 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic and Semantic Control of Large Language Models via Sequential Monte Carlo
Apr 18, 2025



A wide range of LM applications require generating text that conforms to syntactic or semantic constraints. Imposing such constraints can be naturally framed as probabilistic conditioning, but exact generation from the resulting distribution -- which can differ substantially from the LM's base distribution -- is generally intractable. In this work, we develop an architecture for controlled LM generation based on sequential Monte Carlo (SMC). Our SMC framework allows us to flexibly incorporate domain- and problem-specific constraints at inference time, and efficiently reallocate computational resources in light of new information during the course of generation. By comparing to a number of alternatives and ablations on four challenging domains -- Python code generation for data science, text-to-SQL, goal inference, and molecule synthesis -- we demonstrate that, with little overhead, our approach allows small open-source language models to outperform models over 8x larger, as well as closed-source, fine-tuned ones. In support of the probabilistic perspective, we show that these performance improvements are driven by better approximation to the posterior distribution. Our system builds on the framework of Lew et al. (2023) and integrates with its language model probabilistic programming language, giving users a simple, programmable way to apply SMC to a broad variety of controlled generation problems.
Self-Steering Language Models
Apr 09, 2025While test-time reasoning enables language models to tackle complex tasks, searching or planning in natural language can be slow, costly, and error-prone. But even when LMs struggle to emulate the precise reasoning steps needed to solve a problem, they often excel at describing its abstract structure--both how to verify solutions and how to search for them. This paper introduces DisCIPL, a method for "self-steering" LMs where a Planner model generates a task-specific inference program that is executed by a population of Follower models. Our approach equips LMs with the ability to write recursive search procedures that guide LM inference, enabling new forms of verifiable and efficient reasoning. When instantiated with a small Follower (e.g., Llama-3.2-1B), DisCIPL matches (and sometimes outperforms) much larger models, including GPT-4o and o1, on challenging constrained generation tasks. In decoupling planning from execution, our work opens up a design space of highly-parallelized Monte Carlo inference strategies that outperform standard best-of-N sampling, require no finetuning, and can be implemented automatically by existing LMs.
Fast Controlled Generation from Language Models with Adaptive Weighted Rejection Sampling
Apr 07, 2025The dominant approach to generating from language models subject to some constraint is locally constrained decoding (LCD), incrementally sampling tokens at each time step such that the constraint is never violated. Typically, this is achieved through token masking: looping over the vocabulary and excluding non-conforming tokens. There are two important problems with this approach. (i) Evaluating the constraint on every token can be prohibitively expensive -- LM vocabularies often exceed $100,000$ tokens. (ii) LCD can distort the global distribution over strings, sampling tokens based only on local information, even if they lead down dead-end paths. This work introduces a new algorithm that addresses both these problems. First, to avoid evaluating a constraint on the full vocabulary at each step of generation, we propose an adaptive rejection sampling algorithm that typically requires orders of magnitude fewer constraint evaluations. Second, we show how this algorithm can be extended to produce low-variance, unbiased estimates of importance weights at a very small additional cost -- estimates that can be soundly used within previously proposed sequential Monte Carlo algorithms to correct for the myopic behavior of local constraint enforcement. Through extensive empirical evaluation in text-to-SQL, molecular synthesis, goal inference, pattern matching, and JSON domains, we show that our approach is superior to state-of-the-art baselines, supporting a broader class of constraints and improving both runtime and performance. Additional theoretical and empirical analyses show that our method's runtime efficiency is driven by its dynamic use of computation, scaling with the divergence between the unconstrained and constrained LM, and as a consequence, runtime improvements are greater for better models.
Probabilistic Programming with Programmable Variational Inference
Jun 22, 2024



Compared to the wide array of advanced Monte Carlo methods supported by modern probabilistic programming languages (PPLs), PPL support for variational inference (VI) is less developed: users are typically limited to a predefined selection of variational objectives and gradient estimators, which are implemented monolithically (and without formal correctness arguments) in PPL backends. In this paper, we propose a more modular approach to supporting variational inference in PPLs, based on compositional program transformation. In our approach, variational objectives are expressed as programs, that may employ first-class constructs for computing densities of and expected values under user-defined models and variational families. We then transform these programs systematically into unbiased gradient estimators for optimizing the objectives they define. Our design enables modular reasoning about many interacting concerns, including automatic differentiation, density accumulation, tracing, and the application of unbiased gradient estimation strategies. Additionally, relative to existing support for VI in PPLs, our design increases expressiveness along three axes: (1) it supports an open-ended set of user-defined variational objectives, rather than a fixed menu of options; (2) it supports a combinatorial space of gradient estimation strategies, many not automated by today's PPLs; and (3) it supports a broader class of models and variational families, because it supports constructs for approximate marginalization and normalization (previously introduced only for Monte Carlo inference). We implement our approach in an extension to the Gen probabilistic programming system (genjax.vi, implemented in JAX), and evaluate on several deep generative modeling tasks, showing minimal performance overhead vs. hand-coded implementations and performance competitive with well-established open-source PPLs.
Differentiating Metropolis-Hastings to Optimize Intractable Densities
Jun 30, 2023We develop an algorithm for automatic differentiation of Metropolis-Hastings samplers, allowing us to differentiate through probabilistic inference, even if the model has discrete components within it. Our approach fuses recent advances in stochastic automatic differentiation with traditional Markov chain coupling schemes, providing an unbiased and low-variance gradient estimator. This allows us to apply gradient-based optimization to objectives expressed as expectations over intractable target densities. We demonstrate our approach by finding an ambiguous observation in a Gaussian mixture model and by maximizing the specific heat in an Ising model.
From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought
Jun 23, 2023



How does language inform our downstream thinking? In particular, how do humans make meaning from language--and how can we leverage a theory of linguistic meaning to build machines that think in more human-like ways? In this paper, we propose rational meaning construction, a computational framework for language-informed thinking that combines neural language models with probabilistic models for rational inference. We frame linguistic meaning as a context-sensitive mapping from natural language into a probabilistic language of thought (PLoT)--a general-purpose symbolic substrate for generative world modeling. Our architecture integrates two computational tools that have not previously come together: we model thinking with probabilistic programs, an expressive representation for commonsense reasoning; and we model meaning construction with large language models (LLMs), which support broad-coverage translation from natural language utterances to code expressions in a probabilistic programming language. We illustrate our framework through examples covering four core domains from cognitive science: probabilistic reasoning, logical and relational reasoning, visual and physical reasoning, and social reasoning. In each, we show that LLMs can generate context-sensitive translations that capture pragmatically-appropriate linguistic meanings, while Bayesian inference with the generated programs supports coherent and robust commonsense reasoning. We extend our framework to integrate cognitively-motivated symbolic modules (physics simulators, graphics engines, and planning algorithms) to provide a unified commonsense thinking interface from language. Finally, we explore how language can drive the construction of world models themselves. We hope this work will provide a roadmap towards cognitive models and AI systems that synthesize the insights of both modern and classical computational perspectives.
Sequential Monte Carlo Steering of Large Language Models using Probabilistic Programs
Jun 05, 2023Even after fine-tuning and reinforcement learning, large language models (LLMs) can be difficult, if not impossible, to control reliably with prompts alone. We propose a new inference-time approach to enforcing syntactic and semantic constraints on the outputs of LLMs, called sequential Monte Carlo (SMC) steering. The key idea is to specify language generation tasks as posterior inference problems in a class of discrete probabilistic sequence models, and replace standard decoding with sequential Monte Carlo inference. For a computational cost similar to that of beam search, SMC can steer LLMs to solve diverse tasks, including infilling, generation under syntactic constraints, and prompt intersection. To facilitate experimentation with SMC steering, we present a probabilistic programming library, LLaMPPL (https://github.com/probcomp/LLaMPPL), for concisely specifying new generation tasks as language model probabilistic programs, and automating steering of LLaMA-family Transformers.
$ω$PAP Spaces: Reasoning Denotationally About Higher-Order, Recursive Probabilistic and Differentiable Programs
Feb 21, 2023



We introduce a new setting, the category of $\omega$PAP spaces, for reasoning denotationally about expressive differentiable and probabilistic programming languages. Our semantics is general enough to assign meanings to most practical probabilistic and differentiable programs, including those that use general recursion, higher-order functions, discontinuous primitives, and both discrete and continuous sampling. But crucially, it is also specific enough to exclude many pathological denotations, enabling us to establish new results about both deterministic differentiable programs and probabilistic programs. In the deterministic setting, we prove very general correctness theorems for automatic differentiation and its use within gradient descent. In the probabilistic setting, we establish the almost-everywhere differentiability of probabilistic programs' trace density functions, and the existence of convenient base measures for density computation in Monte Carlo inference. In some cases these results were previously known, but required detailed proofs with an operational flavor; by contrast, all our proofs work directly with programs' denotations.
Recursive Monte Carlo and Variational Inference with Auxiliary Variables
Mar 05, 2022

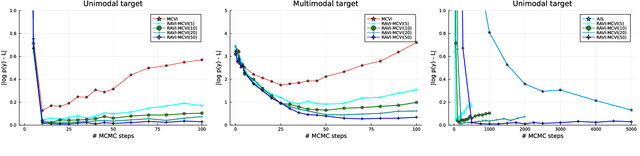

A key challenge in applying Monte Carlo and variational inference (VI) is the design of proposals and variational families that are flexible enough to closely approximate the posterior, but simple enough to admit tractable densities and variational bounds. This paper presents recursive auxiliary-variable inference (RAVI), a new framework for exploiting flexible proposals, for example based on involved simulations or stochastic optimization, within Monte Carlo and VI algorithms. The key idea is to estimate intractable proposal densities via meta-inference: additional Monte Carlo or variational inference targeting the proposal, rather than the model. RAVI generalizes and unifies several existing methods for inference with expressive approximating families, which we show correspond to specific choices of meta-inference algorithm, and provides new theory for analyzing their bias and variance. We illustrate RAVI's design framework and theorems by using them to analyze and improve upon Salimans et al. (2015)'s Markov Chain Variational Inference, and to design a novel sampler for Dirichlet process mixtures, achieving state-of-the-art results on a standard benchmark dataset from astronomy and on a challenging data-cleaning task with Medicare hospital data.
PClean: Bayesian Data Cleaning at Scale with Domain-Specific Probabilistic Programming
Aug 07, 2020
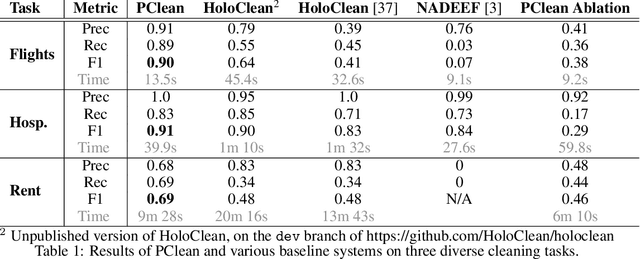

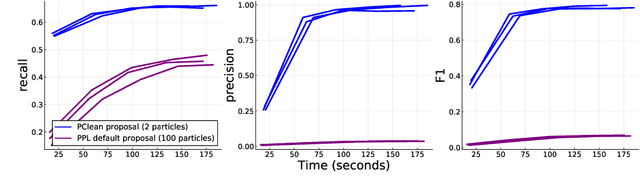
Data cleaning is naturally framed as probabilistic inference in a generative model, combining a prior distribution over ground-truth databases with a likelihood that models the noisy channel by which the data are filtered, corrupted, and joined to yield incomplete, dirty, and denormalized datasets. Based on this view, we present PClean, a unified generative modeling architecture for cleaning and normalizing dirty data in diverse domains. Given an unclean dataset and a probabilistic program encoding relevant domain knowledge, PClean learns a structured representation of the data as a relational database of interrelated objects, and uses this latent structure to impute missing values, identify duplicates, detect errors, and propose corrections in the original data table. PClean makes three modeling and inference contributions: (i) a domain-general non-parametric generative model of relational data, for inferring latent objects and their network of latent connections; (ii) a domain-specific probabilistic programming language, for encoding domain knowledge specific to each dataset being cleaned; and (iii) a domain-general inference engine that adapts to each PClean program by constructing data-driven proposals used in sequential Monte Carlo and particle Gibbs. We show empirically that short (< 50-line) PClean programs deliver higher accuracy than state-of-the-art data cleaning systems based on machine learning and weighted logic; that PClean's inference algorithm is faster than generic particle Gibbs inference for probabilistic programs; and that PClean scales to large real-world datasets with millions of rows.