 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee, Point, Refine: Multi-Turn Approach to GUI Grounding with Visual Feedback
Apr 14, 2026Computer Use Agents (CUAs) fundamentally rely on graphical user interface (GUI) grounding to translate language instructions into executable screen actions, but editing-level grounding in dense coding interfaces, where sub-pixel accuracy is required to interact with dense IDE elements, remains underexplored. Existing approaches typically rely on single-shot coordinate prediction, which lacks a mechanism for error correction and often fails in high-density interfaces. In this technical report, we conduct an empirical study of pixel-precise cursor localization in coding environments. Instead of a single-step execution, our agent engages in an iterative refinement process, utilizing visual feedback from previous attempts to reach the target element. This closed-loop grounding mechanism allows the agent to self-correct displacement errors and adapt to dynamic UI changes. We evaluate our approach across GPT-5.4, Claude, and Qwen on a suite of complex coding benchmarks, demonstrating that multi-turn refinement significantly outperforms state-of-the-art single-shot models in both click precision and overall task success rate. Our results suggest that iterative visual reasoning is a critical component for the next generation of reliable software engineering agents. Code: https://github.com/microsoft/precision-cua-bench.
WiCV at CVPR 2025: The Women in Computer Vision Workshop
Nov 11, 2025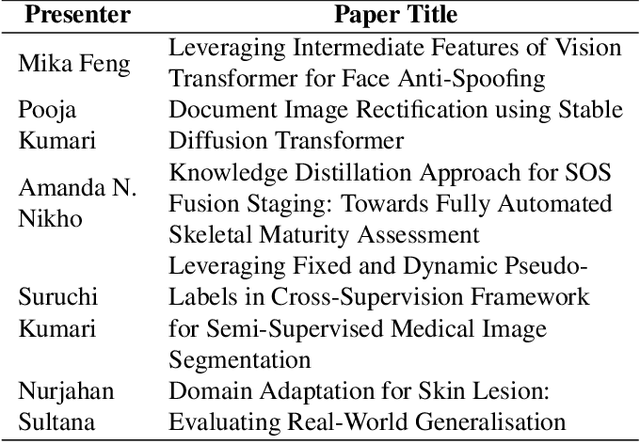
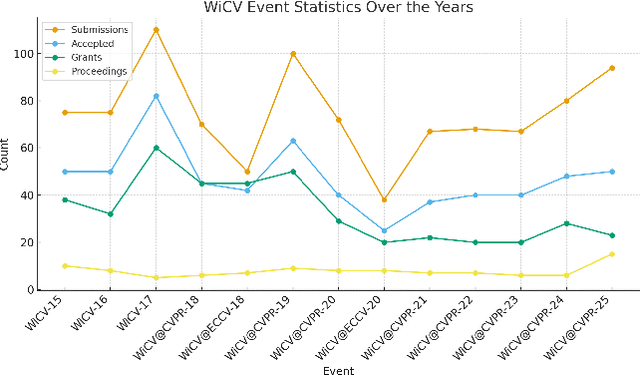
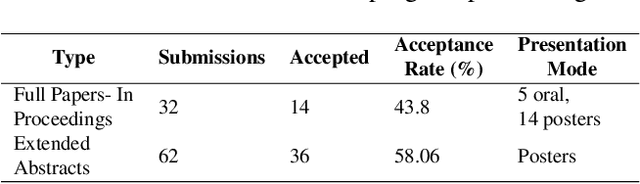

The Women in Computer Vision Workshop (WiCV@CVPR 2025) was held in conjunction with the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025) in Nashville, Tennessee, United States. This report presents an overview of the workshop program, participation statistics, mentorship outcomes, and historical trends from previous WiCV editions. The goal is to document the impact and evolution of WiCV as a reference for future editions and for other initiatives aimed at advancing diversity, equity, and inclusion within the AI and computer vision communities. WiCV@CVPR 2025 marked the 16th edition of this long-standing event dedicated to increasing the visibility, inclusion, and professional growth of women and underrepresented minorities in the computer vision community. This year's workshop featured 14 accepted papers in the CVPR Workshop Proceedings out of 32 full-paper submissions. Five of these were selected for oral presentations, while all 14 were also presented as posters, along with 36 extended abstract posters accepted from 62 short-paper submissions, which are not included in the proceedings. The mentoring program matched 80 mentees with 37 mentors from both academia and industry. The 2025 edition attracted over 100 onsite participants, fostering rich technical and networking interactions across all career stages. Supported by 10 sponsors and approximately $44,000 USD in travel grants and diversity awards, WiCV continued its mission to empower emerging researchers and amplify diverse voices in computer vision.
UniPhy: Learning a Unified Constitutive Model for Inverse Physics Simulation
May 22, 2025We propose UniPhy, a common latent-conditioned neural constitutive model that can encode the physical properties of diverse materials. At inference UniPhy allows `inverse simulation' i.e. inferring material properties by optimizing the scene-specific latent to match the available observations via differentiable simulation. In contrast to existing methods that treat such inference as system identification, UniPhy does not rely on user-specified material type information. Compared to prior neural constitutive modeling approaches which learn instance specific networks, the shared training across materials improves both, robustness and accuracy of the estimates. We train UniPhy using simulated trajectories across diverse geometries and materials -- elastic, plasticine, sand, and fluids (Newtonian & non-Newtonian). At inference, given an object with unknown material properties, UniPhy can infer the material properties via latent optimization to match the motion observations, and can then allow re-simulating the object under diverse scenarios. We compare UniPhy against prior inverse simulation methods, and show that the inference from UniPhy enables more accurate replay and re-simulation under novel conditions.
WiCV@CVPR2024: The Thirteenth Women In Computer Vision Workshop at the Annual CVPR Conference
Nov 03, 2024In this paper, we present the details of Women in Computer Vision Workshop - WiCV 2024, organized alongside the CVPR 2024 in Seattle, Washington, United States. WiCV aims to amplify the voices of underrepresented women in the computer vision community, fostering increased visibility in both academia and industry. We believe that such events play a vital role in addressing gender imbalances within the field. The annual WiCV@CVPR workshop offers a)~opportunity for collaboration between researchers from minority groups, b) mentorship for female junior researchers, c) financial support to presenters to alleviate financial burdens and d)~a diverse array of role models who can inspire younger researchers at the outset of their careers. In this paper, we present a comprehensive report on the workshop program, historical trends from the past WiCV@CVPR events, and a summary of statistics related to presenters, attendees, and sponsorship for the WiCV 2024 workshop.
Can't make an Omelette without Breaking some Eggs: Plausible Action Anticipation using Large Video-Language Models
May 30, 2024



We introduce PlausiVL, a large video-language model for anticipating action sequences that are plausible in the real-world. While significant efforts have been made towards anticipating future actions, prior approaches do not take into account the aspect of plausibility in an action sequence. To address this limitation, we explore the generative capability of a large video-language model in our work and further, develop the understanding of plausibility in an action sequence by introducing two objective functions, a counterfactual-based plausible action sequence learning loss and a long-horizon action repetition loss. We utilize temporal logical constraints as well as verb-noun action pair logical constraints to create implausible/counterfactual action sequences and use them to train the model with plausible action sequence learning loss. This loss helps the model to differentiate between plausible and not plausible action sequences and also helps the model to learn implicit temporal cues crucial for the task of action anticipation. The long-horizon action repetition loss puts a higher penalty on the actions that are more prone to repetition over a longer temporal window. With this penalization, the model is able to generate diverse, plausible action sequences. We evaluate our approach on two large-scale datasets, Ego4D and EPIC-Kitchens-100, and show improvements on the task of action anticipation.
Learning State-Aware Visual Representations from Audible Interactions
Sep 27, 2022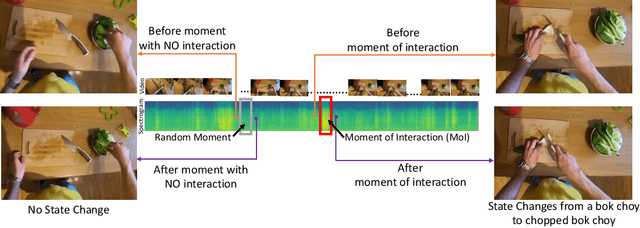

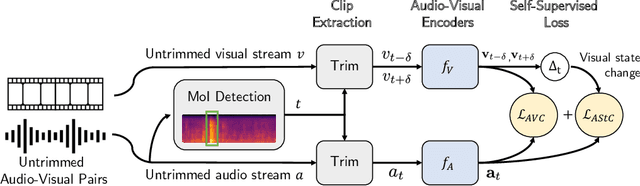
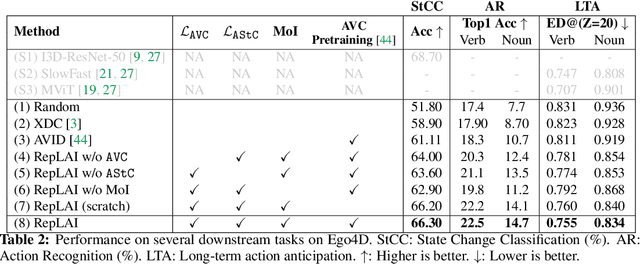
We propose a self-supervised algorithm to learn representations from egocentric video data. Recently, significant efforts have been made to capture humans interacting with their own environments as they go about their daily activities. In result, several large egocentric datasets of interaction-rich multi-modal data have emerged. However, learning representations from videos can be challenging. First, given the uncurated nature of long-form continuous videos, learning effective representations require focusing on moments in time when interactions take place. Second, visual representations of daily activities should be sensitive to changes in the state of the environment. However, current successful multi-modal learning frameworks encourage representation invariance over time. To address these challenges, we leverage audio signals to identify moments of likely interactions which are conducive to better learning. We also propose a novel self-supervised objective that learns from audible state changes caused by interactions. We validate these contributions extensively on two large-scale egocentric datasets, EPIC-Kitchens-100 and the recently released Ego4D, and show improvements on several downstream tasks, including action recognition, long-term action anticipation, and object state change classification.
Self-Supervised Point Cloud Completion via Inpainting
Nov 21, 2021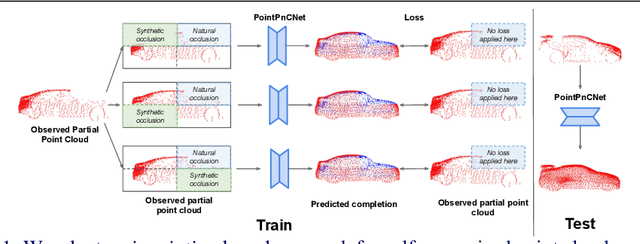
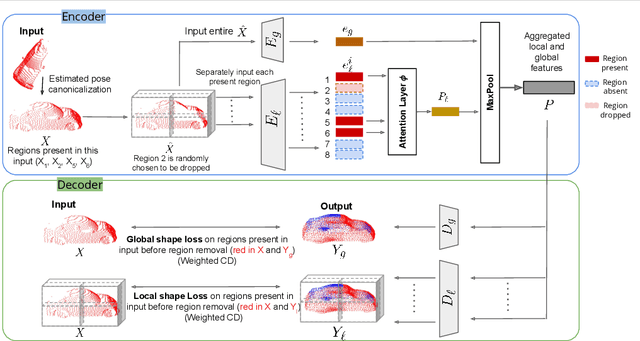
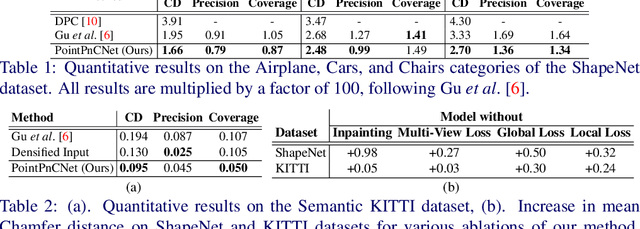

When navigating in urban environments, many of the objects that need to be tracked and avoided are heavily occluded. Planning and tracking using these partial scans can be challenging. The aim of this work is to learn to complete these partial point clouds, giving us a full understanding of the object's geometry using only partial observations. Previous methods achieve this with the help of complete, ground-truth annotations of the target objects, which are available only for simulated datasets. However, such ground truth is unavailable for real-world LiDAR data. In this work, we present a self-supervised point cloud completion algorithm, PointPnCNet, which is trained only on partial scans without assuming access to complete, ground-truth annotations. Our method achieves this via inpainting. We remove a portion of the input data and train the network to complete the missing region. As it is difficult to determine which regions were occluded in the initial cloud and which were synthetically removed, our network learns to complete the full cloud, including the missing regions in the initial partial cloud. We show that our method outperforms previous unsupervised and weakly-supervised methods on both the synthetic dataset, ShapeNet, and real-world LiDAR dataset, Semantic KITTI.
Interpreting Context of Images using Scene Graphs
Dec 01, 2019
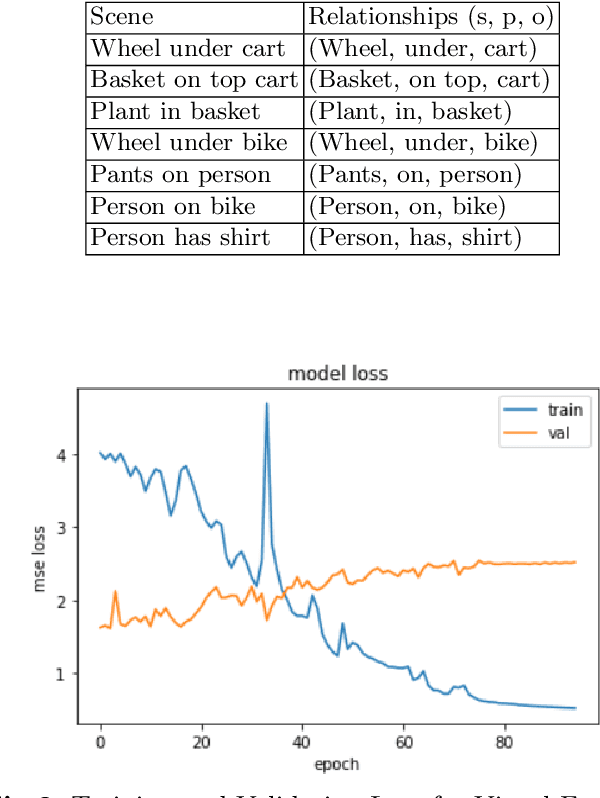

Understanding a visual scene incorporates objects, relationships, and context. Traditional methods working on an image mostly focus on object detection and fail to capture the relationship between the objects. Relationships can give rich semantic information about the objects in a scene. The context can be conducive to comprehending an image since it will help us to perceive the relation between the objects and thus, give us a deeper insight into the image. Through this idea, our project delivers a model that focuses on finding the context present in an image by representing the image as a graph, where the nodes will the objects and edges will be the relation between them. The context is found using the visual and semantic cues which are further concatenated and given to the Support Vector Machines (SVM) to detect the relation between two objects. This presents us with the context of the image which can be further used in applications such as similar image retrieval, image captioning, or story generation.
Just Go with the Flow: Self-Supervised Scene Flow Estimation
Dec 01, 2019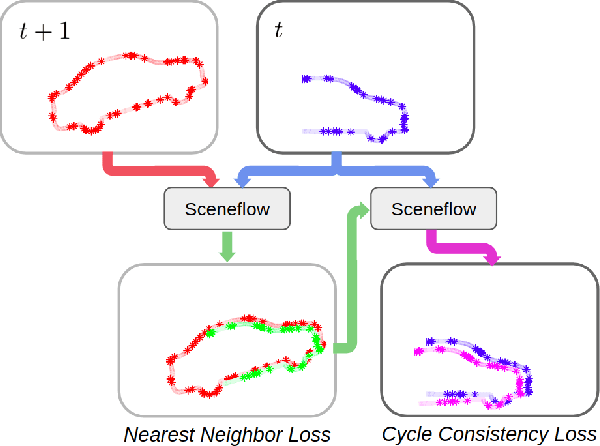

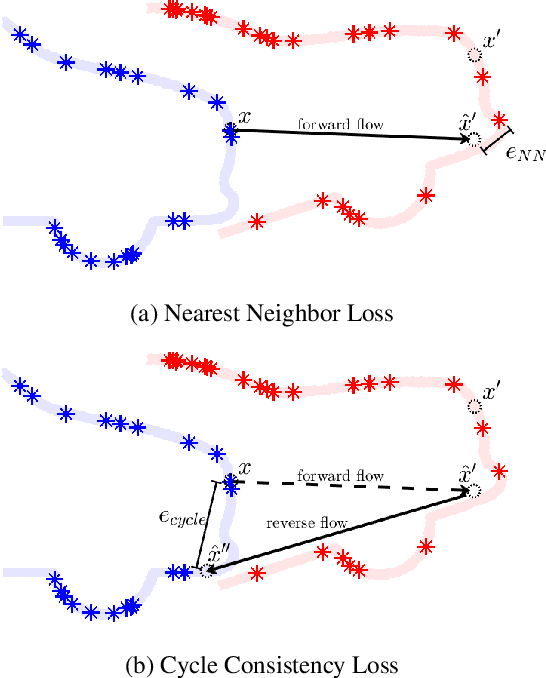
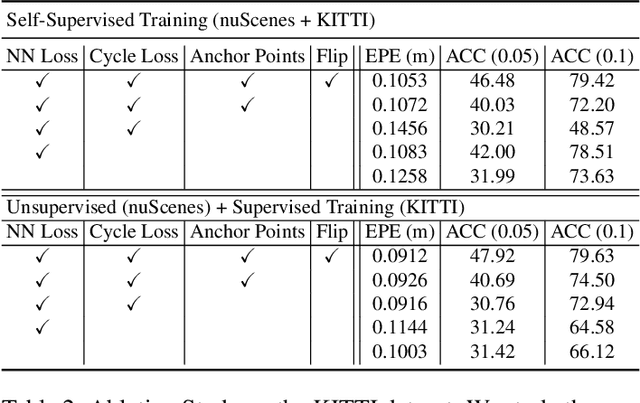
When interacting with highly dynamic environments, scene flow allows autonomous systems to reason about the non-rigid motion of multiple independent objects. This is of particular interest in the field of autonomous driving, in which many cars, people, bicycles, and other objects need to be accurately tracked. Current state of the art methods require annotated scene flow data from autonomous driving scenes to train scene flow networks with supervised learning. As an alternative, we present a method of training scene flow that uses two self-supervised losses, based on nearest neighbors and cycle consistency. These self-supervised losses allow us to train our method on large unlabeled autonomous driving datasets; the resulting method matches current state-of-the-art supervised performance using no real world annotations and exceeds state-of-the-art performance when combining our self-supervised approach with supervised learning on a smaller labeled dataset.
STWalk: Learning Trajectory Representations in Temporal Graphs
Nov 11, 2017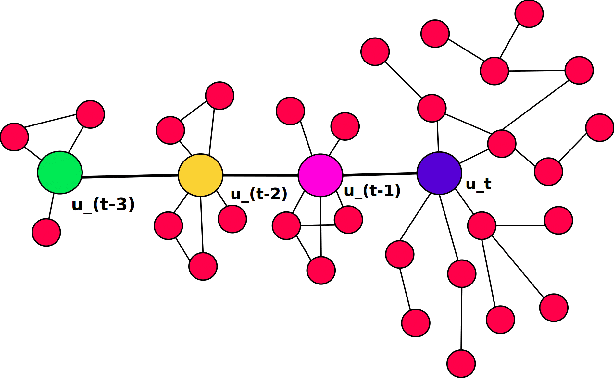
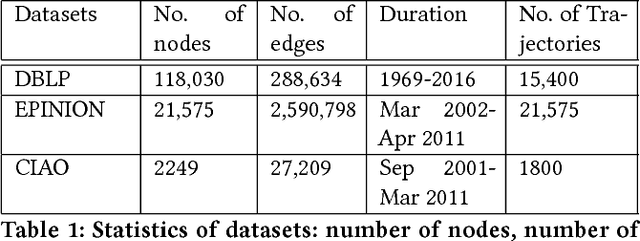
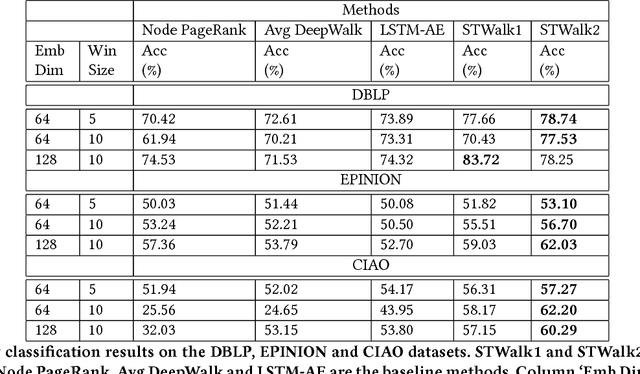
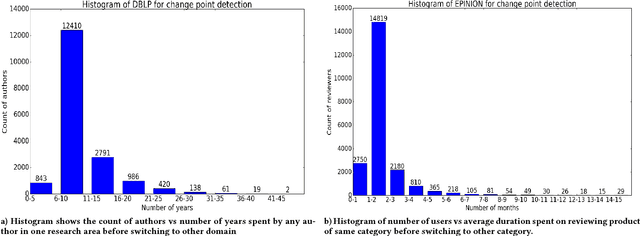
Analyzing the temporal behavior of nodes in time-varying graphs is useful for many applications such as targeted advertising, community evolution and outlier detection. In this paper, we present a novel approach, STWalk, for learning trajectory representations of nodes in temporal graphs. The proposed framework makes use of structural properties of graphs at current and previous time-steps to learn effective node trajectory representations. STWalk performs random walks on a graph at a given time step (called space-walk) as well as on graphs from past time-steps (called time-walk) to capture the spatio-temporal behavior of nodes. We propose two variants of STWalk to learn trajectory representations. In one algorithm, we perform space-walk and time-walk as part of a single step. In the other variant, we perform space-walk and time-walk separately and combine the learned representations to get the final trajectory embedding. Extensive experiments on three real-world temporal graph datasets validate the effectiveness of the learned representations when compared to three baseline methods. We also show the goodness of the learned trajectory embeddings for change point detection, as well as demonstrate that arithmetic operations on these trajectory representations yield interesting and interpretable results.