 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIAM: Identity-Aware Human Motion and Shape Joint Generation
Apr 28, 2026Recent advances in text-driven human motion generation enable models to synthesize realistic motion sequences from natural language descriptions. However, most existing approaches assume identity-neutral motion and generate movements using a canonical body representation, ignoring the strong influence of body morphology on motion dynamics. In practice, attributes such as body proportions, mass distribution, and age significantly affect how actions are performed, and neglecting this coupling often leads to physically inconsistent motions. We propose an identity-aware motion generation framework that explicitly models the relationship between body morphology and motion dynamics. Instead of relying on explicit geometric measurements, identity is represented using multimodal signals, including natural language descriptions and visual cues. We further introduce a joint motion-shape generation paradigm that simultaneously synthesizes motion sequences and body shape parameters, allowing identity cues to directly modulate motion dynamics. Extensive experiments on motion capture datasets and large-scale in-the-wild videos demonstrate improved motion realism and motion-identity consistency while maintaining high motion quality. Project page: https://vjwq.github.io/IAM
UMO: Unified In-Context Learning Unlocks Motion Foundation Model Priors
Mar 16, 2026Large-scale foundation models (LFMs) have recently made impressive progress in text-to-motion generation by learning strong generative priors from massive 3D human motion datasets and paired text descriptions. However, how to effectively and efficiently leverage such single-purpose motion LFMs, i.e., text-to-motion synthesis, in more diverse cross-modal and in-context motion generation downstream tasks remains largely unclear. Prior work typically adapts pretrained generative priors to individual downstream tasks in a task-specific manner. In contrast, our goal is to unlock such priors to support a broad spectrum of downstream motion generation tasks within a single unified framework. To bridge this gap, we present UMO, a simple yet general unified formulation that casts diverse downstream tasks into compositions of atomic per-frame operations, enabling in-context adaptation to unlock the generative priors of pretrained DiT-based motion LFMs. Specifically, UMO introduces three learnable frame-level meta-operation embeddings to specify per-frame intent and employs lightweight temporal fusion to inject in-context cues into the pretrained backbone, with negligible runtime overhead compared to the base model. With this design, UMO finetunes the pretrained model, originally limited to text-to-motion generation, to support diverse previously unsupported tasks, including temporal inpainting, text-guided motion editing, text-serialized geometric constraints, and multi-identity reaction generation. Experiments demonstrate that UMO consistently outperforms task-specific and training-free baselines across a wide range of benchmarks, despite using a single unified model. Code and model will be publicly available. Project Page: https://oliver-cong02.github.io/UMO.github.io/
LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
Challenges of Zero-Shot Recognition with Vision-Language Models: Granularity and Correctness
Jun 28, 2023



This paper investigates the challenges of applying vision-language models (VLMs) to zero-shot visual recognition tasks in an open-world setting, with a focus on contrastive vision-language models such as CLIP. We first examine the performance of VLMs on concepts of different granularity levels. We propose a way to fairly evaluate the performance discrepancy under two experimental setups and find that VLMs are better at recognizing fine-grained concepts. Furthermore, we find that the similarity scores from VLMs do not strictly reflect the correctness of the textual inputs given visual input. We propose an evaluation protocol to test our hypothesis that the scores can be biased towards more informative descriptions, and the nature of the similarity score between embedding makes it challenging for VLMs to recognize the correctness between similar but wrong descriptions. Our study highlights the challenges of using VLMs in open-world settings and suggests directions for future research to improve their zero-shot capabilities.
ScaleDet: A Scalable Multi-Dataset Object Detector
Jun 08, 2023



Multi-dataset training provides a viable solution for exploiting heterogeneous large-scale datasets without extra annotation cost. In this work, we propose a scalable multi-dataset detector (ScaleDet) that can scale up its generalization across datasets when increasing the number of training datasets. Unlike existing multi-dataset learners that mostly rely on manual relabelling efforts or sophisticated optimizations to unify labels across datasets, we introduce a simple yet scalable formulation to derive a unified semantic label space for multi-dataset training. ScaleDet is trained by visual-textual alignment to learn the label assignment with label semantic similarities across datasets. Once trained, ScaleDet can generalize well on any given upstream and downstream datasets with seen and unseen classes. We conduct extensive experiments using LVIS, COCO, Objects365, OpenImages as upstream datasets, and 13 datasets from Object Detection in the Wild (ODinW) as downstream datasets. Our results show that ScaleDet achieves compelling strong model performance with an mAP of 50.7 on LVIS, 58.8 on COCO, 46.8 on Objects365, 76.2 on OpenImages, and 71.8 on ODinW, surpassing state-of-the-art detectors with the same backbone.
Energy-Based Learning for Scene Graph Generation
Mar 03, 2021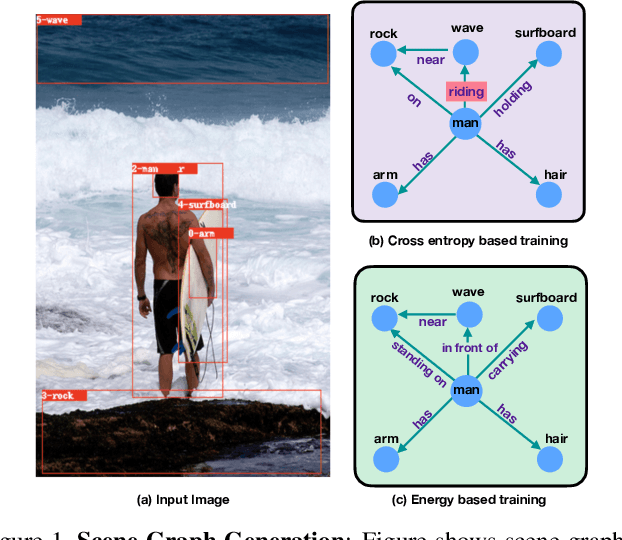
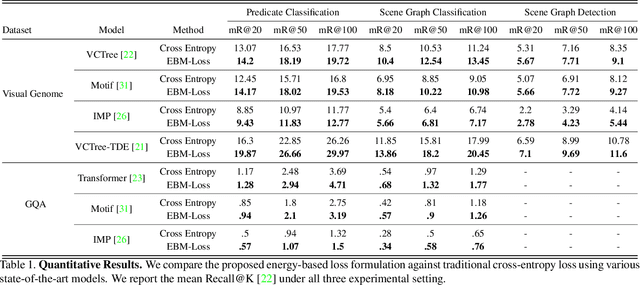
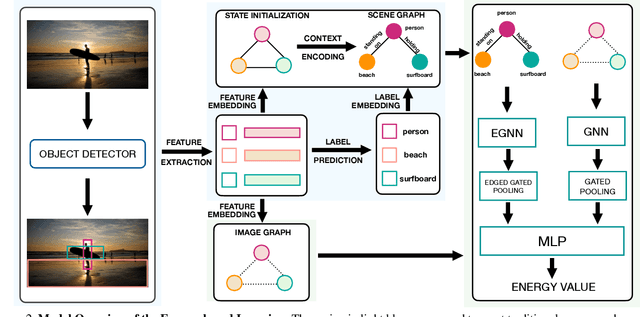
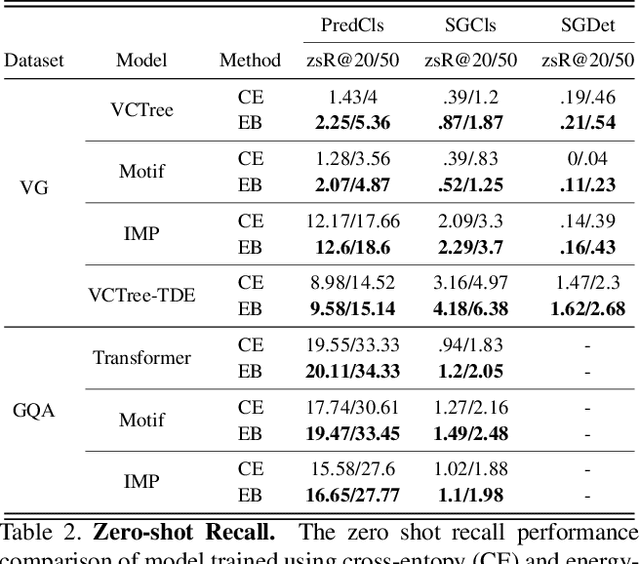
Traditional scene graph generation methods are trained using cross-entropy losses that treat objects and relationships as independent entities. Such a formulation, however, ignores the structure in the output space, in an inherently structured prediction problem. In this work, we introduce a novel energy-based learning framework for generating scene graphs. The proposed formulation allows for efficiently incorporating the structure of scene graphs in the output space. This additional constraint in the learning framework acts as an inductive bias and allows models to learn efficiently from a small number of labels. We use the proposed energy-based framework to train existing state-of-the-art models and obtain a significant performance improvement, of up to 21% and 27%, on the Visual Genome and GQA benchmark datasets, respectively. Furthermore, we showcase the learning efficiency of the proposed framework by demonstrating superior performance in the zero- and few-shot settings where data is scarce.