allows unsafe behaviours to be suppressed through iterative refinement, which we conceptualise as inference-time behavioural unlearning. Evaluated across multiple LLMs and unsafe dialogue scenarios, SafeCtrl-RL consistently improves safety and response quality, outperforms existing prompt-based optimisation methods, and achieves favourable performance--efficiency trade-offs. **Warning: This paper may contain examples of harmful language, and reader discretion is recommended.
Conceptual Text Region Network: Cognition-Inspired Accurate Scene Text Detection
Mar 16, 2021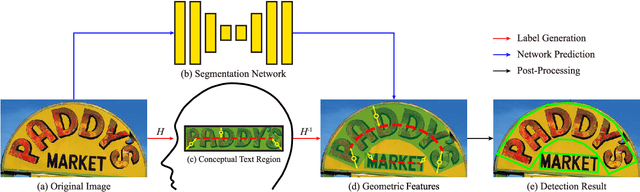
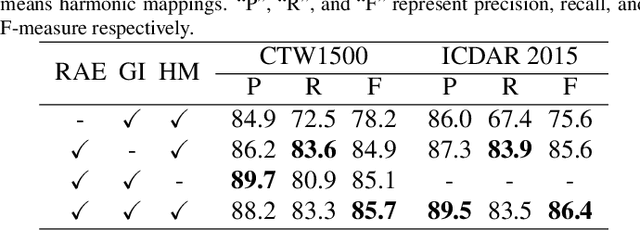
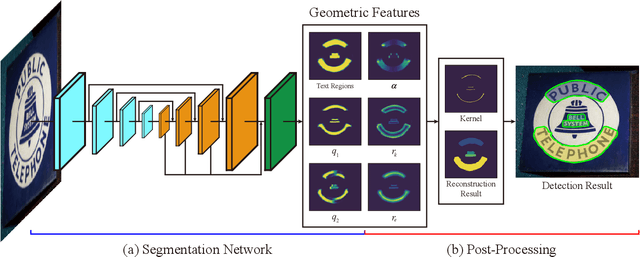
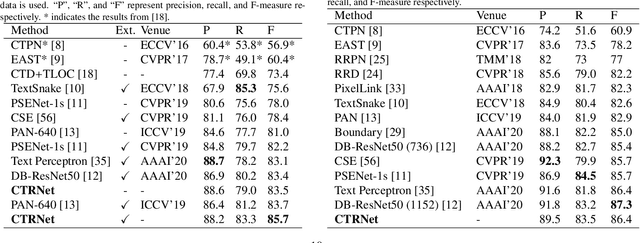
Segmentation-based methods are widely used for scene text detection due to their superiority in describing arbitrary-shaped text instances. However, two major problems still exist: 1) current label generation techniques are mostly empirical and lack theoretical support, discouraging elaborate label design; 2) as a result, most methods rely heavily on text kernel segmentation which is unstable and requires deliberate tuning. To address these challenges, we propose a human cognition-inspired framework, termed, Conceptual Text Region Network (CTRNet). The framework utilizes Conceptual Text Regions (CTRs), which is a class of cognition-based tools inheriting good mathematical properties, allowing for sophisticated label design. Another component of CTRNet is an inference pipeline that, with the help of CTRs, completely omits the need for text kernel segmentation. Compared with previous segmentation-based methods, our approach is not only more interpretable but also more accurate. Experimental results show that CTRNet achieves state-of-the-art performance on benchmark CTW1500, Total-Text, MSRA-TD500, and ICDAR 2015 datasets, yielding performance gains of up to 2.0%. Notably, to the best of our knowledge, CTRNet is among the first detection models to achieve F-measures higher than 85.0% on all four of the benchmarks, with remarkable consistency and stability.