 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaperon: A Peppered English-French Generative Language Model Suite
Oct 29, 2025We release Gaperon, a fully open suite of French-English-coding language models designed to advance transparency and reproducibility in large-scale model training. The Gaperon family includes 1.5B, 8B, and 24B parameter models trained on 2-4 trillion tokens, released with all elements of the training pipeline: French and English datasets filtered with a neural quality classifier, an efficient data curation and training framework, and hundreds of intermediate checkpoints. Through this work, we study how data filtering and contamination interact to shape both benchmark and generative performance. We find that filtering for linguistic quality enhances text fluency and coherence but yields subpar benchmark results, and that late deliberate contamination -- continuing training on data mixes that include test sets -- recovers competitive scores while only reasonably harming generation quality. We discuss how usual neural filtering can unintentionally amplify benchmark leakage. To support further research, we also introduce harmless data poisoning during pretraining, providing a realistic testbed for safety studies. By openly releasing all models, datasets, code, and checkpoints, Gaperon establishes a reproducible foundation for exploring the trade-offs between data curation, evaluation, safety, and openness in multilingual language model development.
Q-Filters: Leveraging QK Geometry for Efficient KV Cache Compression
Mar 04, 2025Autoregressive language models rely on a Key-Value (KV) Cache, which avoids re-computing past hidden states during generation, making it faster. As model sizes and context lengths grow, the KV Cache becomes a significant memory bottleneck, which calls for compression methods that limit its size during generation. In this paper, we discover surprising properties of Query (Q) and Key (K) vectors that allow us to efficiently approximate attention scores without computing the attention maps. We propose Q-Filters, a training-free KV Cache compression method that filters out less crucial Key-Value pairs based on a single context-agnostic projection. Contrarily to many alternatives, Q-Filters is compatible with FlashAttention, as it does not require direct access to attention weights. Experimental results in long-context settings demonstrate that Q-Filters is competitive with attention-based compression methods such as SnapKV in retrieval tasks while consistently outperforming efficient compression schemes such as Streaming-LLM in generation setups. Notably, Q-Filters achieves a 99% accuracy in the needle-in-a-haystack task with a x32 compression level while reducing the generation perplexity drop by up to 65% in text generation compared to Streaming-LLM.
CamemBERT 2.0: A Smarter French Language Model Aged to Perfection
Nov 13, 2024French language models, such as CamemBERT, have been widely adopted across industries for natural language processing (NLP) tasks, with models like CamemBERT seeing over 4 million downloads per month. However, these models face challenges due to temporal concept drift, where outdated training data leads to a decline in performance, especially when encountering new topics and terminology. This issue emphasizes the need for updated models that reflect current linguistic trends. In this paper, we introduce two new versions of the CamemBERT base model-CamemBERTav2 and CamemBERTv2-designed to address these challenges. CamemBERTav2 is based on the DeBERTaV3 architecture and makes use of the Replaced Token Detection (RTD) objective for better contextual understanding, while CamemBERTv2 is built on RoBERTa, which uses the Masked Language Modeling (MLM) objective. Both models are trained on a significantly larger and more recent dataset with longer context length and an updated tokenizer that enhances tokenization performance for French. We evaluate the performance of these models on both general-domain NLP tasks and domain-specific applications, such as medical field tasks, demonstrating their versatility and effectiveness across a range of use cases. Our results show that these updated models vastly outperform their predecessors, making them valuable tools for modern NLP systems. All our new models, as well as intermediate checkpoints, are made openly available on Huggingface.
Why do small language models underperform? Studying Language Model Saturation via the Softmax Bottleneck
Apr 11, 2024Recent advances in language modeling consist in pretraining highly parameterized neural networks on extremely large web-mined text corpora. Training and inference with such models can be costly in practice, which incentivizes the use of smaller counterparts. However, it has been observed that smaller models can suffer from saturation, characterized as a drop in performance at some advanced point in training followed by a plateau. In this paper, we find that such saturation can be explained by a mismatch between the hidden dimension of smaller models and the high rank of the target contextual probability distribution. This mismatch affects the performance of the linear prediction head used in such models through the well-known softmax bottleneck phenomenon. We measure the effect of the softmax bottleneck in various settings and find that models based on less than 1000 hidden dimensions tend to adopt degenerate latent representations in late pretraining, which leads to reduced evaluation performance.
On the Scaling Laws of Geographical Representation in Language Models
Mar 04, 2024



Language models have long been shown to embed geographical information in their hidden representations. This line of work has recently been revisited by extending this result to Large Language Models (LLMs). In this paper, we propose to fill the gap between well-established and recent literature by observing how geographical knowledge evolves when scaling language models. We show that geographical knowledge is observable even for tiny models, and that it scales consistently as we increase the model size. Notably, we observe that larger language models cannot mitigate the geographical bias that is inherent to the training data.
Anisotropy Is Inherent to Self-Attention in Transformers
Jan 24, 2024



The representation degeneration problem is a phenomenon that is widely observed among self-supervised learning methods based on Transformers. In NLP, it takes the form of anisotropy, a singular property of hidden representations which makes them unexpectedly close to each other in terms of angular distance (cosine-similarity). Some recent works tend to show that anisotropy is a consequence of optimizing the cross-entropy loss on long-tailed distributions of tokens. We show in this paper that anisotropy can also be observed empirically in language models with specific objectives that should not suffer directly from the same consequences. We also show that the anisotropy problem extends to Transformers trained on other modalities. Our observations suggest that anisotropy is actually inherent to Transformers-based models.
Headless Language Models: Learning without Predicting with Contrastive Weight Tying
Sep 15, 2023



Self-supervised pre-training of language models usually consists in predicting probability distributions over extensive token vocabularies. In this study, we propose an innovative method that shifts away from probability prediction and instead focuses on reconstructing input embeddings in a contrastive fashion via Constrastive Weight Tying (CWT). We apply this approach to pretrain Headless Language Models in both monolingual and multilingual contexts. Our method offers practical advantages, substantially reducing training computational requirements by up to 20 times, while simultaneously enhancing downstream performance and data efficiency. We observe a significant +1.6 GLUE score increase and a notable +2.7 LAMBADA accuracy improvement compared to classical LMs within similar compute budgets.
Is Anisotropy Inherent to Transformers?
Jun 13, 2023The representation degeneration problem is a phenomenon that is widely observed among self-supervised learning methods based on Transformers. In NLP, it takes the form of anisotropy, a singular property of hidden representations which makes them unexpectedly close to each other in terms of angular distance (cosine-similarity). Some recent works tend to show that anisotropy is a consequence of optimizing the cross-entropy loss on long-tailed distributions of tokens. We show in this paper that anisotropy can also be observed empirically in language models with specific objectives that should not suffer directly from the same consequences. We also show that the anisotropy problem extends to Transformers trained on other modalities. Our observations tend to demonstrate that anisotropy might actually be inherent to Transformers-based models.
MANTa: Efficient Gradient-Based Tokenization for Robust End-to-End Language Modeling
Dec 14, 2022



Static subword tokenization algorithms have been an essential component of recent works on language modeling. However, their static nature results in important flaws that degrade the models' downstream performance and robustness. In this work, we propose MANTa, a Module for Adaptive Neural TokenizAtion. MANTa is a differentiable tokenizer trained end-to-end with the language model. The resulting system offers a trade-off between the expressiveness of byte-level models and the speed of models trained using subword tokenization. In addition, our tokenizer is highly explainable since it produces an explicit segmentation of sequences into blocks. We evaluate our pre-trained model on several English datasets from different domains as well as on synthetic noise. We find that MANTa improves robustness to character perturbations and out-of-domain data. We then show that MANTa performs comparably to other models on the general-domain GLUE benchmark. Finally, we show that it is considerably faster than strictly byte-level models.
Clustering-based Automatic Construction of Legal Entity Knowledge Base from Contracts
Dec 07, 2020
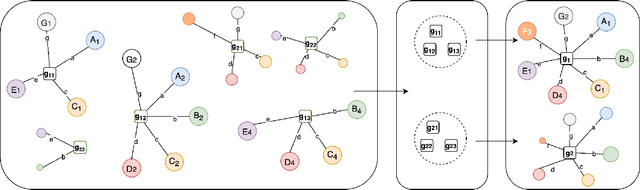

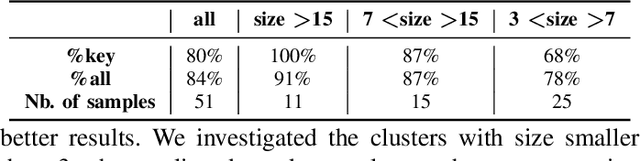
In contract analysis and contract automation, a knowledge base (KB) of legal entities is fundamental for performing tasks such as contract verification, contract generation and contract analytic. However, such a KB does not always exist nor can be produced in a short time. In this paper, we propose a clustering-based approach to automatically generate a reliable knowledge base of legal entities from given contracts without any supplemental references. The proposed method is robust to different types of errors brought by pre-processing such as Optical Character Recognition (OCR) and Named Entity Recognition (NER), as well as editing errors such as typos. We evaluate our method on a dataset that consists of 800 real contracts with various qualities from 15 clients. Compared to the collected ground-truth data, our method is able to recall 84\% of the knowledge.