 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Context Vision Transformers
Jun 20, 2022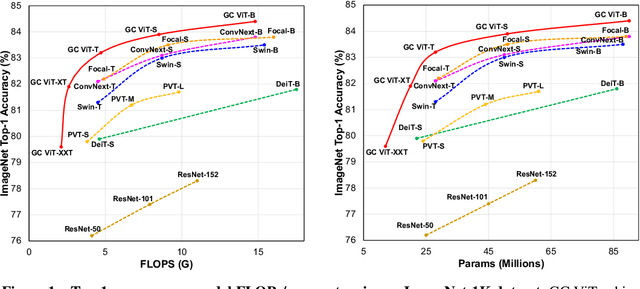
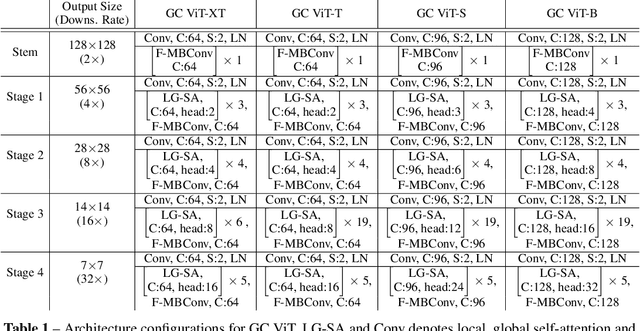
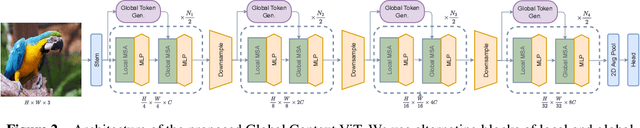
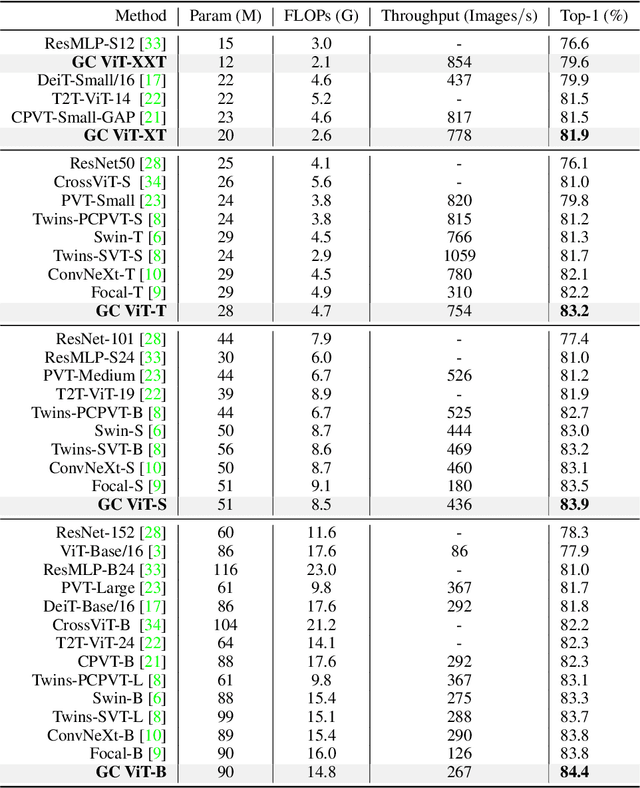
We propose global context vision transformer (GC ViT), a novel architecture that enhances parameter and compute utilization. Our method leverages global context self-attention modules, joint with local self-attention, to effectively yet efficiently model both long and short-range spatial interactions, without the need for expensive operations such as computing attention masks or shifting local windows. In addition, we address the issue of lack of the inductive bias in ViTs via proposing to use a modified fused inverted residual blocks in our architecture. Our proposed GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, the base, small and tiny variants of GC ViT with $28$M, $51$M and $90$M parameters achieve $\textbf{83.2\%}$, $\textbf{83.9\%}$ and $\textbf{84.4\%}$ Top-1 accuracy, respectively, surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer by a large margin. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation, and semantic segmentation using MS COCO and ADE20K datasets outperform prior work consistently, sometimes by large margins. Code available at https://github.com/NVlabs/GCViT.
UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation
Apr 05, 2022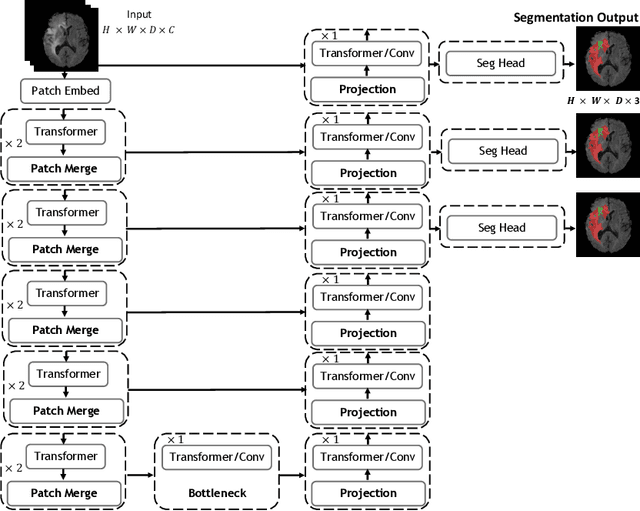
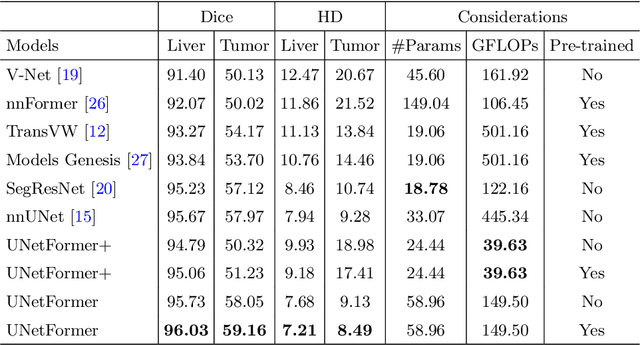
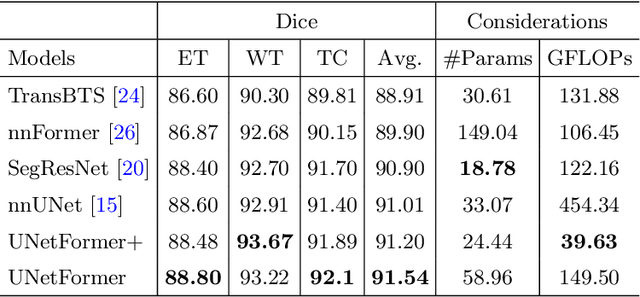
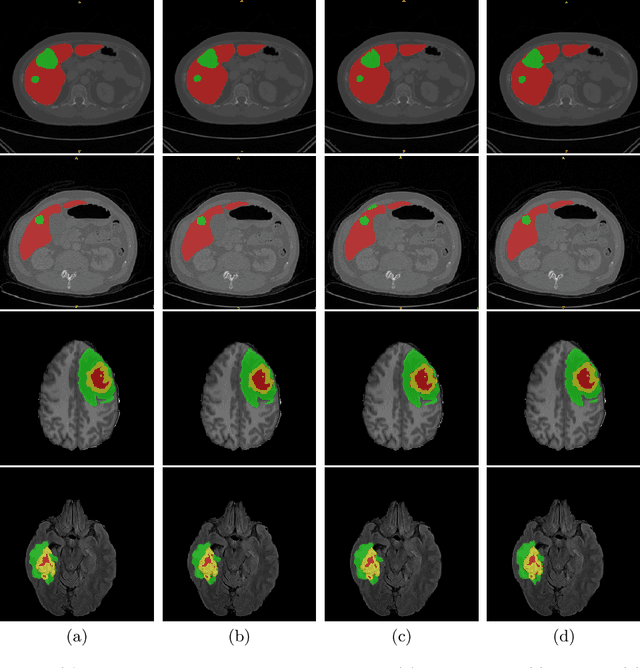
Vision Transformers (ViT)s have recently become popular due to their outstanding modeling capabilities, in particular for capturing long-range information, and scalability to dataset and model sizes which has led to state-of-the-art performance in various computer vision and medical image analysis tasks. In this work, we introduce a unified framework consisting of two architectures, dubbed UNetFormer, with a 3D Swin Transformer-based encoder and Convolutional Neural Network (CNN) and transformer-based decoders. In the proposed model, the encoder is linked to the decoder via skip connections at five different resolutions with deep supervision. The design of proposed architecture allows for meeting a wide range of trade-off requirements between accuracy and computational cost. In addition, we present a methodology for self-supervised pre-training of the encoder backbone via learning to predict randomly masked volumetric tokens using contextual information of visible tokens. We pre-train our framework on a cohort of $5050$ CT images, gathered from publicly available CT datasets, and present a systematic investigation of various components such as masking ratio and patch size that affect the representation learning capability and performance of downstream tasks. We validate the effectiveness of our pre-training approach by fine-tuning and testing our model on liver and liver tumor segmentation task using the Medical Segmentation Decathlon (MSD) dataset and achieve state-of-the-art performance in terms of various segmentation metrics. To demonstrate its generalizability, we train and test the model on BraTS 21 dataset for brain tumor segmentation using MRI images and outperform other methods in terms of Dice score. Code: https://github.com/Project-MONAI/research-contributions
RAVIR: A Dataset and Methodology for the Semantic Segmentation and Quantitative Analysis of Retinal Arteries and Veins in Infrared Reflectance Imaging
Mar 28, 2022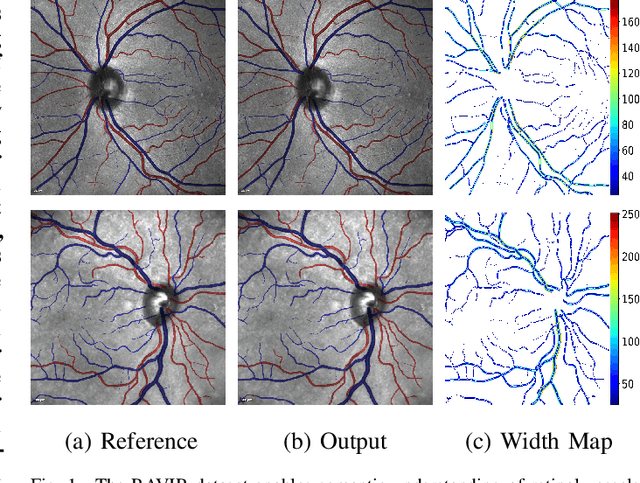
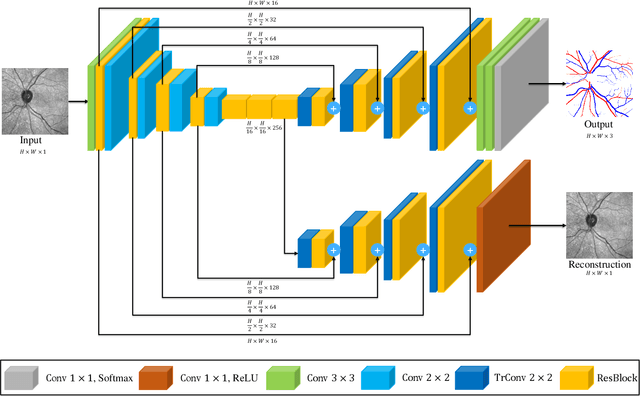
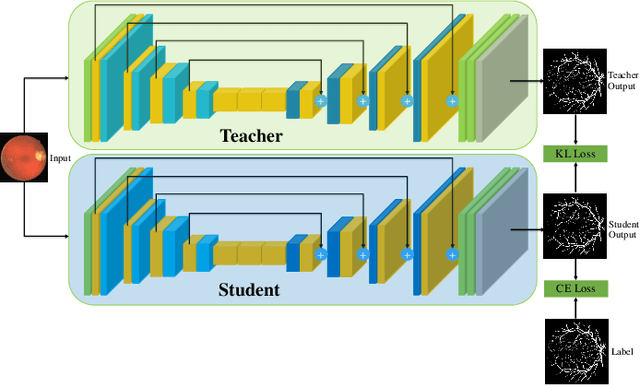
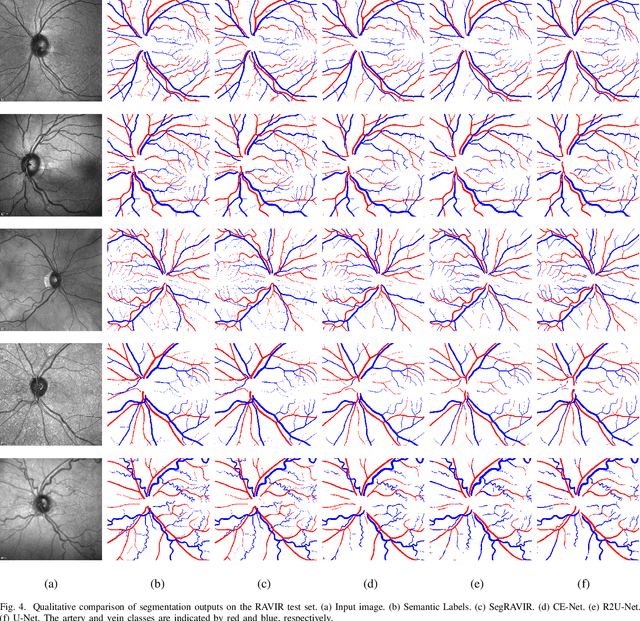
The retinal vasculature provides important clues in the diagnosis and monitoring of systemic diseases including hypertension and diabetes. The microvascular system is of primary involvement in such conditions, and the retina is the only anatomical site where the microvasculature can be directly observed. The objective assessment of retinal vessels has long been considered a surrogate biomarker for systemic vascular diseases, and with recent advancements in retinal imaging and computer vision technologies, this topic has become the subject of renewed attention. In this paper, we present a novel dataset, dubbed RAVIR, for the semantic segmentation of Retinal Arteries and Veins in Infrared Reflectance (IR) imaging. It enables the creation of deep learning-based models that distinguish extracted vessel type without extensive post-processing. We propose a novel deep learning-based methodology, denoted as SegRAVIR, for the semantic segmentation of retinal arteries and veins and the quantitative measurement of the widths of segmented vessels. Our extensive experiments validate the effectiveness of SegRAVIR and demonstrate its superior performance in comparison to state-of-the-art models. Additionally, we propose a knowledge distillation framework for the domain adaptation of RAVIR pretrained networks on color images. We demonstrate that our pretraining procedure yields new state-of-the-art benchmarks on the DRIVE, STARE, and CHASE_DB1 datasets. Dataset link: https://ravirdataset.github.io/data/
GradViT: Gradient Inversion of Vision Transformers
Mar 28, 2022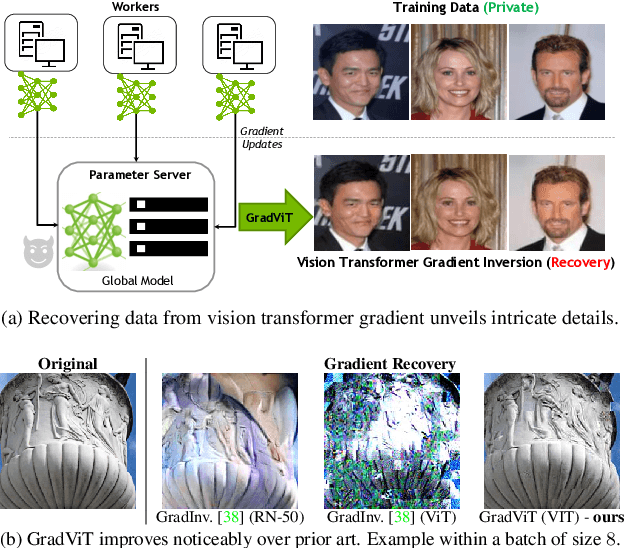
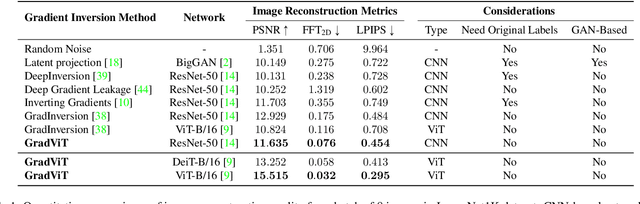
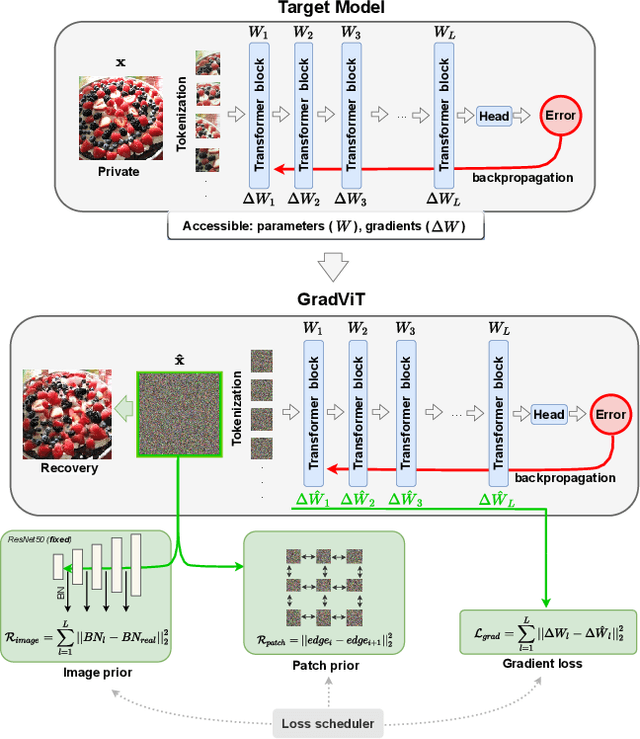
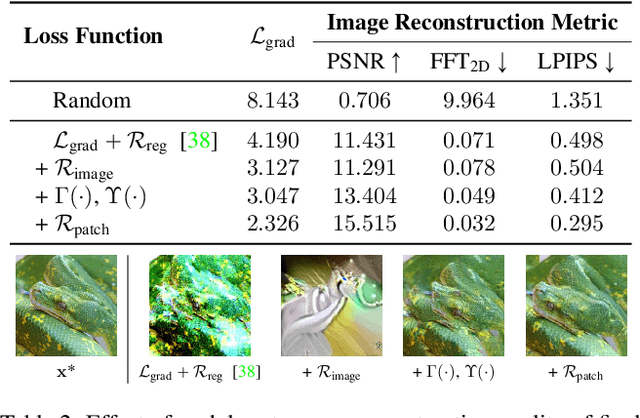
In this work we demonstrate the vulnerability of vision transformers (ViTs) to gradient-based inversion attacks. During this attack, the original data batch is reconstructed given model weights and the corresponding gradients. We introduce a method, named GradViT, that optimizes random noise into naturally looking images via an iterative process. The optimization objective consists of (i) a loss on matching the gradients, (ii) image prior in the form of distance to batch-normalization statistics of a pretrained CNN model, and (iii) a total variation regularization on patches to guide correct recovery locations. We propose a unique loss scheduling function to overcome local minima during optimization. We evaluate GadViT on ImageNet1K and MS-Celeb-1M datasets, and observe unprecedentedly high fidelity and closeness to the original (hidden) data. During the analysis we find that vision transformers are significantly more vulnerable than previously studied CNNs due to the presence of the attention mechanism. Our method demonstrates new state-of-the-art results for gradient inversion in both qualitative and quantitative metrics. Project page at https://gradvit.github.io/.
Closing the Generalization Gap of Cross-silo Federated Medical Image Segmentation
Mar 18, 2022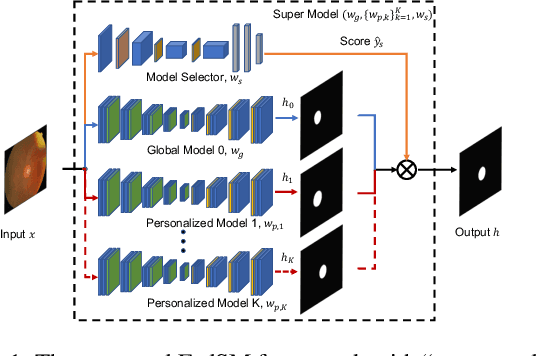
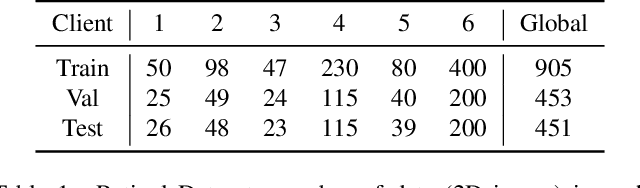
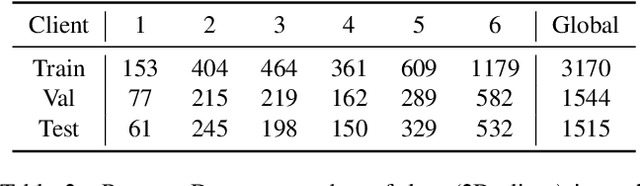
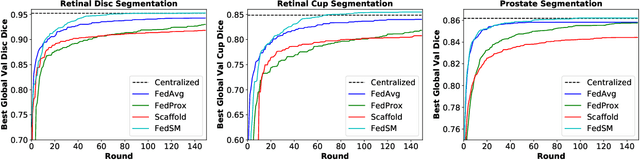
Cross-silo federated learning (FL) has attracted much attention in medical imaging analysis with deep learning in recent years as it can resolve the critical issues of insufficient data, data privacy, and training efficiency. However, there can be a generalization gap between the model trained from FL and the one from centralized training. This important issue comes from the non-iid data distribution of the local data in the participating clients and is well-known as client drift. In this work, we propose a novel training framework FedSM to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. We also propose a novel personalized FL objective formulation and a new method SoftPull to solve it in our proposed framework FedSM. We conduct rigorous theoretical analysis to guarantee its convergence for optimizing the non-convex smooth objective function. Real-world medical image segmentation experiments using deep FL validate the motivations and effectiveness of our proposed method.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022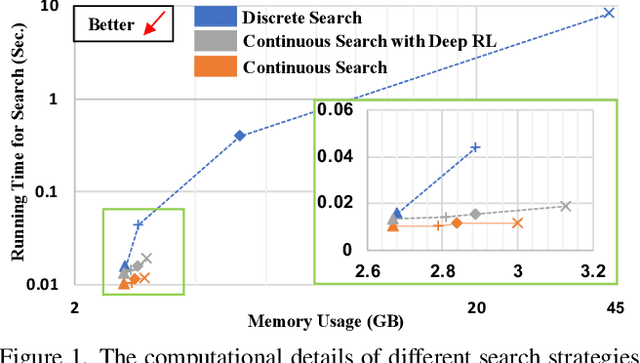

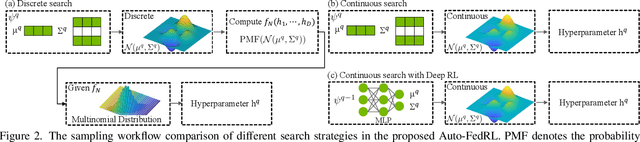

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
Do Gradient Inversion Attacks Make Federated Learning Unsafe?
Feb 14, 2022



Federated learning (FL) allows the collaborative training of AI models without needing to share raw data. This capability makes it especially interesting for healthcare applications where patient and data privacy is of utmost concern. However, recent works on the inversion of deep neural networks from model gradients raised concerns about the security of FL in preventing the leakage of training data. In this work, we show that these attacks presented in the literature are impractical in real FL use-cases and provide a new baseline attack that works for more realistic scenarios where the clients' training involves updating the Batch Normalization (BN) statistics. Furthermore, we present new ways to measure and visualize potential data leakage in FL. Our work is a step towards establishing reproducible methods of measuring data leakage in FL and could help determine the optimal tradeoffs between privacy-preserving techniques, such as differential privacy, and model accuracy based on quantifiable metrics.
Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
Jan 04, 2022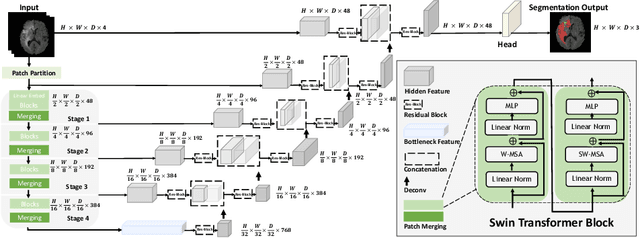

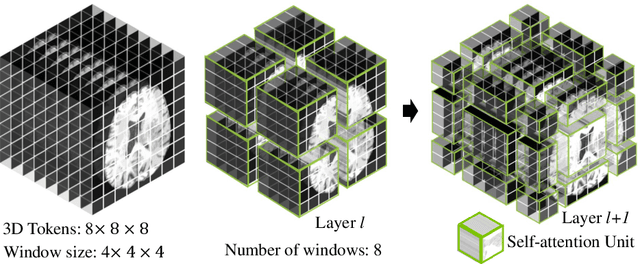
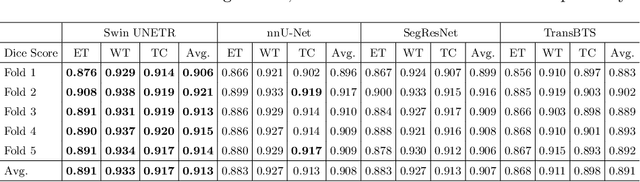
Semantic segmentation of brain tumors is a fundamental medical image analysis task involving multiple MRI imaging modalities that can assist clinicians in diagnosing the patient and successively studying the progression of the malignant entity. In recent years, Fully Convolutional Neural Networks (FCNNs) approaches have become the de facto standard for 3D medical image segmentation. The popular "U-shaped" network architecture has achieved state-of-the-art performance benchmarks on different 2D and 3D semantic segmentation tasks and across various imaging modalities. However, due to the limited kernel size of convolution layers in FCNNs, their performance of modeling long-range information is sub-optimal, and this can lead to deficiencies in the segmentation of tumors with variable sizes. On the other hand, transformer models have demonstrated excellent capabilities in capturing such long-range information in multiple domains, including natural language processing and computer vision. Inspired by the success of vision transformers and their variants, we propose a novel segmentation model termed Swin UNEt TRansformers (Swin UNETR). Specifically, the task of 3D brain tumor semantic segmentation is reformulated as a sequence to sequence prediction problem wherein multi-modal input data is projected into a 1D sequence of embedding and used as an input to a hierarchical Swin transformer as the encoder. The swin transformer encoder extracts features at five different resolutions by utilizing shifted windows for computing self-attention and is connected to an FCNN-based decoder at each resolution via skip connections. We have participated in BraTS 2021 segmentation challenge, and our proposed model ranks among the top-performing approaches in the validation phase. Code: https://monai.io/research/swin-unetr
HyperSegNAS: Bridging One-Shot Neural Architecture Search with 3D Medical Image Segmentation using HyperNet
Dec 20, 2021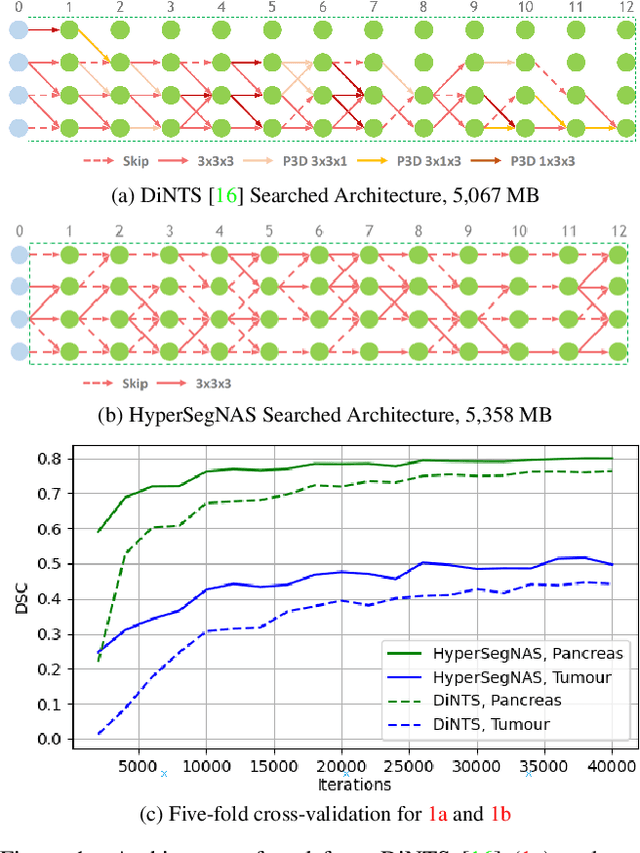
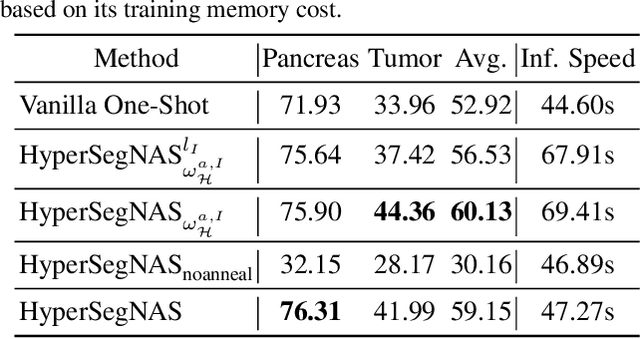
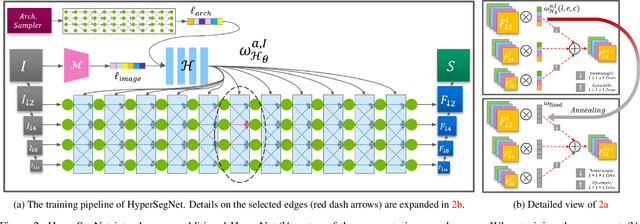
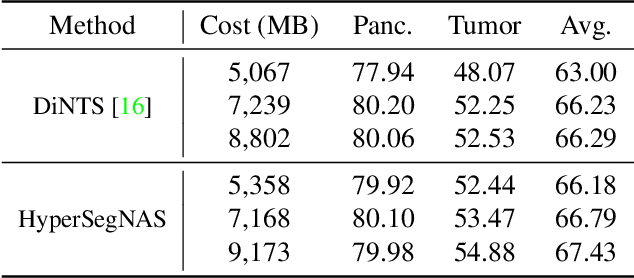
Semantic segmentation of 3D medical images is a challenging task due to the high variability of the shape and pattern of objects (such as organs or tumors). Given the recent success of deep learning in medical image segmentation, Neural Architecture Search (NAS) has been introduced to find high-performance 3D segmentation network architectures. However, because of the massive computational requirements of 3D data and the discrete optimization nature of architecture search, previous NAS methods require a long search time or necessary continuous relaxation, and commonly lead to sub-optimal network architectures. While one-shot NAS can potentially address these disadvantages, its application in the segmentation domain has not been well studied in the expansive multi-scale multi-path search space. To enable one-shot NAS for medical image segmentation, our method, named HyperSegNAS, introduces a HyperNet to assist super-net training by incorporating architecture topology information. Such a HyperNet can be removed once the super-net is trained and introduces no overhead during architecture search. We show that HyperSegNAS yields better performing and more intuitive architectures compared to the previous state-of-the-art (SOTA) segmentation networks; furthermore, it can quickly and accurately find good architecture candidates under different computing constraints. Our method is evaluated on public datasets from the Medical Segmentation Decathlon (MSD) challenge, and achieves SOTA performances.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021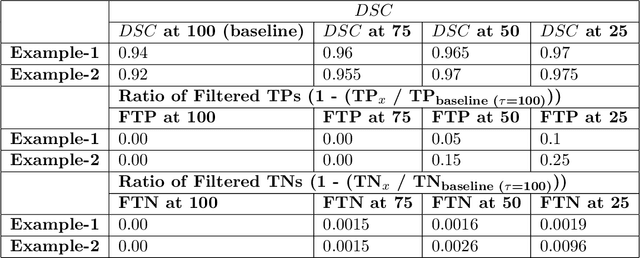
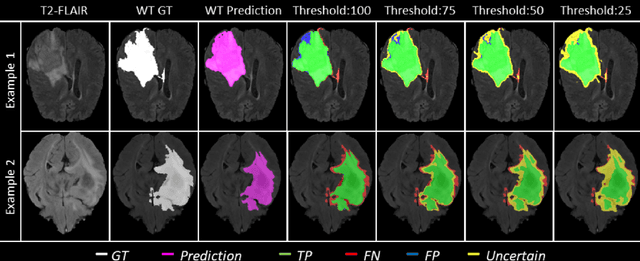
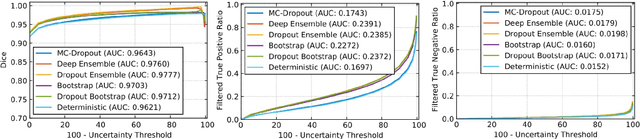
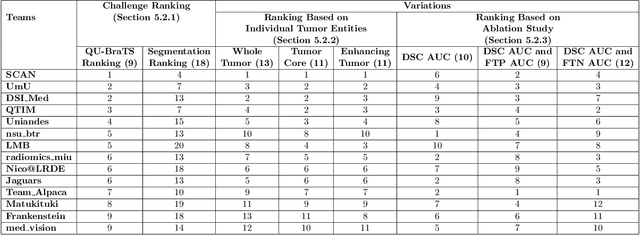
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.