 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Large Language Models for Molecular Property Prediction: Distilling Knowledge from Specialist Models
Mar 12, 2026Molecular Property Prediction (MPP) is a central task in drug discovery. While Large Language Models (LLMs) show promise as generalist models for MPP, their current performance remains below the threshold for practical adoption. We propose TreeKD, a novel knowledge distillation method that transfers complementary knowledge from tree-based specialist models into LLMs. Our approach trains specialist decision trees on functional group features, then verbalizes their learned predictive rules as natural language to enable rule-augmented context learning. This enables LLMs to leverage structural insights that are difficult to extract from SMILES strings alone. We further introduce rule-consistency, a test-time scaling technique inspired by bagging that ensembles predictions across diverse rules from a Random Forest. Experiments on 22 ADMET properties from the TDC benchmark demonstrate that TreeKD substantially improves LLM performance, narrowing the gap with SOTA specialist models and advancing toward practical generalist models for molecular property prediction.
Agentic Design Patterns: A System-Theoretic Framework
Jan 27, 2026With the development of foundation model (FM), agentic AI systems are getting more attention, yet their inherent issues like hallucination and poor reasoning, coupled with the frequent ad-hoc nature of system design, lead to unreliable and brittle applications. Existing efforts to characterise agentic design patterns often lack a rigorous systems-theoretic foundation, resulting in high-level or convenience-based taxonomies that are difficult to implement. This paper addresses this gap by introducing a principled methodology for engineering robust AI agents. We propose two primary contributions: first, a novel system-theoretic framework that deconstructs an agentic AI system into five core, interacting functional subsystems: Reasoning & World Model, Perception & Grounding, Action Execution, Learning & Adaptation, and Inter-Agent Communication. Second, derived from this architecture and directly mapped to a comprehensive taxonomy of agentic challenges, we present a collection of 12 agentic design patterns. These patterns - categorised as Foundational, Cognitive & Decisional, Execution & Interaction, and Adaptive & Learning - offer reusable, structural solutions to recurring problems in agent design. The utility of the framework is demonstrated by a case study on the ReAct framework, showing how the proposed patterns can rectify systemic architectural deficiencies. This work provides a foundational language and a structured methodology to standardise agentic design communication among researchers and engineers, leading to more modular, understandable, and reliable autonomous systems.
WaveGAS: Waveform Relaxation for Scaling Graph Neural Networks
Feb 27, 2025



With the ever-growing size of real-world graphs, numerous techniques to overcome resource limitations when training Graph Neural Networks (GNNs) have been developed. One such approach, GNNAutoScale (GAS), uses graph partitioning to enable training under constrained GPU memory. GAS also stores historical embedding vectors, which are retrieved from one-hop neighbors in other partitions, ensuring critical information is captured across partition boundaries. The historical embeddings which come from the previous training iteration are stale compared to the GAS estimated embeddings, resulting in approximation errors of the training algorithm. Furthermore, these errors accumulate over multiple layers, leading to suboptimal node embeddings. To address this shortcoming, we propose two enhancements: first, WaveGAS, inspired by waveform relaxation, performs multiple forward passes within GAS before the backward pass, refining the approximation of historical embeddings and gradients to improve accuracy; second, a gradient-tracking method that stores and utilizes more accurate historical gradients during training. Empirical results show that WaveGAS enhances GAS and achieves better accuracy, even outperforming methods that train on full graphs, thanks to its robust estimation of node embeddings.
TabularFM: An Open Framework For Tabular Foundational Models
Jun 18, 2024Foundational models (FMs), pretrained on extensive datasets using self-supervised techniques, are capable of learning generalized patterns from large amounts of data. This reduces the need for extensive labeled datasets for each new task, saving both time and resources by leveraging the broad knowledge base established during pretraining. Most research on FMs has primarily focused on unstructured data, such as text and images, or semi-structured data, like time-series. However, there has been limited attention to structured data, such as tabular data, which, despite its prevalence, remains under-studied due to a lack of clean datasets and insufficient research on the transferability of FMs for various tabular data tasks. In response to this gap, we introduce a framework called TabularFM, which incorporates state-of-the-art methods for developing FMs specifically for tabular data. This includes variations of neural architectures such as GANs, VAEs, and Transformers. We have curated a million of tabular datasets and released cleaned versions to facilitate the development of tabular FMs. We pretrained FMs on this curated data, benchmarked various learning methods on these datasets, and released the pretrained models along with leaderboards for future comparative studies. Our fully open-sourced system provides a comprehensive analysis of the transferability of tabular FMs. By releasing these datasets, pretrained models, and leaderboards, we aim to enhance the validity and usability of tabular FMs in the near future.
Description Boosting for Zero-Shot Entity and Relation Classification
Jun 04, 2024



Zero-shot entity and relation classification models leverage available external information of unseen classes -- e.g., textual descriptions -- to annotate input text data. Thanks to the minimum data requirement, Zero-Shot Learning (ZSL) methods have high value in practice, especially in applications where labeled data is scarce. Even though recent research in ZSL has demonstrated significant results, our analysis reveals that those methods are sensitive to provided textual descriptions of entities (or relations). Even a minor modification of descriptions can lead to a change in the decision boundary between entity (or relation) classes. In this paper, we formally define the problem of identifying effective descriptions for zero shot inference. We propose a strategy for generating variations of an initial description, a heuristic for ranking them and an ensemble method capable of boosting the predictions of zero-shot models through description enhancement. Empirical results on four different entity and relation classification datasets show that our proposed method outperform existing approaches and achieve new SOTA results on these datasets under the ZSL settings. The source code of the proposed solutions and the evaluation framework are open-sourced.
Zshot: An Open-source Framework for Zero-Shot Named Entity Recognition and Relation Extraction
Jul 25, 2023The Zero-Shot Learning (ZSL) task pertains to the identification of entities or relations in texts that were not seen during training. ZSL has emerged as a critical research area due to the scarcity of labeled data in specific domains, and its applications have grown significantly in recent years. With the advent of large pretrained language models, several novel methods have been proposed, resulting in substantial improvements in ZSL performance. There is a growing demand, both in the research community and industry, for a comprehensive ZSL framework that facilitates the development and accessibility of the latest methods and pretrained models.In this study, we propose a novel ZSL framework called Zshot that aims to address the aforementioned challenges. Our primary objective is to provide a platform that allows researchers to compare different state-of-the-art ZSL methods with standard benchmark datasets. Additionally, we have designed our framework to support the industry with readily available APIs for production under the standard SpaCy NLP pipeline. Our API is extendible and evaluable, moreover, we include numerous enhancements such as boosting the accuracy with pipeline ensembling and visualization utilities available as a SpaCy extension.
* Accepted at ACL 2023
Otter-Knowledge: benchmarks of multimodal knowledge graph representation learning from different sources for drug discovery
Jun 23, 2023Recent research in representation learning utilizes large databases of proteins or molecules to acquire knowledge of drug and protein structures through unsupervised learning techniques. These pre-trained representations have proven to significantly enhance the accuracy of subsequent tasks, such as predicting the affinity between drugs and target proteins. In this study, we demonstrate that by incorporating knowledge graphs from diverse sources and modalities into the sequences or SMILES representation, we can further enrich the representation and achieve state-of-the-art results on established benchmark datasets. We provide preprocessed and integrated data obtained from 7 public sources, which encompass over 30M triples. Additionally, we make available the pre-trained models based on this data, along with the reported outcomes of their performance on three widely-used benchmark datasets for drug-target binding affinity prediction found in the Therapeutic Data Commons (TDC) benchmarks. Additionally, we make the source code for training models on benchmark datasets publicly available. Our objective in releasing these pre-trained models, accompanied by clean data for model pretraining and benchmark results, is to encourage research in knowledge-enhanced representation learning.
Evaluating Robustness of Cooperative MARL: A Model-based Approach
Feb 07, 2022



In recent years, a proliferation of methods were developed for cooperative multi-agent reinforcement learning (c-MARL). However, the robustness of c-MARL agents against adversarial attacks has been rarely explored. In this paper, we propose to evaluate the robustness of c-MARL agents via a model-based approach. Our proposed formulation can craft stronger adversarial state perturbations of c-MARL agents(s) to lower total team rewards more than existing model-free approaches. In addition, we propose the first victim-agent selection strategy which allows us to develop even stronger adversarial attack. Numerical experiments on multi-agent MuJoCo benchmarks illustrate the advantage of our approach over other baselines. The proposed model-based attack consistently outperforms other baselines in all tested environments.
Ensembling Graph Predictions for AMR Parsing
Oct 18, 2021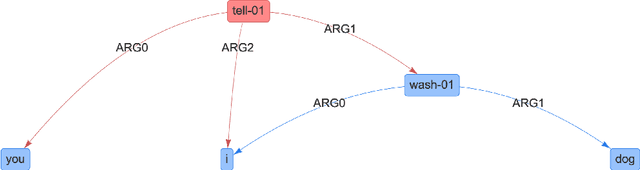
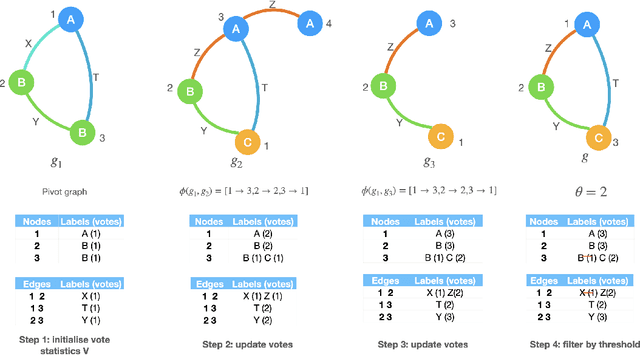
In many machine learning tasks, models are trained to predict structure data such as graphs. For example, in natural language processing, it is very common to parse texts into dependency trees or abstract meaning representation (AMR) graphs. On the other hand, ensemble methods combine predictions from multiple models to create a new one that is more robust and accurate than individual predictions. In the literature, there are many ensembling techniques proposed for classification or regression problems, however, ensemble graph prediction has not been studied thoroughly. In this work, we formalize this problem as mining the largest graph that is the most supported by a collection of graph predictions. As the problem is NP-Hard, we propose an efficient heuristic algorithm to approximate the optimal solution. To validate our approach, we carried out experiments in AMR parsing problems. The experimental results demonstrate that the proposed approach can combine the strength of state-of-the-art AMR parsers to create new predictions that are more accurate than any individual models in five standard benchmark datasets.
Neural Unification for Logic Reasoning over Natural Language
Sep 17, 2021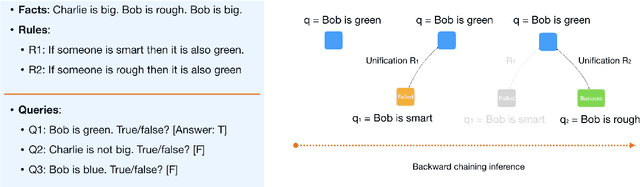
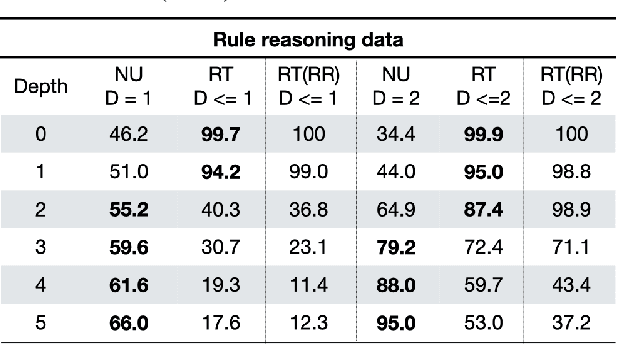
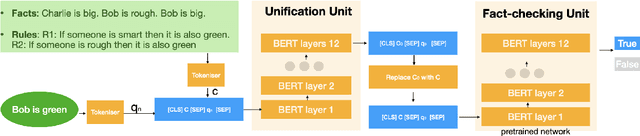

Automated Theorem Proving (ATP) deals with the development of computer programs being able to show that some conjectures (queries) are a logical consequence of a set of axioms (facts and rules). There exists several successful ATPs where conjectures and axioms are formally provided (e.g. formalised as First Order Logic formulas). Recent approaches, such as (Clark et al., 2020), have proposed transformer-based architectures for deriving conjectures given axioms expressed in natural language (English). The conjecture is verified through a binary text classifier, where the transformers model is trained to predict the truth value of a conjecture given the axioms. The RuleTaker approach of (Clark et al., 2020) achieves appealing results both in terms of accuracy and in the ability to generalize, showing that when the model is trained with deep enough queries (at least 3 inference steps), the transformers are able to correctly answer the majority of queries (97.6%) that require up to 5 inference steps. In this work we propose a new architecture, namely the Neural Unifier, and a relative training procedure, which achieves state-of-the-art results in term of generalisation, showing that mimicking a well-known inference procedure, the backward chaining, it is possible to answer deep queries even when the model is trained only on shallow ones. The approach is demonstrated in experiments using a diverse set of benchmark data.