 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Conversational Networks
Jun 15, 2021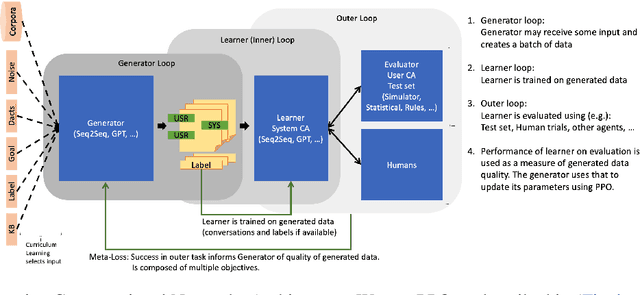
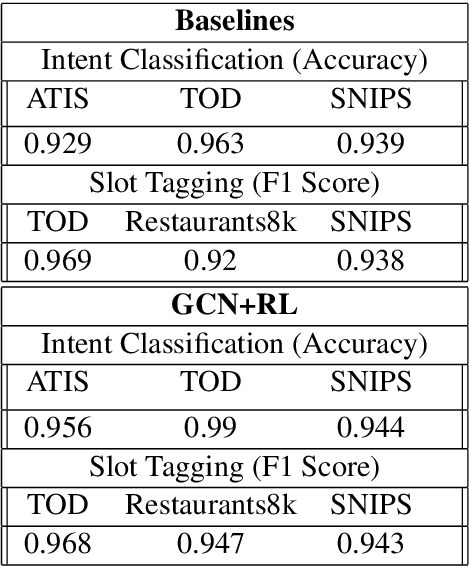
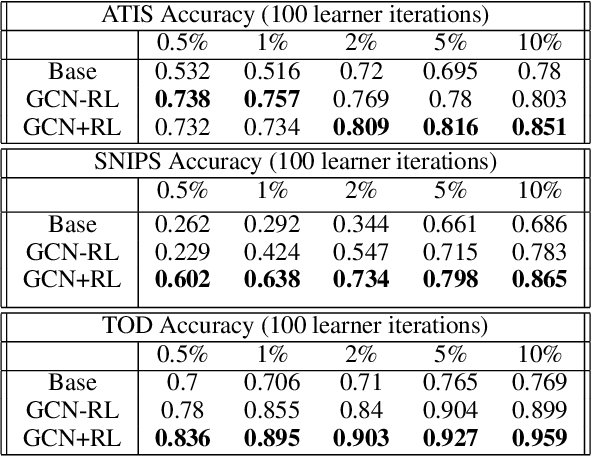
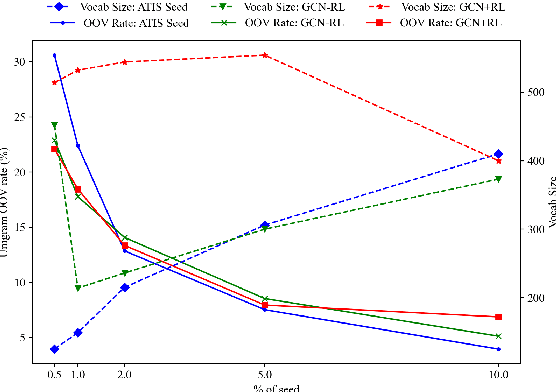
Inspired by recent work in meta-learning and generative teaching networks, we propose a framework called Generative Conversational Networks, in which conversational agents learn to generate their own labelled training data (given some seed data) and then train themselves from that data to perform a given task. We use reinforcement learning to optimize the data generation process where the reward signal is the agent's performance on the task. The task can be any language-related task, from intent detection to full task-oriented conversations. In this work, we show that our approach is able to generalise from seed data and performs well in limited data and limited computation settings, with significant gains for intent detection and slot tagging across multiple datasets: ATIS, TOD, SNIPS, and Restaurants8k. We show an average improvement of 35% in intent detection and 21% in slot tagging over a baseline model trained from the seed data. We also conduct an analysis of the novelty of the generated data and provide generated examples for intent detection, slot tagging, and non-goal oriented conversations.
Dialog as a Vehicle for Lifelong Learning
Jun 26, 2020Dialog systems research has primarily been focused around two main types of applications - task-oriented dialog systems that learn to use clarification to aid in understanding a goal, and open-ended dialog systems that are expected to carry out unconstrained "chit chat" conversations. However, dialog interactions can also be used to obtain various types of knowledge that can be used to improve an underlying language understanding system, or other machine learning systems that the dialog acts over. In this position paper, we present the problem of designing dialog systems that enable lifelong learning as an important challenge problem, in particular for applications involving physically situated robots. We include examples of prior work in this direction, and discuss challenges that remain to be addressed.
Dialog Policy Learning for Joint Clarification and Active Learning Queries
Jun 09, 2020
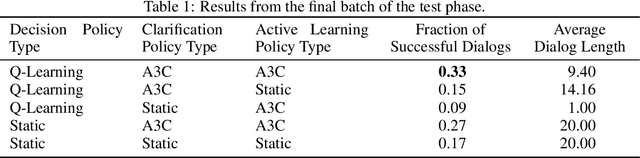

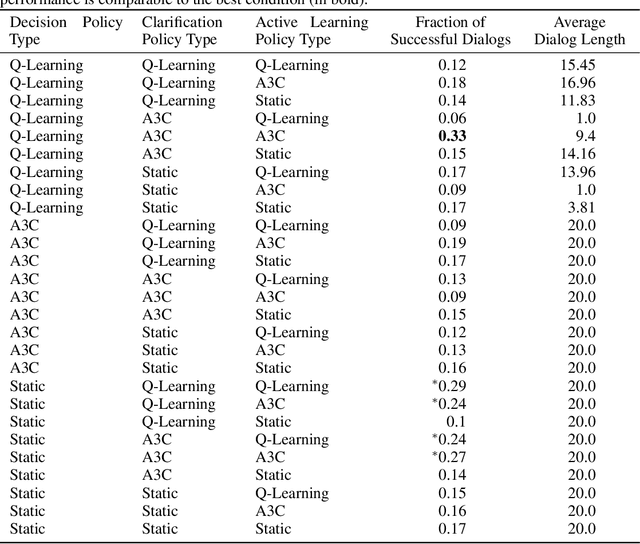
Intelligent systems need to be able to recover from mistakes, resolve uncertainty, and adapt to novel concepts not seen during training. Dialog interaction can enable this by the use of clarifications for correction and resolving uncertainty, and active learning queries to learn new concepts encountered during operation. Prior work on dialog systems has either focused on exclusively learning how to perform clarification/ information seeking, or to perform active learning. In this work, we train a hierarchical dialog policy to jointly perform {\it both} clarification and active learning in the context of an interactive language-based image retrieval task motivated by an on-line shopping application, and demonstrate that jointly learning dialog policies for clarification and active learning is more effective than the use of static dialog policies for one or both of these functions.
Improving Grounded Natural Language Understanding through Human-Robot Dialog
Mar 01, 2019

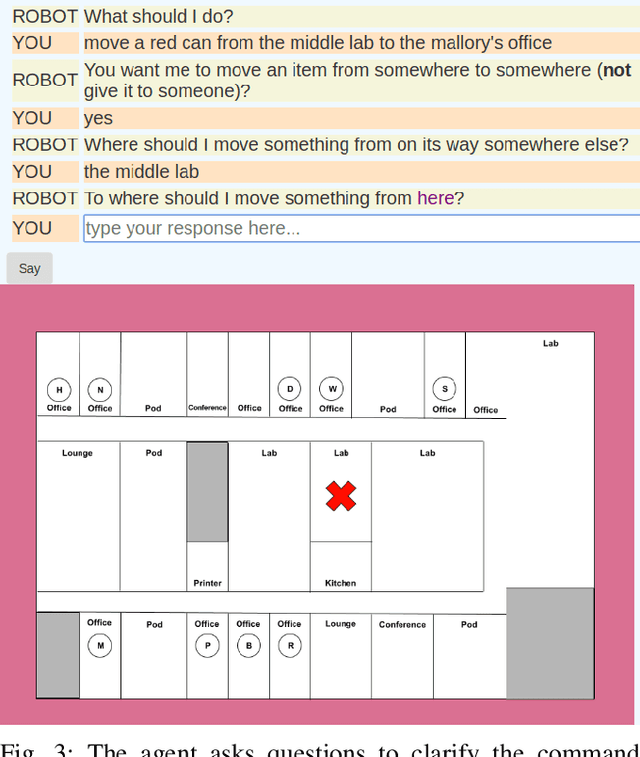

Natural language understanding for robotics can require substantial domain- and platform-specific engineering. For example, for mobile robots to pick-and-place objects in an environment to satisfy human commands, we can specify the language humans use to issue such commands, and connect concept words like red can to physical object properties. One way to alleviate this engineering for a new domain is to enable robots in human environments to adapt dynamically---continually learning new language constructions and perceptual concepts. In this work, we present an end-to-end pipeline for translating natural language commands to discrete robot actions, and use clarification dialogs to jointly improve language parsing and concept grounding. We train and evaluate this agent in a virtual setting on Amazon Mechanical Turk, and we transfer the learned agent to a physical robot platform to demonstrate it in the real world.
Interaction and Autonomy in RoboCup@Home and Building-Wide Intelligence
Oct 06, 2018



Efforts are underway at UT Austin to build autonomous robot systems that address the challenges of long-term deployments in office environments and of the more prescribed domestic service tasks of the RoboCup@Home competition. We discuss the contrasts and synergies of these efforts, highlighting how our work to build a RoboCup@Home Domestic Standard Platform League entry led us to identify an integrated software architecture that could support both projects. Further, naturalistic deployments of our office robot platform as part of the Building-Wide Intelligence project have led us to identify and research new problems in a traditional laboratory setting.
Learning a Policy for Opportunistic Active Learning
Aug 29, 2018
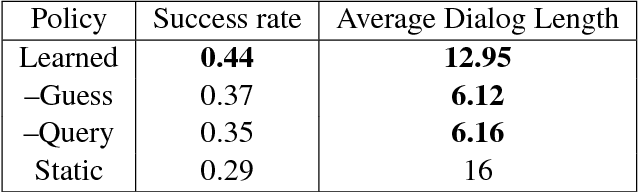
Active learning identifies data points to label that are expected to be the most useful in improving a supervised model. Opportunistic active learning incorporates active learning into interactive tasks that constrain possible queries during interactions. Prior work has shown that opportunistic active learning can be used to improve grounding of natural language descriptions in an interactive object retrieval task. In this work, we use reinforcement learning for such an object retrieval task, to learn a policy that effectively trades off task completion with model improvement that would benefit future tasks.
* EMNLP 2018 Camera Ready