 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoForest: Automatically Generating Forest Plots from Biomedical Studies with End-to-End Evidence Extraction and Synthesis
Jun 01, 2026Systematic reviews rely on forest plots to synthesise quantitative evidence across biomedical studies, but generating them remains a fragmented and labour-intensive process. Researchers must interpret complex clinical texts, manually extract outcome data from trials, define appropriate interventions and comparators, harmonise inconsistent study designs, and carry out meta-analytic computations-typically using specialised software that demands structured inputs and domain expertise. While recent work has demonstrated that large language models can extract study-level data from unstructured text, no existing system automates the complete pipeline from raw documents to synthesised forest plots. To address this gap, we introduce AutoForest, the first end-to-end system that generates publication-ready forest plots directly from biomedical papers. Given one or more study papers, AutoForest automatically suggests ICO (Intervention, Comparator, Outcome) elements, extracts outcome data, performs statistical synthesis, and renders the final forest plot. We describe the system architecture, user interface and demonstrate its effectiveness on real-world examples through a user study involving clinicians, showing how AutoForest can accelerate evidence synthesis and substantially lower the barrier to conducting meta-analyses.
Enhancing Study-Level Inference from Clinical Trial Papers via RL-based Numeric Reasoning
May 28, 2025Systematic reviews in medicine play a critical role in evidence-based decision-making by aggregating findings from multiple studies. A central bottleneck in automating this process is extracting numeric evidence and determining study-level conclusions for specific outcomes and comparisons. Prior work has framed this problem as a textual inference task by retrieving relevant content fragments and inferring conclusions from them. However, such approaches often rely on shallow textual cues and fail to capture the underlying numeric reasoning behind expert assessments. In this work, we conceptualise the problem as one of quantitative reasoning. Rather than inferring conclusions from surface text, we extract structured numerical evidence (e.g., event counts or standard deviations) and apply domain knowledge informed logic to derive outcome-specific conclusions. We develop a numeric reasoning system composed of a numeric data extraction model and an effect estimate component, enabling more accurate and interpretable inference aligned with the domain expert principles. We train the numeric data extraction model using different strategies, including supervised fine-tuning (SFT) and reinforcement learning (RL) with a new value reward model. When evaluated on the CochraneForest benchmark, our best-performing approach -- using RL to train a small-scale number extraction model -- yields up to a 21% absolute improvement in F1 score over retrieval-based systems and outperforms general-purpose LLMs of over 400B parameters by up to 9%. Our results demonstrate the promise of reasoning-driven approaches for automating systematic evidence synthesis.
Query-driven Document-level Scientific Evidence Extraction from Biomedical Studies
May 09, 2025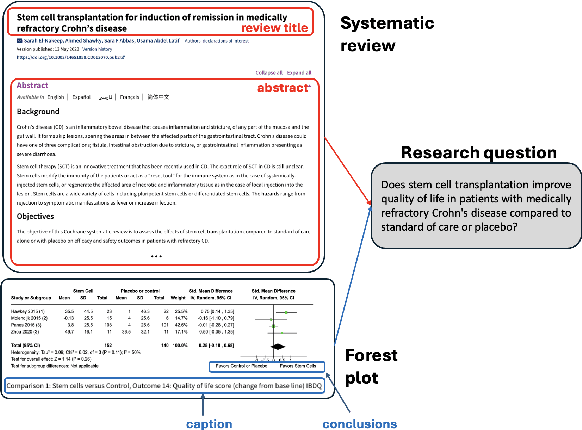
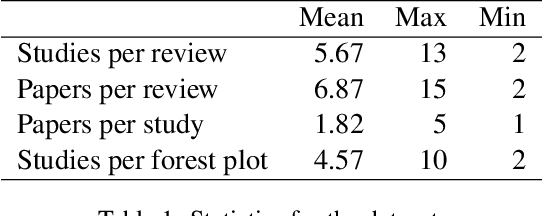
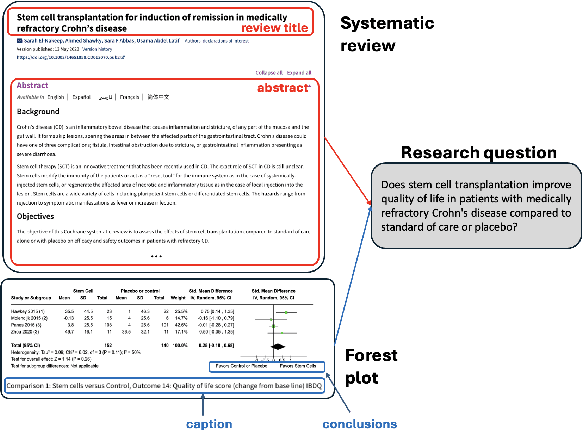
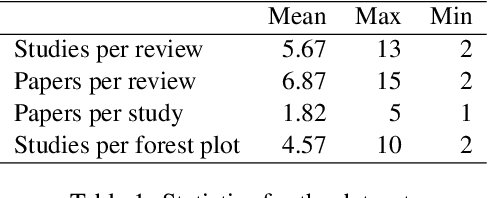
Extracting scientific evidence from biomedical studies for clinical research questions (e.g., Does stem cell transplantation improve quality of life in patients with medically refractory Crohn's disease compared to placebo?) is a crucial step in synthesising biomedical evidence. In this paper, we focus on the task of document-level scientific evidence extraction for clinical questions with conflicting evidence. To support this task, we create a dataset called CochraneForest, leveraging forest plots from Cochrane systematic reviews. It comprises 202 annotated forest plots, associated clinical research questions, full texts of studies, and study-specific conclusions. Building on CochraneForest, we propose URCA (Uniform Retrieval Clustered Augmentation), a retrieval-augmented generation framework designed to tackle the unique challenges of evidence extraction. Our experiments show that URCA outperforms the best existing methods by up to 10.3% in F1 score on this task. However, the results also underscore the complexity of CochraneForest, establishing it as a challenging testbed for advancing automated evidence synthesis systems.