 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacO: Benchmarking Tactile Sensors for Object Manipulation
May 21, 2026Vision-based learning from demonstrations has achieved remarkable success in enabling robots to perform manipulation tasks and high-level semantic reasoning, yet it remains insufficient for complex, contact-rich manipulation. While there is broad agreement that tactile sensing improves manipulation, there is no empirical guidance on which tactile sensors are best suited for which manipulation tasks. In this paper, we provide a systematic, task-driven evaluation of tactile sensors for robot manipulation and propose a framework for selecting and evaluating sensors based on manipulation policy performance. Separate manipulation policies are trained for tactile sensors of four distinct modalities: visual, acoustic, magnetic, and resistive, across three tasks: pick-and-place with unknown mass, object reorientation, and plug insertion. For each task, an analysis of how sensor properties such as spatial resolution, shear sensing, and tactile representation, and the inherent material friction affect task performances is done. Rather than tactile sensing being universally beneficial in the same way, our results show that the usefulness of tactile information depends strongly on sensor modality, material properties, and the specific manipulation tasks. All of the tactile sensors, code, data, and hardware setup will be publicly available on the project website.
The Curious Robot: Learning Visual Representations via Physical Interactions
Jul 26, 2016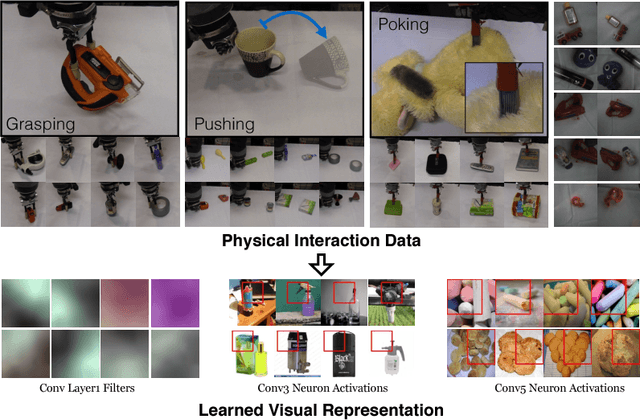



What is the right supervisory signal to train visual representations? Current approaches in computer vision use category labels from datasets such as ImageNet to train ConvNets. However, in case of biological agents, visual representation learning does not require millions of semantic labels. We argue that biological agents use physical interactions with the world to learn visual representations unlike current vision systems which just use passive observations (images and videos downloaded from web). For example, babies push objects, poke them, put them in their mouth and throw them to learn representations. Towards this goal, we build one of the first systems on a Baxter platform that pushes, pokes, grasps and observes objects in a tabletop environment. It uses four different types of physical interactions to collect more than 130K datapoints, with each datapoint providing supervision to a shared ConvNet architecture allowing us to learn visual representations. We show the quality of learned representations by observing neuron activations and performing nearest neighbor retrieval on this learned representation. Quantitatively, we evaluate our learned ConvNet on image classification tasks and show improvements compared to learning without external data. Finally, on the task of instance retrieval, our network outperforms the ImageNet network on recall@1 by 3%