 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation of Embedding Models to Financial Filings via LLM Distillation
Dec 08, 2025Despite advances in generative large language models (LLMs), practical application of specialized conversational AI agents remains constrained by computation costs, latency requirements, and the need for precise domain-specific relevance measures. While existing embedding models address the first two constraints, they underperform on information retrieval in specialized domains like finance. This paper introduces a scalable pipeline that trains specialized models from an unlabeled corpus using a general purpose retrieval embedding model as foundation. Our method yields an average of 27.7% improvement in MRR$\texttt{@}$5, 44.6% improvement in mean DCG$\texttt{@}$5 across 14 financial filing types measured over 21,800 query-document pairs, and improved NDCG on 3 of 4 document classes in FinanceBench. We adapt retrieval embeddings (bi-encoder) for RAG, not LLM generators, using LLM-judged relevance to distill domain knowledge into a compact retriever. There are prior works which pair synthetically generated queries with real passages to directly fine-tune the retrieval model. Our pipeline differs from these by introducing interaction between student and teacher models that interleaves retrieval-based mining of hard positive/negative examples from the unlabeled corpus with iterative retraining of the student model's weights using these examples. Each retrieval iteration uses the refined student model to mine the corpus for progressively harder training examples for the subsequent training iteration. The methodology provides a cost-effective solution to bridging the gap between general-purpose models and specialized domains without requiring labor-intensive human annotation.
Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling
May 15, 2024



We study the problem of automatically annotating relevant numerals (GAAP metrics) occurring in the financial documents with their corresponding XBRL tags. Different from prior works, we investigate the feasibility of solving this extreme classification problem using a generative paradigm through instruction tuning of Large Language Models (LLMs). To this end, we leverage metric metadata information to frame our target outputs while proposing a parameter efficient solution for the task using LoRA. We perform experiments on two recently released financial numeric labeling datasets. Our proposed model, FLAN-FinXC, achieves new state-of-the-art performances on both the datasets, outperforming several strong baselines. We explain the better scores of our proposed model by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Also, even when we fail to predict the XBRL tags correctly, our generated output has substantial overlap with the ground-truth in majority of the cases.
FinRED: A Dataset for Relation Extraction in Financial Domain
Jun 06, 2023



Relation extraction models trained on a source domain cannot be applied on a different target domain due to the mismatch between relation sets. In the current literature, there is no extensive open-source relation extraction dataset specific to the finance domain. In this paper, we release FinRED, a relation extraction dataset curated from financial news and earning call transcripts containing relations from the finance domain. FinRED has been created by mapping Wikidata triplets using distance supervision method. We manually annotate the test data to ensure proper evaluation. We also experiment with various state-of-the-art relation extraction models on this dataset to create the benchmark. We see a significant drop in their performance on FinRED compared to the general relation extraction datasets which tells that we need better models for financial relation extraction.
A Generative Approach for Financial Causality Extraction
Apr 12, 2022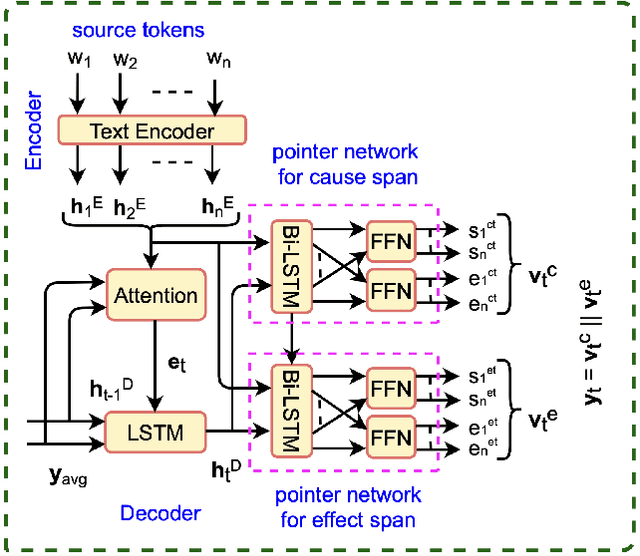
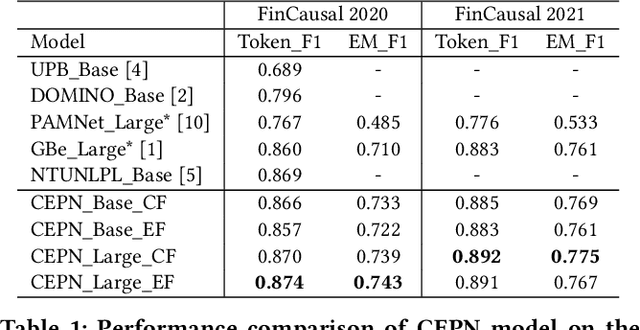
Causality represents the foremost relation between events in financial documents such as financial news articles, financial reports. Each financial causality contains a cause span and an effect span. Previous works proposed sequence labeling approaches to solve this task. But sequence labeling models find it difficult to extract multiple causalities and overlapping causalities from the text segments. In this paper, we explore a generative approach for causality extraction using the encoder-decoder framework and pointer networks. We use a causality dataset from the financial domain, \textit{FinCausal}, for our experiments and our proposed framework achieves very competitive performance on this dataset.