 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of Real Minimal Complexity Reservoir
Aug 15, 2024


Reservoir Computing (RC) models, a subclass of recurrent neural networks, are distinguished by their fixed, non-trainable input layer and dynamically coupled reservoir, with only the static readout layer being trained. This design circumvents the issues associated with backpropagating error signals through time, thereby enhancing both stability and training efficiency. RC models have been successfully applied across a broad range of application domains. Crucially, they have been demonstrated to be universal approximators of time-invariant dynamic filters with fading memory, under various settings of approximation norms and input driving sources. Simple Cycle Reservoirs (SCR) represent a specialized class of RC models with a highly constrained reservoir architecture, characterized by uniform ring connectivity and binary input-to-reservoir weights with an aperiodic sign pattern. For linear reservoirs, given the reservoir size, the reservoir construction has only one degree of freedom -- the reservoir cycle weight. Such architectures are particularly amenable to hardware implementations without significant performance degradation in many practical tasks. In this study we endow these observations with solid theoretical foundations by proving that SCRs operating in real domain are universal approximators of time-invariant dynamic filters with fading memory. Our results supplement recent research showing that SCRs in the complex domain can approximate, to arbitrary precision, any unrestricted linear reservoir with a non-linear readout. We furthermore introduce a novel method to drastically reduce the number of SCR units, making such highly constrained architectures natural candidates for low-complexity hardware implementations. Our findings are supported by empirical studies on real-world time series datasets.
Simple Cycle Reservoirs are Universal
Aug 21, 2023

Reservoir computation models form a subclass of recurrent neural networks with fixed non-trainable input and dynamic coupling weights. Only the static readout from the state space (reservoir) is trainable, thus avoiding the known problems with propagation of gradient information backwards through time. Reservoir models have been successfully applied in a variety of tasks and were shown to be universal approximators of time-invariant fading memory dynamic filters under various settings. Simple cycle reservoirs (SCR) have been suggested as severely restricted reservoir architecture, with equal weight ring connectivity of the reservoir units and input-to-reservoir weights of binary nature with the same absolute value. Such architectures are well suited for hardware implementations without performance degradation in many practical tasks. In this contribution, we rigorously study the expressive power of SCR in the complex domain and show that they are capable of universal approximation of any unrestricted linear reservoir system (with continuous readout) and hence any time-invariant fading memory filter over uniformly bounded input streams.
A Survey on Neural Network Interpretability
Dec 28, 2020
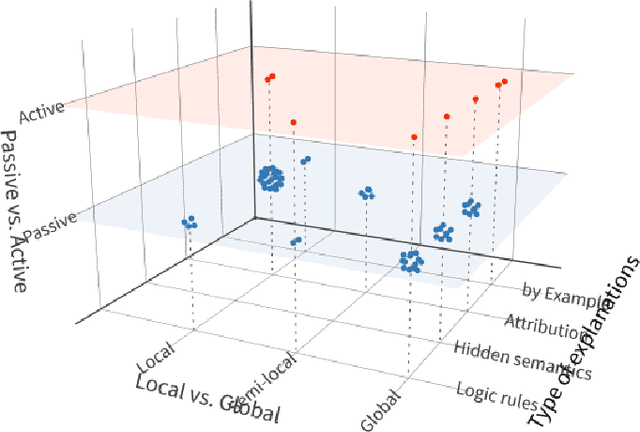
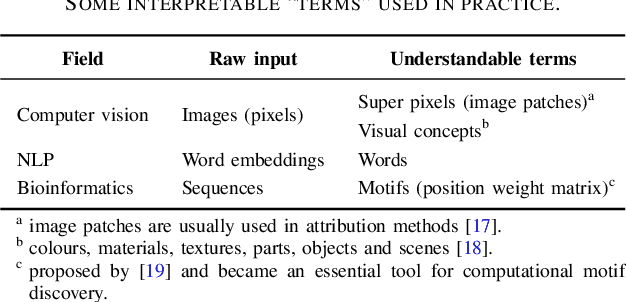
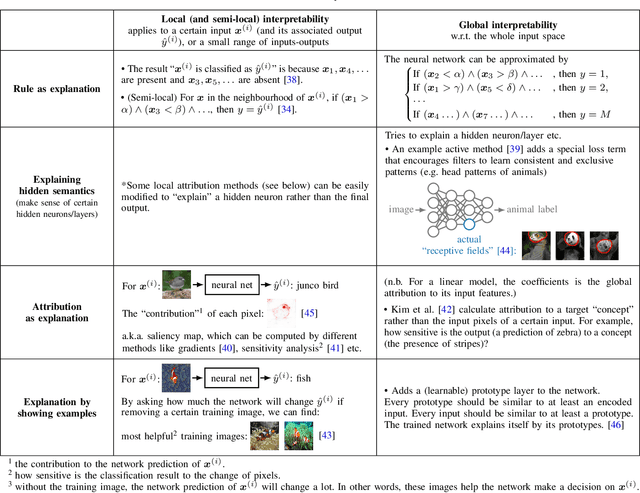
Along with the great success of deep neural networks, there is also growing concern about their black-box nature. The interpretability issue affects people's trust on deep learning systems. It is also related to many ethical problems, e.g., algorithmic discrimination. Moreover, interpretability is a desired property for deep networks to become powerful tools in other research fields, e.g., drug discovery and genomics. In this survey, we conduct a comprehensive review of the neural network interpretability research. We first clarify the definition of interpretability as it has been used in many different contexts. Then we elaborate on the importance of interpretability and propose a novel taxonomy organized along three dimensions: type of engagement (passive vs. active interpretation approaches), the type of explanation, and the focus (from local to global interpretability). This taxonomy provides a meaningful 3D view of distribution of papers from the relevant literature as two of the dimensions are not simply categorical but allow ordinal subcategories. Finally, we summarize the existing interpretability evaluation methods and suggest possible research directions inspired by our new taxonomy.
Model-Coupled Autoencoder for Time Series Visualisation
Jan 21, 2016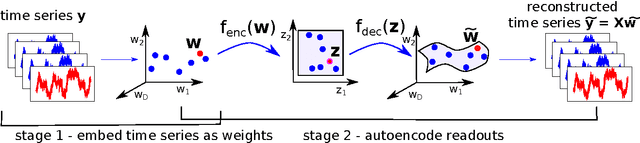
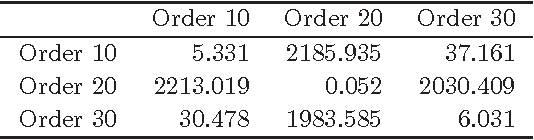
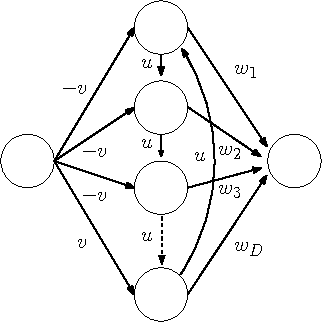
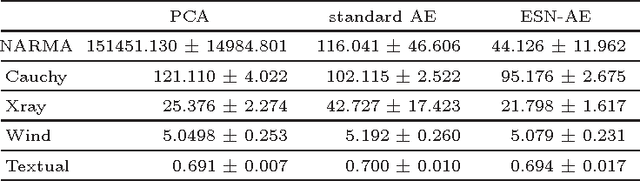
We present an approach for the visualisation of a set of time series that combines an echo state network with an autoencoder. For each time series in the dataset we train an echo state network, using a common and fixed reservoir of hidden neurons, and use the optimised readout weights as the new representation. Dimensionality reduction is then performed via an autoencoder on the readout weight representations. The crux of the work is to equip the autoencoder with a loss function that correctly interprets the reconstructed readout weights by associating them with a reconstruction error measured in the data space of sequences. This essentially amounts to measuring the predictive performance that the reconstructed readout weights exhibit on their corresponding sequences when plugged back into the echo state network with the same fixed reservoir. We demonstrate that the proposed visualisation framework can deal both with real valued sequences as well as binary sequences. We derive magnification factors in order to analyse distance preservations and distortions in the visualisation space. The versatility and advantages of the proposed method are demonstrated on datasets of time series that originate from diverse domains.