 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokaMind: A Multi-Modal Transformer Foundation Model for Tokamak Plasma Dynamics
Feb 16, 2026We present TokaMind, an open-source foundation model framework for fusion plasma modeling, based on a Multi-Modal Transformer (MMT) and trained on heterogeneous tokamak diagnostics from the publicly available MAST dataset. TokaMind supports multiple data modalities (time-series, 2D profiles, and videos) with different sampling rates, robust missing-signal handling, and efficient task adaptation via selectively loading and freezing four model components. To represent multi-modal signals, we use a training-free Discrete Cosine Transform embedding (DCT3D) and provide a clean interface for alternative embeddings (e.g., Variational Autoencoders - VAEs). We evaluate TokaMind on the recently introduced MAST benchmark TokaMark, comparing training and embedding strategies. Our results show that fine-tuned TokaMind outperforms the benchmark baseline on all but one task, and that, for several tasks, lightweight fine-tuning yields better performance than training the same architecture from scratch under a matched epoch budget. These findings highlight the benefits of multi-modal pretraining for tokamak plasma dynamics and provide a practical, extensible foundation for future fusion modeling tasks. Training code and model weights will be made publicly available.
TokaMark: A Comprehensive Benchmark for MAST Tokamak Plasma Models
Feb 12, 2026Development and operation of commercially viable fusion energy reactors such as tokamaks require accurate predictions of plasma dynamics from sparse, noisy, and incomplete sensors readings. The complexity of the underlying physics and the heterogeneity of experimental data pose formidable challenges for conventional numerical methods, while simultaneously highlight the promise of modern data-native AI approaches. A major obstacle in realizing this potential is, however, the lack of curated, openly available datasets and standardized benchmarks. Existing fusion datasets are scarce, fragmented across institutions, facility-specific, and inconsistently annotated, which limits reproducibility and prevents a fair and scalable comparison of AI approaches. In this paper, we introduce TokaMark, a structured benchmark to evaluate AI models on real experimental data collected from the Mega Ampere Spherical Tokamak (MAST). TokaMark provides a comprehensive suite of tools designed to (i) unify access to multi-modal heterogeneous fusion data, and (ii) harmonize formats, metadata, temporal alignment and evaluation protocols to enable consistent cross-model and cross-task comparisons. The benchmark includes a curated list of 14 tasks spanning a range of physical mechanisms, exploiting a variety of diagnostics and covering multiple operational use cases. A baseline model is provided to facilitate transparent comparison and validation within a unified framework. By establishing a unified benchmark for both the fusion and AI-for-science communities, TokaMark aims to accelerate progress in data-driven AI-based plasma modeling, contributing to the broader goal of achieving sustainable and stable fusion energy. The benchmark, documentation, and tooling will be fully open sourced upon acceptance to encourage community adoption and contribution.
Forging Time Series with Language: A Large Language Model Approach to Synthetic Data Generation
May 21, 2025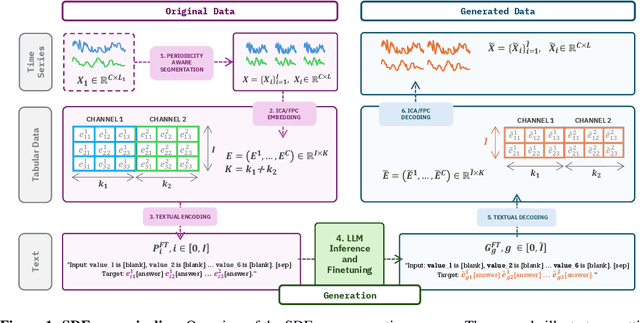
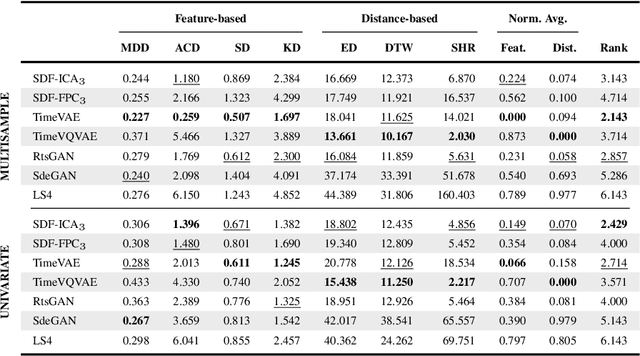
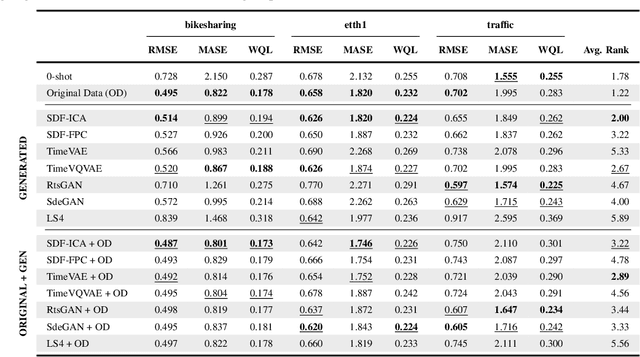
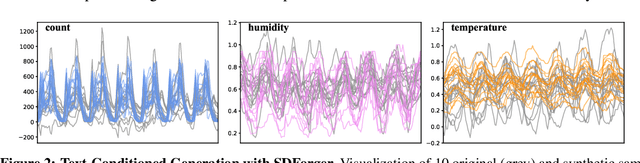
SDForger is a flexible and efficient framework for generating high-quality multivariate time series using LLMs. Leveraging a compact data representation, SDForger provides synthetic time series generation from a few samples and low-computation fine-tuning of any autoregressive LLM. Specifically, the framework transforms univariate and multivariate signals into tabular embeddings, which are then encoded into text and used to fine-tune the LLM. At inference, new textual embeddings are sampled and decoded into synthetic time series that retain the original data's statistical properties and temporal dynamics. Across a diverse range of datasets, SDForger outperforms existing generative models in many scenarios, both in similarity-based evaluations and downstream forecasting tasks. By enabling textual conditioning in the generation process, SDForger paves the way for multimodal modeling and the streamlined integration of time series with textual information. SDForger source code will be open-sourced soon.
Functional Graph Convolutional Networks: A unified multi-task and multi-modal learning framework to facilitate health and social-care insights
Mar 27, 2024



This paper introduces a novel Functional Graph Convolutional Network (funGCN) framework that combines Functional Data Analysis and Graph Convolutional Networks to address the complexities of multi-task and multi-modal learning in digital health and longitudinal studies. With the growing importance of health solutions to improve health care and social support, ensure healthy lives, and promote well-being at all ages, funGCN offers a unified approach to handle multivariate longitudinal data for multiple entities and ensures interpretability even with small sample sizes. Key innovations include task-specific embedding components that manage different data types, the ability to perform classification, regression, and forecasting, and the creation of a knowledge graph for insightful data interpretation. The efficacy of funGCN is validated through simulation experiments and a real-data application.