 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Control using Learned Safety Filters and Adaptive Conformal Inference
Apr 20, 2026Safety filters have been shown to be effective tools to ensure the safety of control systems with unsafe nominal policies. To address scalability challenges in traditional synthesis methods, learning-based approaches have been proposed for designing safety filters for systems with high-dimensional state and control spaces. However, the inevitable errors in the decisions of these models raise concerns about their reliability and the safety guarantees they offer. This paper presents Adaptive Conformal Filtering (ACoFi), a method that combines learned Hamilton-Jacobi reachability-based safety filters with adaptive conformal inference. Under ACoFi, the filter dynamically adjusts its switching criteria based on the observed errors in its predictions of the safety of actions. The range of possible safety values of the nominal policy's output is used to quantify uncertainty in safety assessment. The filter switches from the nominal policy to the learned safe one when that range suggests it might be unsafe. We show that ACoFi guarantees that the rate of incorrectly quantifying uncertainty in the predicted safety of the nominal policy is asymptotically upper bounded by a user-defined parameter. This gives a soft safety guarantee rather than a hard safety guarantee. We evaluate ACoFi in a Dubins car simulation and a Safety Gymnasium environment, empirically demonstrating that it significantly outperforms the baseline method that uses a fixed switching threshold by achieving higher learned safety values and fewer safety violations, especially in out-of-distribution scenarios.
Statistically Assuring Safety of Control Systems using Ensembles of Safety Filters and Conformal Prediction
Nov 11, 2025Safety assurance is a fundamental requirement for deploying learning-enabled autonomous systems. Hamilton-Jacobi (HJ) reachability analysis is a fundamental method for formally verifying safety and generating safe controllers. However, computing the HJ value function that characterizes the backward reachable set (BRS) of a set of user-defined failure states is computationally expensive, especially for high-dimensional systems, motivating the use of reinforcement learning approaches to approximate the value function. Unfortunately, a learned value function and its corresponding safe policy are not guaranteed to be correct. The learned value function evaluated at a given state may not be equal to the actual safety return achieved by following the learned safe policy. To address this challenge, we introduce a conformal prediction-based (CP) framework that bounds such uncertainty. We leverage CP to provide probabilistic safety guarantees when using learned HJ value functions and policies to prevent control systems from reaching failure states. Specifically, we use CP to calibrate the switching between the unsafe nominal controller and the learned HJ-based safe policy and to derive safety guarantees under this switched policy. We also investigate using an ensemble of independently trained HJ value functions as a safety filter and compare this ensemble approach to using individual value functions alone.
Designing Latent Safety Filters using Pre-Trained Vision Models
Sep 18, 2025Ensuring safety of vision-based control systems remains a major challenge hindering their deployment in critical settings. Safety filters have gained increased interest as effective tools for ensuring the safety of classical control systems, but their applications in vision-based control settings have so far been limited. Pre-trained vision models (PVRs) have been shown to be effective perception backbones for control in various robotics domains. In this paper, we are interested in examining their effectiveness when used for designing vision-based safety filters. We use them as backbones for classifiers defining failure sets, for Hamilton-Jacobi (HJ) reachability-based safety filters, and for latent world models. We discuss the trade-offs between training from scratch, fine-tuning, and freezing the PVRs when training the models they are backbones for. We also evaluate whether one of the PVRs is superior across all tasks, evaluate whether learned world models or Q-functions are better for switching decisions to safe policies, and discuss practical considerations for deploying these PVRs on resource-constrained devices.
Learning Neural Control Barrier Functions from Offline Data with Conservatism
May 01, 2025



Safety filters, particularly those based on control barrier functions, have gained increased interest as effective tools for safe control of dynamical systems. Existing correct-by-construction synthesis algorithms, however, suffer from the curse of dimensionality. Deep learning approaches have been proposed in recent years to address this challenge. In this paper, we contribute to this line of work by proposing an algorithm for training control barrier functions from offline datasets. Our algorithm trains the filter to not only prevent the system from reaching unsafe states but also out-of-distribution ones, at which the filter would be unreliable. It is inspired by Conservative Q-learning, an offline reinforcement learning algorithm. We call its outputs Conservative Control Barrier Functions (CCBFs). Our empirical results demonstrate that CCBFs outperform existing methods in maintaining safety and out-of-distribution avoidance while minimally affecting task performance.
Learning Ensembles of Vision-based Safety Control Filters
Dec 02, 2024

Safety filters in control systems correct nominal controls that violate safety constraints. Designing such filters as functions of visual observations in uncertain and complex environments is challenging. Several deep learning-based approaches to tackle this challenge have been proposed recently. However, formally verifying that the learned filters satisfy critical properties that enable them to guarantee the safety of the system is currently beyond reach. Instead, in this work, motivated by the success of ensemble methods in reinforcement learning, we empirically investigate the efficacy of ensembles in enhancing the accuracy and the out-of-distribution generalization of such filters, as a step towards more reliable ones. We experiment with diverse pre-trained vision representation models as filter backbones, training approaches, and output aggregation techniques. We compare the performance of ensembles with different configurations against each other, their individual member models, and large single-model baselines in distinguishing between safe and unsafe states and controls in the DeepAccident dataset. Our results show that diverse ensembles have better state and control classification accuracies compared to individual models.
Pre-Trained Vision Models as Perception Backbones for Safety Filters in Autonomous Driving
Oct 29, 2024


End-to-end vision-based autonomous driving has achieved impressive success, but safety remains a major concern. The safe control problem has been addressed in low-dimensional settings using safety filters, e.g., those based on control barrier functions. Designing safety filters for vision-based controllers in the high-dimensional settings of autonomous driving can similarly alleviate the safety problem, but is significantly more challenging. In this paper, we address this challenge by using frozen pre-trained vision representation models as perception backbones to design vision-based safety filters, inspired by these models' success as backbones of robotic control policies. We empirically evaluate the offline performance of four common pre-trained vision models in this context. We try three existing methods for training safety filters for black-box dynamics, as the dynamics over representation spaces are not known. We use the DeepAccident dataset that consists of action-annotated videos from multiple cameras on vehicles in CARLA simulating real accident scenarios. Our results show that the filters resulting from our approach are competitive with the ones that are given the ground truth state of the ego vehicle and its environment.
Safe Decentralized Multi-Agent Control using Black-Box Predictors, Conformal Decision Policies, and Control Barrier Functions
Sep 27, 2024We address the challenge of safe control in decentralized multi-agent robotic settings, where agents use uncertain black-box models to predict other agents' trajectories. We use the recently proposed conformal decision theory to adapt the restrictiveness of control barrier functions-based safety constraints based on observed prediction errors. We use these constraints to synthesize controllers that balance between the objectives of safety and task accomplishment, despite the prediction errors. We provide an upper bound on the average over time of the value of a monotonic function of the difference between the safety constraint based on the predicted trajectories and the constraint based on the ground truth ones. We validate our theory through experimental results showing the performance of our controllers when navigating a robot in the multi-agent scenes in the Stanford Drone Dataset.
A Grammar for the Representation of Unmanned Aerial Vehicles with 3D Topologies
Feb 27, 2023
We propose a context-sensitive grammar for the systematic exploration of the design space of the topology of 3D robots, particularly unmanned aerial vehicles. It defines production rules for adding components to an incomplete design topology modeled over a 3D grid. The rules are local. The grammar is simple, yet capable of modeling most existing UAVs as well as novel ones. It can be easily generalized to other robotic platforms. It can be thought of as a building block for any design exploration and optimization algorithm.
Certifying Safety in Reinforcement Learning under Adversarial Perturbation Attacks
Dec 28, 2022
Function approximation has enabled remarkable advances in applying reinforcement learning (RL) techniques in environments with high-dimensional inputs, such as images, in an end-to-end fashion, mapping such inputs directly to low-level control. Nevertheless, these have proved vulnerable to small adversarial input perturbations. A number of approaches for improving or certifying robustness of end-to-end RL to adversarial perturbations have emerged as a result, focusing on cumulative reward. However, what is often at stake in adversarial scenarios is the violation of fundamental properties, such as safety, rather than the overall reward that combines safety with efficiency. Moreover, properties such as safety can only be defined with respect to true state, rather than the high-dimensional raw inputs to end-to-end policies. To disentangle nominal efficiency and adversarial safety, we situate RL in deterministic partially-observable Markov decision processes (POMDPs) with the goal of maximizing cumulative reward subject to safety constraints. We then propose a partially-supervised reinforcement learning (PSRL) framework that takes advantage of an additional assumption that the true state of the POMDP is known at training time. We present the first approach for certifying safety of PSRL policies under adversarial input perturbations, and two adversarial training approaches that make direct use of PSRL. Our experiments demonstrate both the efficacy of the proposed approach for certifying safety in adversarial environments, and the value of the PSRL framework coupled with adversarial training in improving certified safety while preserving high nominal reward and high-quality predictions of true state.
SymAR: Symmetry Abstractions and Refinement for Accelerating Scenarios with Neural Network Controllers Verification
Nov 21, 2020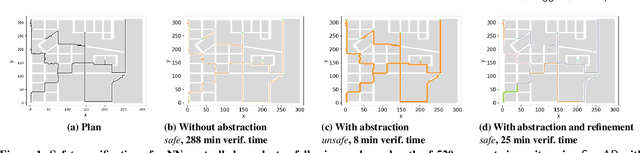
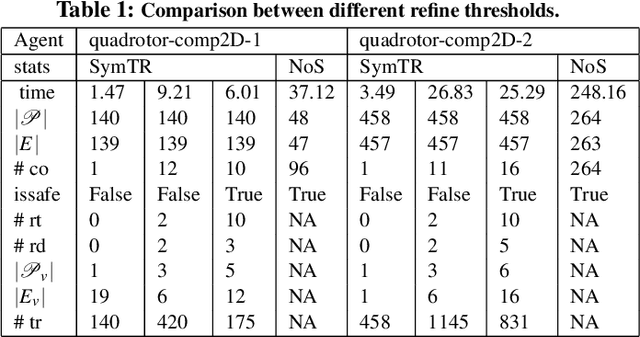
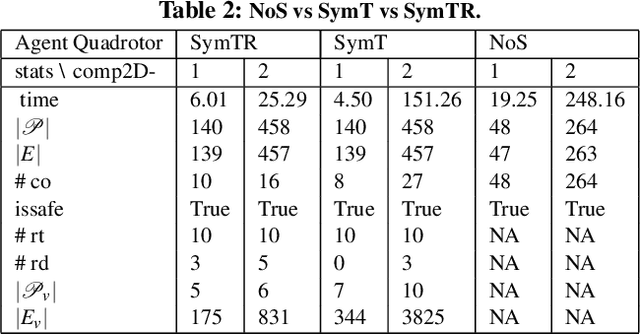
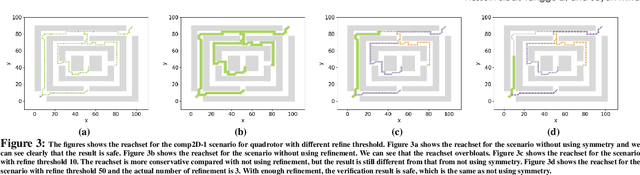
We present a Symmetry-based abstraction refinement algorithm SymAR that is directed towards safety verification of large-scale scenarios with complex dynamical systems. The abstraction maps modes with symmetric dynamics to a single abstract mode and refinements recursively split the modes when safety checks fail. We show how symmetry abstractions can be applied effectively to closed-loop control systems, including non-symmetric deep neural network (DNN) controllers. For such controllers, we transform their inputs and outputs to enforce symmetry and make the closed loop system amenable for abstraction. We implemented SymAR in Python and used it to verify paths with 100s of segments in 2D and 3D scenarios followed by a six dimensional DNN-controlled quadrotor, and also a ground vehicle. Our experiments show significant savings, up to 10x in some cases, in verification time over existing methods.