 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Learning of Coupled Biogeochemical-Physical Models
Nov 12, 2022Predictive models for marine ecosystems are used for a variety of needs. Due to sparse measurements and limited understanding of the myriad of ocean processes, there is however uncertainty. There is model uncertainty in the parameter values, functional forms with diverse parameterizations, level of complexity needed, and thus in the state fields. We develop a principled Bayesian model learning methodology that allows interpolation in the space of candidate models and discovery of new models, all while estimating state fields and parameter values, as well as the joint probability distributions of all learned quantities. We address the challenges of high-dimensional and multidisciplinary dynamics governed by partial differential equations (PDEs) by using state augmentation and the computationally efficient Gaussian Mixture Model - Dynamically Orthogonal filter. Our innovations include special stochastic parameters to unify candidate models into a single general model and stochastic piecewise function approximations to generate dense candidate model spaces. They allow handling many candidate models, possibly none of which are accurate, and learning elusive unknown functional forms in compatible and embedded models. Our new methodology is generalizable and interpretable and extrapolates out of the space of models to discover new ones. We perform a series of twin experiments based on flows past a seamount coupled with three-to-five component ecosystem models, including flows with chaotic advection. We quantify learning skills, and evaluate convergence and sensitivity to hyper-parameters. Our PDE framework successfully discriminates among model candidates, learns in the absence of prior knowledge by searching in dense function spaces, and updates joint probabilities while capturing non-Gaussian statistics. The parameter values and model formulations that best explain the data are identified.
All the Feels: A dexterous hand with large area sensing
Oct 27, 2022



High cost and lack of reliability has precluded the widespread adoption of dexterous hands in robotics. Furthermore, the lack of a viable tactile sensor capable of sensing over the entire area of the hand impedes the rich, low-level feedback that would improve learning of dexterous manipulation skills. This paper introduces an inexpensive, modular, robust, and scalable platform - the DManus- aimed at resolving these challenges while satisfying the large-scale data collection capabilities demanded by deep robot learning paradigms. Studies on human manipulation point to the criticality of low-level tactile feedback in performing everyday dexterous tasks. The DManus comes with ReSkin sensing on the entire surface of the palm as well as the fingertips. We demonstrate effectiveness of the fully integrated system in a tactile aware task - bin picking and sorting. Code, documentation, design files, detailed assembly instructions, trained models, task videos, and all supplementary materials required to recreate the setup can be found on http://roboticsbenchmarks.org/platforms/dmanus
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022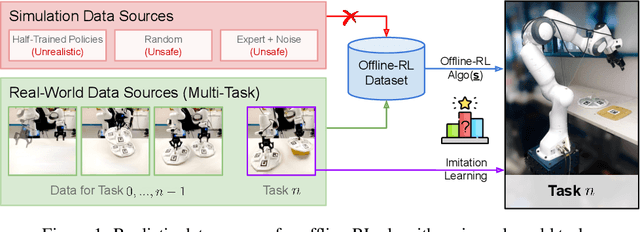

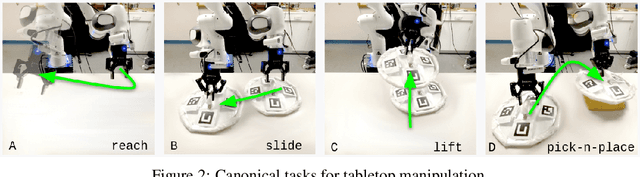
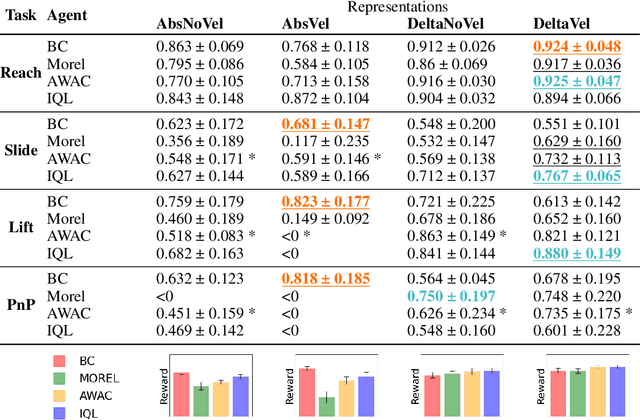
Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl
Learning State-Aware Visual Representations from Audible Interactions
Sep 27, 2022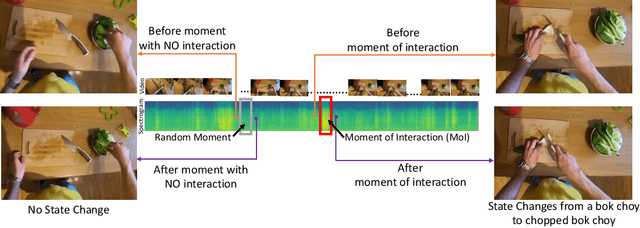

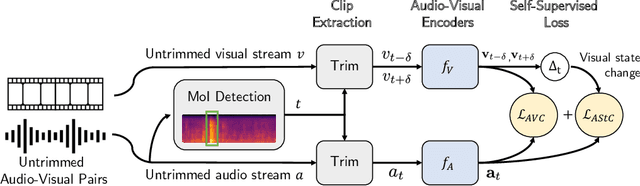
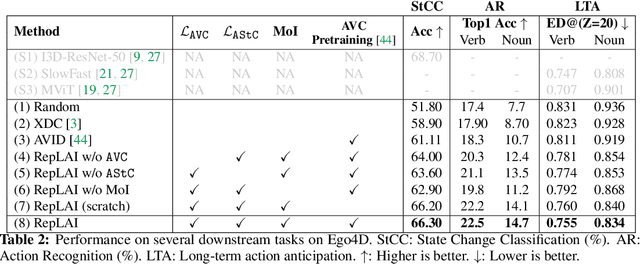
We propose a self-supervised algorithm to learn representations from egocentric video data. Recently, significant efforts have been made to capture humans interacting with their own environments as they go about their daily activities. In result, several large egocentric datasets of interaction-rich multi-modal data have emerged. However, learning representations from videos can be challenging. First, given the uncurated nature of long-form continuous videos, learning effective representations require focusing on moments in time when interactions take place. Second, visual representations of daily activities should be sensitive to changes in the state of the environment. However, current successful multi-modal learning frameworks encourage representation invariance over time. To address these challenges, we leverage audio signals to identify moments of likely interactions which are conducive to better learning. We also propose a novel self-supervised objective that learns from audible state changes caused by interactions. We validate these contributions extensively on two large-scale egocentric datasets, EPIC-Kitchens-100 and the recently released Ego4D, and show improvements on several downstream tasks, including action recognition, long-term action anticipation, and object state change classification.
Learning Dexterous Manipulation from Exemplar Object Trajectories and Pre-Grasps
Sep 22, 2022
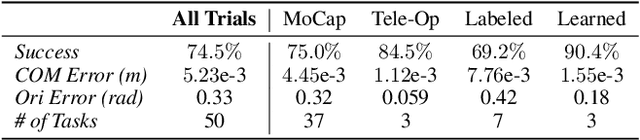
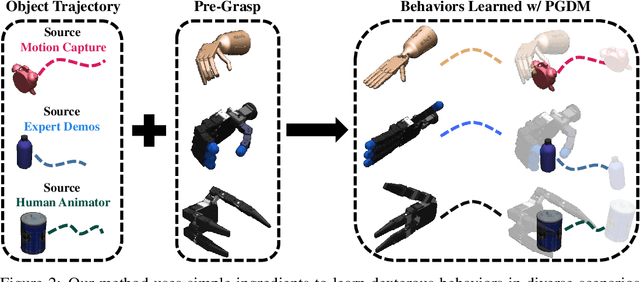

Learning diverse dexterous manipulation behaviors with assorted objects remains an open grand challenge. While policy learning methods offer a powerful avenue to attack this problem, they require extensive per-task engineering and algorithmic tuning. This paper seeks to escape these constraints, by developing a Pre-Grasp informed Dexterous Manipulation (PGDM) framework that generates diverse dexterous manipulation behaviors, without any task-specific reasoning or hyper-parameter tuning. At the core of PGDM is a well known robotics construct, pre-grasps (i.e. the hand-pose preparing for object interaction). This simple primitive is enough to induce efficient exploration strategies for acquiring complex dexterous manipulation behaviors. To exhaustively verify these claims, we introduce TCDM, a benchmark of 50 diverse manipulation tasks defined over multiple objects and dexterous manipulators. Tasks for TCDM are defined automatically using exemplar object trajectories from various sources (animators, human behaviors, etc.), without any per-task engineering and/or supervision. Our experiments validate that PGDM's exploration strategy, induced by a surprisingly simple ingredient (single pre-grasp pose), matches the performance of prior methods, which require expensive per-task feature/reward engineering, expert supervision, and hyper-parameter tuning. For animated visualizations, trained policies, and project code, please refer to: https://pregrasps.github.io/
Human-to-Robot Imitation in the Wild
Jul 19, 2022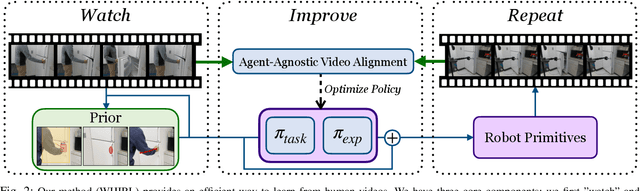



We approach the problem of learning by watching humans in the wild. While traditional approaches in Imitation and Reinforcement Learning are promising for learning in the real world, they are either sample inefficient or are constrained to lab settings. Meanwhile, there has been a lot of success in processing passive, unstructured human data. We propose tackling this problem via an efficient one-shot robot learning algorithm, centered around learning from a third-person perspective. We call our method WHIRL: In-the-Wild Human Imitating Robot Learning. WHIRL extracts a prior over the intent of the human demonstrator, using it to initialize our agent's policy. We introduce an efficient real-world policy learning scheme that improves using interactions. Our key contributions are a simple sampling-based policy optimization approach, a novel objective function for aligning human and robot videos as well as an exploration method to boost sample efficiency. We show one-shot generalization and success in real-world settings, including 20 different manipulation tasks in the wild. Videos and talk at https://human2robot.github.io
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
Apr 23, 2022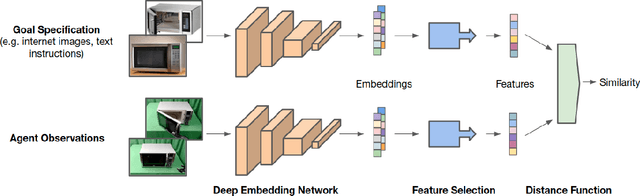
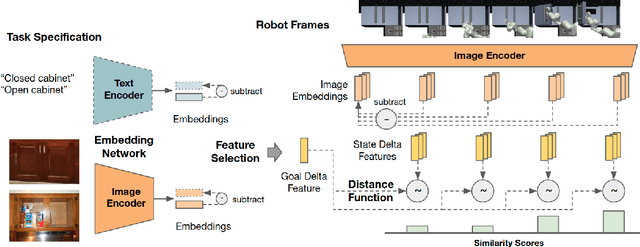
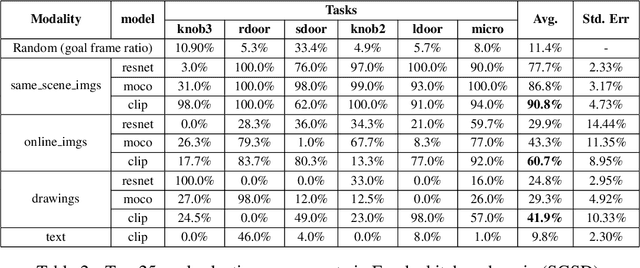

Task specification is at the core of programming autonomous robots. A low-effort modality for task specification is critical for engagement of non-expert end-users and ultimate adoption of personalized robot agents. A widely studied approach to task specification is through goals, using either compact state vectors or goal images from the same robot scene. The former is hard to interpret for non-experts and necessitates detailed state estimation and scene understanding. The latter requires the generation of desired goal image, which often requires a human to complete the task, defeating the purpose of having autonomous robots. In this work, we explore alternate and more general forms of goal specification that are expected to be easier for humans to specify and use such as images obtained from the internet, hand sketches that provide a visual description of the desired task, or simple language descriptions. As a preliminary step towards this, we investigate the capabilities of large scale pre-trained models (foundation models) for zero-shot goal specification, and find promising results in a collection of simulated robot manipulation tasks and real-world datasets.
What's in your hands? 3D Reconstruction of Generic Objects in Hands
Apr 14, 2022
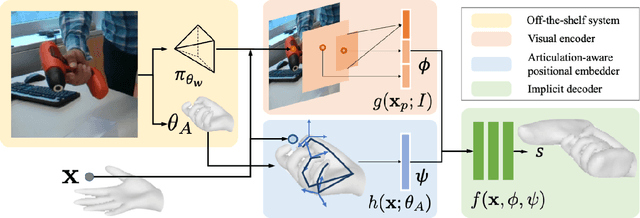

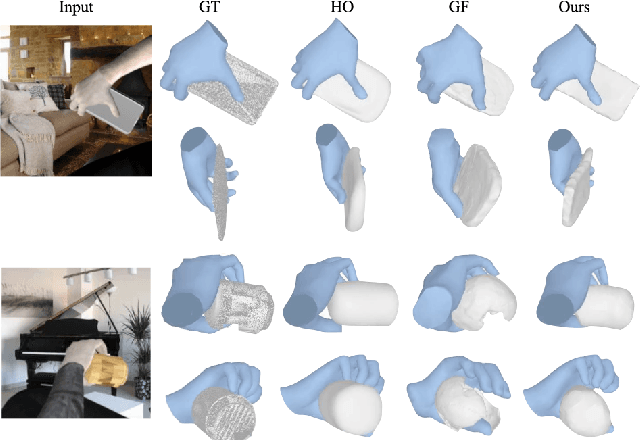
Our work aims to reconstruct hand-held objects given a single RGB image. In contrast to prior works that typically assume known 3D templates and reduce the problem to 3D pose estimation, our work reconstructs generic hand-held object without knowing their 3D templates. Our key insight is that hand articulation is highly predictive of the object shape, and we propose an approach that conditionally reconstructs the object based on the articulation and the visual input. Given an image depicting a hand-held object, we first use off-the-shelf systems to estimate the underlying hand pose and then infer the object shape in a normalized hand-centric coordinate frame. We parameterized the object by signed distance which are inferred by an implicit network which leverages the information from both visual feature and articulation-aware coordinates to process a query point. We perform experiments across three datasets and show that our method consistently outperforms baselines and is able to reconstruct a diverse set of objects. We analyze the benefits and robustness of explicit articulation conditioning and also show that this allows the hand pose estimation to further improve in test-time optimization.
Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction
Apr 07, 2022

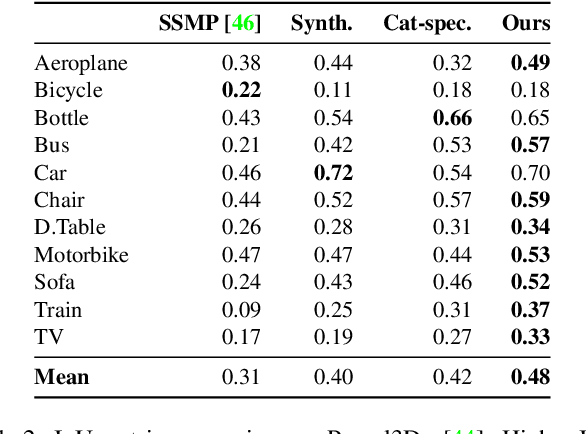
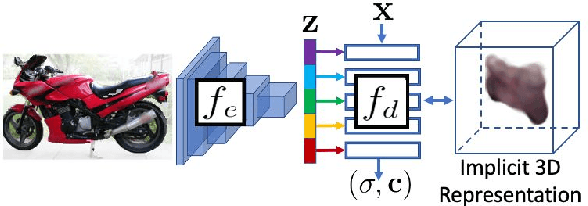
Our work learns a unified model for single-view 3D reconstruction of objects from hundreds of semantic categories. As a scalable alternative to direct 3D supervision, our work relies on segmented image collections for learning 3D of generic categories. Unlike prior works that use similar supervision but learn independent category-specific models from scratch, our approach of learning a unified model simplifies the training process while also allowing the model to benefit from the common structure across categories. Using image collections from standard recognition datasets, we show that our approach allows learning 3D inference for over 150 object categories. We evaluate using two datasets and qualitatively and quantitatively show that our unified reconstruction approach improves over prior category-specific reconstruction baselines. Our final 3D reconstruction model is also capable of zero-shot inference on images from unseen object categories and we empirically show that increasing the number of training categories improves the reconstruction quality.
The Challenges of Continuous Self-Supervised Learning
Mar 28, 2022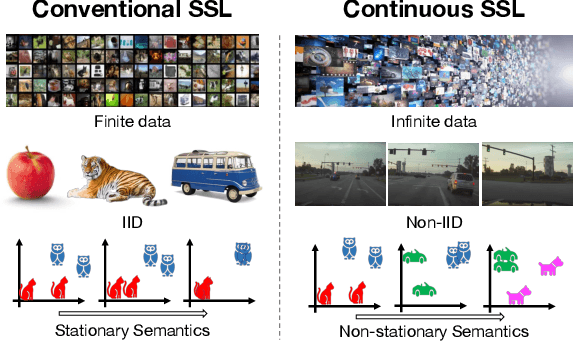
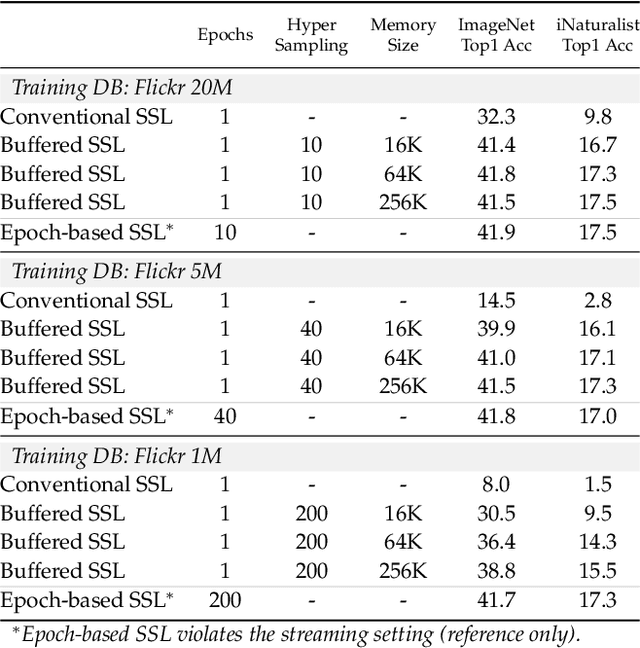
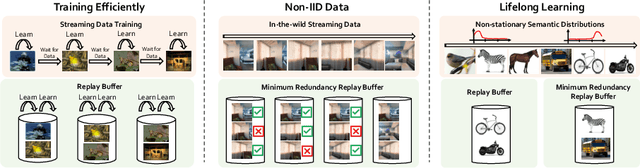
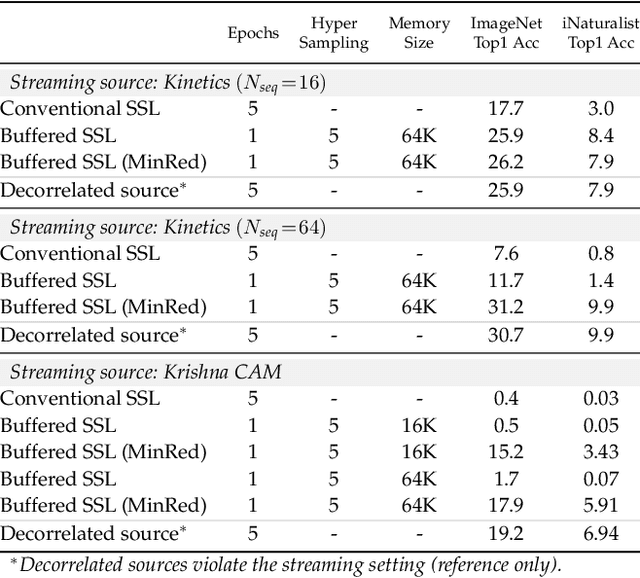
Self-supervised learning (SSL) aims to eliminate one of the major bottlenecks in representation learning - the need for human annotations. As a result, SSL holds the promise to learn representations from data in-the-wild, i.e., without the need for finite and static datasets. Instead, true SSL algorithms should be able to exploit the continuous stream of data being generated on the internet or by agents exploring their environments. But do traditional self-supervised learning approaches work in this setup? In this work, we investigate this question by conducting experiments on the continuous self-supervised learning problem. While learning in the wild, we expect to see a continuous (infinite) non-IID data stream that follows a non-stationary distribution of visual concepts. The goal is to learn a representation that can be robust, adaptive yet not forgetful of concepts seen in the past. We show that a direct application of current methods to such continuous setup is 1) inefficient both computationally and in the amount of data required, 2) leads to inferior representations due to temporal correlations (non-IID data) in some sources of streaming data and 3) exhibits signs of catastrophic forgetting when trained on sources with non-stationary data distributions. We propose the use of replay buffers as an approach to alleviate the issues of inefficiency and temporal correlations. We further propose a novel method to enhance the replay buffer by maintaining the least redundant samples. Minimum redundancy (MinRed) buffers allow us to learn effective representations even in the most challenging streaming scenarios composed of sequential visual data obtained from a single embodied agent, and alleviates the problem of catastrophic forgetting when learning from data with non-stationary semantic distributions.