 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Varied Learners for Binary Classification using Stacked Generalization
Feb 17, 2022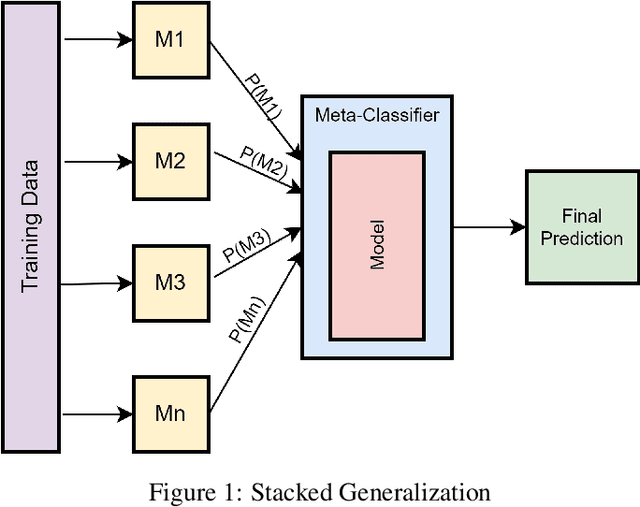
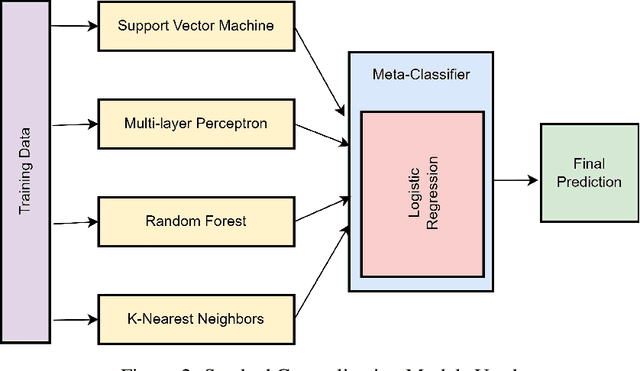
The Machine Learning has various learning algorithms that are better in some or the other aspect when compared with each other but a common error that all algorithms will suffer from is training data with very high dimensional feature set. This usually ends up algorithms into generalization error that deplete the performance. This can be solved using an Ensemble Learning method known as Stacking commonly termed as Stacked Generalization. In this paper we perform binary classification using Stacked Generalization on high dimensional Polycystic Ovary Syndrome dataset and prove the point that model becomes generalized and metrics improve significantly. The various metrics are given in this paper that also point out a subtle transgression found with Receiver Operating Characteristic Curve that was proved to be incorrect.
Binary Classification for High Dimensional Data using Supervised Non-Parametric Ensemble Method
Feb 15, 2022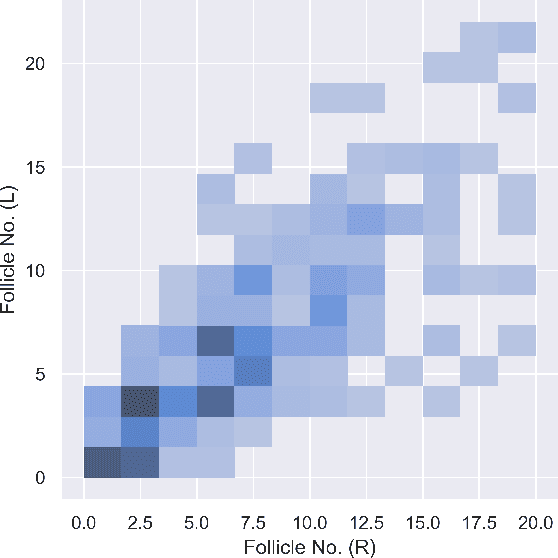

Medical Research data used for prognostication deals with binary classification problems in most of the cases. The endocrinological disorders have data available and it can be leveraged using Machine Learning. The dataset for Polycystic Ovary Syndrome is available, which is termed as an endocrinological disorder in women. Non-Parametric Supervised Ensemble machine learning methods can be used for prediction of the disorder in early stages. In this paper we present the Bootstrap Aggregation Supervised Ensemble Non-parametric method for prognostication that competes state-of-the-art performance with accuracy of over 92% along with in depth analysis of the data.
HAA4D: Few-Shot Human Atomic Action Recognition via 3D Spatio-Temporal Skeletal Alignment
Feb 15, 2022Human actions involve complex pose variations and their 2D projections can be highly ambiguous. Thus 3D spatio-temporal or 4D (i.e., 3D+T) human skeletons, which are photometric and viewpoint invariant, are an excellent alternative to 2D+T skeletons/pixels to improve action recognition accuracy. This paper proposes a new 4D dataset HAA4D which consists of more than 3,300 RGB videos in 300 human atomic action classes. HAA4D is clean, diverse, class-balanced where each class is viewpoint-balanced with the use of 4D skeletons, in which as few as one 4D skeleton per class is sufficient for training a deep recognition model. Further, the choice of atomic actions makes annotation even easier, because each video clip lasts for only a few seconds. All training and testing 3D skeletons in HAA4D are globally aligned, using a deep alignment model to the same global space, making each skeleton face the negative z-direction. Such alignment makes matching skeletons more stable by reducing intraclass variations and thus with fewer training samples per class needed for action recognition. Given the high diversity and skeletal alignment in HAA4D, we construct the first baseline few-shot 4D human atomic action recognition network without bells and whistles, which produces comparable or higher performance than relevant state-of-the-art techniques relying on embedded space encoding without explicit skeletal alignment, using the same small number of training samples of unseen classes.
State of AI Ethics Report (Volume 6, February 2022)
Feb 12, 2022This report from the Montreal AI Ethics Institute (MAIEI) covers the most salient progress in research and reporting over the second half of 2021 in the field of AI ethics. Particular emphasis is placed on an "Analysis of the AI Ecosystem", "Privacy", "Bias", "Social Media and Problematic Information", "AI Design and Governance", "Laws and Regulations", "Trends", and other areas covered in the "Outside the Boxes" section. The two AI spotlights feature application pieces on "Constructing and Deconstructing Gender with AI-Generated Art" as well as "Will an Artificial Intellichef be Cooking Your Next Meal at a Michelin Star Restaurant?". Given MAIEI's mission to democratize AI, submissions from external collaborators have featured, such as pieces on the "Challenges of AI Development in Vietnam: Funding, Talent and Ethics" and using "Representation and Imagination for Preventing AI Harms". The report is a comprehensive overview of what the key issues in the field of AI ethics were in 2021, what trends are emergent, what gaps exist, and a peek into what to expect from the field of AI ethics in 2022. It is a resource for researchers and practitioners alike in the field to set their research and development agendas to make contributions to the field of AI ethics.
Effects of Parametric and Non-Parametric Methods on High Dimensional Sparse Matrix Representations
Feb 07, 2022The semantics are derived from textual data that provide representations for Machine Learning algorithms. These representations are interpretable form of high dimensional sparse matrix that are given as an input to the machine learning algorithms. Since learning methods are broadly classified as parametric and non-parametric learning methods, in this paper we provide the effects of these type of algorithms on the high dimensional sparse matrix representations. In order to derive the representations from the text data, we have considered TF-IDF representation with valid reason in the paper. We have formed representations of 50, 100, 500, 1000 and 5000 dimensions respectively over which we have performed classification using Linear Discriminant Analysis and Naive Bayes as parametric learning method, Decision Tree and Support Vector Machines as non-parametric learning method. We have later provided the metrics on every single dimension of the representation and effect of every single algorithm detailed in this paper.
Change Detection of Markov Kernels with Unknown Post Change Kernel using Maximum Mean Discrepancy
Jan 27, 2022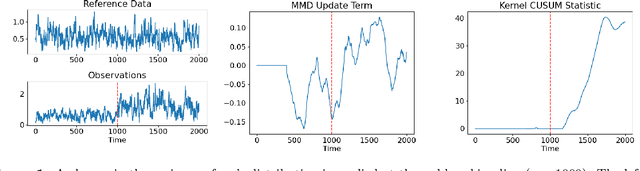
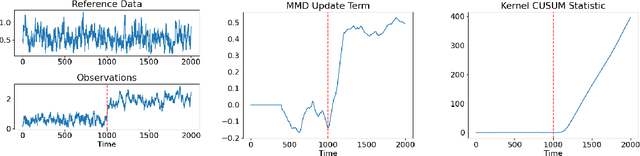
In this paper, we develop a new change detection algorithm for detecting a change in the Markov kernel over a metric space in which the post-change kernel is unknown. Under the assumption that the pre- and post-change Markov kernel is geometrically ergodic, we derive an upper bound on the mean delay and a lower bound on the mean time between false alarms.
Discriminant Analysis in Contrasting Dimensions for Polycystic Ovary Syndrome Prognostication
Jan 09, 2022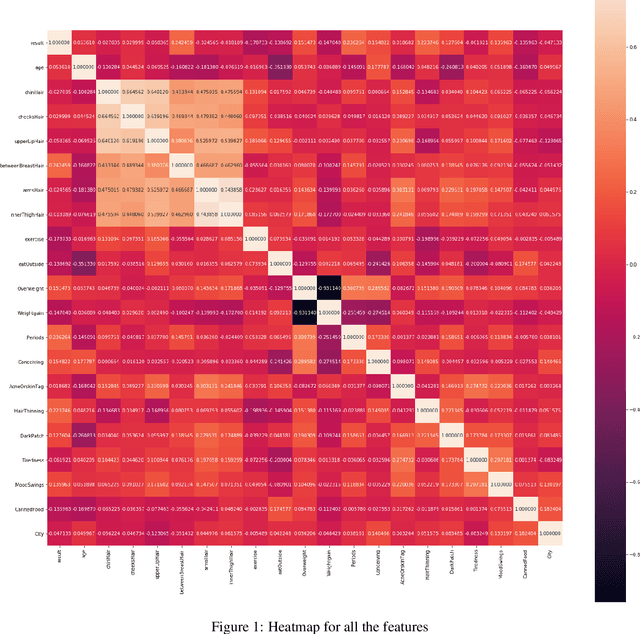

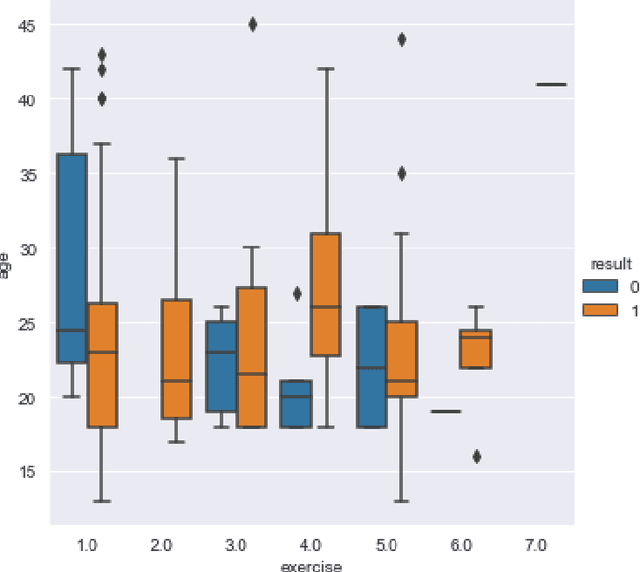

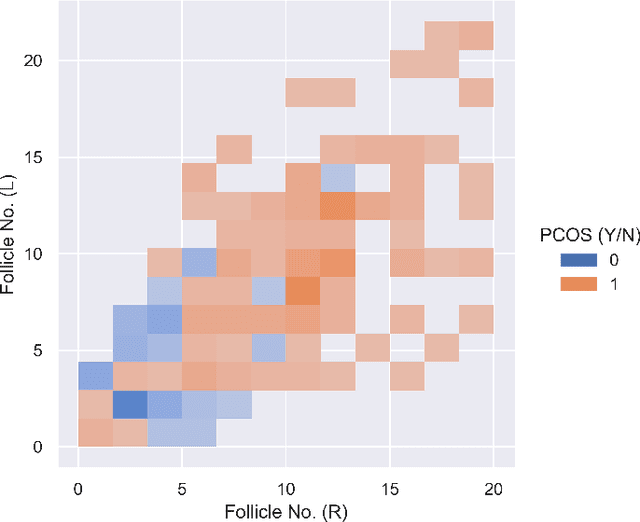
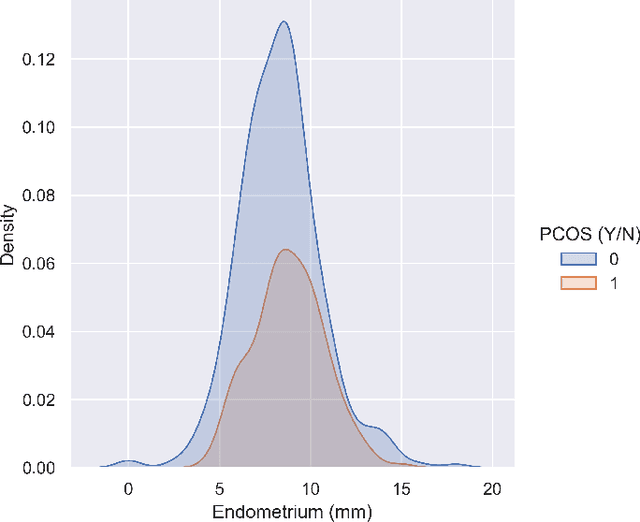
A lot of prognostication methodologies have been formulated for early detection of Polycystic Ovary Syndrome also known as PCOS using Machine Learning. PCOS is a binary classification problem. Dimensionality Reduction methods impact the performance of Machine Learning to a greater extent and using a Supervised Dimensionality Reduction method can give us a new edge to tackle this problem. In this paper we present Discriminant Analysis in different dimensions with Linear and Quadratic form for binary classification along with metrics. We were able to achieve good accuracy and less variation with Discriminant Analysis as compared to many commonly used classification algorithms with training accuracy reaching 97.37% and testing accuracy of 95.92% using Quadratic Discriminant Analysis. Paper also gives the analysis of data with visualizations for deeper understanding of problem.
Succinct Differentiation of Disparate Boosting Ensemble Learning Methods for Prognostication of Polycystic Ovary Syndrome Diagnosis
Jan 02, 2022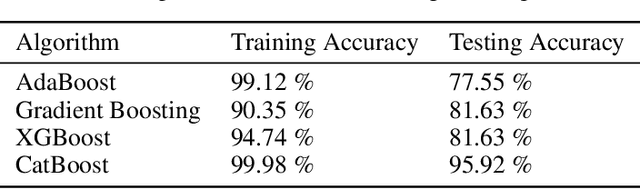
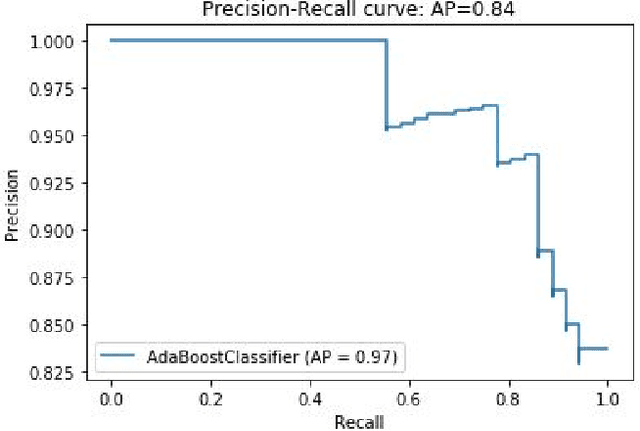
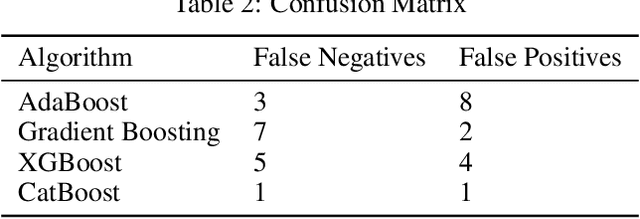
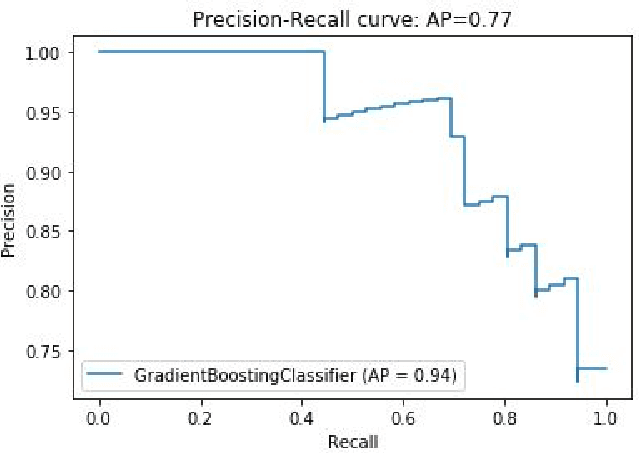
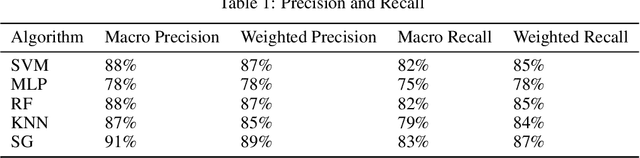
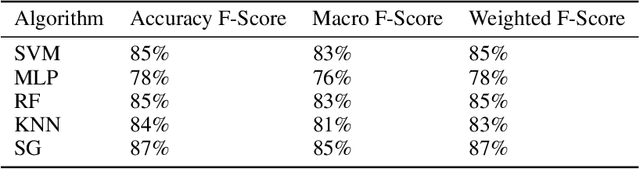
Prognostication of medical problems using the clinical data by leveraging the Machine Learning techniques with stellar precision is one of the most important real world challenges at the present time. Considering the medical problem of Polycystic Ovary Syndrome also known as PCOS is an emerging problem in women aged from 15 to 49. Diagnosing this disorder by using various Boosting Ensemble Methods is something we have presented in this paper. A detailed and compendious differentiation between Adaptive Boost, Gradient Boosting Machine, XGBoost and CatBoost with their respective performance metrics highlighting the hidden anomalies in the data and its effects on the result is something we have presented in this paper. Metrics like Confusion Matrix, Precision, Recall, F1 Score, FPR, RoC Curve and AUC have been used in this paper.
Autonomous Reinforcement Learning: Formalism and Benchmarking
Dec 17, 2021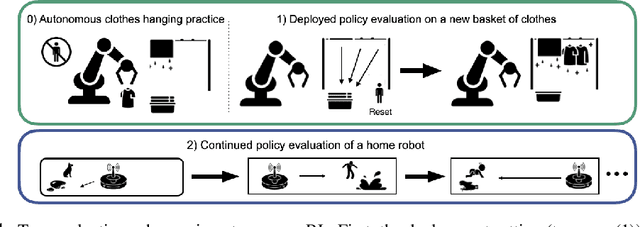

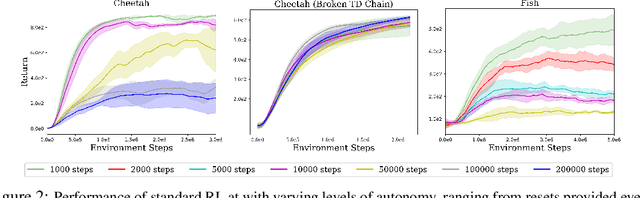

Reinforcement learning (RL) provides a naturalistic framing for learning through trial and error, which is appealing both because of its simplicity and effectiveness and because of its resemblance to how humans and animals acquire skills through experience. However, real-world embodied learning, such as that performed by humans and animals, is situated in a continual, non-episodic world, whereas common benchmark tasks in RL are episodic, with the environment resetting between trials to provide the agent with multiple attempts. This discrepancy presents a major challenge when attempting to take RL algorithms developed for episodic simulated environments and run them on real-world platforms, such as robots. In this paper, we aim to address this discrepancy by laying out a framework for Autonomous Reinforcement Learning (ARL): reinforcement learning where the agent not only learns through its own experience, but also contends with lack of human supervision to reset between trials. We introduce a simulated benchmark EARL around this framework, containing a set of diverse and challenging simulated tasks reflective of the hurdles introduced to learning when only a minimal reliance on extrinsic intervention can be assumed. We show that standard approaches to episodic RL and existing approaches struggle as interventions are minimized, underscoring the need for developing new algorithms for reinforcement learning with a greater focus on autonomy.
Offline RL With Resource Constrained Online Deployment
Oct 07, 2021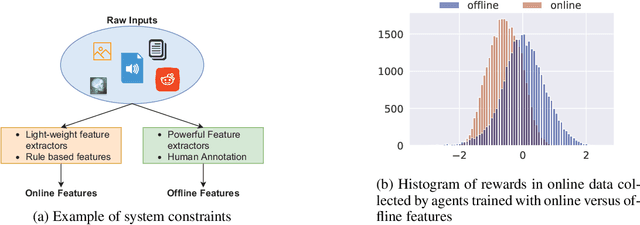


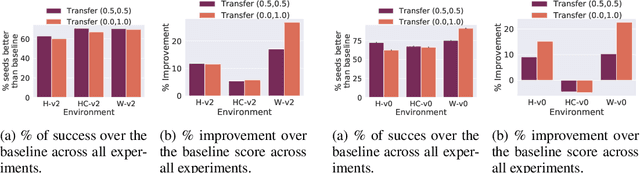
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.