 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Neural Keyphrase Generation
Sep 22, 2020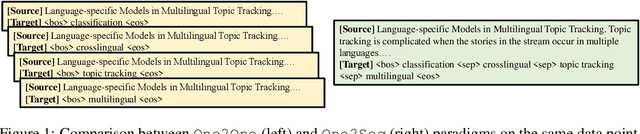
Recent years have seen a flourishing of neural keyphrase generation works, including the release of several large-scale datasets and a host of new models to tackle them. Model performance on keyphrase generation tasks has increased significantly with evolving deep learning research. However, there lacks a comprehensive comparison among models, and an investigation on related factors (e.g., architectural choice, decoding strategy) that may affect a keyphrase generation system's performance. In this empirical study, we aim to fill this gap by providing extensive experimental results and analyzing the most crucial factors impacting the performance of keyphrase generation models. We hope this study can help clarify some of the uncertainties surrounding the keyphrase generation task and facilitate future research on this topic.
Exploring and Predicting Transferability across NLP Tasks
May 02, 2020
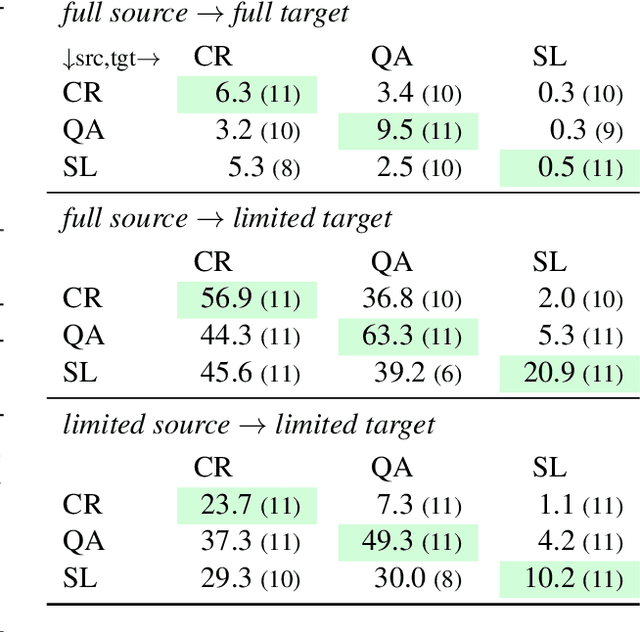
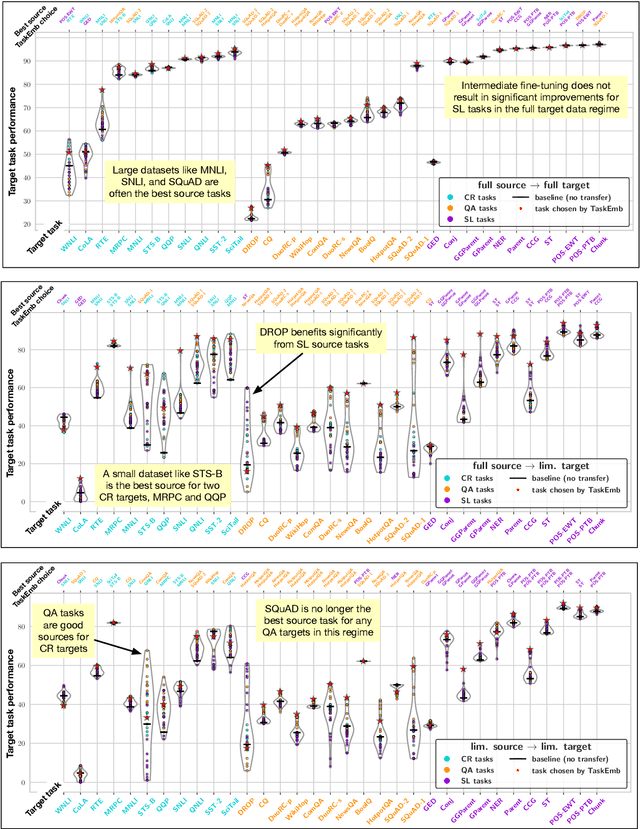
Recent advances in NLP demonstrate the effectiveness of training large-scale language models and transferring them to downstream tasks. Can fine-tuning these models on tasks other than language modeling further improve performance? In this paper, we conduct an extensive study of the transferability between 33 NLP tasks across three broad classes of problems (text classification, question answering, and sequence labeling). Our results show that transfer learning is more beneficial than previously thought, especially when target task data is scarce, and can improve performance even when the source task is small or differs substantially from the target task (e.g., part-of-speech tagging transfers well to the DROP QA dataset). We also develop task embeddings that can be used to predict the most transferable source tasks for a given target task, and we validate their effectiveness in experiments controlled for source and target data size. Overall, our experiments reveal that factors such as source data size, task and domain similarity, and task complexity all play a role in determining transferability.
Exploiting Structured Knowledge in Text via Graph-Guided Representation Learning
Apr 29, 2020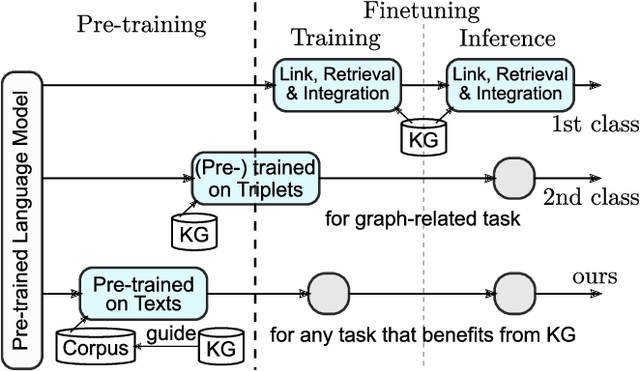
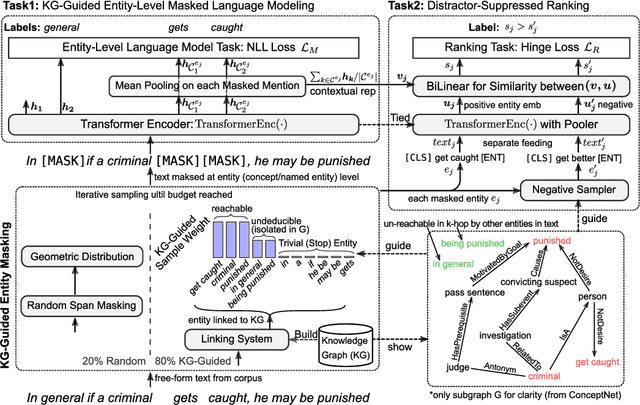
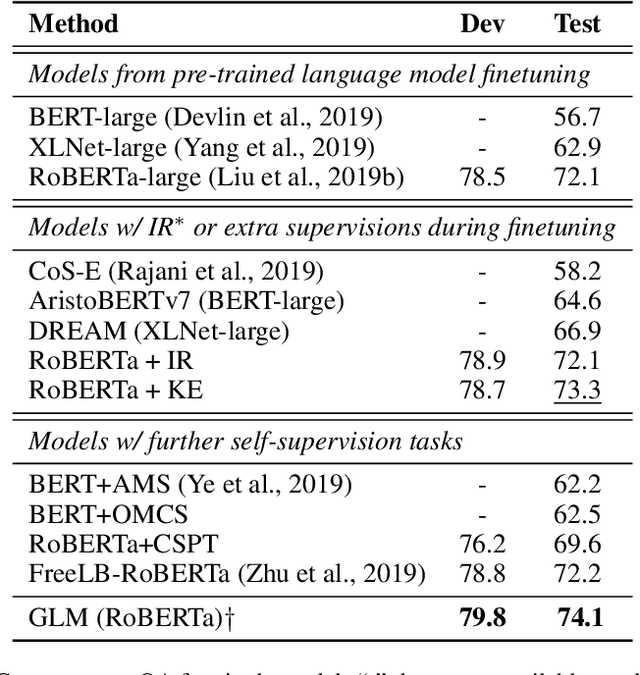
In this work, we aim at equipping pre-trained language models with structured knowledge. We present two self-supervised tasks learning over raw text with the guidance from knowledge graphs. Building upon entity-level masked language models, our first contribution is an entity masking scheme that exploits relational knowledge underlying the text. This is fulfilled by using a linked knowledge graph to select informative entities and then masking their mentions. In addition we use knowledge graphs to obtain distractors for the masked entities, and propose a novel distractor-suppressed ranking objective which is optimized jointly with masked language model. In contrast to existing paradigms, our approach uses knowledge graphs implicitly, only during pre-training, to inject language models with structured knowledge via learning from raw text. It is more efficient than retrieval-based methods that perform entity linking and integration during finetuning and inference, and generalizes more effectively than the methods that directly learn from concatenated graph triples. Experiments show that our proposed model achieves improved performance on five benchmark datasets, including question answering and knowledge base completion tasks.
Role-Wise Data Augmentation for Knowledge Distillation
Apr 19, 2020
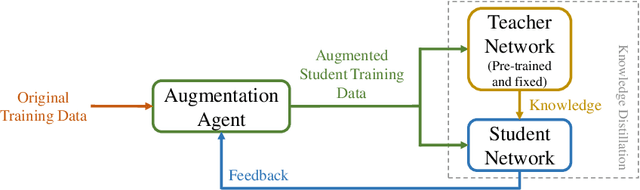
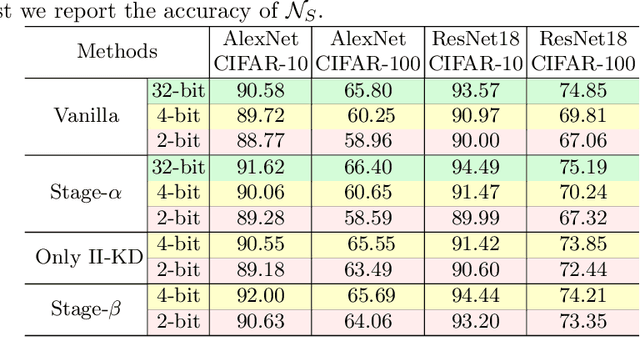

Knowledge Distillation (KD) is a common method for transferring the ``knowledge'' learned by one machine learning model (the \textit{teacher}) into another model (the \textit{student}), where typically, the teacher has a greater capacity (e.g., more parameters or higher bit-widths). To our knowledge, existing methods overlook the fact that although the student absorbs extra knowledge from the teacher, both models share the same input data -- and this data is the only medium by which the teacher's knowledge can be demonstrated. Due to the difference in model capacities, the student may not benefit fully from the same data points on which the teacher is trained. On the other hand, a human teacher may demonstrate a piece of knowledge with individualized examples adapted to a particular student, for instance, in terms of her cultural background and interests. Inspired by this behavior, we design data augmentation agents with distinct roles to facilitate knowledge distillation. Our data augmentation agents generate distinct training data for the teacher and student, respectively. We find empirically that specially tailored data points enable the teacher's knowledge to be demonstrated more effectively to the student. We compare our approach with existing KD methods on training popular neural architectures and demonstrate that role-wise data augmentation improves the effectiveness of KD over strong prior approaches. The code for reproducing our results can be found at https://github.com/bigaidream-projects/role-kd
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020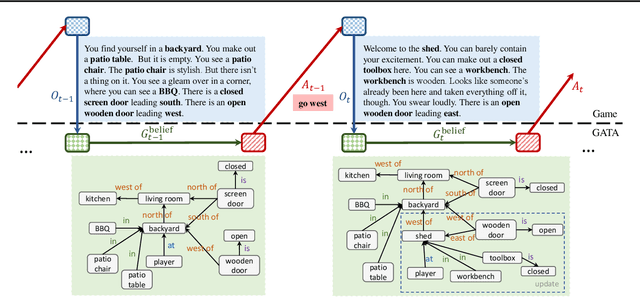

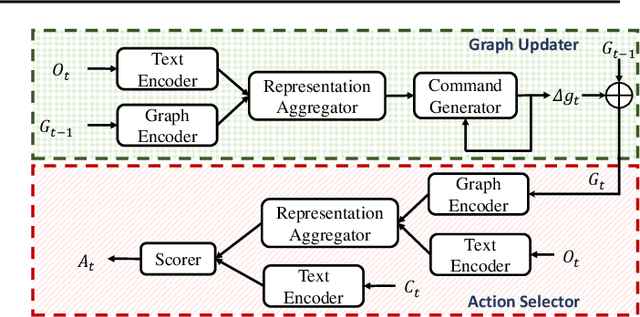
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.
Building Dynamic Knowledge Graphs from Text-based Games
Oct 22, 2019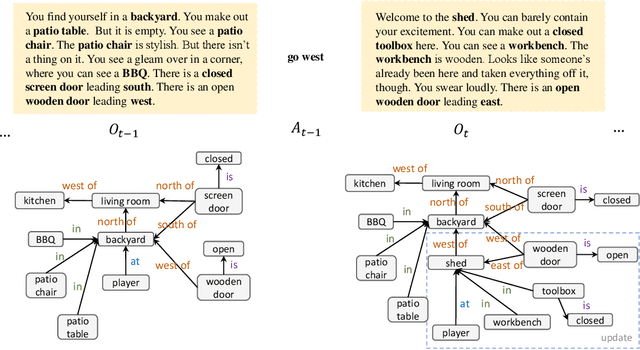

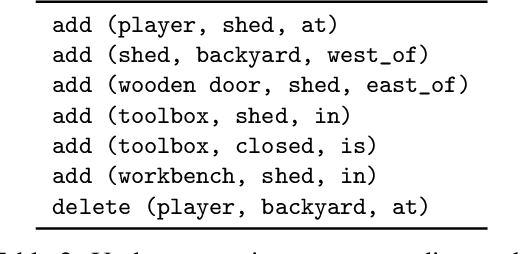
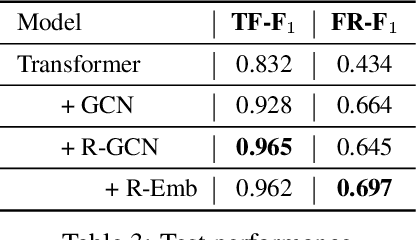
We are interested in learning how to update Knowledge Graphs (KG) from text. In this preliminary work, we propose a novel Sequence-to-Sequence (Seq2Seq) architecture to generate elementary KG operations. Furthermore, we introduce a new dataset for KG extraction built upon text-based game transitions (over 300k data points). We conduct experiments and discuss the results.
Does Order Matter? An Empirical Study on Generating Multiple Keyphrases as a Sequence
Oct 20, 2019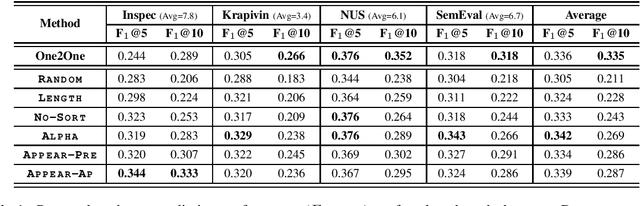
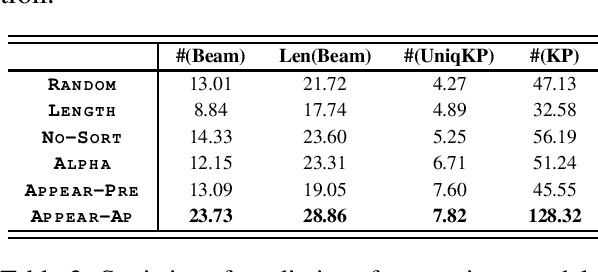
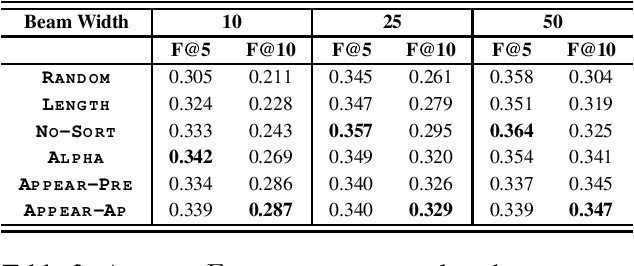
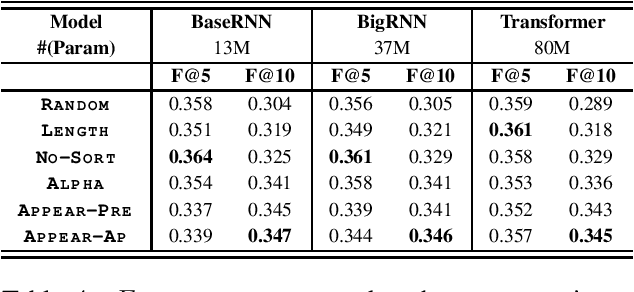
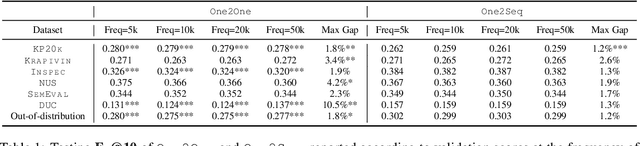
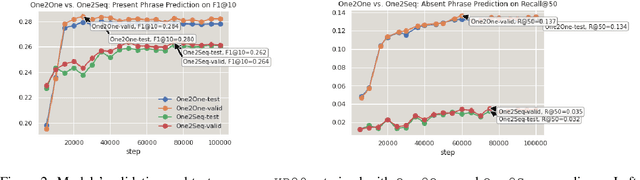
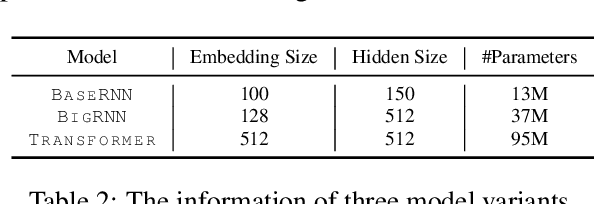
Recently, concatenating multiple keyphrases as a target sequence has been proposed as a new learning paradigm for keyphrase generation. Existing studies concatenate target keyphrases in different orders but no study has examined the effects of ordering on models' behavior. In this paper, we propose several orderings for concatenation and inspect the important factors for training a successful keyphrase generation model. By running comprehensive comparisons, we observe one preferable ordering and summarize a number of empirical findings and challenges, which can shed light on future research on this line of work.
Interactive Machine Comprehension with Information Seeking Agents
Sep 04, 2019
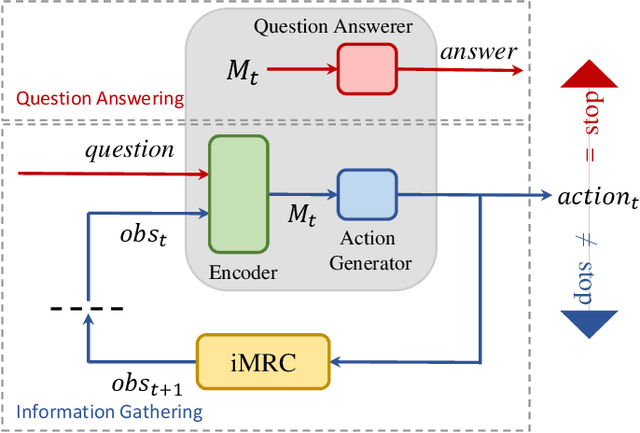
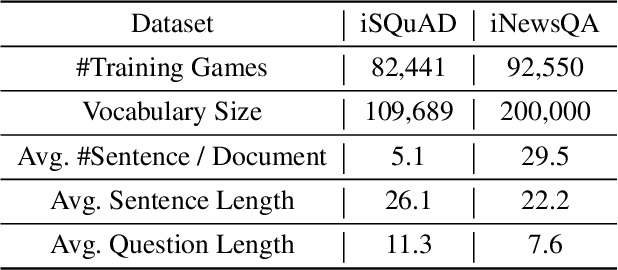
Existing machine reading comprehension (MRC) models do not scale effectively to real-world applications like web-level information retrieval and question answering (QA). We argue that this stems from the nature of MRC datasets: most of these are static environments wherein the supporting documents and all necessary information are fully observed. In this paper, we propose a simple method that reframes existing MRC datasets as interactive, partially observable environments. Specifically, we "occlude" the majority of a document's text and add context-sensitive commands that reveal "glimpses" of the hidden text to a model. We repurpose SQuAD and NewsQA as an initial case study, and then show how the interactive corpora can be used to train a model that seeks relevant information through sequential decision making. We believe that this setting can contribute in scaling models to web-level QA scenarios.
Interactive Language Learning by Question Answering
Aug 28, 2019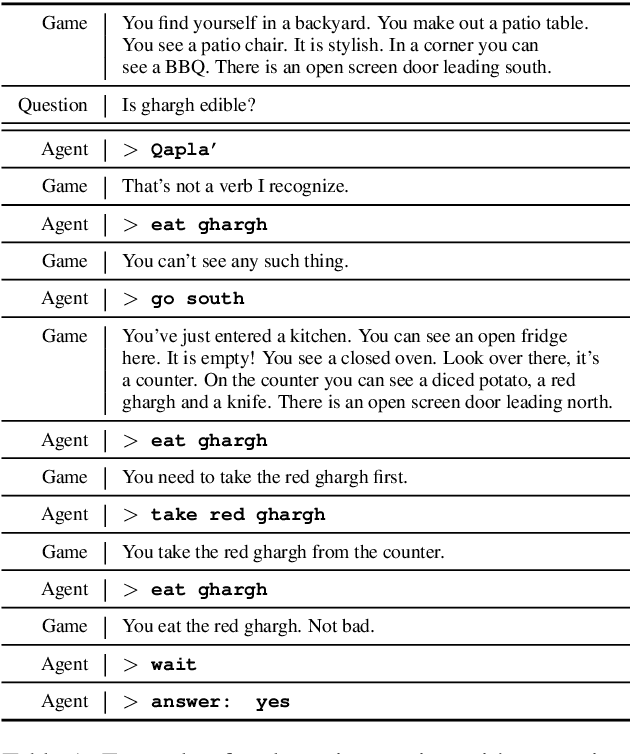
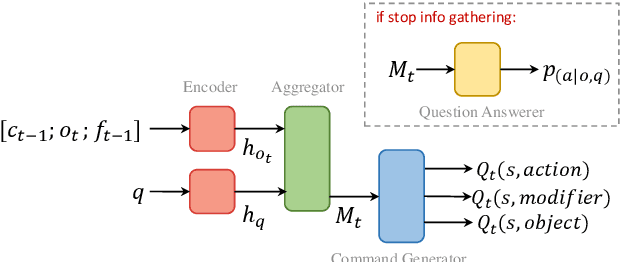
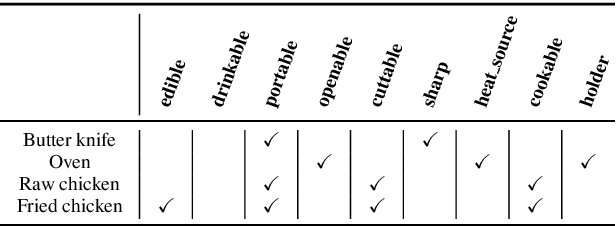
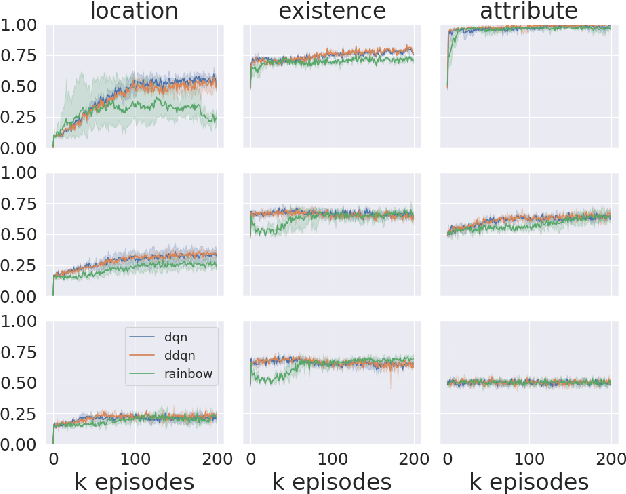
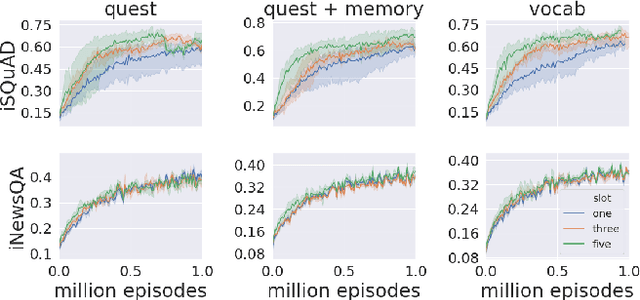
Humans observe and interact with the world to acquire knowledge. However, most existing machine reading comprehension (MRC) tasks miss the interactive, information-seeking component of comprehension. Such tasks present models with static documents that contain all necessary information, usually concentrated in a single short substring. Thus, models can achieve strong performance through simple word- and phrase-based pattern matching. We address this problem by formulating a novel text-based question answering task: Question Answering with Interactive Text (QAit). In QAit, an agent must interact with a partially observable text-based environment to gather information required to answer questions. QAit poses questions about the existence, location, and attributes of objects found in the environment. The data is built using a text-based game generator that defines the underlying dynamics of interaction with the environment. We propose and evaluate a set of baseline models for the QAit task that includes deep reinforcement learning agents. Experiments show that the task presents a major challenge for machine reading systems, while humans solve it with relative ease.
Metalearned Neural Memory
Jul 23, 2019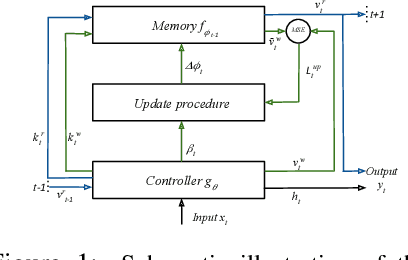
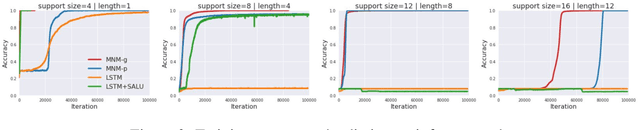

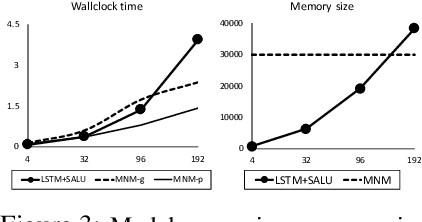
We augment recurrent neural networks with an external memory mechanism that builds upon recent progress in metalearning. We conceptualize this memory as a rapidly adaptable function that we parameterize as a deep neural network. Reading from the neural memory function amounts to pushing an input (the key vector) through the function to produce an output (the value vector). Writing to memory means changing the function; specifically, updating the parameters of the neural network to encode desired information. We leverage training and algorithmic techniques from metalearning to update the neural memory function in one shot. The proposed memory-augmented model achieves strong performance on a variety of learning problems, from supervised question answering to reinforcement learning.