 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Adversarial Reinforcement Learning
Mar 08, 2017
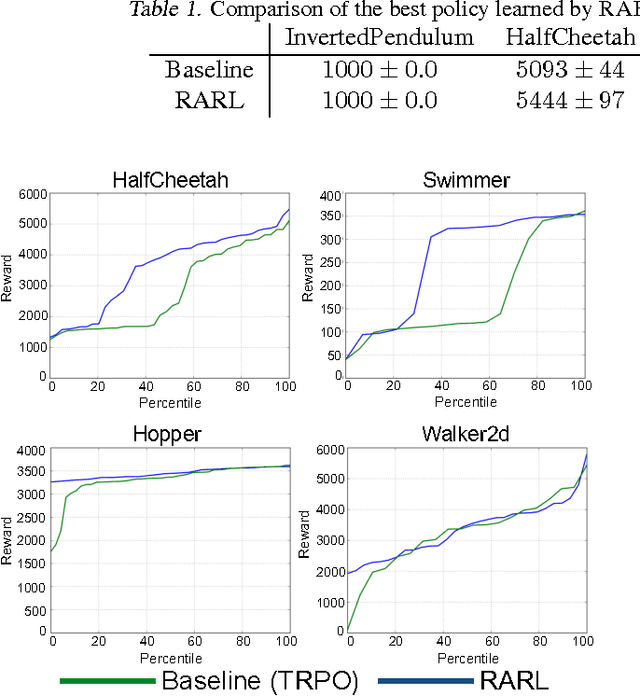
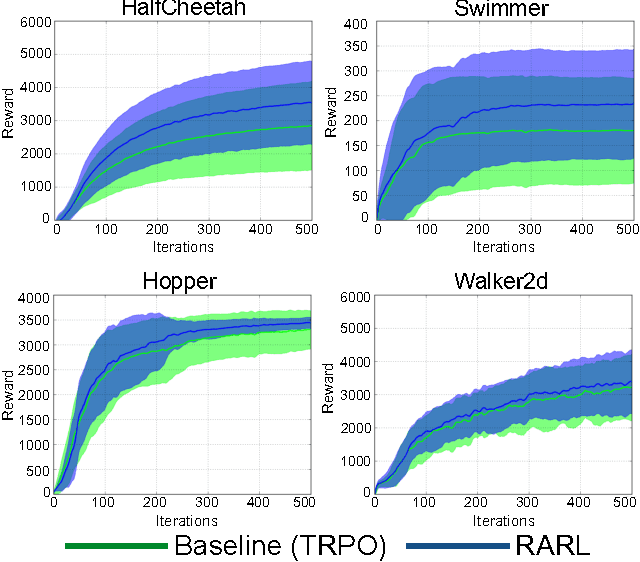
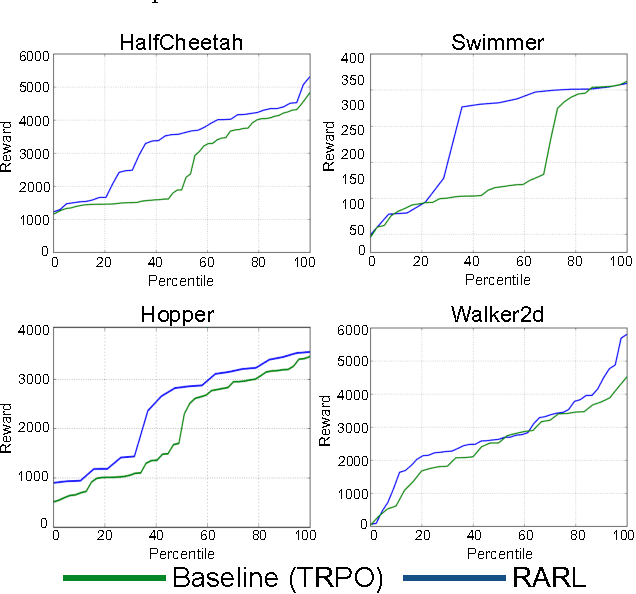
Deep neural networks coupled with fast simulation and improved computation have led to recent successes in the field of reinforcement learning (RL). However, most current RL-based approaches fail to generalize since: (a) the gap between simulation and real world is so large that policy-learning approaches fail to transfer; (b) even if policy learning is done in real world, the data scarcity leads to failed generalization from training to test scenarios (e.g., due to different friction or object masses). Inspired from H-infinity control methods, we note that both modeling errors and differences in training and test scenarios can be viewed as extra forces/disturbances in the system. This paper proposes the idea of robust adversarial reinforcement learning (RARL), where we train an agent to operate in the presence of a destabilizing adversary that applies disturbance forces to the system. The jointly trained adversary is reinforced -- that is, it learns an optimal destabilization policy. We formulate the policy learning as a zero-sum, minimax objective function. Extensive experiments in multiple environments (InvertedPendulum, HalfCheetah, Swimmer, Hopper and Walker2d) conclusively demonstrate that our method (a) improves training stability; (b) is robust to differences in training/test conditions; and c) outperform the baseline even in the absence of the adversary.
PixelNet: Representation of the pixels, by the pixels, and for the pixels
Feb 21, 2017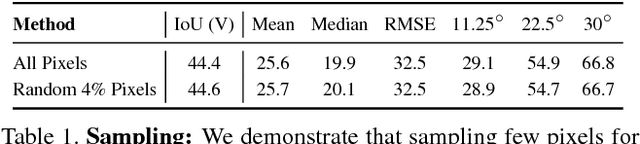
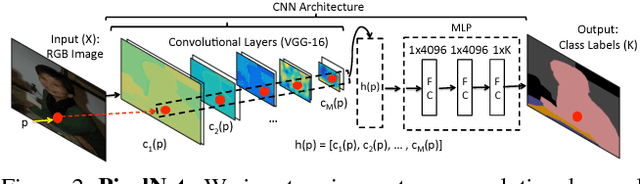
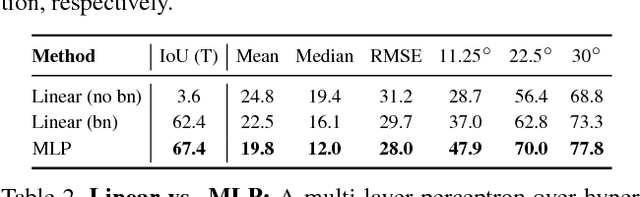
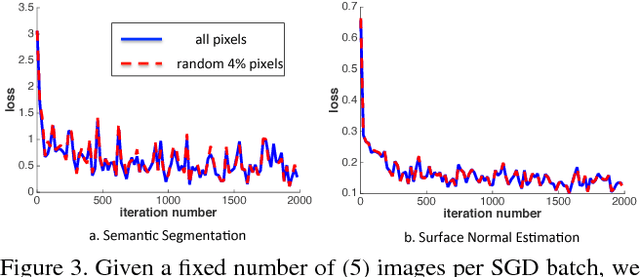
We explore design principles for general pixel-level prediction problems, from low-level edge detection to mid-level surface normal estimation to high-level semantic segmentation. Convolutional predictors, such as the fully-convolutional network (FCN), have achieved remarkable success by exploiting the spatial redundancy of neighboring pixels through convolutional processing. Though computationally efficient, we point out that such approaches are not statistically efficient during learning precisely because spatial redundancy limits the information learned from neighboring pixels. We demonstrate that stratified sampling of pixels allows one to (1) add diversity during batch updates, speeding up learning; (2) explore complex nonlinear predictors, improving accuracy; and (3) efficiently train state-of-the-art models tabula rasa (i.e., "from scratch") for diverse pixel-labeling tasks. Our single architecture produces state-of-the-art results for semantic segmentation on PASCAL-Context dataset, surface normal estimation on NYUDv2 depth dataset, and edge detection on BSDS.
An Implementation of Faster RCNN with Study for Region Sampling
Feb 08, 2017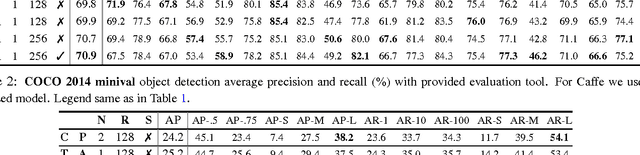
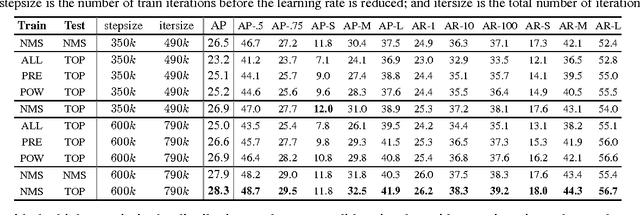
We adapted the join-training scheme of Faster RCNN framework from Caffe to TensorFlow as a baseline implementation for object detection. Our code is made publicly available. This report documents the simplifications made to the original pipeline, with justifications from ablation analysis on both PASCAL VOC 2007 and COCO 2014. We further investigated the role of non-maximal suppression (NMS) in selecting regions-of-interest (RoIs) for region classification, and found that a biased sampling toward small regions helps performance and can achieve on-par mAP to NMS-based sampling when converged sufficiently.
Supervision via Competition: Robot Adversaries for Learning Tasks
Oct 05, 2016
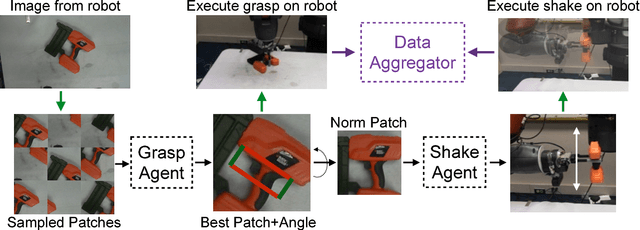


There has been a recent paradigm shift in robotics to data-driven learning for planning and control. Due to large number of experiences required for training, most of these approaches use a self-supervised paradigm: using sensors to measure success/failure. However, in most cases, these sensors provide weak supervision at best. In this work, we propose an adversarial learning framework that pits an adversary against the robot learning the task. In an effort to defeat the adversary, the original robot learns to perform the task with more robustness leading to overall improved performance. We show that this adversarial framework forces the the robot to learn a better grasping model in order to overcome the adversary. By grasping 82% of presented novel objects compared to 68% without an adversary, we demonstrate the utility of creating adversaries. We also demonstrate via experiments that having robots in adversarial setting might be a better learning strategy as compared to having collaborative multiple robots.
Much Ado About Time: Exhaustive Annotation of Temporal Data
Oct 03, 2016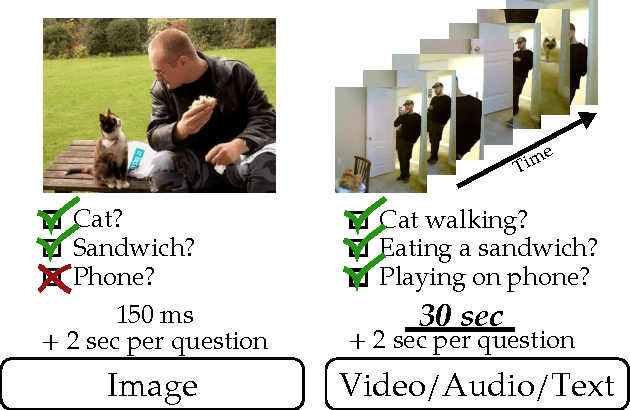


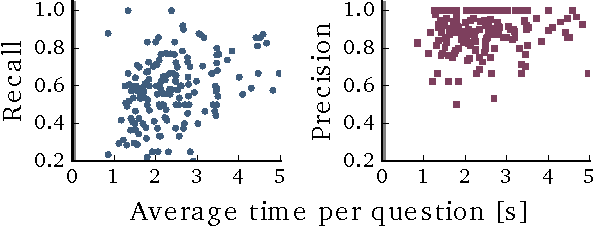
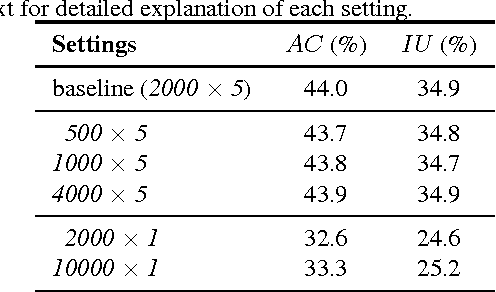
Large-scale annotated datasets allow AI systems to learn from and build upon the knowledge of the crowd. Many crowdsourcing techniques have been developed for collecting image annotations. These techniques often implicitly rely on the fact that a new input image takes a negligible amount of time to perceive. In contrast, we investigate and determine the most cost-effective way of obtaining high-quality multi-label annotations for temporal data such as videos. Watching even a short 30-second video clip requires a significant time investment from a crowd worker; thus, requesting multiple annotations following a single viewing is an important cost-saving strategy. But how many questions should we ask per video? We conclude that the optimal strategy is to ask as many questions as possible in a HIT (up to 52 binary questions after watching a 30-second video clip in our experiments). We demonstrate that while workers may not correctly answer all questions, the cost-benefit analysis nevertheless favors consensus from multiple such cheap-yet-imperfect iterations over more complex alternatives. When compared with a one-question-per-video baseline, our method is able to achieve a 10% improvement in recall 76.7% ours versus 66.7% baseline) at comparable precision (83.8% ours versus 83.0% baseline) in about half the annotation time (3.8 minutes ours compared to 7.1 minutes baseline). We demonstrate the effectiveness of our method by collecting multi-label annotations of 157 human activities on 1,815 videos.
Learning to Push by Grasping: Using multiple tasks for effective learning
Sep 28, 2016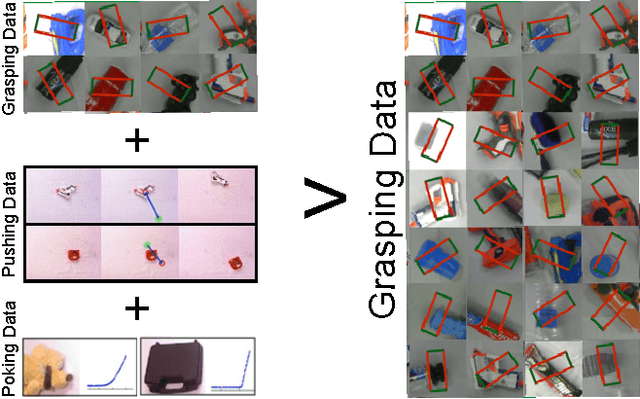


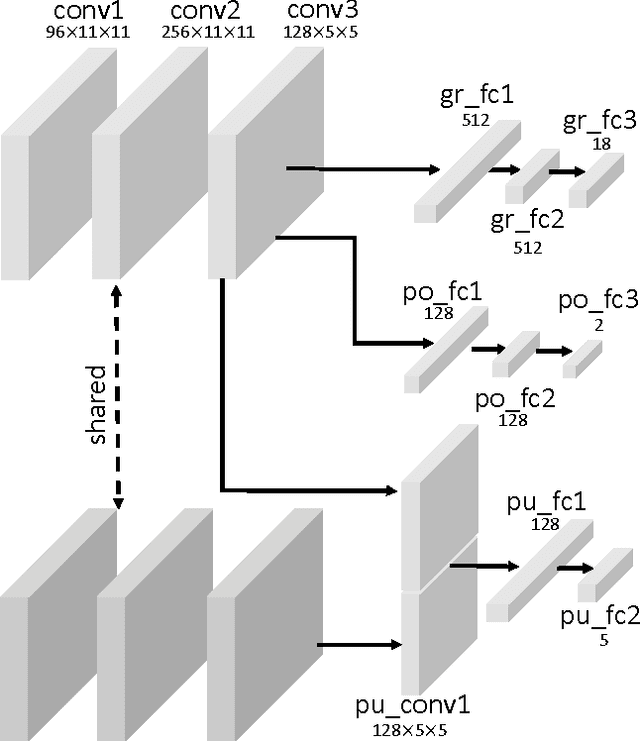
Recently, end-to-end learning frameworks are gaining prevalence in the field of robot control. These frameworks input states/images and directly predict the torques or the action parameters. However, these approaches are often critiqued due to their huge data requirements for learning a task. The argument of the difficulty in scalability to multiple tasks is well founded, since training these tasks often require hundreds or thousands of examples. But do end-to-end approaches need to learn a unique model for every task? Intuitively, it seems that sharing across tasks should help since all tasks require some common understanding of the environment. In this paper, we attempt to take the next step in data-driven end-to-end learning frameworks: move from the realm of task-specific models to joint learning of multiple robot tasks. In an astonishing result we show that models with multi-task learning tend to perform better than task-specific models trained with same amounts of data. For example, a deep-network learned with 2.5K grasp and 2.5K push examples performs better on grasping than a network trained on 5K grasp examples.
PixelNet: Towards a General Pixel-level Architecture
Sep 21, 2016
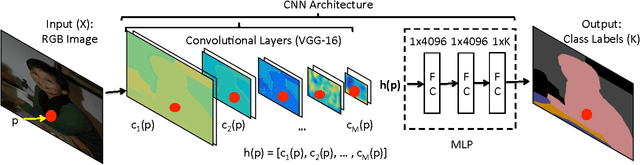

We explore architectures for general pixel-level prediction problems, from low-level edge detection to mid-level surface normal estimation to high-level semantic segmentation. Convolutional predictors, such as the fully-convolutional network (FCN), have achieved remarkable success by exploiting the spatial redundancy of neighboring pixels through convolutional processing. Though computationally efficient, we point out that such approaches are not statistically efficient during learning precisely because spatial redundancy limits the information learned from neighboring pixels. We demonstrate that (1) stratified sampling allows us to add diversity during batch updates and (2) sampled multi-scale features allow us to explore more nonlinear predictors (multiple fully-connected layers followed by ReLU) that improve overall accuracy. Finally, our objective is to show how a architecture can get performance better than (or comparable to) the architectures designed for a particular task. Interestingly, our single architecture produces state-of-the-art results for semantic segmentation on PASCAL-Context, surface normal estimation on NYUDv2 dataset, and edge detection on BSDS without contextual post-processing.
Pose from Action: Unsupervised Learning of Pose Features based on Motion
Sep 18, 2016

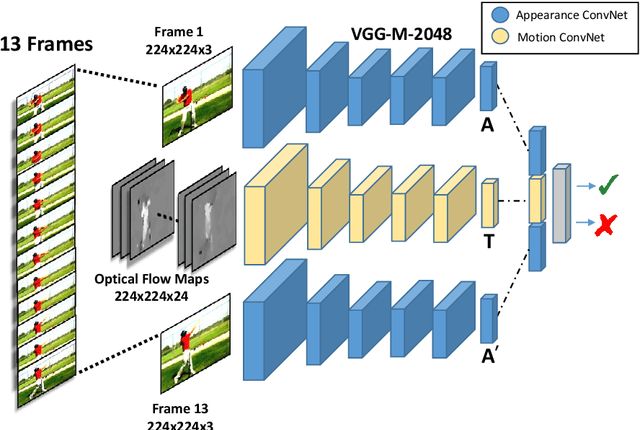
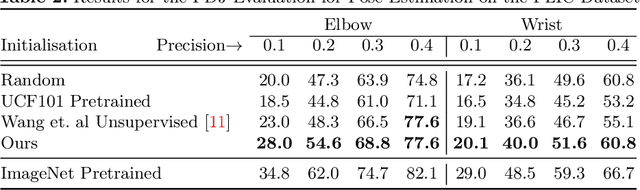
Human actions are comprised of a sequence of poses. This makes videos of humans a rich and dense source of human poses. We propose an unsupervised method to learn pose features from videos that exploits a signal which is complementary to appearance and can be used as supervision: motion. The key idea is that humans go through poses in a predictable manner while performing actions. Hence, given two poses, it should be possible to model the motion that caused the change between them. We represent each of the poses as a feature in a CNN (Appearance ConvNet) and generate a motion encoding from optical flow maps using a separate CNN (Motion ConvNet). The data for this task is automatically generated allowing us to train without human supervision. We demonstrate the strength of the learned representation by finetuning the trained model for Pose Estimation on the FLIC dataset, for static image action recognition on PASCAL and for action recognition in videos on UCF101 and HMDB51.
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning
Sep 16, 2016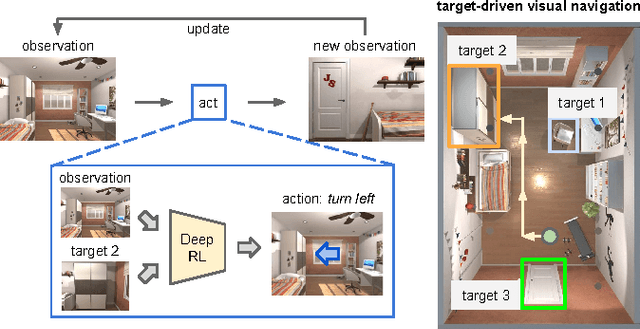

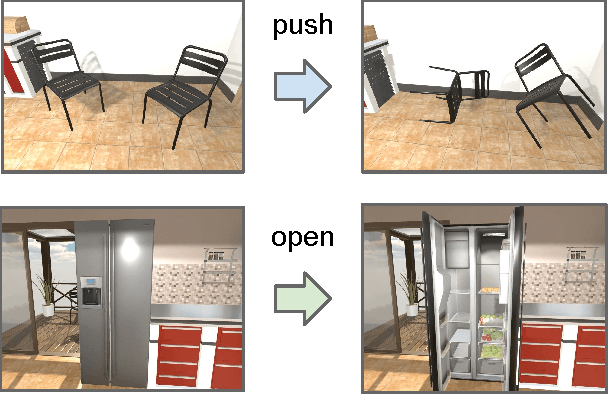
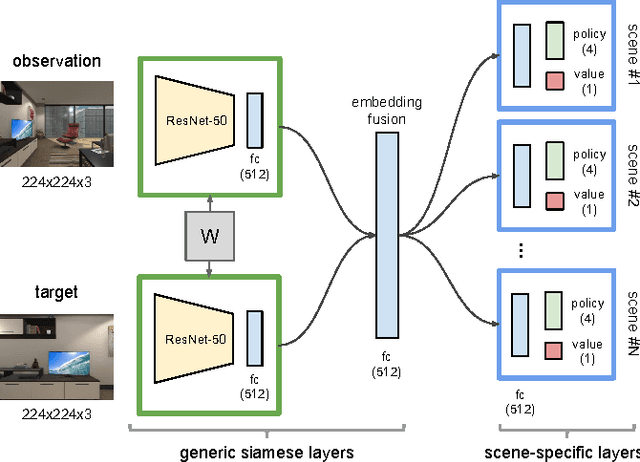
Two less addressed issues of deep reinforcement learning are (1) lack of generalization capability to new target goals, and (2) data inefficiency i.e., the model requires several (and often costly) episodes of trial and error to converge, which makes it impractical to be applied to real-world scenarios. In this paper, we address these two issues and apply our model to the task of target-driven visual navigation. To address the first issue, we propose an actor-critic model whose policy is a function of the goal as well as the current state, which allows to better generalize. To address the second issue, we propose AI2-THOR framework, which provides an environment with high-quality 3D scenes and physics engine. Our framework enables agents to take actions and interact with objects. Hence, we can collect a huge number of training samples efficiently. We show that our proposed method (1) converges faster than the state-of-the-art deep reinforcement learning methods, (2) generalizes across targets and across scenes, (3) generalizes to a real robot scenario with a small amount of fine-tuning (although the model is trained in simulation), (4) is end-to-end trainable and does not need feature engineering, feature matching between frames or 3D reconstruction of the environment. The supplementary video can be accessed at the following link: https://youtu.be/SmBxMDiOrvs.
Learning a Predictable and Generative Vector Representation for Objects
Aug 31, 2016
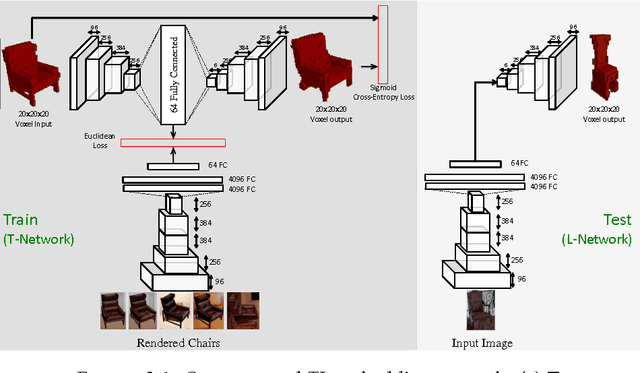


What is a good vector representation of an object? We believe that it should be generative in 3D, in the sense that it can produce new 3D objects; as well as be predictable from 2D, in the sense that it can be perceived from 2D images. We propose a novel architecture, called the TL-embedding network, to learn an embedding space with these properties. The network consists of two components: (a) an autoencoder that ensures the representation is generative; and (b) a convolutional network that ensures the representation is predictable. This enables tackling a number of tasks including voxel prediction from 2D images and 3D model retrieval. Extensive experimental analysis demonstrates the usefulness and versatility of this embedding.