 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language Representations
Sep 05, 2025We introduce Entropy2Vec, a novel framework for deriving cross-lingual language representations by leveraging the entropy of monolingual language models. Unlike traditional typological inventories that suffer from feature sparsity and static snapshots, Entropy2Vec uses the inherent uncertainty in language models to capture typological relationships between languages. By training a language model on a single language, we hypothesize that the entropy of its predictions reflects its structural similarity to other languages: Low entropy indicates high similarity, while high entropy suggests greater divergence. This approach yields dense, non-sparse language embeddings that are adaptable to different timeframes and free from missing values. Empirical evaluations demonstrate that Entropy2Vec embeddings align with established typological categories and achieved competitive performance in downstream multilingual NLP tasks, such as those addressed by the LinguAlchemy framework.
Predicting the Order of Upcoming Tokens Improves Language Modeling
Aug 26, 2025



Multi-Token Prediction (MTP) has been proposed as an auxiliary objective to improve next-token prediction (NTP) in language model training but shows inconsistent improvements, underperforming in standard NLP benchmarks. We argue that MTP's exact future token prediction is too difficult as an auxiliary loss. Instead, we propose Token Order Prediction (TOP), which trains models to order upcoming tokens by their proximity using a learning-to-rank loss. TOP requires only a single additional unembedding layer compared to MTP's multiple transformer layers. We pretrain models of 340M, 1.8B, and 7B parameters using NTP, MTP, and TOP objectives. Results on eight standard NLP benchmarks show that TOP overall outperforms both NTP and MTP even at scale. Our code is available at https://github.com/zaydzuhri/token-order-prediction
WangchanThaiInstruct: An instruction-following Dataset for Culture-Aware, Multitask, and Multi-domain Evaluation in Thai
Aug 21, 2025Large language models excel at instruction-following in English, but their performance in low-resource languages like Thai remains underexplored. Existing benchmarks often rely on translations, missing cultural and domain-specific nuances needed for real-world use. We present WangchanThaiInstruct, a human-authored Thai dataset for evaluation and instruction tuning, covering four professional domains and seven task types. Created through a multi-stage quality control process with annotators, domain experts, and AI researchers, WangchanThaiInstruct supports two studies: (1) a zero-shot evaluation showing performance gaps on culturally and professionally specific tasks, and (2) an instruction tuning study with ablations isolating the effect of native supervision. Models fine-tuned on WangchanThaiInstruct outperform those using translated data in both in-domain and out-of-domain benchmarks. These findings underscore the need for culturally and professionally grounded instruction data to improve LLM alignment in low-resource, linguistically diverse settings.
LoraxBench: A Multitask, Multilingual Benchmark Suite for 20 Indonesian Languages
Aug 17, 2025As one of the world's most populous countries, with 700 languages spoken, Indonesia is behind in terms of NLP progress. We introduce LoraxBench, a benchmark that focuses on low-resource languages of Indonesia and covers 6 diverse tasks: reading comprehension, open-domain QA, language inference, causal reasoning, translation, and cultural QA. Our dataset covers 20 languages, with the addition of two formality registers for three languages. We evaluate a diverse set of multilingual and region-focused LLMs and found that this benchmark is challenging. We note a visible discrepancy between performance in Indonesian and other languages, especially the low-resource ones. There is no clear lead when using a region-specific model as opposed to the general multilingual model. Lastly, we show that a change in register affects model performance, especially with registers not commonly found in social media, such as high-level politeness `Krama' Javanese.
SEADialogues: A Multilingual Culturally Grounded Multi-turn Dialogue Dataset on Southeast Asian Languages
Aug 09, 2025Although numerous datasets have been developed to support dialogue systems, most existing chit-chat datasets overlook the cultural nuances inherent in natural human conversations. To address this gap, we introduce SEADialogues, a culturally grounded dialogue dataset centered on Southeast Asia, a region with over 700 million people and immense cultural diversity. Our dataset features dialogues in eight languages from six Southeast Asian countries, many of which are low-resource despite having sizable speaker populations. To enhance cultural relevance and personalization, each dialogue includes persona attributes and two culturally grounded topics that reflect everyday life in the respective communities. Furthermore, we release a multi-turn dialogue dataset to advance research on culturally aware and human-centric large language models, including conversational dialogue agents.
Unveiling the Influence of Amplifying Language-Specific Neurons
Jul 30, 2025Language-specific neurons in LLMs that strongly correlate with individual languages have been shown to influence model behavior by deactivating them. However, their role in amplification remains underexplored. This work investigates the effect of amplifying language-specific neurons through interventions across 18 languages, including low-resource ones, using three models primarily trained in different languages. We compare amplification factors by their effectiveness in steering to the target language using a proposed Language Steering Shift (LSS) evaluation score, then evaluate it on downstream tasks: commonsense reasoning (XCOPA, XWinograd), knowledge (Include), and translation (FLORES). The optimal amplification factors effectively steer output toward nearly all tested languages. Intervention using this factor on downstream tasks improves self-language performance in some cases but generally degrades cross-language results. These findings highlight the effect of language-specific neurons in multilingual behavior, where amplification can be beneficial especially for low-resource languages, but provides limited advantage for cross-lingual transfer.
Language Surgery in Multilingual Large Language Models
Jun 14, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across tasks and languages, revolutionizing natural language processing. This paper investigates the naturally emerging representation alignment in LLMs, particularly in the middle layers, and its implications for disentangling language-specific and language-agnostic information. We empirically confirm the existence of this alignment, analyze its behavior in comparison to explicitly designed alignment models, and demonstrate its potential for language-specific manipulation without semantic degradation. Building on these findings, we propose Inference-Time Language Control (ITLC), a novel method that leverages latent injection to enable precise cross-lingual language control and mitigate language confusion in LLMs. Our experiments highlight ITLC's strong cross-lingual control capabilities while preserving semantic integrity in target languages. Furthermore, we demonstrate its effectiveness in alleviating the cross-lingual language confusion problem, which persists even in current large-scale LLMs, leading to inconsistent language generation. This work advances our understanding of representation alignment in LLMs and introduces a practical solution for enhancing their cross-lingual performance.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025
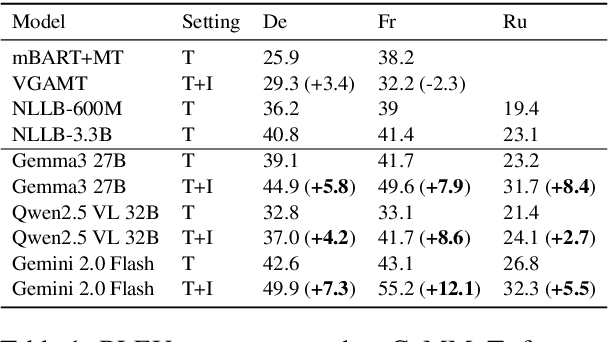

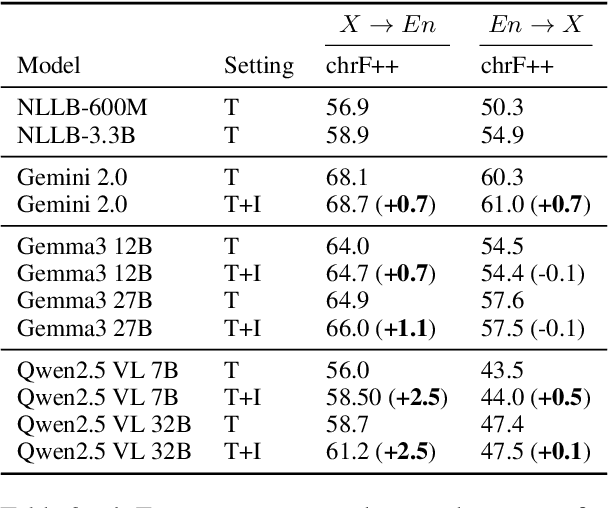
Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
From Surveys to Narratives: Rethinking Cultural Value Adaptation in LLMs
May 22, 2025Adapting cultural values in Large Language Models (LLMs) presents significant challenges, particularly due to biases and limited training data. Prior work primarily aligns LLMs with different cultural values using World Values Survey (WVS) data. However, it remains unclear whether this approach effectively captures cultural nuances or produces distinct cultural representations for various downstream tasks. In this paper, we systematically investigate WVS-based training for cultural value adaptation and find that relying solely on survey data can homogenize cultural norms and interfere with factual knowledge. To investigate these issues, we augment WVS with encyclopedic and scenario-based cultural narratives from Wikipedia and NormAd. While these narratives may have variable effects on downstream tasks, they consistently improve cultural distinctiveness than survey data alone. Our work highlights the inherent complexity of aligning cultural values with the goal of guiding task-specific behavior.
Understanding Cross-Lingual Inconsistency in Large Language Models
May 19, 2025Large language models (LLMs) are demonstrably capable of cross-lingual transfer, but can produce inconsistent output when prompted with the same queries written in different languages. To understand how language models are able to generalize knowledge from one language to the others, we apply the logit lens to interpret the implicit steps taken by LLMs to solve multilingual multi-choice reasoning questions. We find LLMs predict inconsistently and are less accurate because they rely on subspaces of individual languages, rather than working in a shared semantic space. While larger models are more multilingual, we show their hidden states are more likely to dissociate from the shared representation compared to smaller models, but are nevertheless more capable of retrieving knowledge embedded across different languages. Finally, we demonstrate that knowledge sharing can be modulated by steering the models' latent processing towards the shared semantic space. We find reinforcing utilization of the shared space improves the models' multilingual reasoning performance, as a result of more knowledge transfer from, and better output consistency with English.