 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked LARk: Masked Learning, Aggregation and Reporting worKflow
Oct 27, 2021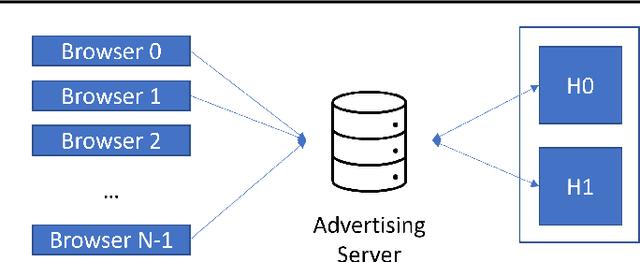
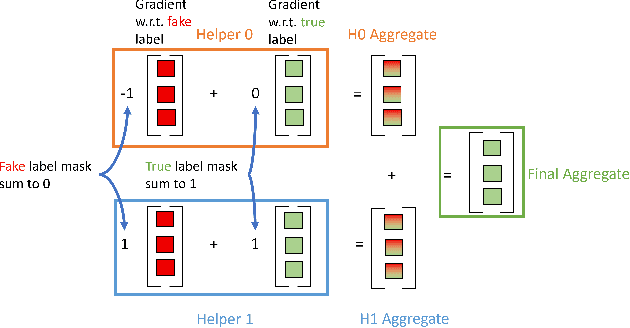
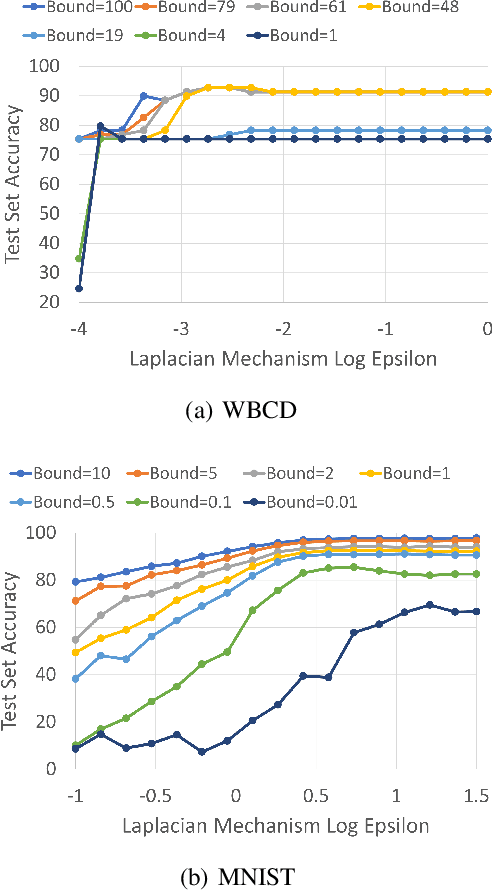
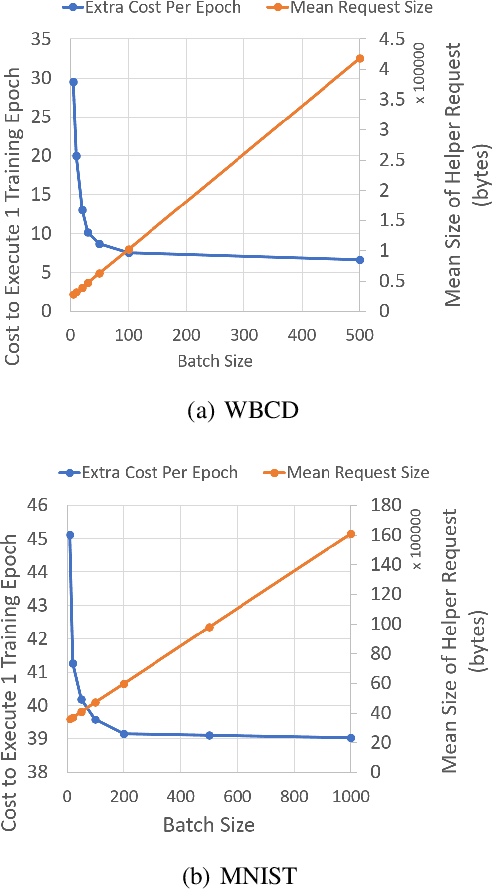
Today, many web advertising data flows involve passive cross-site tracking of users. Enabling such a mechanism through the usage of third party tracking cookies (3PC) exposes sensitive user data to a large number of parties, with little oversight on how that data can be used. Thus, most browsers are moving towards removal of 3PC in subsequent browser iterations. In order to substantially improve end-user privacy while allowing sites to continue to sustain their business through ad funding, new privacy-preserving primitives need to be introduced. In this paper, we discuss a new proposal, called Masked LARk, for aggregation of user engagement measurement and model training that prevents cross-site tracking, while remaining (a) flexible, for engineering development and maintenance, (b) secure, in the sense that cross-site tracking and tracing are blocked and (c) open for continued model development and training, allowing advertisers to serve relevant ads to interested users. We introduce a secure multi-party compute (MPC) protocol that utilizes "helper" parties to train models, so that once data leaves the browser, no downstream system can individually construct a complete picture of the user activity. For training, our key innovation is through the usage of masking, or the obfuscation of the true labels, while still allowing a gradient to be accurately computed in aggregate over a batch of data. Our protocol only utilizes light cryptography, at such a level that an interested yet inexperienced reader can understand the core algorithm. We develop helper endpoints that implement this system, and give example usage of training in PyTorch.
Offline RL With Resource Constrained Online Deployment
Oct 07, 2021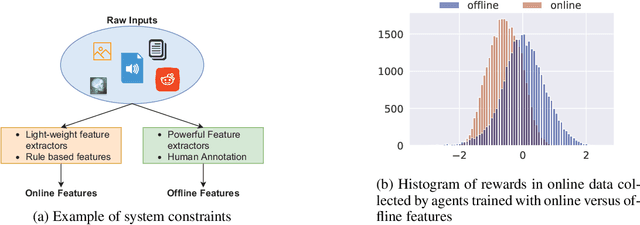


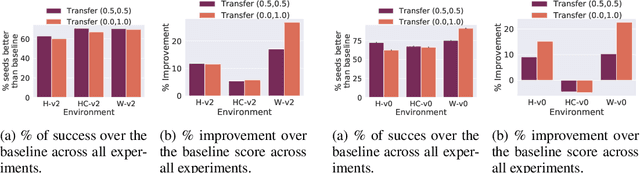
Offline reinforcement learning is used to train policies in scenarios where real-time access to the environment is expensive or impossible. As a natural consequence of these harsh conditions, an agent may lack the resources to fully observe the online environment before taking an action. We dub this situation the resource-constrained setting. This leads to situations where the offline dataset (available for training) can contain fully processed features (using powerful language models, image models, complex sensors, etc.) which are not available when actions are actually taken online. This disconnect leads to an interesting and unexplored problem in offline RL: Is it possible to use a richly processed offline dataset to train a policy which has access to fewer features in the online environment? In this work, we introduce and formalize this novel resource-constrained problem setting. We highlight the performance gap between policies trained using the full offline dataset and policies trained using limited features. We address this performance gap with a policy transfer algorithm which first trains a teacher agent using the offline dataset where features are fully available, and then transfers this knowledge to a student agent that only uses the resource-constrained features. To better capture the challenge of this setting, we propose a data collection procedure: Resource Constrained-Datasets for RL (RC-D4RL). We evaluate our transfer algorithm on RC-D4RL and the popular D4RL benchmarks and observe consistent improvement over the baseline (TD3+BC without transfer). The code for the experiments is available at https://github.com/JayanthRR/RC-OfflineRL}{github.com/RC-OfflineRL.
On the Equivalence between Online and Private Learnability beyond Binary Classification
Jun 02, 2020Alon et al. [2019] and Bun et al. [2020] recently showed that online learnability and private PAC learnability are equivalent in binary classification. We investigate whether this equivalence extends to multi-class classification and regression. First, we show that private learnability implies online learnability in both settings. Our extension involves studying a novel variant of the Littlestone dimension that depends on a tolerance parameter and on an appropriate generalization of the concept of threshold functions beyond binary classification. Second, we show that while online learnability continues to imply private learnability in multi-class classification, current proof techniques encounter significant hurdles in the regression setting. While the equivalence for regression remains open, we provide non-trivial sufficient conditions for an online learnable class to also be privately learnable.
Online Boosting for Multilabel Ranking with Top-k Feedback
Nov 06, 2019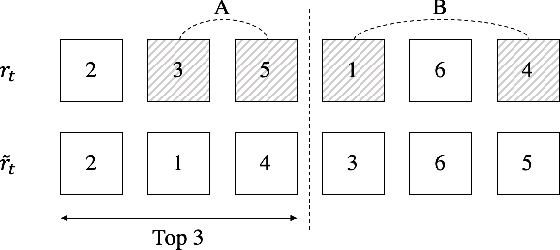
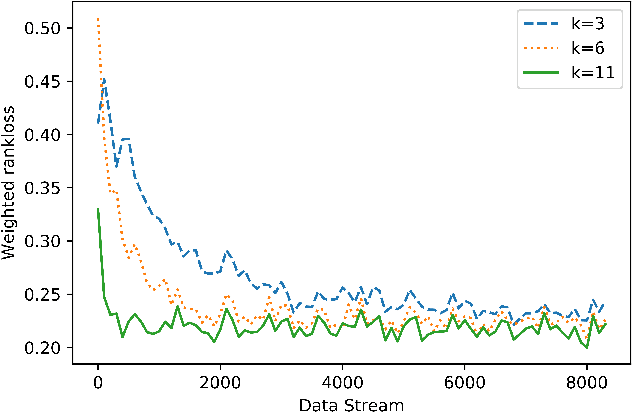

We present online boosting algorithms for multilabel ranking with top-k feedback,where the learner only receives information about the top-k items from the ranking it provides. We propose a novel surrogate loss function and unbiased estimator, allowing weak learners to update themselves with limited information. Using these techniques we adapt full information multilabel ranking algorithms (Jung and Tewari, 2018) to the top-k feedback setting and provide theoretical performance bounds which closely match the bounds of their full information counter parts, with the cost of increased sample complexity. The experimental results also verify these claims.
Thompson Sampling in Non-Episodic Restless Bandits
Oct 12, 2019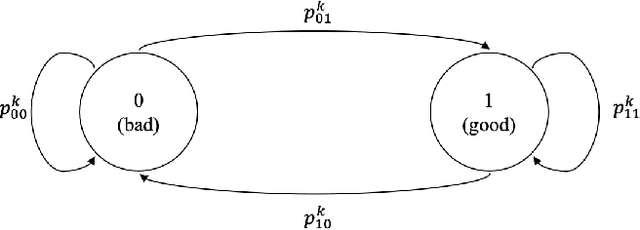
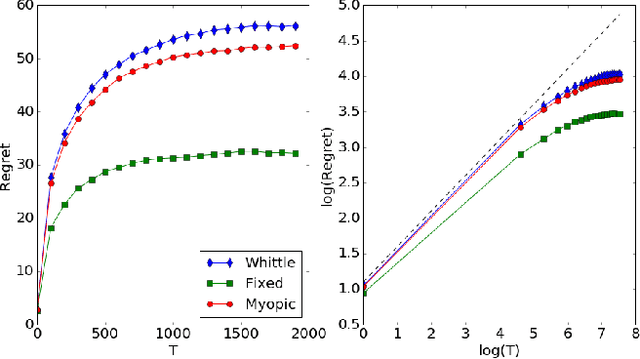
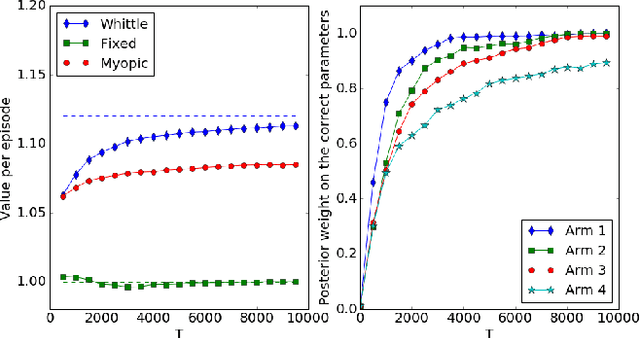
Restless bandit problems assume time-varying reward distributions of the arms, which adds flexibility to the model but makes the analysis more challenging. We study learning algorithms over the unknown reward distributions and prove a sub-linear, $O(\sqrt{T}\log T)$, regret bound for a variant of Thompson sampling. Our analysis applies in the infinite time horizon setting, resolving the open question raised by Jung and Tewari (2019) whose analysis is limited to the episodic case. We adopt their policy mapping framework, which allows our algorithm to be efficient and simultaneously keeps the regret meaningful. Our algorithm adapts the TSDE algorithm of Ouyang et al. (2017) in a non-trivial manner to account for the special structure of restless bandits. We test our algorithm on a simulated dynamic channel access problem with several policy mappings, and the empirical regrets agree with the theoretical bound regardless of the choice of the policy mapping.
Regret Bounds for Thompson Sampling in Restless Bandit Problems
May 29, 2019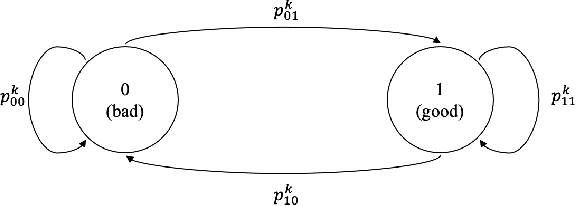
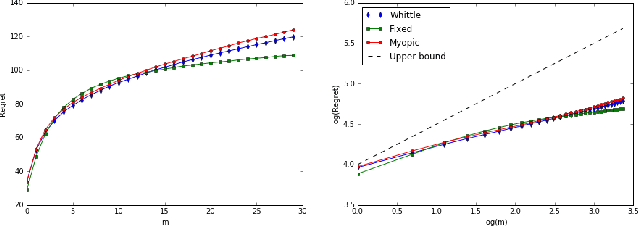
Restless bandit problems are instances of non-stationary multi-armed bandits. These problems have been studied well from the optimization perspective, where we aim to efficiently find a near-optimal policy when system parameters are known. However, very few papers adopt a learning perspective, where the parameters are unknown. In this paper, we analyze the performance of Thompson sampling in restless bandits with unknown parameters. We consider a general policy map to define our competitor and prove an $\tilde{O}(\sqrt{T})$ Bayesian regret bound. Our competitor is flexible enough to represent various benchmarks including the best fixed action policy, the optimal policy, the Whittle index policy, or the myopic policy. We also present empirical results that support our theoretical findings.
Online Multiclass Boosting with Bandit Feedback
Oct 11, 2018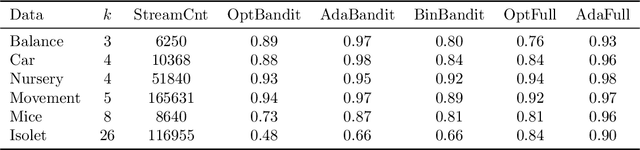
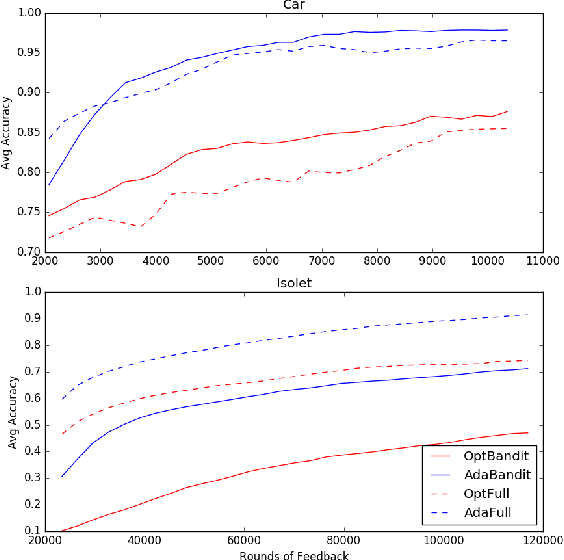
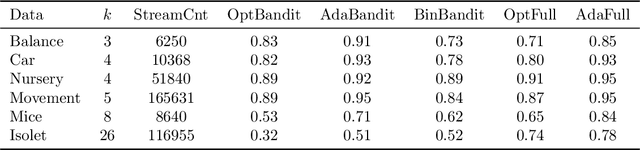
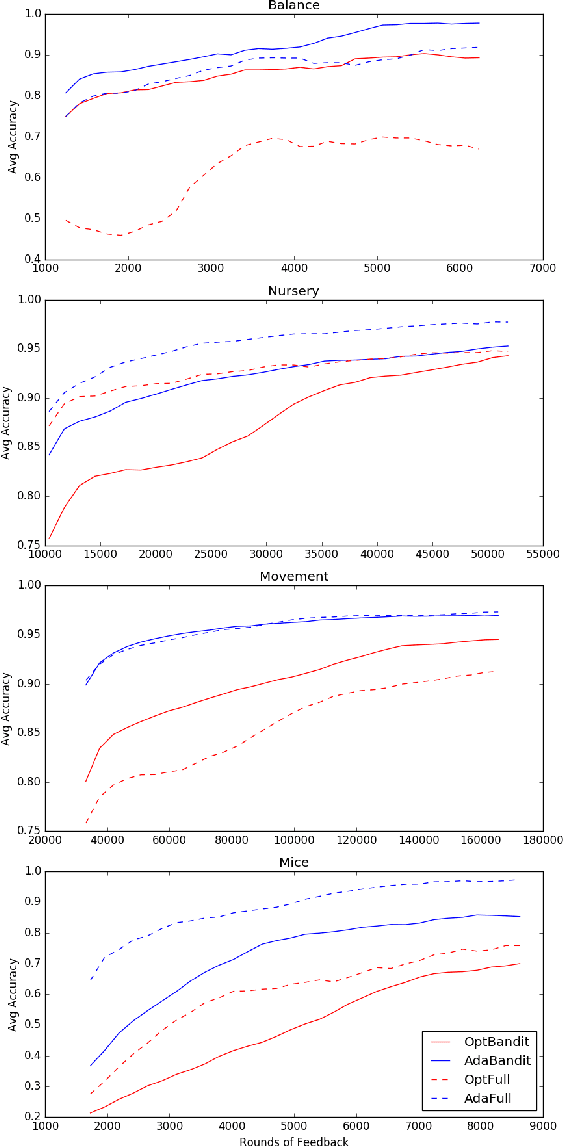
We present online boosting algorithms for multiclass classification with bandit feedback, where the learner only receives feedback about the correctness of its prediction. We propose an unbiased estimate of the loss using a randomized prediction, allowing the model to update its weak learners with limited information. Using the unbiased estimate, we extend two full information boosting algorithms (Jung et al., 2017) to the bandit setting. We prove that the asymptotic error bounds of the bandit algorithms exactly match their full information counterparts. The cost of restricted feedback is reflected in the larger sample complexity. Experimental results also support our theoretical findings, and performance of the proposed models is comparable to the that of an existing bandit boosting algorithm, which is limited to use binary weak learners.
Fighting Contextual Bandits with Stochastic Smoothing
Oct 11, 2018
We introduce a new stochastic smoothing perspective to study adversarial contextual bandit problems. We propose a general algorithm template that represents random perturbation based algorithms and identify several perturbation distributions that lead to strong regret bounds. Using the idea of smoothness, we provide an $O(\sqrt{T})$ zero-order bound for the vanilla algorithm and an $O(L^{*2/3}_{T})$ first-order bound for the clipped version. These bounds hold when the algorithms use with a variety of distributions that have a bounded hazard rate. Our algorithm template includes EXP4 as a special case corresponding to the Gumbel perturbation. Our regret bounds match existing results for EXP4 without relying on the specific properties of the algorithm.
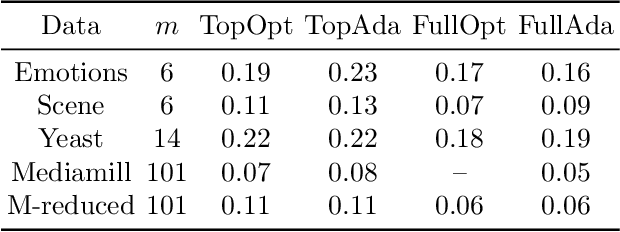
Online Boosting Algorithms for Multi-label Ranking
Feb 25, 2018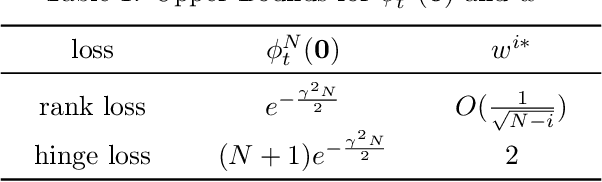
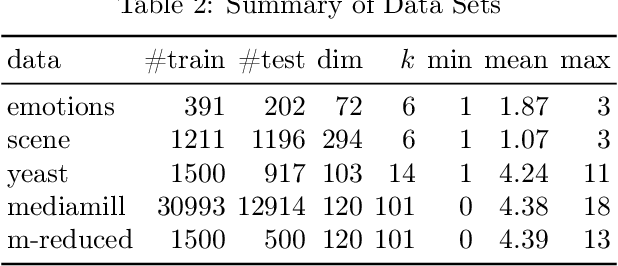
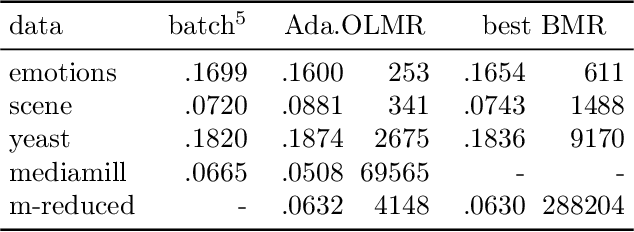
We consider the multi-label ranking approach to multi-label learning. Boosting is a natural method for multi-label ranking as it aggregates weak predictions through majority votes, which can be directly used as scores to produce a ranking of the labels. We design online boosting algorithms with provable loss bounds for multi-label ranking. We show that our first algorithm is optimal in terms of the number of learners required to attain a desired accuracy, but it requires knowledge of the edge of the weak learners. We also design an adaptive algorithm that does not require this knowledge and is hence more practical. Experimental results on real data sets demonstrate that our algorithms are at least as good as existing batch boosting algorithms.
Online Multiclass Boosting
Feb 25, 2018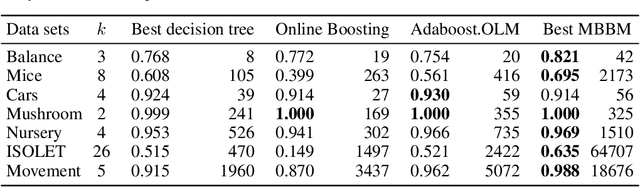
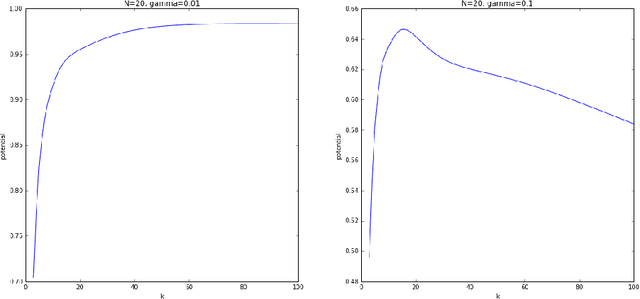
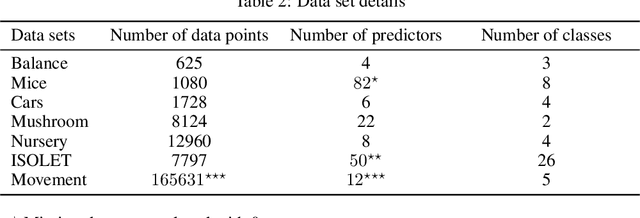
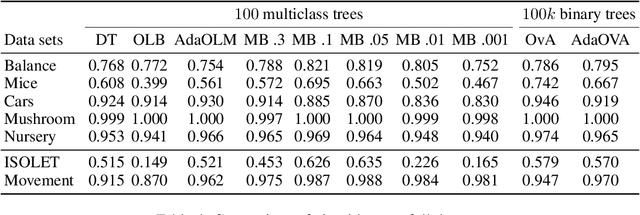
Recent work has extended the theoretical analysis of boosting algorithms to multiclass problems and to online settings. However, the multiclass extension is in the batch setting and the online extensions only consider binary classification. We fill this gap in the literature by defining, and justifying, a weak learning condition for online multiclass boosting. This condition leads to an optimal boosting algorithm that requires the minimal number of weak learners to achieve a certain accuracy. Additionally, we propose an adaptive algorithm which is near optimal and enjoys an excellent performance on real data due to its adaptive property.