 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022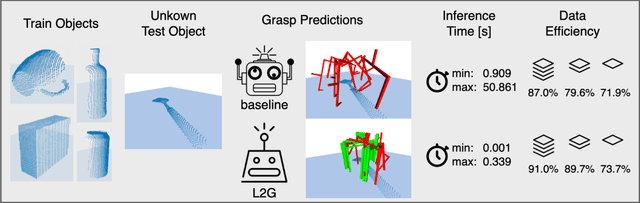
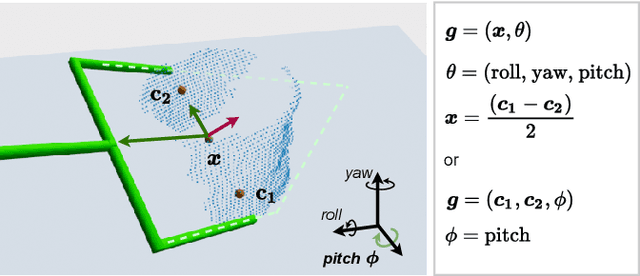
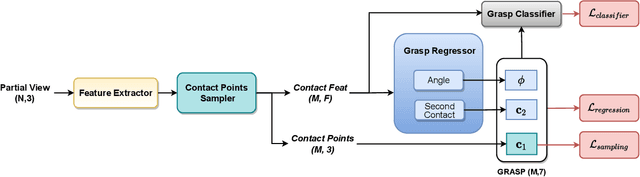
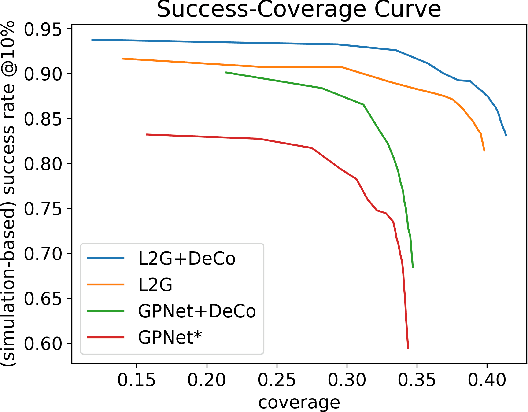
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.
Model-Based Image Signal Processors via Learnable Dictionaries
Jan 10, 2022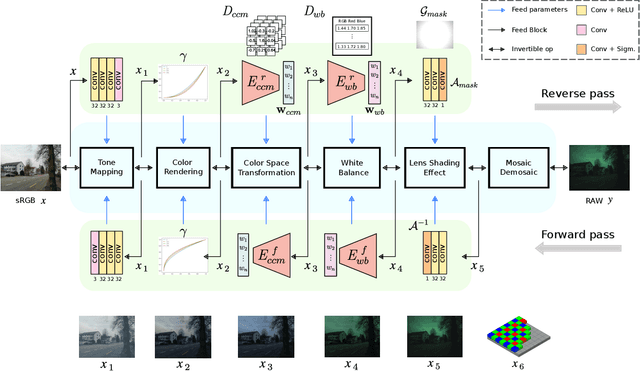
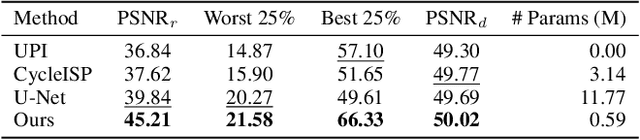
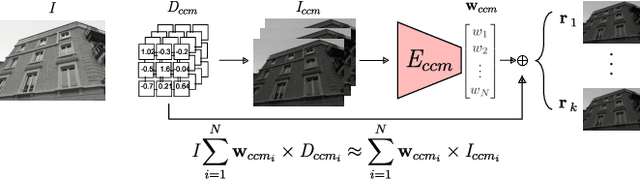
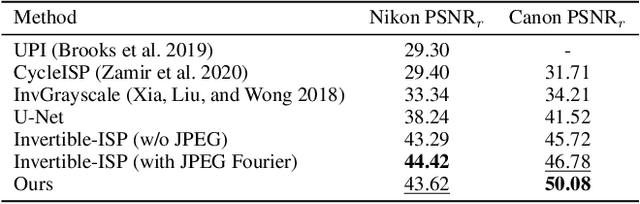
Digital cameras transform sensor RAW readings into RGB images by means of their Image Signal Processor (ISP). Computational photography tasks such as image denoising and colour constancy are commonly performed in the RAW domain, in part due to the inherent hardware design, but also due to the appealing simplicity of noise statistics that result from the direct sensor readings. Despite this, the availability of RAW images is limited in comparison with the abundance and diversity of available RGB data. Recent approaches have attempted to bridge this gap by estimating the RGB to RAW mapping: handcrafted model-based methods that are interpretable and controllable usually require manual parameter fine-tuning, while end-to-end learnable neural networks require large amounts of training data, at times with complex training procedures, and generally lack interpretability and parametric control. Towards addressing these existing limitations, we present a novel hybrid model-based and data-driven ISP that builds on canonical ISP operations and is both learnable and interpretable. Our proposed invertible model, capable of bidirectional mapping between RAW and RGB domains, employs end-to-end learning of rich parameter representations, i.e. dictionaries, that are free from direct parametric supervision and additionally enable simple and plausible data augmentation. We evidence the value of our data generation process by extensive experiments under both RAW image reconstruction and RAW image denoising tasks, obtaining state-of-the-art performance in both. Additionally, we show that our ISP can learn meaningful mappings from few data samples, and that denoising models trained with our dictionary-based data augmentation are competitive despite having only few or zero ground-truth labels.
FlexHDR: Modelling Alignment and Exposure Uncertainties for Flexible HDR Imaging
Jan 07, 2022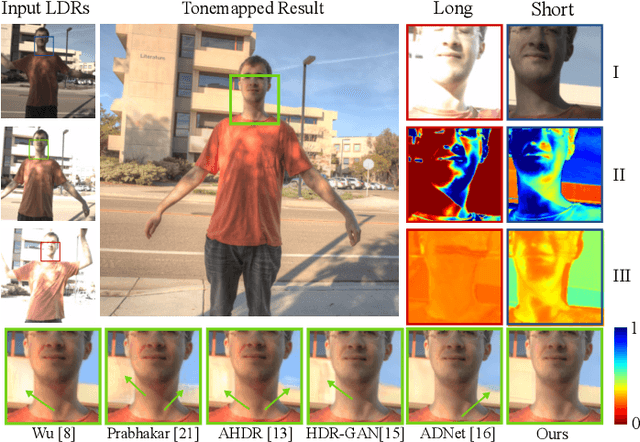


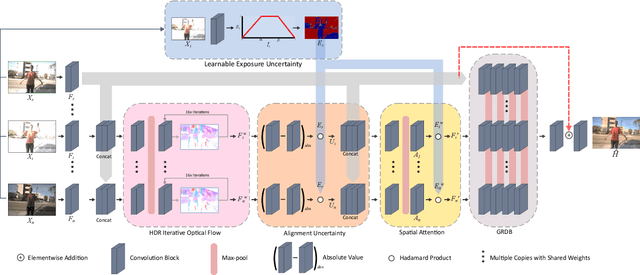
High dynamic range (HDR) imaging is of fundamental importance in modern digital photography pipelines and used to produce a high-quality photograph with well exposed regions despite varying illumination across the image. This is typically achieved by merging multiple low dynamic range (LDR) images taken at different exposures. However, over-exposed regions and misalignment errors due to poorly compensated motion result in artefacts such as ghosting. In this paper, we present a new HDR imaging technique that specifically models alignment and exposure uncertainties to produce high quality HDR results. We introduce a strategy that learns to jointly align and assess the alignment and exposure reliability using an HDR-aware, uncertainty-driven attention map that robustly merges the frames into a single high quality HDR image. Further, we introduce a progressive, multi-stage image fusion approach that can flexibly merge any number of LDR images in a permutation-invariant manner. Experimental results show our method can produce better quality HDR images with up to 0.8dB PSNR improvement to the state-of-the-art, and subjective improvements in terms of better detail, colours, and fewer artefacts.
DepthTrack : Unveiling the Power of RGBD Tracking
Aug 31, 2021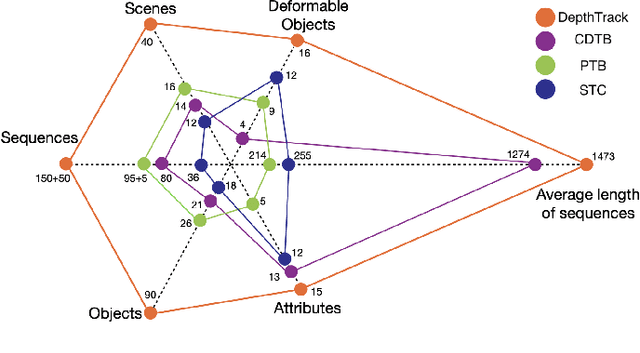
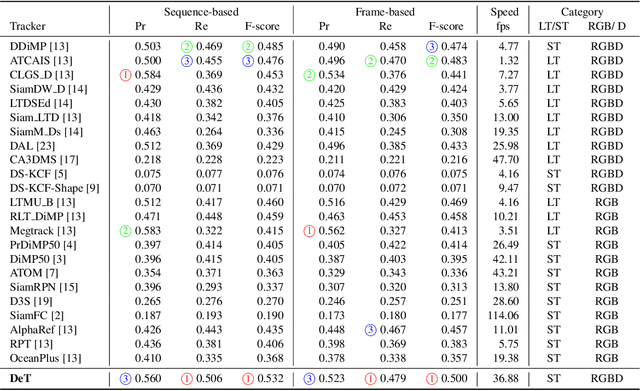

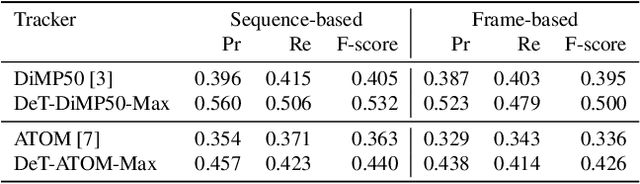
RGBD (RGB plus depth) object tracking is gaining momentum as RGBD sensors have become popular in many application fields such as robotics.However, the best RGBD trackers are extensions of the state-of-the-art deep RGB trackers. They are trained with RGB data and the depth channel is used as a sidekick for subtleties such as occlusion detection. This can be explained by the fact that there are no sufficiently large RGBD datasets to 1) train deep depth trackers and to 2) challenge RGB trackers with sequences for which the depth cue is essential. This work introduces a new RGBD tracking dataset - Depth-Track - that has twice as many sequences (200) and scene types (40) than in the largest existing dataset, and three times more objects (90). In addition, the average length of the sequences (1473), the number of deformable objects (16) and the number of annotated tracking attributes (15) have been increased. Furthermore, by running the SotA RGB and RGBD trackers on DepthTrack, we propose a new RGBD tracking baseline, namely DeT, which reveals that deep RGBD tracking indeed benefits from genuine training data. The code and dataset is available at https://github.com/xiaozai/DeT
NTIRE 2021 Challenge on High Dynamic Range Imaging: Dataset, Methods and Results
Jun 02, 2021
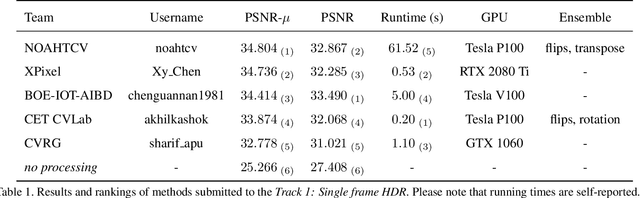
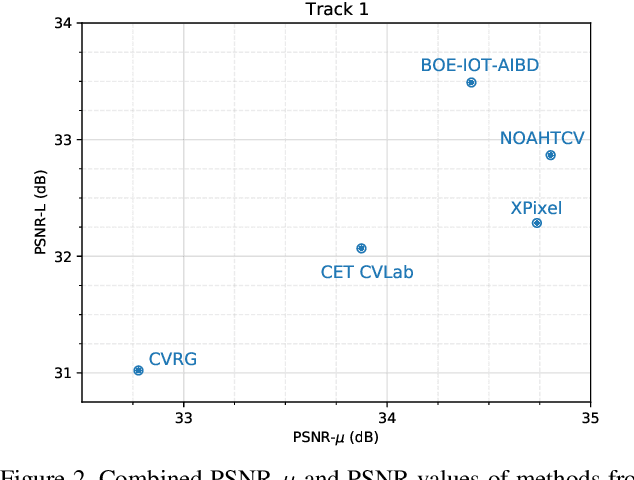
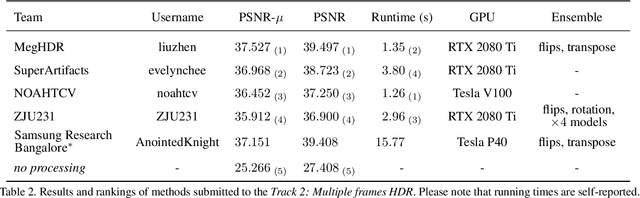
This paper reviews the first challenge on high-dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2021. This manuscript focuses on the newly introduced dataset, the proposed methods and their results. The challenge aims at estimating a HDR image from one or multiple respective low-dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed by two tracks: In Track 1 only a single LDR image is provided as input, whereas in Track 2 three differently-exposed LDR images with inter-frame motion are available. In both tracks, the ultimate goal is to achieve the best objective HDR reconstruction in terms of PSNR with respect to a ground-truth image, evaluated both directly and with a canonical tonemapping operation.
A Survey on Neural Network Interpretability
Dec 28, 2020
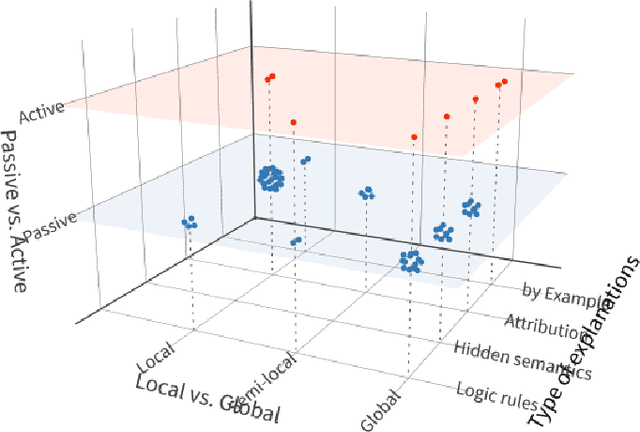
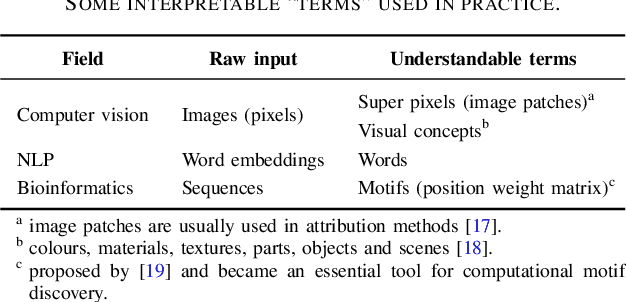
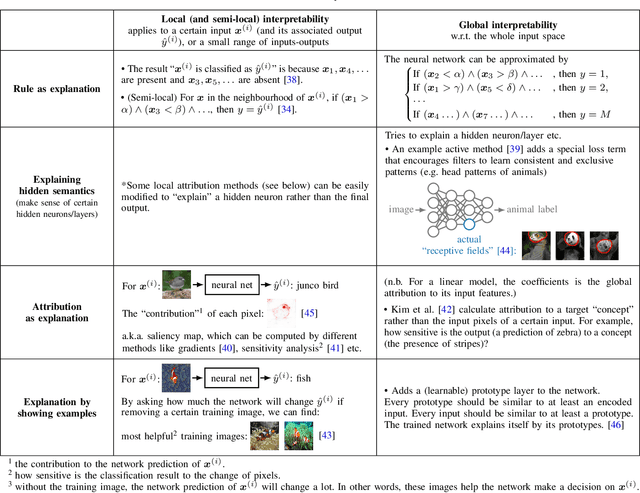
Along with the great success of deep neural networks, there is also growing concern about their black-box nature. The interpretability issue affects people's trust on deep learning systems. It is also related to many ethical problems, e.g., algorithmic discrimination. Moreover, interpretability is a desired property for deep networks to become powerful tools in other research fields, e.g., drug discovery and genomics. In this survey, we conduct a comprehensive review of the neural network interpretability research. We first clarify the definition of interpretability as it has been used in many different contexts. Then we elaborate on the importance of interpretability and propose a novel taxonomy organized along three dimensions: type of engagement (passive vs. active interpretation approaches), the type of explanation, and the focus (from local to global interpretability). This taxonomy provides a meaningful 3D view of distribution of papers from the relevant literature as two of the dimensions are not simply categorical but allow ordinal subcategories. Finally, we summarize the existing interpretability evaluation methods and suggest possible research directions inspired by our new taxonomy.
Learning Manipulation under Physics Constraints with Visual Perception
Apr 19, 2019
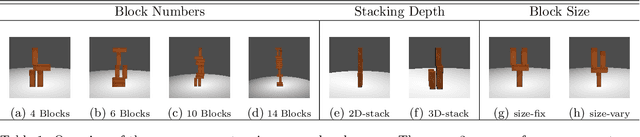
Understanding physical phenomena is a key competence that enables humans and animals to act and interact under uncertain perception in previously unseen environments containing novel objects and their configurations. In this work, we consider the problem of autonomous block stacking and explore solutions to learning manipulation under physics constraints with visual perception inherent to the task. Inspired by the intuitive physics in humans, we first present an end-to-end learning-based approach to predict stability directly from appearance, contrasting a more traditional model-based approach with explicit 3D representations and physical simulation. We study the model's behavior together with an accompanied human subject test. It is then integrated into a real-world robotic system to guide the placement of a single wood block into the scene without collapsing existing tower structure. To further automate the process of consecutive blocks stacking, we present an alternative approach where the model learns the physics constraint through the interaction with the environment, bypassing the dedicated physics learning as in the former part of this work. In particular, we are interested in the type of tasks that require the agent to reach a given goal state that may be different for every new trial. Thereby we propose a deep reinforcement learning framework that learns policies for stacking tasks which are parametrized by a target structure.
Assessing Capsule Networks With Biased Data
Apr 09, 2019
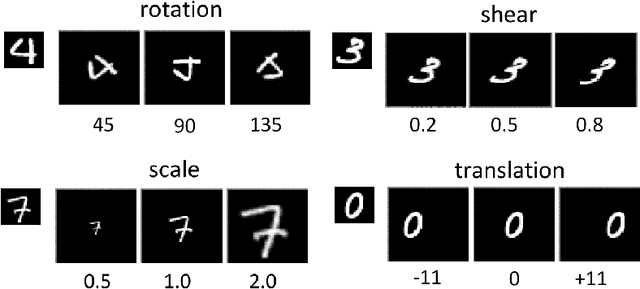
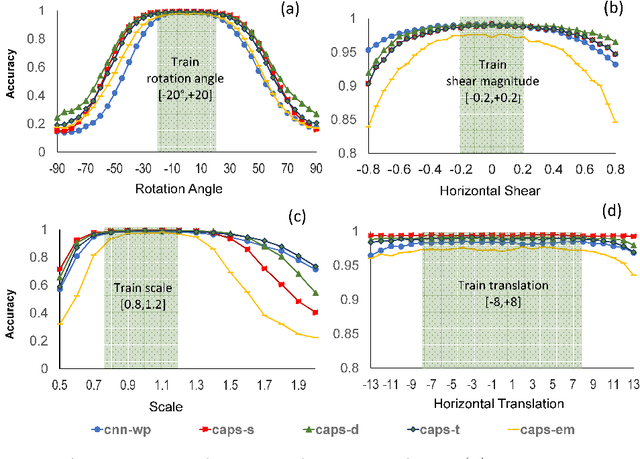
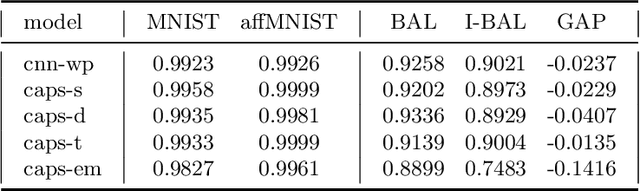
Machine learning based methods achieves impressive results in object classification and detection. Utilizing representative data of the visual world during the training phase is crucial to achieve good performance with such data driven approaches. However, it not always possible to access bias-free datasets thus, robustness to biased data is a desirable property for a learning system. Capsule Networks have been introduced recently and their tolerance to biased data has received little attention. This paper aims to fill this gap and proposes two experimental scenarios to assess the tolerance to imbalanced training data and to determine the generalization performance of a model with unfamiliar affine transformations of the images. This paper assesses dynamic routing and EM routing based Capsule Networks and proposes a comparison with Convolutional Neural Networks in the two tested scenarios. The presented results provide new insights into the behaviour of capsule networks.
Spatially-Adaptive Filter Units for Compact and Efficient Deep Neural Networks
Feb 20, 2019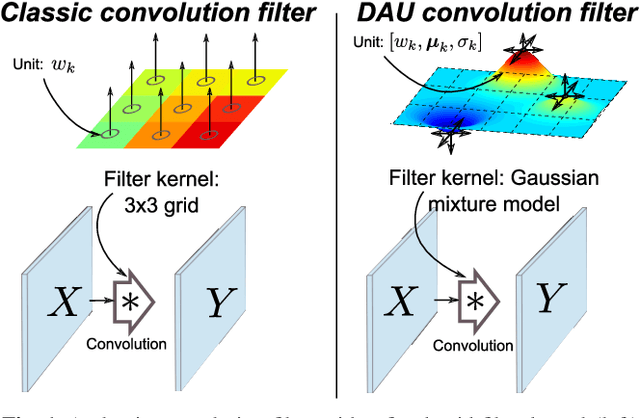

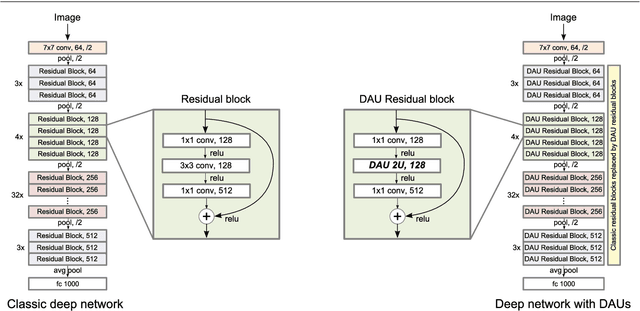

Convolutional neural networks excel in a number of computer vision tasks. One of their most crucial architectural elements is the effective receptive field size, that has to be manually set to accommodate a specific task. Standard solutions involve large kernels, down/up-sampling and dilated convolutions. These require testing a variety of dilation and down/up-sampling factors and result in non-compact representations and excessive number of parameters. We address this issue by proposing a new convolution filter composed of displaced aggregation units (DAU). DAUs learn spatial displacements and adapt the receptive field sizes of individual convolution filters to a given problem, thus eliminating the need for hand-crafted modifications. DAUs provide a seamless substitution of convolutional filters in existing state-of-the-art architectures, which we demonstrate on AlexNet, ResNet50, ResNet101, DeepLab and SRN-DeblurNet. The benefits of this design are demonstrated on a variety of computer vision tasks and datasets, such as image classification (ILSVRC 2012), semantic segmentation (PASCAL VOC 2011, Cityscape) and blind image de-blurring (GOPRO). Results show that DAUs efficiently allocate parameters resulting in up to four times more compact networks at similar or better performance.
Spatially-Adaptive Filter Units for Deep Neural Networks
Mar 15, 2018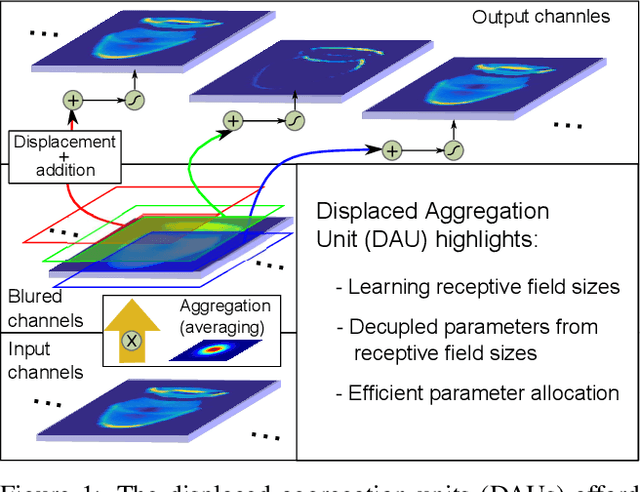
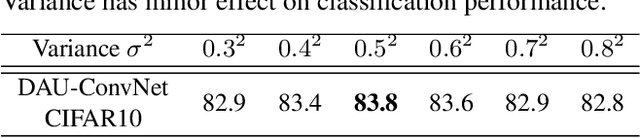

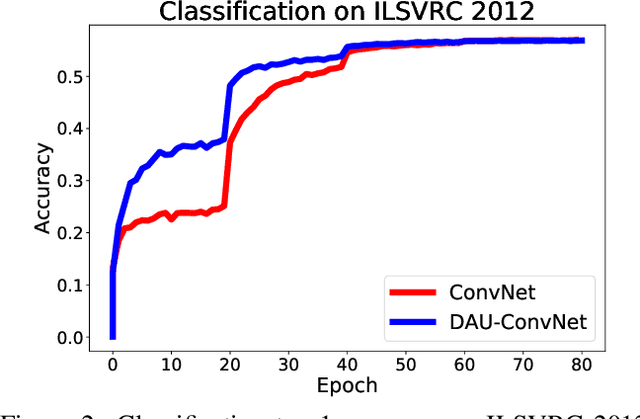
Classical deep convolutional networks increase receptive field size by either gradual resolution reduction or application of hand-crafted dilated convolutions to prevent increase in the number of parameters. In this paper we propose a novel displaced aggregation unit (DAU) that does not require hand-crafting. In contrast to classical filters with units (pixels) placed on a fixed regular grid, the displacement of the DAUs are learned, which enables filters to spatially-adapt their receptive field to a given problem. We extensively demonstrate the strength of DAUs on a classification and semantic segmentation tasks. Compared to ConvNets with regular filter, ConvNets with DAUs achieve comparable performance at faster convergence and up to 3-times reduction in parameters. Furthermore, DAUs allow us to study deep networks from novel perspectives. We study spatial distributions of DAU filters and analyze the number of parameters allocated for spatial coverage in a filter.