 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Deep Linear Discriminant Analysis with Variation for Polycystic Ovary Syndrome Classification
Mar 25, 2023The polycystic ovary syndrome diagnosis is a problem that can be leveraged using prognostication based learning procedures. Many implementations of PCOS can be seen with Machine Learning but the algorithms have certain limitations in utilizing the processing power graphical processing units. The simple machine learning algorithms can be improved with advanced frameworks using Deep Learning. The Linear Discriminant Analysis is a linear dimensionality reduction algorithm for classification that can be boosted in terms of performance using deep learning with Deep LDA, a transformed version of the traditional LDA. In this result oriented paper we present the Deep LDA implementation with a variation for prognostication of PCOS.
Discriminant Analysis in Contrasting Dimensions for Polycystic Ovary Syndrome Prognostication
Jan 09, 2022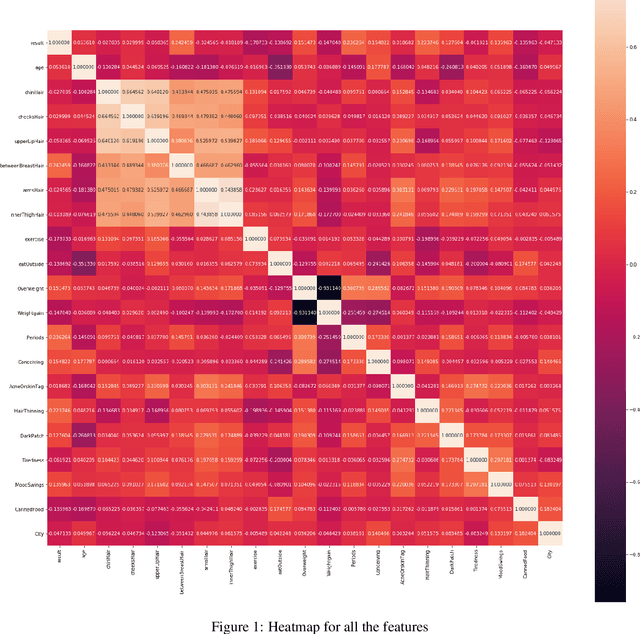

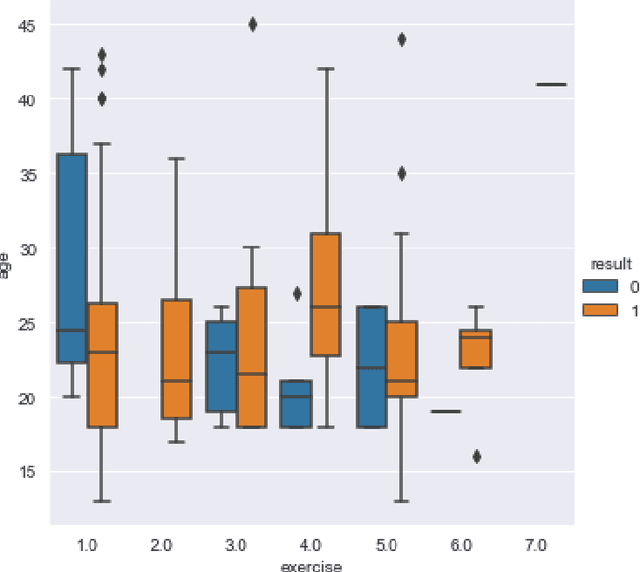

A lot of prognostication methodologies have been formulated for early detection of Polycystic Ovary Syndrome also known as PCOS using Machine Learning. PCOS is a binary classification problem. Dimensionality Reduction methods impact the performance of Machine Learning to a greater extent and using a Supervised Dimensionality Reduction method can give us a new edge to tackle this problem. In this paper we present Discriminant Analysis in different dimensions with Linear and Quadratic form for binary classification along with metrics. We were able to achieve good accuracy and less variation with Discriminant Analysis as compared to many commonly used classification algorithms with training accuracy reaching 97.37% and testing accuracy of 95.92% using Quadratic Discriminant Analysis. Paper also gives the analysis of data with visualizations for deeper understanding of problem.