 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reinforcement Learning for Recommendation: A Prompt Perspective
Jun 15, 2022
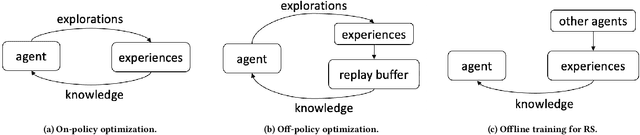
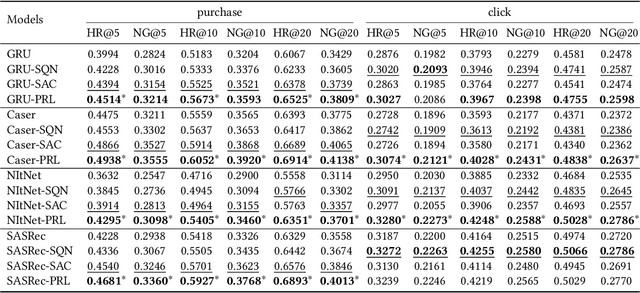
Modern recommender systems aim to improve user experience. As reinforcement learning (RL) naturally fits this objective -- maximizing an user's reward per session -- it has become an emerging topic in recommender systems. Developing RL-based recommendation methods, however, is not trivial due to the \emph{offline training challenge}. Specifically, the keystone of traditional RL is to train an agent with large amounts of online exploration making lots of `errors' in the process. In the recommendation setting, though, we cannot afford the price of making `errors' online. As a result, the agent needs to be trained through offline historical implicit feedback, collected under different recommendation policies; traditional RL algorithms may lead to sub-optimal policies under these offline training settings. Here we propose a new learning paradigm -- namely Prompt-Based Reinforcement Learning (PRL) -- for the offline training of RL-based recommendation agents. While traditional RL algorithms attempt to map state-action input pairs to their expected rewards (e.g., Q-values), PRL directly infers actions (i.e., recommended items) from state-reward inputs. In short, the agents are trained to predict a recommended item given the prior interactions and an observed reward value -- with simple supervised learning. At deployment time, this historical (training) data acts as a knowledge base, while the state-reward pairs are used as a prompt. The agents are thus used to answer the question: \emph{ Which item should be recommended given the prior interactions \& the prompted reward value}? We implement PRL with four notable recommendation models and conduct experiments on two real-world e-commerce datasets. Experimental results demonstrate the superior performance of our proposed methods.
Enhancing Top-N Item Recommendations by Peer Collaboration
Dec 02, 2021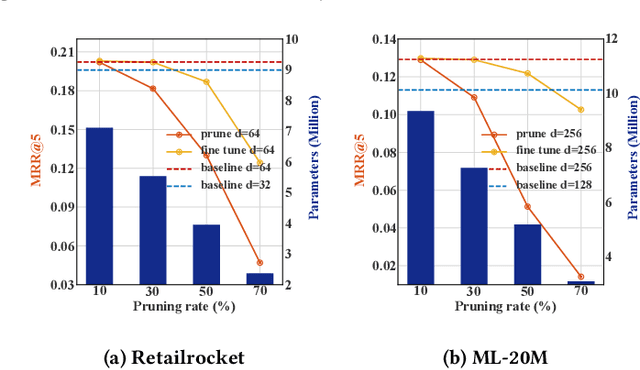
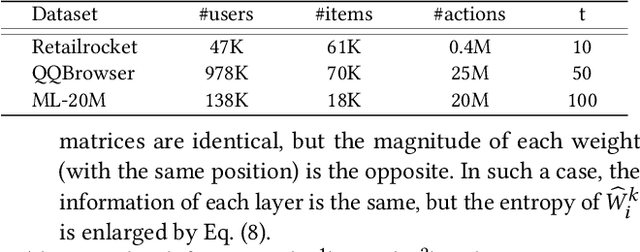
Deep neural networks (DNN) have achieved great success in the recommender systems (RS) domain. However, to achieve remarkable performance, DNN-based recommender models often require numerous parameters, which inevitably bring redundant neurons and weights, a phenomenon referred to as over-parameterization. In this paper, we plan to exploit such redundancy phenomena to improve the performance of RS. Specifically, we propose PCRec, a top-N item \underline{rec}ommendation framework that leverages collaborative training of two DNN-based recommender models with the same network structure, termed \underline{p}eer \underline{c}ollaboration. PCRec can reactivate and strengthen the unimportant (redundant) weights during training, which achieves higher prediction accuracy but maintains its original inference efficiency. To realize this, we first introduce two criteria to identify the importance of weights of a given recommender model. Then, we rejuvenate the unimportant weights by transplanting outside information (i.e., weights) from its peer network. After such an operation and retraining, the original recommender model is endowed with more representation capacity by possessing more functional model parameters. To show its generality, we instantiate PCRec by using three well-known recommender models. We conduct extensive experiments on three real-world datasets, and show that PCRec yields significantly better recommendations than its counterpart with the same model (parameter) size.
Supervised Advantage Actor-Critic for Recommender Systems
Nov 05, 2021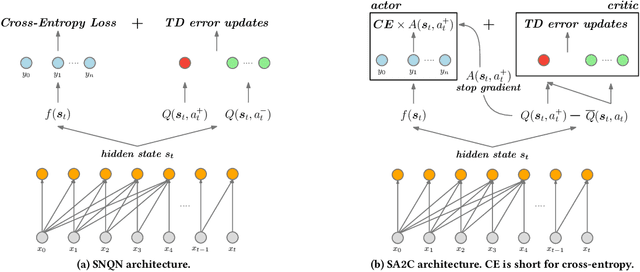
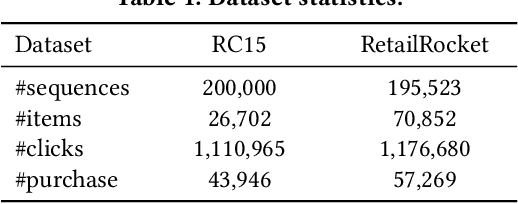
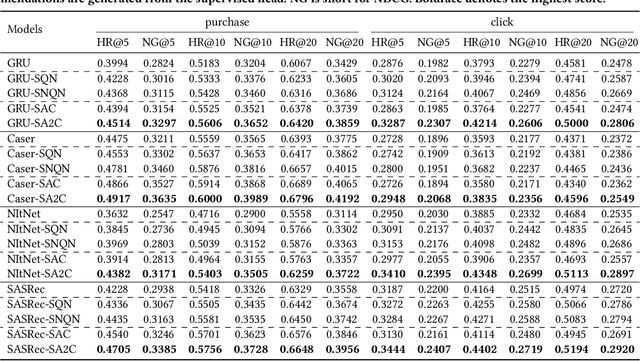
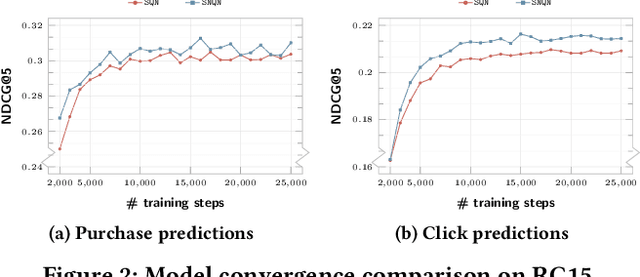
Casting session-based or sequential recommendation as reinforcement learning (RL) through reward signals is a promising research direction towards recommender systems (RS) that maximize cumulative profits. However, the direct use of RL algorithms in the RS setting is impractical due to challenges like off-policy training, huge action spaces and lack of sufficient reward signals. Recent RL approaches for RS attempt to tackle these challenges by combining RL and (self-)supervised sequential learning, but still suffer from certain limitations. For example, the estimation of Q-values tends to be biased toward positive values due to the lack of negative reward signals. Moreover, the Q-values also depend heavily on the specific timestamp of a sequence. To address the above problems, we propose negative sampling strategy for training the RL component and combine it with supervised sequential learning. We call this method Supervised Negative Q-learning (SNQN). Based on sampled (negative) actions (items), we can calculate the "advantage" of a positive action over the average case, which can be further utilized as a normalized weight for learning the supervised sequential part. This leads to another learning framework: Supervised Advantage Actor-Critic (SA2C). We instantiate SNQN and SA2C with four state-of-the-art sequential recommendation models and conduct experiments on two real-world datasets. Experimental results show that the proposed approaches achieve significantly better performance than state-of-the-art supervised methods and existing self-supervised RL methods . Code will be open-sourced.
Choosing the Best of Both Worlds: Diverse and Novel Recommendations through Multi-Objective Reinforcement Learning
Oct 28, 2021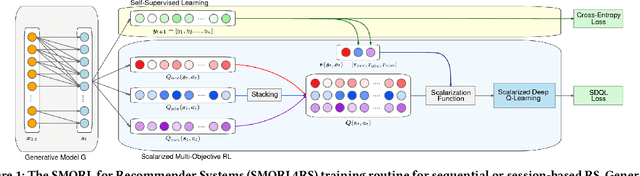
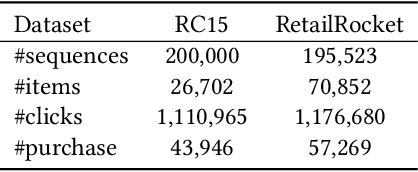
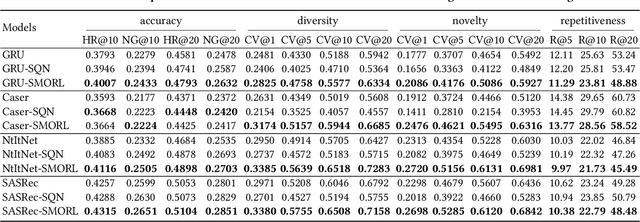
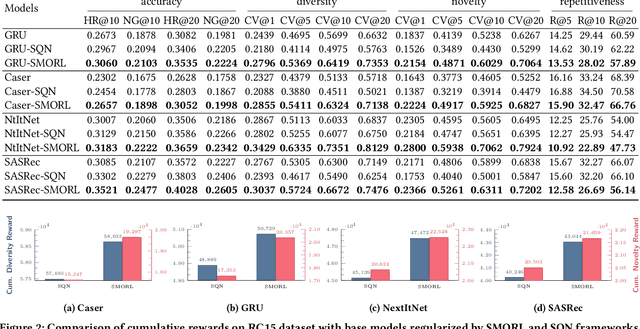
Since the inception of Recommender Systems (RS), the accuracy of the recommendations in terms of relevance has been the golden criterion for evaluating the quality of RS algorithms. However, by focusing on item relevance, one pays a significant price in terms of other important metrics: users get stuck in a "filter bubble" and their array of options is significantly reduced, hence degrading the quality of the user experience and leading to churn. Recommendation, and in particular session-based/sequential recommendation, is a complex task with multiple - and often conflicting objectives - that existing state-of-the-art approaches fail to address. In this work, we take on the aforementioned challenge and introduce Scalarized Multi-Objective Reinforcement Learning (SMORL) for the RS setting, a novel Reinforcement Learning (RL) framework that can effectively address multi-objective recommendation tasks. The proposed SMORL agent augments standard recommendation models with additional RL layers that enforce it to simultaneously satisfy three principal objectives: accuracy, diversity, and novelty of recommendations. We integrate this framework with four state-of-the-art session-based recommendation models and compare it with a single-objective RL agent that only focuses on accuracy. Our experimental results on two real-world datasets reveal a substantial increase in aggregate diversity, a moderate increase in accuracy, reduced repetitiveness of recommendations, and demonstrate the importance of reinforcing diversity and novelty as complementary objectives.
On Interpretation and Measurement of Soft Attributes for Recommendation
May 19, 2021
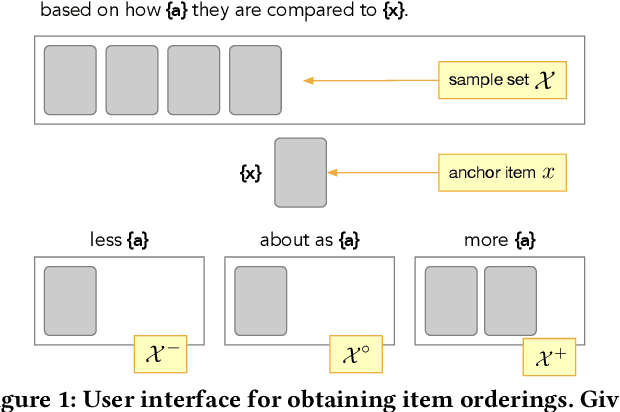

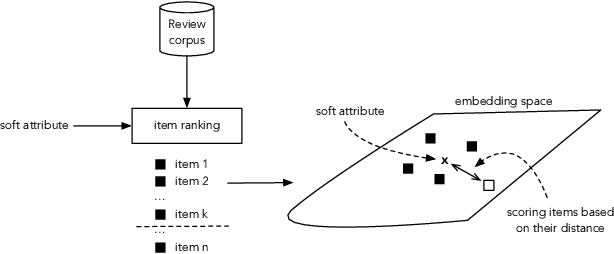
We address how to robustly interpret natural language refinements (or critiques) in recommender systems. In particular, in human-human recommendation settings people frequently use soft attributes to express preferences about items, including concepts like the originality of a movie plot, the noisiness of a venue, or the complexity of a recipe. While binary tagging is extensively studied in the context of recommender systems, soft attributes often involve subjective and contextual aspects, which cannot be captured reliably in this way, nor be represented as objective binary truth in a knowledge base. This also adds important considerations when measuring soft attribute ranking. We propose a more natural representation as personalized relative statements, rather than as absolute item properties. We present novel data collection techniques and evaluation approaches, and a new public dataset. We also propose a set of scoring approaches, from unsupervised to weakly supervised to fully supervised, as a step towards interpreting and acting upon soft attribute based critiques.
Graph Convolutional Embeddings for Recommender Systems
Mar 05, 2021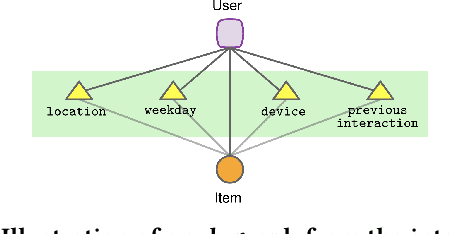
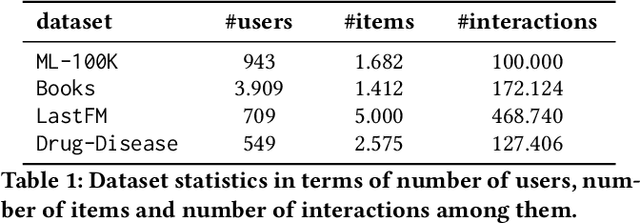
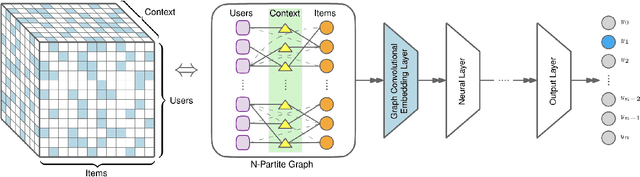
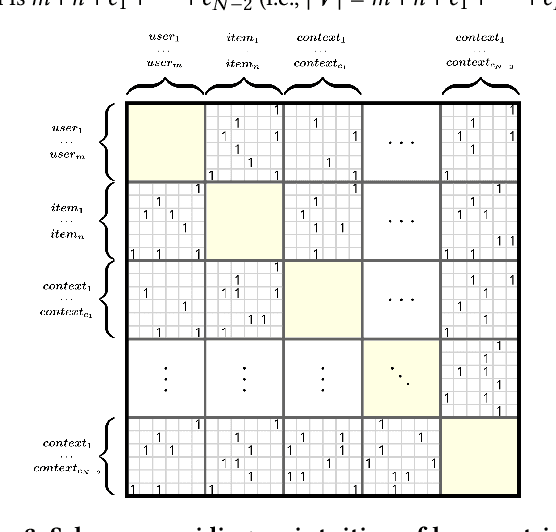
Modern recommender systems (RS) work by processing a number of signals that can be inferred from large sets of user-item interaction data. The main signal to analyze stems from the raw matrix that represents interactions. However, we can increase the performance of RS by considering other kinds of signals like the context of interactions, which could be, for example, the time or date of the interaction, the user location, or sequential data corresponding to the historical interactions of the user with the system. These complex, context-based interaction signals are characterized by a rich relational structure that can be represented by a multi-partite graph. Graph Convolutional Networks (GCNs) have been used successfully in collaborative filtering with simple user-item interaction data. In this work, we generalize the use of GCNs for N-partite graphs by considering N multiple context dimensions and propose a simple way for their seamless integration in modern deep learning RS architectures. More specifically, we define a graph convolutional embedding layer for N-partite graphs that processes user-item-context interactions, and constructs node embeddings by leveraging their relational structure. Experiments on several datasets from recommender systems to drug re-purposing show the benefits of the introduced GCN embedding layer by measuring the performance of different context-enriched tasks.
Self-Supervised Reinforcement Learning for Recommender Systems
Jun 11, 2020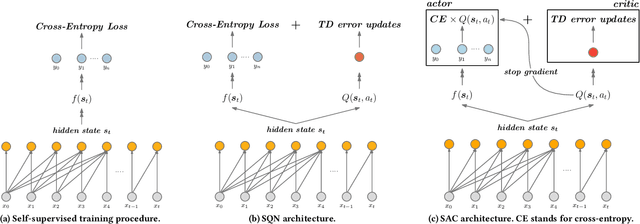

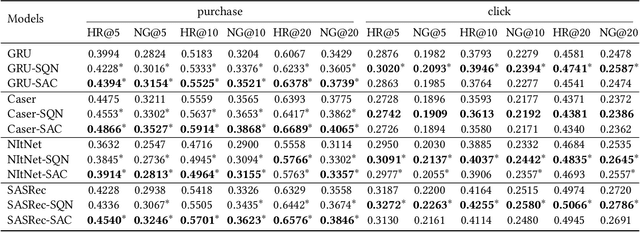
In session-based or sequential recommendation, it is important to consider a number of factors like long-term user engagement, multiple types of user-item interactions such as clicks, purchases etc. The current state-of-the-art supervised approaches fail to model them appropriately. Casting sequential recommendation task as a reinforcement learning (RL) problem is a promising direction. A major component of RL approaches is to train the agent through interactions with the environment. However, it is often problematic to train a recommender in an on-line fashion due to the requirement to expose users to irrelevant recommendations. As a result, learning the policy from logged implicit feedback is of vital importance, which is challenging due to the pure off-policy setting and lack of negative rewards (feedback). In this paper, we propose self-supervised reinforcement learning for sequential recommendation tasks. Our approach augments standard recommendation models with two output layers: one for self-supervised learning and the other for RL. The RL part acts as a regularizer to drive the supervised layer focusing on specific rewards(e.g., recommending items which may lead to purchases rather than clicks) while the self-supervised layer with cross-entropy loss provides strong gradient signals for parameter updates. Based on such an approach, we propose two frameworks namely Self-Supervised Q-learning(SQN) and Self-Supervised Actor-Critic(SAC). We integrate the proposed frameworks with four state-of-the-art recommendation models. Experimental results on two real-world datasets demonstrate the effectiveness of our approach.
Graph Highway Networks
Apr 09, 2020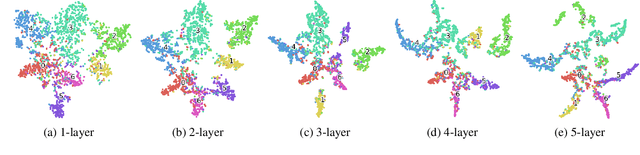
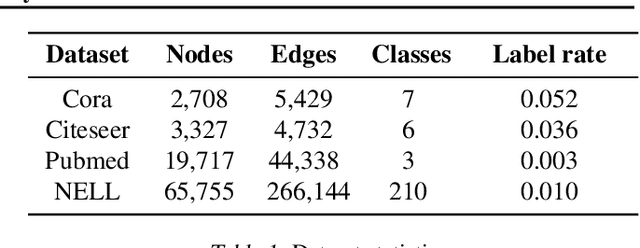
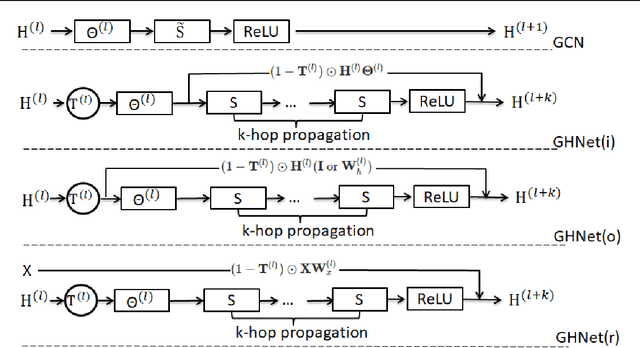
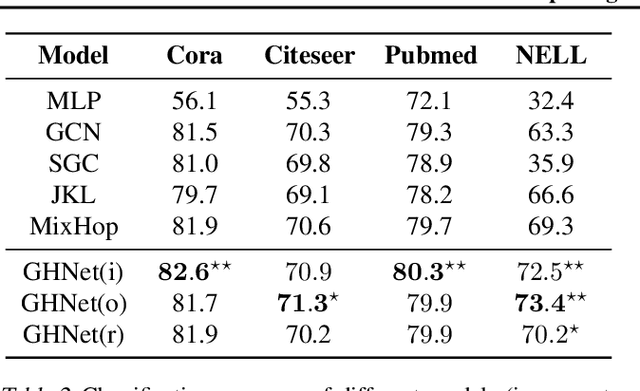
Graph Convolution Networks (GCN) are widely used in learning graph representations due to their effectiveness and efficiency. However, they suffer from the notorious over-smoothing problem, in which the learned representations of densely connected nodes converge to alike vectors when many (>3) graph convolutional layers are stacked. In this paper, we argue that there-normalization trick used in GCN leads to overly homogeneous information propagation, which is the source of over-smoothing. To address this problem, we propose Graph Highway Networks(GHNet) which utilize gating units to automatically balance the trade-off between homogeneity and heterogeneity in the GCN learning process. The gating units serve as direct highways to maintain heterogeneous information from the node itself after feature propagation. This design enables GHNet to achieve much larger receptive fields per node without over-smoothing and thus access to more of the graph connectivity information. Experimental results on benchmark datasets demonstrate the superior performance of GHNet over GCN and related models.
Parameter-Efficient Transfer from Sequential Behaviors for User Modeling and Recommendation
Feb 04, 2020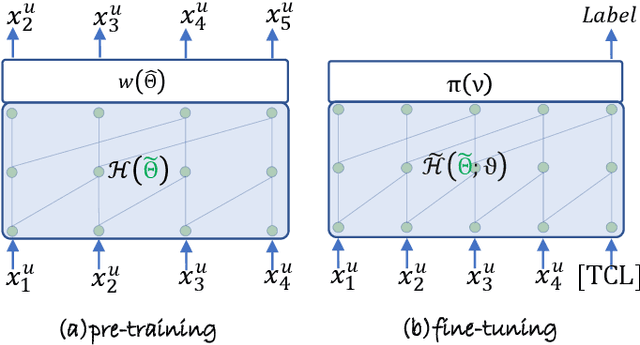
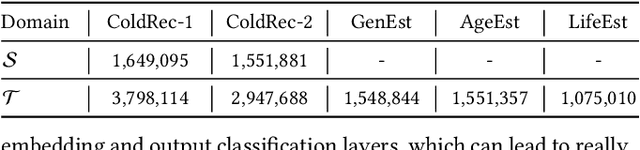
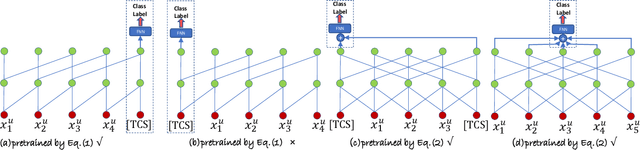
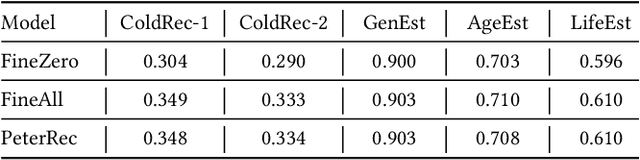
Inductive transfer learning has had a big impact on computer vision and NLP domains but has not been used in the area of recommender systems. Even though there has been a large body of research on generating recommendations based on modeling user-item interaction sequences, few of them attempt to represent and transfer these models for serving downstream tasks where only limited data exists. In this paper, we delve on the task of effectively learning a single user representation that can be applied to a diversity of tasks, from cross-domain recommendations to user profile predictions. Fine-tuning a large pre-trained network and adapting it to downstream tasks is an effective way to solve such tasks. However, fine-tuning is parameter inefficient considering that an entire model needs to be re-trained for every new task. To overcome this issue, we develop a parameter efficient transfer learning architecture, termed as PeterRec, which can be configured on-the-fly to various downstream tasks. Specifically, PeterRec allows the pre-trained parameters to remain unaltered during fine-tuning by injecting a series of re-learned neural networks, which are small but as expressive as learning the entire network. We perform extensive experimental ablation to show the effectiveness of the learned user representation in five downstream tasks. Moreover, we show that PeterRec performs efficient transfer learning in multiple domains, where it achieves comparable or sometimes better performance relative to fine-tuning the entire model parameters.
RecoGym: A Reinforcement Learning Environment for the problem of Product Recommendation in Online Advertising
Sep 14, 2018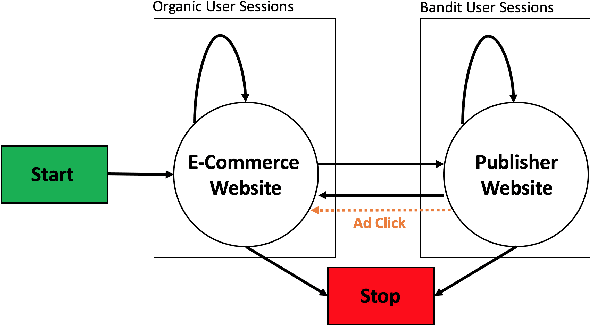

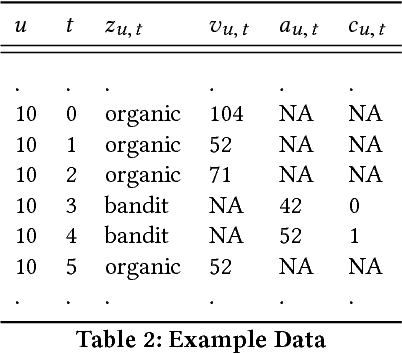
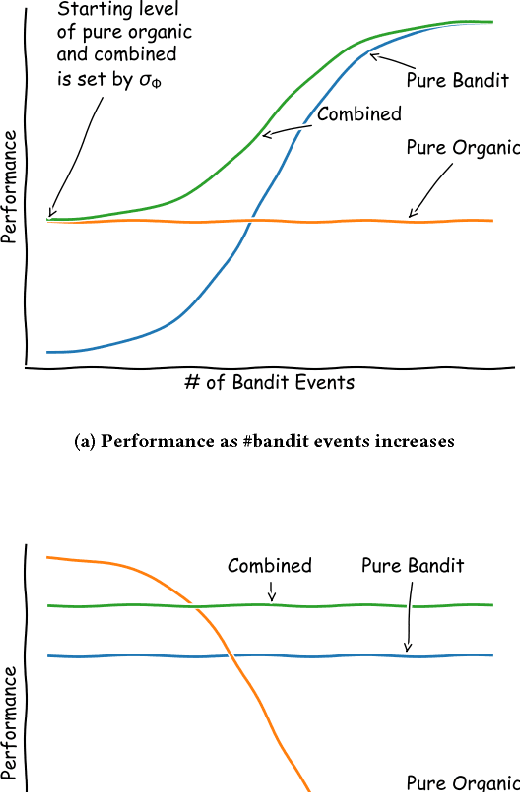
Recommender Systems are becoming ubiquitous in many settings and take many forms, from product recommendation in e-commerce stores, to query suggestions in search engines, to friend recommendation in social networks. Current research directions which are largely based upon supervised learning from historical data appear to be showing diminishing returns with a lot of practitioners report a discrepancy between improvements in offline metrics for supervised learning and the online performance of the newly proposed models. One possible reason is that we are using the wrong paradigm: when looking at the long-term cycle of collecting historical performance data, creating a new version of the recommendation model, A/B testing it and then rolling it out. We see that there a lot of commonalities with the reinforcement learning (RL) setup, where the agent observes the environment and acts upon it in order to change its state towards better states (states with higher rewards). To this end we introduce RecoGym, an RL environment for recommendation, which is defined by a model of user traffic patterns on e-commerce and the users response to recommendations on the publisher websites. We believe that this is an important step forward for the field of recommendation systems research, that could open up an avenue of collaboration between the recommender systems and reinforcement learning communities and lead to better alignment between offline and online performance metrics.