 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speech Enhancement Using Self-supervised Learning to Improve Speech Intelligibility in Cochlear Implant Simulations
Jul 15, 2023



Individuals with hearing impairments face challenges in their ability to comprehend speech, particularly in noisy environments. The aim of this study is to explore the effectiveness of audio-visual speech enhancement (AVSE) in enhancing the intelligibility of vocoded speech in cochlear implant (CI) simulations. Notably, the study focuses on a challenged scenario where there is limited availability of training data for the AVSE task. To address this problem, we propose a novel deep neural network framework termed Self-Supervised Learning-based AVSE (SSL-AVSE). The proposed SSL-AVSE combines visual cues, such as lip and mouth movements, from the target speakers with corresponding audio signals. The contextually combined audio and visual data are then fed into a Transformer-based SSL AV-HuBERT model to extract features, which are further processed using a BLSTM-based SE model. The results demonstrate several key findings. Firstly, SSL-AVSE successfully overcomes the issue of limited data by leveraging the AV-HuBERT model. Secondly, by fine-tuning the AV-HuBERT model parameters for the target SE task, significant performance improvements are achieved. Specifically, there is a notable enhancement in PESQ (Perceptual Evaluation of Speech Quality) from 1.43 to 1.67 and in STOI (Short-Time Objective Intelligibility) from 0.70 to 0.74. Furthermore, the performance of the SSL-AVSE was evaluated using CI vocoded speech to assess the intelligibility for CI users. Comparative experimental outcomes reveal that in the presence of dynamic noises encountered during human conversations, SSL-AVSE exhibits a substantial improvement. The NCM (Normal Correlation Matrix) values indicate an increase of 26.5% to 87.2% compared to the noisy baseline.
Filter Bubbles in Recommender Systems: Fact or Fallacy -- A Systematic Review
Jul 02, 2023A filter bubble refers to the phenomenon where Internet customization effectively isolates individuals from diverse opinions or materials, resulting in their exposure to only a select set of content. This can lead to the reinforcement of existing attitudes, beliefs, or conditions. In this study, our primary focus is to investigate the impact of filter bubbles in recommender systems. This pioneering research aims to uncover the reasons behind this problem, explore potential solutions, and propose an integrated tool to help users avoid filter bubbles in recommender systems. To achieve this objective, we conduct a systematic literature review on the topic of filter bubbles in recommender systems. The reviewed articles are carefully analyzed and classified, providing valuable insights that inform the development of an integrated approach. Notably, our review reveals evidence of filter bubbles in recommendation systems, highlighting several biases that contribute to their existence. Moreover, we propose mechanisms to mitigate the impact of filter bubbles and demonstrate that incorporating diversity into recommendations can potentially help alleviate this issue. The findings of this timely review will serve as a benchmark for researchers working in interdisciplinary fields such as privacy, artificial intelligence ethics, and recommendation systems. Furthermore, it will open new avenues for future research in related domains, prompting further exploration and advancement in this critical area.
Towards Deeper and Better Multi-view Feature Fusion for 3D Semantic Segmentation
Dec 13, 20223D point clouds are rich in geometric structure information, while 2D images contain important and continuous texture information. Combining 2D information to achieve better 3D semantic segmentation has become mainstream in 3D scene understanding. Albeit the success, it still remains elusive how to fuse and process the cross-dimensional features from these two distinct spaces. Existing state-of-the-art usually exploit bidirectional projection methods to align the cross-dimensional features and realize both 2D & 3D semantic segmentation tasks. However, to enable bidirectional mapping, this framework often requires a symmetrical 2D-3D network structure, thus limiting the network's flexibility. Meanwhile, such dual-task settings may distract the network easily and lead to over-fitting in the 3D segmentation task. As limited by the network's inflexibility, fused features can only pass through a decoder network, which affects model performance due to insufficient depth. To alleviate these drawbacks, in this paper, we argue that despite its simplicity, projecting unidirectionally multi-view 2D deep semantic features into the 3D space aligned with 3D deep semantic features could lead to better feature fusion. On the one hand, the unidirectional projection enforces our model focused more on the core task, i.e., 3D segmentation; on the other hand, unlocking the bidirectional to unidirectional projection enables a deeper cross-domain semantic alignment and enjoys the flexibility to fuse better and complicated features from very different spaces. In joint 2D-3D approaches, our proposed method achieves superior performance on the ScanNetv2 benchmark for 3D semantic segmentation.
Audio-Visual Speech Enhancement and Separation by Leveraging Multi-Modal Self-Supervised Embeddings
Oct 31, 2022



AV-HuBERT, a multi-modal self-supervised learning model, has been shown to be effective for categorical problems such as automatic speech recognition and lip-reading. This suggests that useful audio-visual speech representations can be obtained via utilizing multi-modal self-supervised embeddings. Nevertheless, it is unclear if such representations can be generalized to solve real-world multi-modal AV regression tasks, such as audio-visual speech enhancement (AVSE) and audio-visual speech separation (AVSS). In this study, we leveraged the pre-trained AV-HuBERT model followed by an SE module for AVSE and AVSS. Comparative experimental results demonstrate that our proposed model performs better than the state-of-the-art AVSE and traditional audio-only SE models. In summary, our results confirm the effectiveness of our proposed model for the AVSS task with proper fine-tuning strategies, demonstrating that multi-modal self-supervised embeddings obtained from AV-HUBERT can be generalized to audio-visual regression tasks.
Unlocking the potential of two-point cells for energy-efficient training of deep nets
Oct 24, 2022Context-sensitive two-point layer 5 pyramidal cells (L5PC) were discovered as long ago as 1999. However, the potential of this discovery to provide useful neural computation has yet to be demonstrated. Here we show for the first time how a transformative L5PC-driven deep neural network (DNN), termed the multisensory cooperative computing (MCC) architecture, can effectively process large amounts of heterogeneous real-world audio-visual (AV) data, using far less energy compared to best available `point' neuron-driven DNNs. A novel highly-distributed parallel implementation on a Xilinx UltraScale+ MPSoC device estimates energy savings up to $245759 \times 50000$ $\mu$J (i.e., $62\%$ less than the baseline model in a semi-supervised learning setup) where a single synapse consumes $8e^{-5}\mu$J. In a supervised learning setup, the energy-saving can potentially reach up to 1250x less (per feedforward transmission) than the baseline model. This remarkable performance in pilot experiments demonstrates the embodied neuromorphic intelligence of our proposed L5PC based MCC architecture that contextually selects the most salient and relevant information for onward transmission, from overwhelmingly large multimodal information utilised at the early stages of on-chip training. Our proposed approach opens new cross-disciplinary avenues for future on-chip DNN training implementations and posits a radical shift in current neuromorphic computing paradigms.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022



In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
WikiDes: A Wikipedia-Based Dataset for Generating Short Descriptions from Paragraphs
Sep 27, 2022
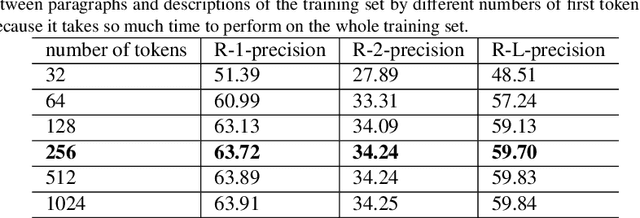

As free online encyclopedias with massive volumes of content, Wikipedia and Wikidata are key to many Natural Language Processing (NLP) tasks, such as information retrieval, knowledge base building, machine translation, text classification, and text summarization. In this paper, we introduce WikiDes, a novel dataset to generate short descriptions of Wikipedia articles for the problem of text summarization. The dataset consists of over 80k English samples on 6987 topics. We set up a two-phase summarization method - description generation (Phase I) and candidate ranking (Phase II) - as a strong approach that relies on transfer and contrastive learning. For description generation, T5 and BART show their superiority compared to other small-scale pre-trained models. By applying contrastive learning with the diverse input from beam search, the metric fusion-based ranking models outperform the direct description generation models significantly up to 22 ROUGE in topic-exclusive split and topic-independent split. Furthermore, the outcome descriptions in Phase II are supported by human evaluation in over 45.33% chosen compared to 23.66% in Phase I against the gold descriptions. In the aspect of sentiment analysis, the generated descriptions cannot effectively capture all sentiment polarities from paragraphs while doing this task better from the gold descriptions. The automatic generation of new descriptions reduces the human efforts in creating them and enriches Wikidata-based knowledge graphs. Our paper shows a practical impact on Wikipedia and Wikidata since there are thousands of missing descriptions. Finally, we expect WikiDes to be a useful dataset for related works in capturing salient information from short paragraphs. The curated dataset is publicly available at: https://github.com/declare-lab/WikiDes.
Towards Simple and Accurate Human Pose Estimation with Stair Network
Feb 18, 2022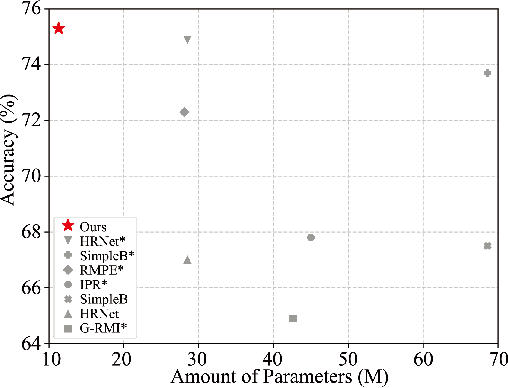
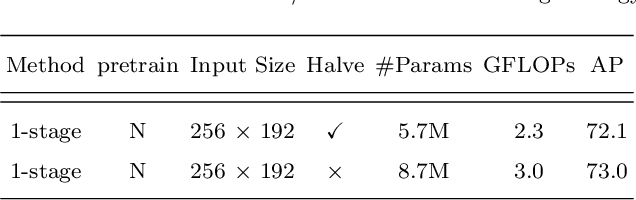
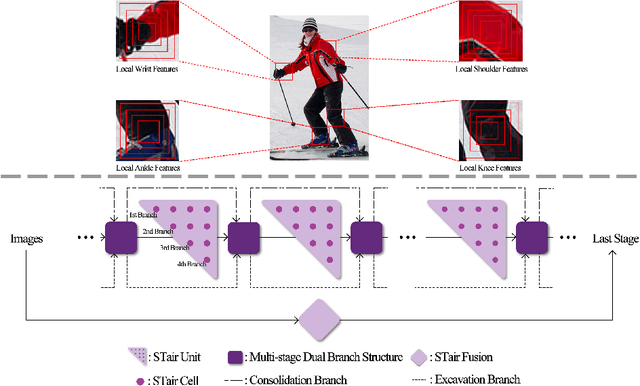
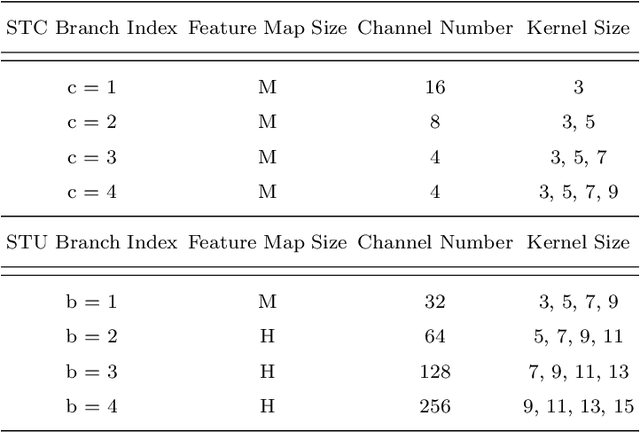
In this paper, we focus on tackling the precise keypoint coordinates regression task. Most existing approaches adopt complicated networks with a large number of parameters, leading to a heavy model with poor cost-effectiveness in practice. To overcome this limitation, we develop a small yet discrimicative model called STair Network, which can be simply stacked towards an accurate multi-stage pose estimation system. Specifically, to reduce computational cost, STair Network is composed of novel basic feature extraction blocks which focus on promoting feature diversity and obtaining rich local representations with fewer parameters, enabling a satisfactory balance on efficiency and performance. To further improve the performance, we introduce two mechanisms with negligible computational cost, focusing on feature fusion and replenish. We demonstrate the effectiveness of the STair Network on two standard datasets, e.g., 1-stage STair Network achieves a higher accuracy than HRNet by 5.5% on COCO test dataset with 80\% fewer parameters and 68% fewer GFLOPs.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022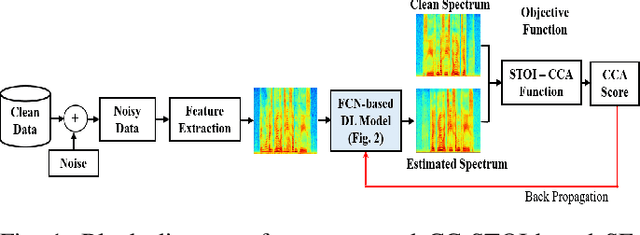
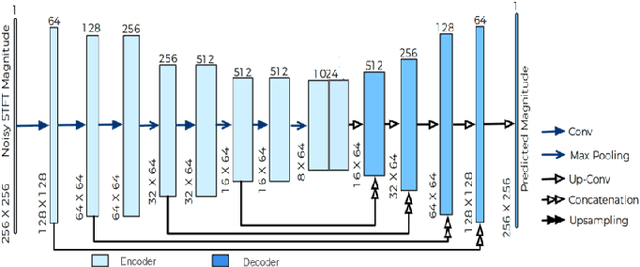
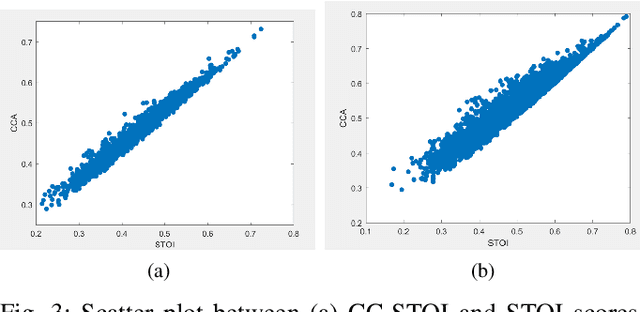
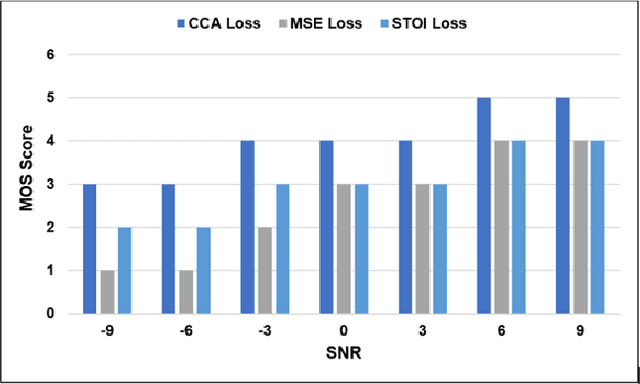
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022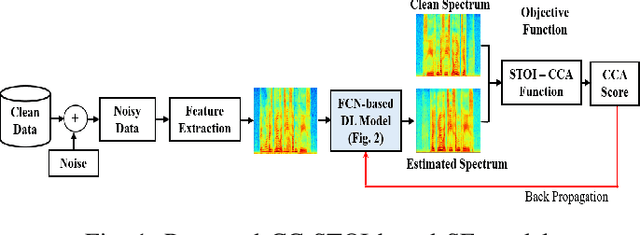
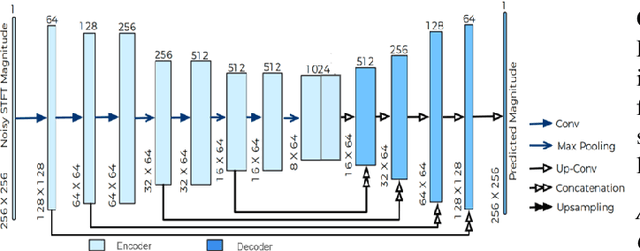
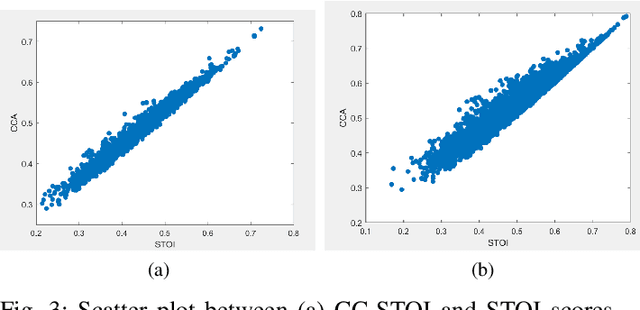
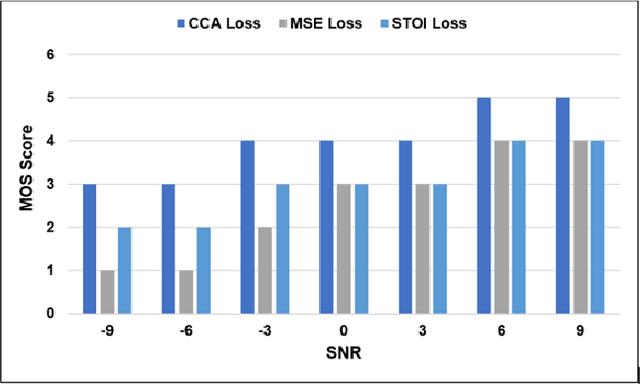
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.