 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Realistic Synthetic User-Generated Content: A Scaffolding Approach to Generating Online Discussions
Aug 15, 2024

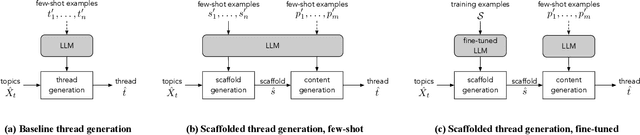

The emergence of synthetic data represents a pivotal shift in modern machine learning, offering a solution to satisfy the need for large volumes of data in domains where real data is scarce, highly private, or difficult to obtain. We investigate the feasibility of creating realistic, large-scale synthetic datasets of user-generated content, noting that such content is increasingly prevalent and a source of frequently sought information. Large language models (LLMs) offer a starting point for generating synthetic social media discussion threads, due to their ability to produce diverse responses that typify online interactions. However, as we demonstrate, straightforward application of LLMs yields limited success in capturing the complex structure of online discussions, and standard prompting mechanisms lack sufficient control. We therefore propose a multi-step generation process, predicated on the idea of creating compact representations of discussion threads, referred to as scaffolds. Our framework is generic yet adaptable to the unique characteristics of specific social media platforms. We demonstrate its feasibility using data from two distinct online discussion platforms. To address the fundamental challenge of ensuring the representativeness and realism of synthetic data, we propose a portfolio of evaluation measures to compare various instantiations of our framework.
SocialQuotes: Learning Contextual Roles of Social Media Quotes on the Web
Jul 22, 2024Web authors frequently embed social media to support and enrich their content, creating the potential to derive web-based, cross-platform social media representations that can enable more effective social media retrieval systems and richer scientific analyses. As step toward such capabilities, we introduce a novel language modeling framework that enables automatic annotation of roles that social media entities play in their embedded web context. Using related communication theory, we liken social media embeddings to quotes, formalize the page context as structured natural language signals, and identify a taxonomy of roles for quotes within the page context. We release SocialQuotes, a new data set built from the Common Crawl of over 32 million social quotes, 8.3k of them with crowdsourced quote annotations. Using SocialQuotes and the accompanying annotations, we provide a role classification case study, showing reasonable performance with modern-day LLMs, and exposing explainable aspects of our framework via page content ablations. We also classify a large batch of un-annotated quotes, revealing interesting cross-domain, cross-platform role distributions on the web.
Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences
Jul 26, 2023Traditional recommender systems leverage users' item preference history to recommend novel content that users may like. However, modern dialog interfaces that allow users to express language-based preferences offer a fundamentally different modality for preference input. Inspired by recent successes of prompting paradigms for large language models (LLMs), we study their use for making recommendations from both item-based and language-based preferences in comparison to state-of-the-art item-based collaborative filtering (CF) methods. To support this investigation, we collect a new dataset consisting of both item-based and language-based preferences elicited from users along with their ratings on a variety of (biased) recommended items and (unbiased) random items. Among numerous experimental results, we find that LLMs provide competitive recommendation performance for pure language-based preferences (no item preferences) in the near cold-start case in comparison to item-based CF methods, despite having no supervised training for this specific task (zero-shot) or only a few labels (few-shot). This is particularly promising as language-based preference representations are more explainable and scrutable than item-based or vector-based representations.
Measuring the Impact of Explanation Bias: A Study of Natural Language Justifications for Recommender Systems
Mar 16, 2023Despite the potential impact of explanations on decision making, there is a lack of research on quantifying their effect on users' choices. This paper presents an experimental protocol for measuring the degree to which positively or negatively biased explanations can lead to users choosing suboptimal recommendations. Key elements of this protocol include a preference elicitation stage to allow for personalizing recommendations, manual identification and extraction of item aspects from reviews, and a controlled method for introducing bias through the combination of both positive and negative aspects. We study explanations in two different textual formats: as a list of item aspects and as fluent natural language text. Through a user study with 129 participants, we demonstrate that explanations can significantly affect users' selections and that these findings generalize across explanation formats.
Beyond Single Items: Exploring User Preferences in Item Sets with the Conversational Playlist Curation Dataset
Mar 13, 2023Users in consumption domains, like music, are often able to more efficiently provide preferences over a set of items (e.g. a playlist or radio) than over single items (e.g. songs). Unfortunately, this is an underexplored area of research, with most existing recommendation systems limited to understanding preferences over single items. Curating an item set exponentiates the search space that recommender systems must consider (all subsets of items!): this motivates conversational approaches-where users explicitly state or refine their preferences and systems elicit preferences in natural language-as an efficient way to understand user needs. We call this task conversational item set curation and present a novel data collection methodology that efficiently collects realistic preferences about item sets in a conversational setting by observing both item-level and set-level feedback. We apply this methodology to music recommendation to build the Conversational Playlist Curation Dataset (CPCD), where we show that it leads raters to express preferences that would not be otherwise expressed. Finally, we propose a wide range of conversational retrieval models as baselines for this task and evaluate them on the dataset.
Generating Synthetic Data for Conversational Music Recommendation Using Random Walks and Language Models
Jan 27, 2023



Conversational recommendation systems (CRSs) enable users to use natural language feedback to control their recommendations, overcoming many of the challenges of traditional recommendation systems. However, the practical adoption of CRSs remains limited due to a lack of rich and diverse conversational training data that pairs user utterances with recommendations. To address this problem, we introduce a new method to generate synthetic training data by transforming curated item collections, such as playlists or movie watch lists, into item-seeking conversations. First, we use a biased random walk to generate a sequence of slates, or sets of item recommendations; then, we use a language model to generate corresponding user utterances. We demonstrate our approach by generating a conversational music recommendation dataset with over one million conversations, which were found to be consistent with relevant recommendations by a crowdsourced evaluation. Using the synthetic data to train a CRS, we significantly outperform standard retrieval baselines in offline and online evaluations.
Resolving Indirect Referring Expressions for Entity Selection
Dec 21, 2022Recent advances in language modeling have enabled new conversational systems. In particular, it is often desirable for people to make choices among specified options when using such systems. We address the problem of reference resolution, when people use natural expressions to choose between real world entities. For example, given the choice `Should we make a Simnel cake or a Pandan cake?' a natural response from a non-expert may be indirect: `let's make the green one'. Reference resolution has been little studied with natural expressions, thus robustly understanding such language has large potential for improving naturalness in dialog, recommendation, and search systems. We create AltEntities (Alternative Entities), a new public dataset of entity pairs and utterances, and develop models for the disambiguation problem. Consisting of 42K indirect referring expressions across three domains, it enables for the first time the study of how large language models can be adapted to this task. We find they achieve 82%-87% accuracy in realistic settings, which while reasonable also invites further advances.
On Natural Language User Profiles for Transparent and Scrutable Recommendation
May 19, 2022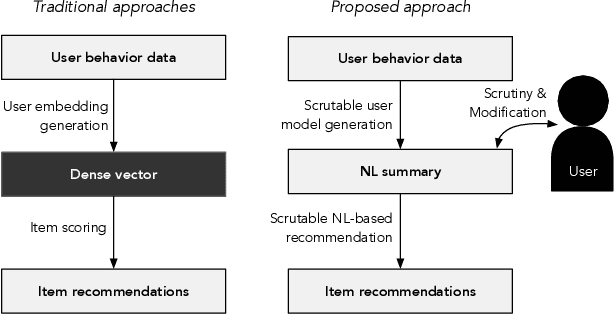



Natural interaction with recommendation and personalized search systems has received tremendous attention in recent years. We focus on the challenge of supporting people's understanding and control of these systems and explore a fundamentally new way of thinking about representation of knowledge in recommendation and personalization systems. Specifically, we argue that it may be both desirable and possible for algorithms that use natural language representations of users' preferences to be developed. We make the case that this could provide significantly greater transparency, as well as affordances for practical actionable interrogation of, and control over, recommendations. Moreover, we argue that such an approach, if successfully applied, may enable a major step towards systems that rely less on noisy implicit observations while increasing portability of knowledge of one's interests.
Conversational Information Seeking
Jan 21, 2022Conversational information seeking (CIS) is concerned with a sequence of interactions between one or more users and an information system. Interactions in CIS are primarily based on natural language dialogue, while they may include other types of interactions, such as click, touch, and body gestures. This monograph provides a thorough overview of CIS definitions, applications, interactions, interfaces, design, implementation, and evaluation. This monograph views CIS applications as including conversational search, conversational question answering, and conversational recommendation. Our aim is to provide an overview of past research related to CIS, introduce the current state-of-the-art in CIS, highlight the challenges still being faced in the community. and suggest future directions.
Soliciting User Preferences in Conversational Recommender Systems via Usage-related Questions
Nov 26, 2021

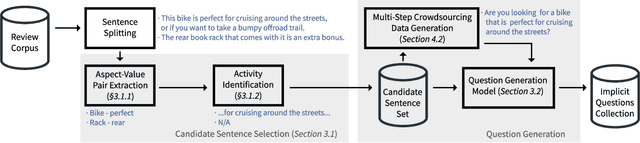
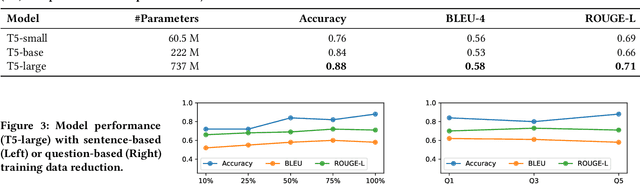
A key distinguishing feature of conversational recommender systems over traditional recommender systems is their ability to elicit user preferences using natural language. Currently, the predominant approach to preference elicitation is to ask questions directly about items or item attributes. These strategies do not perform well in cases where the user does not have sufficient knowledge of the target domain to answer such questions. Conversely, in a shopping setting, talking about the planned use of items does not present any difficulties, even for those that are new to a domain. In this paper, we propose a novel approach to preference elicitation by asking implicit questions based on item usage. Our approach consists of two main steps. First, we identify the sentences from a large review corpus that contain information about item usage. Then, we generate implicit preference elicitation questions from those sentences using a neural text-to-text model. The main contributions of this work also include a multi-stage data annotation protocol using crowdsourcing for collecting high-quality labeled training data for the neural model. We show that our approach is effective in selecting review sentences and transforming them to elicitation questions, even with limited training data. Additionally, we provide an analysis of patterns where the model does not perform optimally.