 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Factorize and Relight a City
Aug 06, 2020
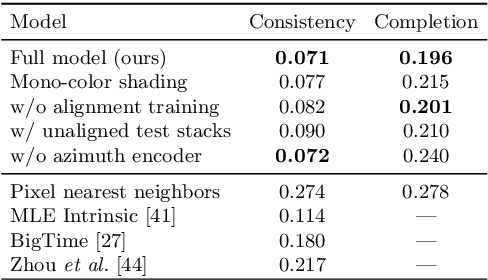


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.
Unselfie: Translating Selfies to Neutral-pose Portraits in the Wild
Jul 29, 2020

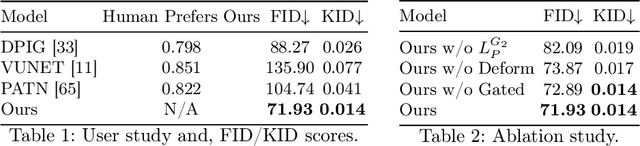
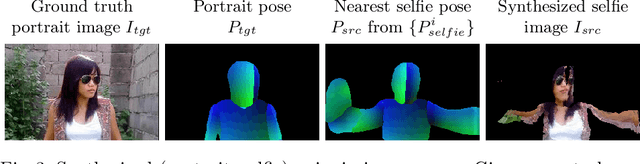
Due to the ubiquity of smartphones, it is popular to take photos of one's self, or "selfies." Such photos are convenient to take, because they do not require specialized equipment or a third-party photographer. However, in selfies, constraints such as human arm length often make the body pose look unnatural. To address this issue, we introduce $\textit{unselfie}$, a novel photographic transformation that automatically translates a selfie into a neutral-pose portrait. To achieve this, we first collect an unpaired dataset, and introduce a way to synthesize paired training data for self-supervised learning. Then, to $\textit{unselfie}$ a photo, we propose a new three-stage pipeline, where we first find a target neutral pose, inpaint the body texture, and finally refine and composite the person on the background. To obtain a suitable target neutral pose, we propose a novel nearest pose search module that makes the reposing task easier and enables the generation of multiple neutral-pose results among which users can choose the best one they like. Qualitative and quantitative evaluations show the superiority of our pipeline over alternatives.
Self-Supervised Policy Adaptation during Deployment
Jul 08, 2020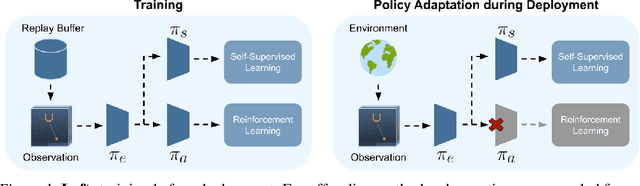
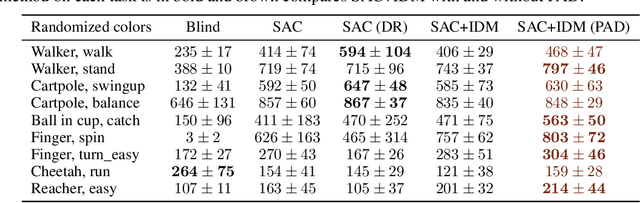

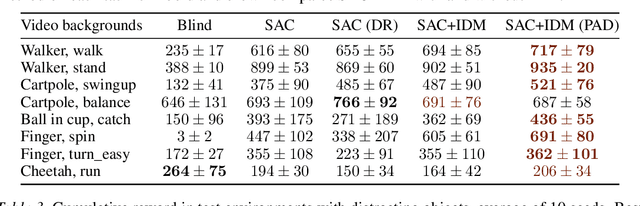
In most real world scenarios, a policy trained by reinforcement learning in one environment needs to be deployed in another, potentially quite different environment. However, generalization across different environments is known to be hard. A natural solution would be to keep training after deployment in the new environment, but this cannot be done if the new environment offers no reward signal. Our work explores the use of self-supervision to allow the policy to continue training after deployment without using any rewards. While previous methods explicitly anticipate changes in the new environment, we assume no prior knowledge of those changes yet still obtain significant improvements. Empirical evaluations are performed on diverse environments from DeepMind Control suite and ViZDoom. Our method improves generalization in 25 out of 30 environments across various tasks, and outperforms domain randomization on a majority of environments.
Swapping Autoencoder for Deep Image Manipulation
Jul 01, 2020


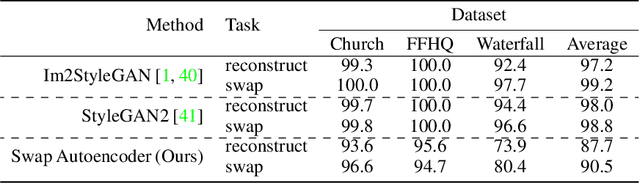
Deep generative models have become increasingly effective at producing realistic images from randomly sampled seeds, but using such models for controllable manipulation of existing images remains challenging. We propose the Swapping Autoencoder, a deep model designed specifically for image manipulation, rather than random sampling. The key idea is to encode an image with two independent components and enforce that any swapped combination maps to a realistic image. In particular, we encourage the components to represent structure and texture, by enforcing one component to encode co-occurrent patch statistics across different parts of an image. As our method is trained with an encoder, finding the latent codes for a new input image becomes trivial, rather than cumbersome. As a result, it can be used to manipulate real input images in various ways, including texture swapping, local and global editing, and latent code vector arithmetic. Experiments on multiple datasets show that our model produces better results and is substantially more efficient compared to recent generative models.
Space-Time Correspondence as a Contrastive Random Walk
Jun 25, 2020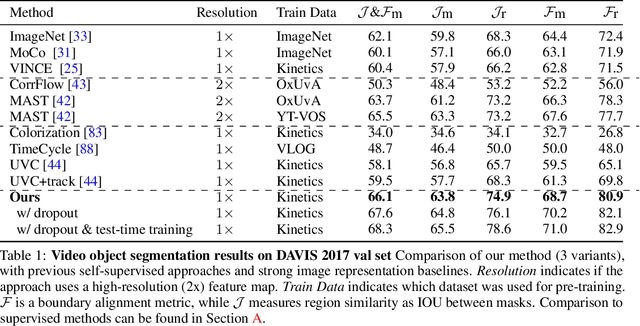
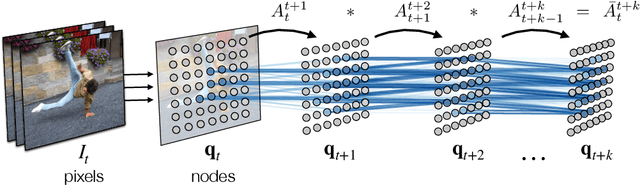
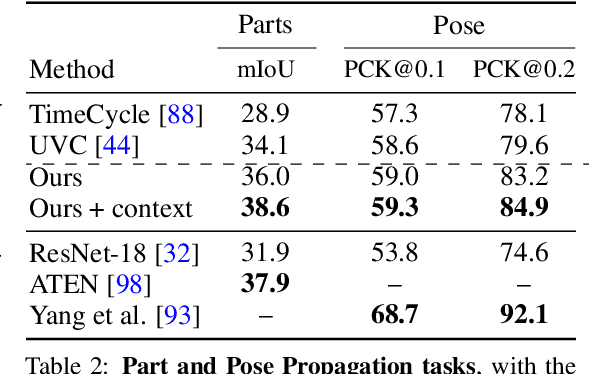
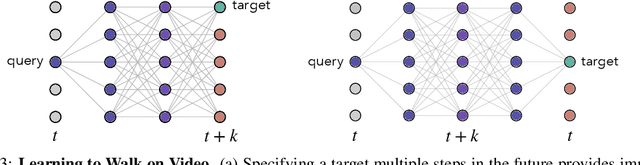
This paper proposes a simple self-supervised approach for learning representations for visual correspondence from raw video. We cast correspondence as link prediction in a space-time graph constructed from a video. In this graph, the nodes are patches sampled from each frame, and nodes adjacent in time can share a directed edge. We learn a node embedding in which pairwise similarity defines transition probabilities of a random walk. Prediction of long-range correspondence is efficiently computed as a walk along this graph. The embedding learns to guide the walk by placing high probability along paths of correspondence. Targets are formed without supervision, by cycle-consistency: we train the embedding to maximize the likelihood of returning to the initial node when walking along a graph constructed from a `palindrome' of frames. We demonstrate that the approach allows for learning representations from large unlabeled video. Despite its simplicity, the method outperforms the self-supervised state-of-the-art on a variety of label propagation tasks involving objects, semantic parts, and pose. Moreover, we show that self-supervised adaptation at test-time and edge dropout improve transfer for object-level correspondence.
RANSAC-Flow: generic two-stage image alignment
Apr 03, 2020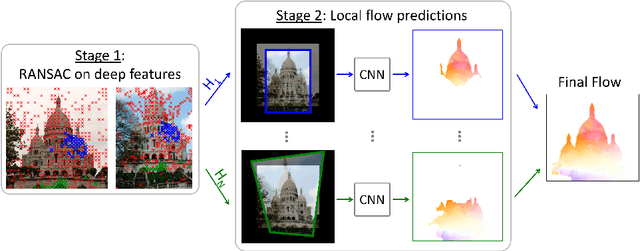
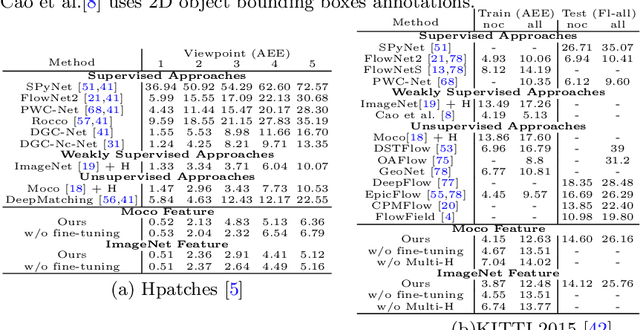

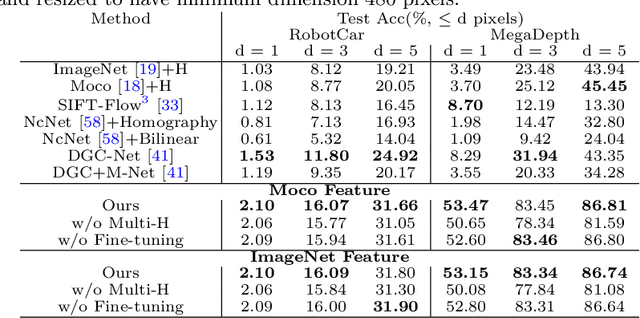
This paper considers the generic problem of dense alignment between two images, whether they be two frames of a video, two widely different views of a scene, two paintings depicting similar content, etc. Whereas each such task is typically addressed with a domain-specific solution, we show that a simple unsupervised approach performs surprisingly well across a range of tasks. Our main insight is that parametric and non-parametric alignment methods have complementary strengths. We propose a two-stage process: first, a feature-based parametric coarse alignment using one or more homographies, followed by non-parametric fine pixel-wise alignment. Coarse alignment is performed using RANSAC on off-the-shelf deep features. Fine alignment is learned in an unsupervised way by a deep network which optimizes a standard structural similarity metric (SSIM) between the two images, plus cycle-consistency. Despite its simplicity, our method shows competitive results on a range of tasks and datasets, including unsupervised optical flow on KITTI, dense correspondences on Hpatches, two-view geometry estimation on YFCC100M, localization on Aachen Day-Night, and, for the first time, fine alignment of artworks on the Brughel dataset. Our code and data are available at http://imagine.enpc.fr/~shenx/RANSAC-Flow/
CNN-generated images are surprisingly easy to spot for now
Dec 23, 2019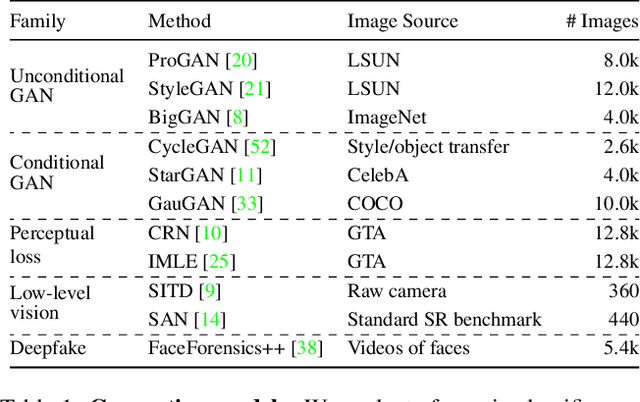
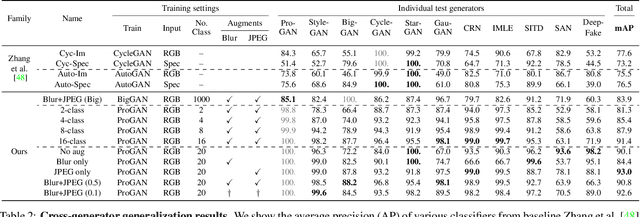
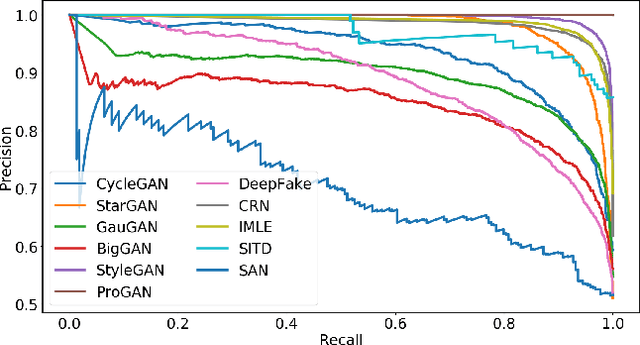

In this work we ask whether it is possible to create a "universal" detector for telling apart real images from these generated by a CNN, regardless of architecture or dataset used. To test this, we collect a dataset consisting of fake images generated by 11 different CNN-based image generator models, chosen to span the space of commonly used architectures today (ProGAN, StyleGAN, BigGAN, CycleGAN, StarGAN, GauGAN, DeepFakes, cascaded refinement networks, implicit maximum likelihood estimation, second-order attention super-resolution, seeing-in-the-dark). We demonstrate that, with careful pre- and post-processing and data augmentation, a standard image classifier trained on only one specific CNN generator (ProGAN) is able to generalize surprisingly well to unseen architectures, datasets, and training methods (including the just released StyleGAN2). Our findings suggest the intriguing possibility that today's CNN-generated images share some common systematic flaws, preventing them from achieving realistic image synthesis.
Test-Time Training for Out-of-Distribution Generalization
Oct 25, 2019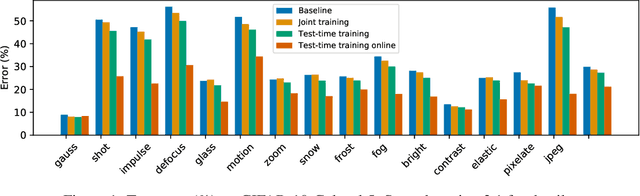
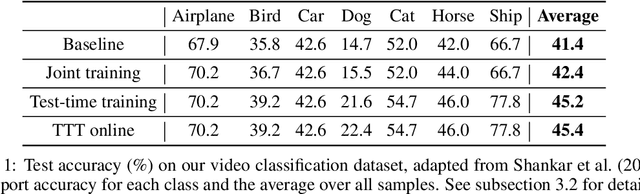
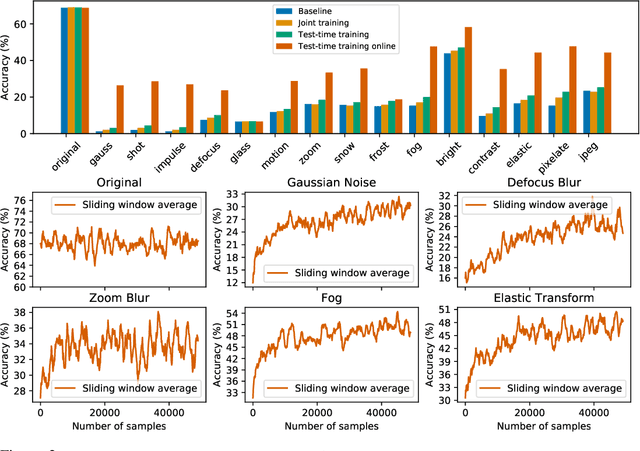
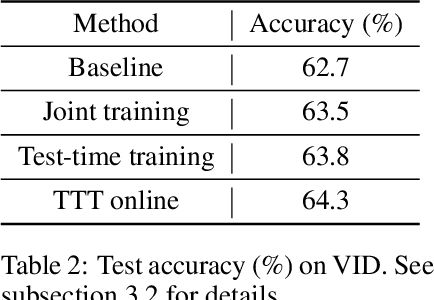
We introduce a general approach, called test-time training, for improving the performance of predictive models when test and training data come from different distributions. Test-time training turns a single unlabeled test instance into a self-supervised learning problem, on which we update the model parameters before making a prediction on this instance. We show that this simple idea leads to surprising improvements on diverse image classification benchmarks aimed at evaluating robustness to distribution shifts. Theoretical investigations on a convex model reveal helpful intuitions for when we can expect our approach to help.
Unsupervised Domain Adaptation through Self-Supervision
Sep 29, 2019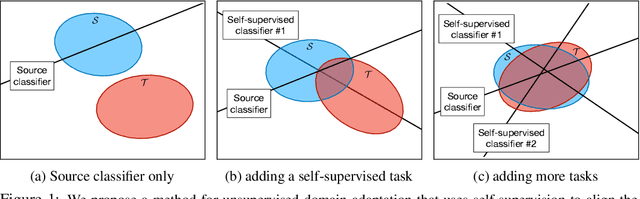

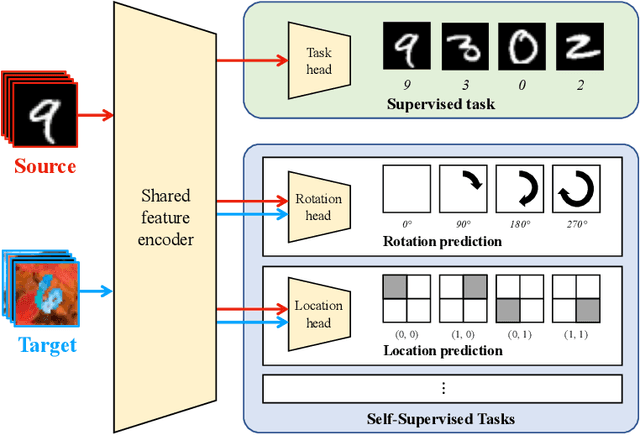
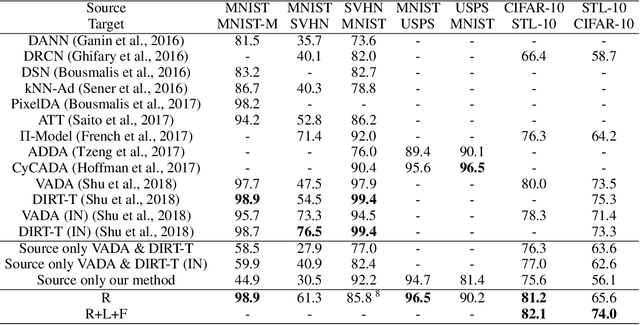
This paper addresses unsupervised domain adaptation, the setting where labeled training data is available on a source domain, but the goal is to have good performance on a target domain with only unlabeled data. Like much of previous work, we seek to align the learned representations of the source and target domains while preserving discriminability. The way we accomplish alignment is by learning to perform auxiliary self-supervised task(s) on both domains simultaneously. Each self-supervised task brings the two domains closer together along the direction relevant to that task. Training this jointly with the main task classifier on the source domain is shown to successfully generalize to the unlabeled target domain. The presented objective is straightforward to implement and easy to optimize. We achieve state-of-the-art results on four out of seven standard benchmarks, and competitive results on segmentation adaptation. We also demonstrate that our method composes well with another popular pixel-level adaptation method.
Interactive Sketch & Fill: Multiclass Sketch-to-Image Translation
Sep 25, 2019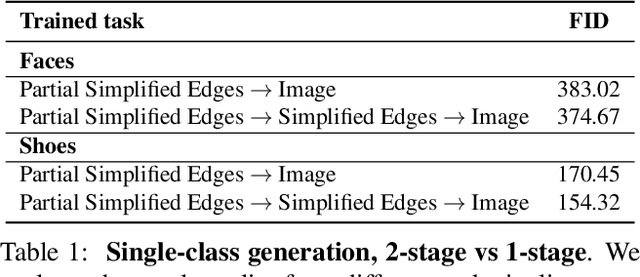


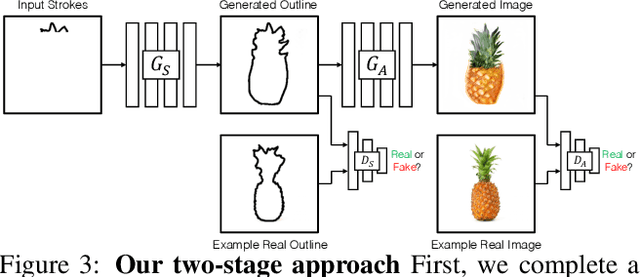
We propose an interactive GAN-based sketch-to-image translation method that helps novice users create images of simple objects. As the user starts to draw a sketch of a desired object type, the network interactively recommends plausible completions, and shows a corresponding synthesized image to the user. This enables a feedback loop, where the user can edit their sketch based on the network's recommendations, visualizing both the completed shape and final rendered image while they draw. In order to use a single trained model across a wide array of object classes, we introduce a gating-based approach for class conditioning, which allows us to generate distinct classes without feature mixing, from a single generator network. Video available at our website: https://arnabgho.github.io/iSketchNFill/.