 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Storylines with Skipping Recurrent Neural Networks
Jul 26, 2016


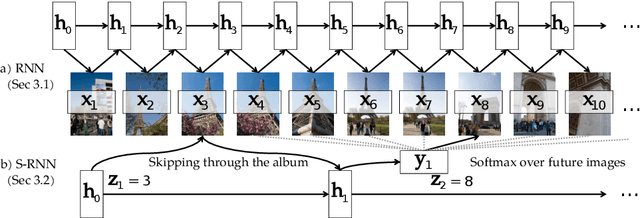
What does a typical visit to Paris look like? Do people first take photos of the Louvre and then the Eiffel Tower? Can we visually model a temporal event like "Paris Vacation" using current frameworks? In this paper, we explore how we can automatically learn the temporal aspects, or storylines of visual concepts from web data. Previous attempts focus on consecutive image-to-image transitions and are unsuccessful at recovering the long-term underlying story. Our novel Skipping Recurrent Neural Network (S-RNN) model does not attempt to predict each and every data point in the sequence, like classic RNNs. Rather, S-RNN uses a framework that skips through the images in the photo stream to explore the space of all ordered subsets of the albums via an efficient sampling procedure. This approach reduces the negative impact of strong short-term correlations, and recovers the latent story more accurately. We show how our learned storylines can be used to analyze, predict, and summarize photo albums from Flickr. Our experimental results provide strong qualitative and quantitative evidence that S-RNN is significantly better than other candidate methods such as LSTMs on learning long-term correlations and recovering latent storylines. Moreover, we show how storylines can help machines better understand and summarize photo streams by inferring a brief personalized story of each individual album.
Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding
Jul 26, 2016
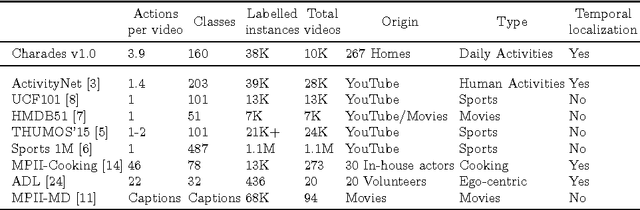

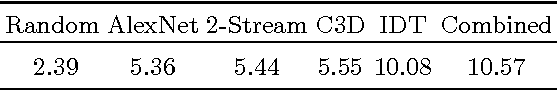
Computer vision has a great potential to help our daily lives by searching for lost keys, watering flowers or reminding us to take a pill. To succeed with such tasks, computer vision methods need to be trained from real and diverse examples of our daily dynamic scenes. While most of such scenes are not particularly exciting, they typically do not appear on YouTube, in movies or TV broadcasts. So how do we collect sufficiently many diverse but boring samples representing our lives? We propose a novel Hollywood in Homes approach to collect such data. Instead of shooting videos in the lab, we ensure diversity by distributing and crowdsourcing the whole process of video creation from script writing to video recording and annotation. Following this procedure we collect a new dataset, Charades, with hundreds of people recording videos in their own homes, acting out casual everyday activities. The dataset is composed of 9,848 annotated videos with an average length of 30 seconds, showing activities of 267 people from three continents. Each video is annotated by multiple free-text descriptions, action labels, action intervals and classes of interacted objects. In total, Charades provides 27,847 video descriptions, 66,500 temporally localized intervals for 157 action classes and 41,104 labels for 46 object classes. Using this rich data, we evaluate and provide baseline results for several tasks including action recognition and automatic description generation. We believe that the realism, diversity, and casual nature of this dataset will present unique challenges and new opportunities for computer vision community.
Actions ~ Transformations
Jul 26, 2016
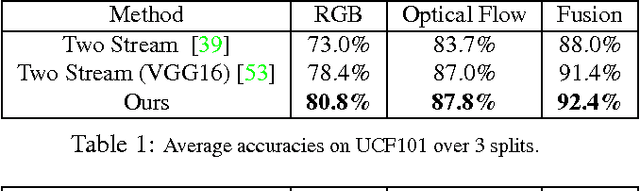

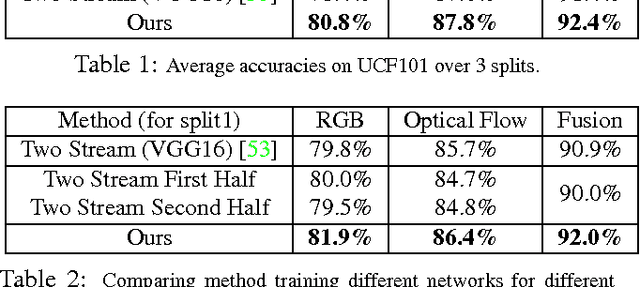
What defines an action like "kicking ball"? We argue that the true meaning of an action lies in the change or transformation an action brings to the environment. In this paper, we propose a novel representation for actions by modeling an action as a transformation which changes the state of the environment before the action happens (precondition) to the state after the action (effect). Motivated by recent advancements of video representation using deep learning, we design a Siamese network which models the action as a transformation on a high-level feature space. We show that our model gives improvements on standard action recognition datasets including UCF101 and HMDB51. More importantly, our approach is able to generalize beyond learned action categories and shows significant performance improvement on cross-category generalization on our new ACT dataset.
Generative Image Modeling using Style and Structure Adversarial Networks
Jul 26, 2016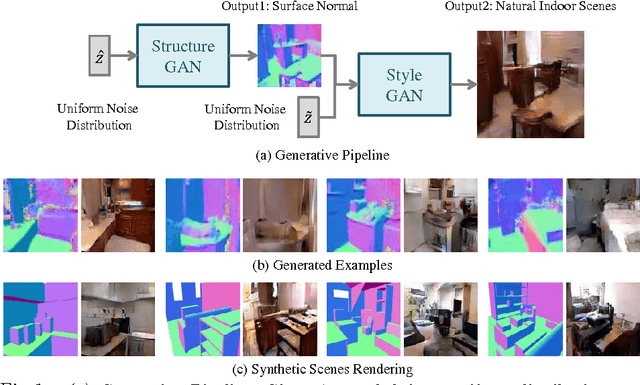
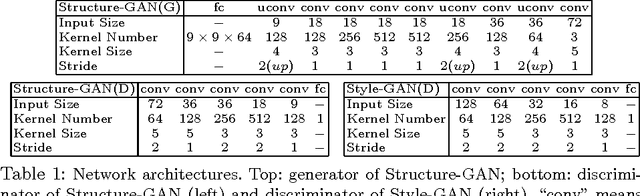


Current generative frameworks use end-to-end learning and generate images by sampling from uniform noise distribution. However, these approaches ignore the most basic principle of image formation: images are product of: (a) Structure: the underlying 3D model; (b) Style: the texture mapped onto structure. In this paper, we factorize the image generation process and propose Style and Structure Generative Adversarial Network (S^2-GAN). Our S^2-GAN has two components: the Structure-GAN generates a surface normal map; the Style-GAN takes the surface normal map as input and generates the 2D image. Apart from a real vs. generated loss function, we use an additional loss with computed surface normals from generated images. The two GANs are first trained independently, and then merged together via joint learning. We show our S^2-GAN model is interpretable, generates more realistic images and can be used to learn unsupervised RGBD representations.
The Curious Robot: Learning Visual Representations via Physical Interactions
Jul 26, 2016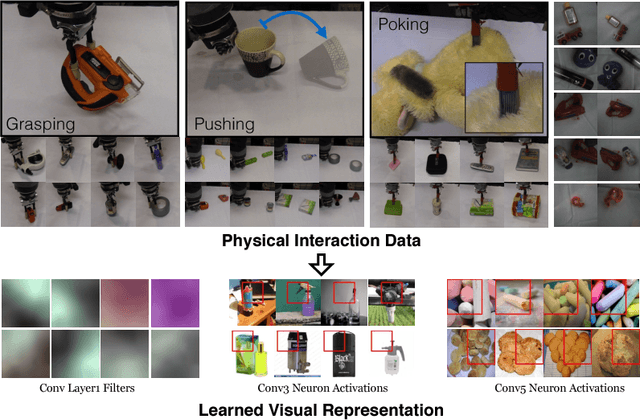



What is the right supervisory signal to train visual representations? Current approaches in computer vision use category labels from datasets such as ImageNet to train ConvNets. However, in case of biological agents, visual representation learning does not require millions of semantic labels. We argue that biological agents use physical interactions with the world to learn visual representations unlike current vision systems which just use passive observations (images and videos downloaded from web). For example, babies push objects, poke them, put them in their mouth and throw them to learn representations. Towards this goal, we build one of the first systems on a Baxter platform that pushes, pokes, grasps and observes objects in a tabletop environment. It uses four different types of physical interactions to collect more than 130K datapoints, with each datapoint providing supervision to a shared ConvNet architecture allowing us to learn visual representations. We show the quality of learned representations by observing neuron activations and performing nearest neighbor retrieval on this learned representation. Quantitatively, we evaluate our learned ConvNet on image classification tasks and show improvements compared to learning without external data. Finally, on the task of instance retrieval, our network outperforms the ImageNet network on recall@1 by 3%
An Uncertain Future: Forecasting from Static Images using Variational Autoencoders
Jun 25, 2016
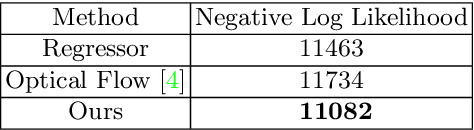
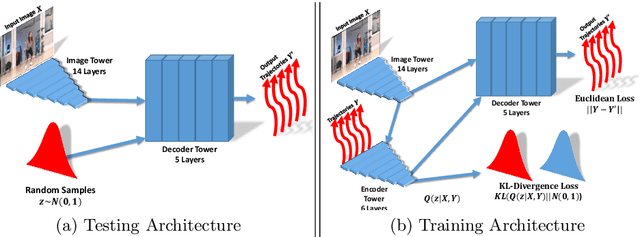

In a given scene, humans can often easily predict a set of immediate future events that might happen. However, generalized pixel-level anticipation in computer vision systems is difficult because machine learning struggles with the ambiguity inherent in predicting the future. In this paper, we focus on predicting the dense trajectory of pixels in a scene, specifically what will move in the scene, where it will travel, and how it will deform over the course of one second. We propose a conditional variational autoencoder as a solution to this problem. In this framework, direct inference from the image shapes the distribution of possible trajectories, while latent variables encode any necessary information that is not available in the image. We show that our method is able to successfully predict events in a wide variety of scenes and can produce multiple different predictions when the future is ambiguous. Our algorithm is trained on thousands of diverse, realistic videos and requires absolutely no human labeling. In addition to non-semantic action prediction, we find that our method learns a representation that is applicable to semantic vision tasks.
Training Region-based Object Detectors with Online Hard Example Mining
Apr 12, 2016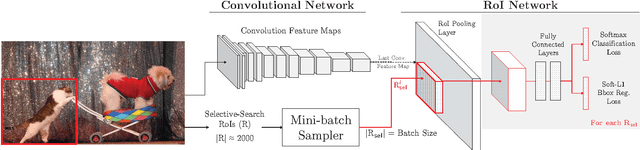
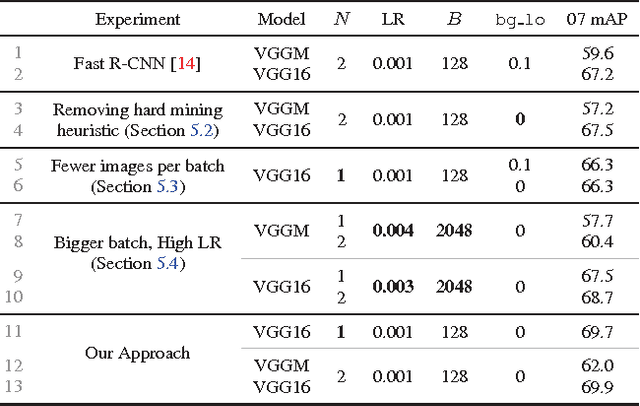
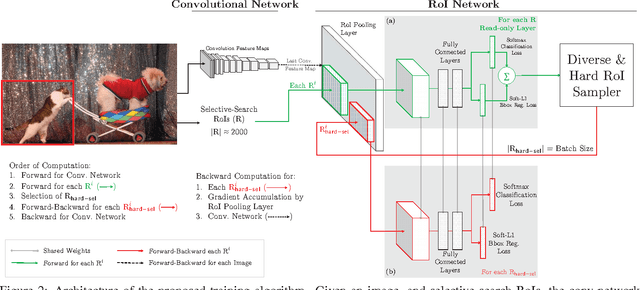

The field of object detection has made significant advances riding on the wave of region-based ConvNets, but their training procedure still includes many heuristics and hyperparameters that are costly to tune. We present a simple yet surprisingly effective online hard example mining (OHEM) algorithm for training region-based ConvNet detectors. Our motivation is the same as it has always been -- detection datasets contain an overwhelming number of easy examples and a small number of hard examples. Automatic selection of these hard examples can make training more effective and efficient. OHEM is a simple and intuitive algorithm that eliminates several heuristics and hyperparameters in common use. But more importantly, it yields consistent and significant boosts in detection performance on benchmarks like PASCAL VOC 2007 and 2012. Its effectiveness increases as datasets become larger and more difficult, as demonstrated by the results on the MS COCO dataset. Moreover, combined with complementary advances in the field, OHEM leads to state-of-the-art results of 78.9% and 76.3% mAP on PASCAL VOC 2007 and 2012 respectively.
Cross-stitch Networks for Multi-task Learning
Apr 12, 2016
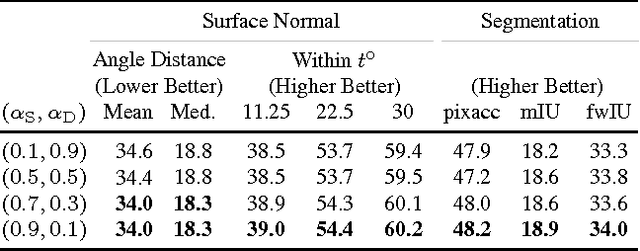
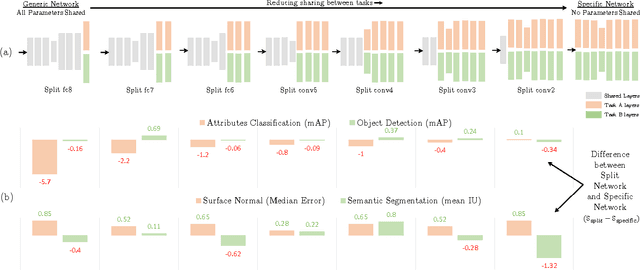
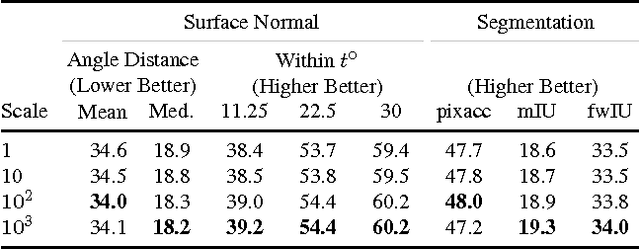
Multi-task learning in Convolutional Networks has displayed remarkable success in the field of recognition. This success can be largely attributed to learning shared representations from multiple supervisory tasks. However, existing multi-task approaches rely on enumerating multiple network architectures specific to the tasks at hand, that do not generalize. In this paper, we propose a principled approach to learn shared representations in ConvNets using multi-task learning. Specifically, we propose a new sharing unit: "cross-stitch" unit. These units combine the activations from multiple networks and can be trained end-to-end. A network with cross-stitch units can learn an optimal combination of shared and task-specific representations. Our proposed method generalizes across multiple tasks and shows dramatically improved performance over baseline methods for categories with few training examples.
Marr Revisited: 2D-3D Alignment via Surface Normal Prediction
Apr 05, 2016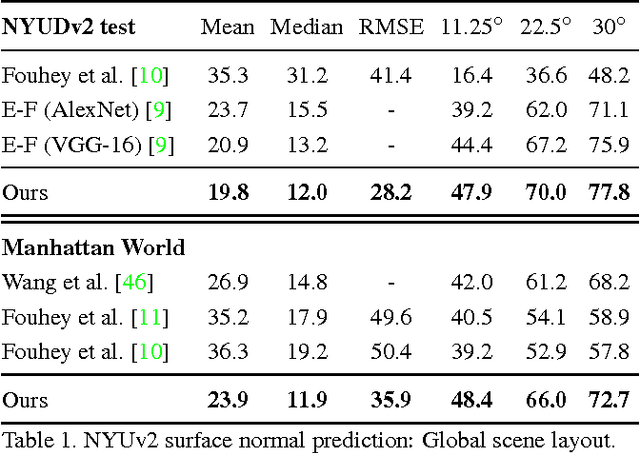
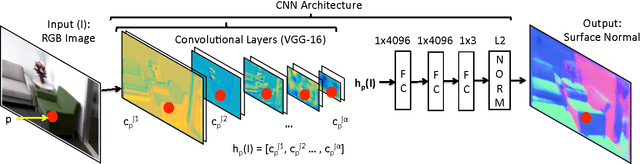
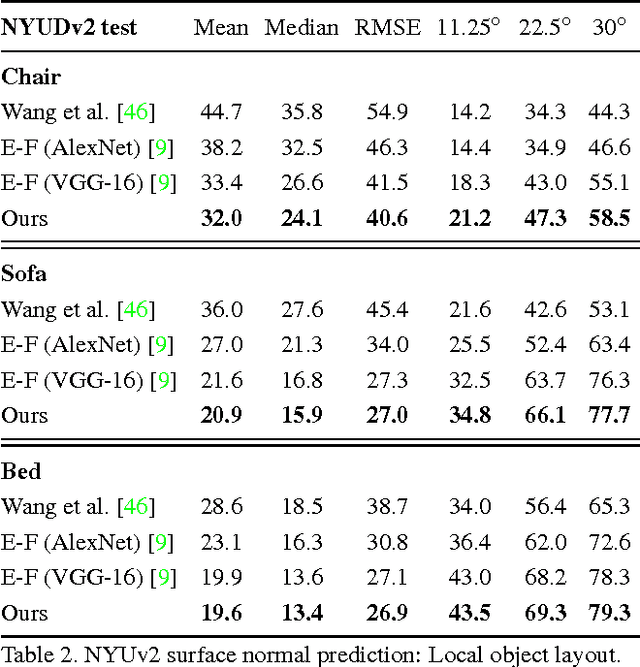
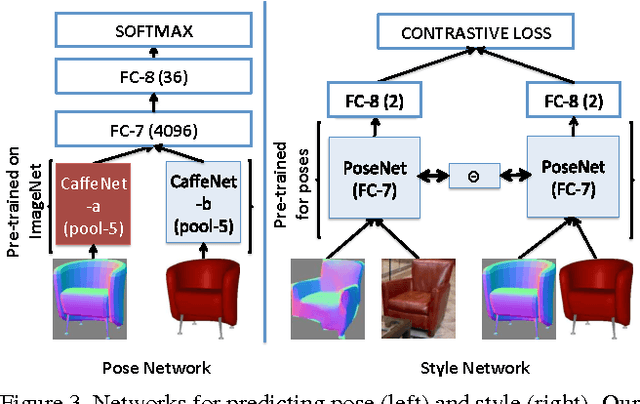
We introduce an approach that leverages surface normal predictions, along with appearance cues, to retrieve 3D models for objects depicted in 2D still images from a large CAD object library. Critical to the success of our approach is the ability to recover accurate surface normals for objects in the depicted scene. We introduce a skip-network model built on the pre-trained Oxford VGG convolutional neural network (CNN) for surface normal prediction. Our model achieves state-of-the-art accuracy on the NYUv2 RGB-D dataset for surface normal prediction, and recovers fine object detail compared to previous methods. Furthermore, we develop a two-stream network over the input image and predicted surface normals that jointly learns pose and style for CAD model retrieval. When using the predicted surface normals, our two-stream network matches prior work using surface normals computed from RGB-D images on the task of pose prediction, and achieves state of the art when using RGB-D input. Finally, our two-stream network allows us to retrieve CAD models that better match the style and pose of a depicted object compared with baseline approaches.
"What happens if" Learning to Predict the Effect of Forces in Images
Mar 17, 2016



What happens if one pushes a cup sitting on a table toward the edge of the table? How about pushing a desk against a wall? In this paper, we study the problem of understanding the movements of objects as a result of applying external forces to them. For a given force vector applied to a specific location in an image, our goal is to predict long-term sequential movements caused by that force. Doing so entails reasoning about scene geometry, objects, their attributes, and the physical rules that govern the movements of objects. We design a deep neural network model that learns long-term sequential dependencies of object movements while taking into account the geometry and appearance of the scene by combining Convolutional and Recurrent Neural Networks. Training our model requires a large-scale dataset of object movements caused by external forces. To build a dataset of forces in scenes, we reconstructed all images in SUN RGB-D dataset in a physics simulator to estimate the physical movements of objects caused by external forces applied to them. Our Forces in Scenes (ForScene) dataset contains 10,335 images in which a variety of external forces are applied to different types of objects resulting in more than 65,000 object movements represented in 3D. Our experimental evaluations show that the challenging task of predicting long-term movements of objects as their reaction to external forces is possible from a single image.