 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Probabilistic Permutation Invariant Training for Speech Separation
Aug 04, 2019
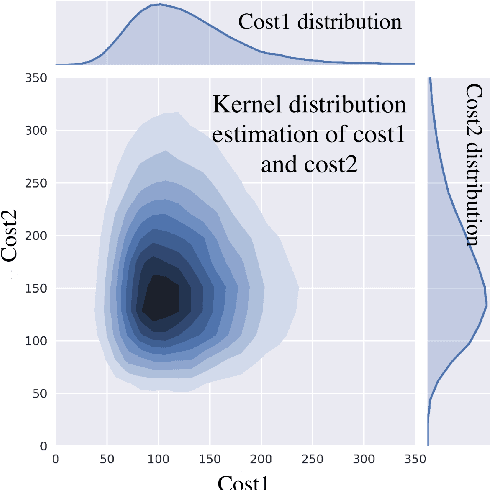
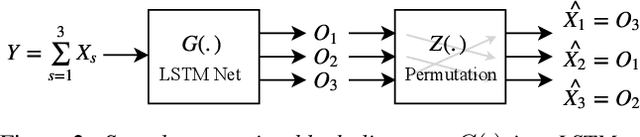
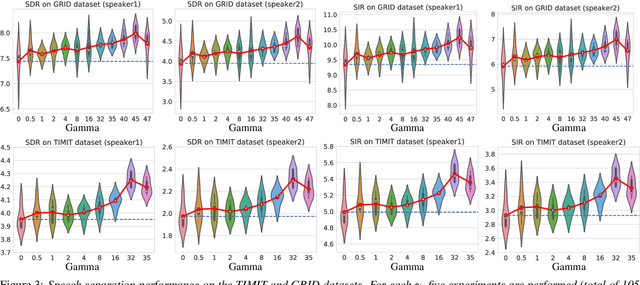
Single-microphone, speaker-independent speech separation is normally performed through two steps: (i) separating the specific speech sources, and (ii) determining the best output-label assignment to find the separation error. The second step is the main obstacle in training neural networks for speech separation. Recently proposed Permutation Invariant Training (PIT) addresses this problem by determining the output-label assignment which minimizes the separation error. In this study, we show that a major drawback of this technique is the overconfident choice of the output-label assignment, especially in the initial steps of training when the network generates unreliable outputs. To solve this problem, we propose Probabilistic PIT (Prob-PIT) which considers the output-label permutation as a discrete latent random variable with a uniform prior distribution. Prob-PIT defines a log-likelihood function based on the prior distributions and the separation errors of all permutations; it trains the speech separation networks by maximizing the log-likelihood function. Prob-PIT can be easily implemented by replacing the minimum function of PIT with a soft-minimum function. We evaluate our approach for speech separation on both TIMIT and CHiME datasets. The results show that the proposed method significantly outperforms PIT in terms of Signal to Distortion Ratio and Signal to Interference Ratio.
Detecting Hate Speech in Memes Using Multimodal Deep Learning Approaches: Prize-winning solution to Hateful Memes Challenge
Dec 23, 2020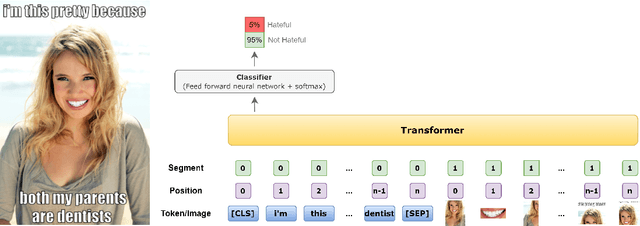
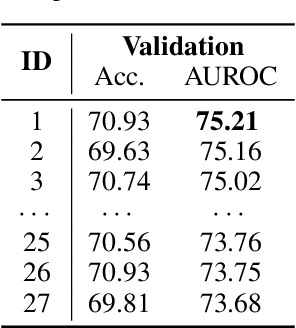

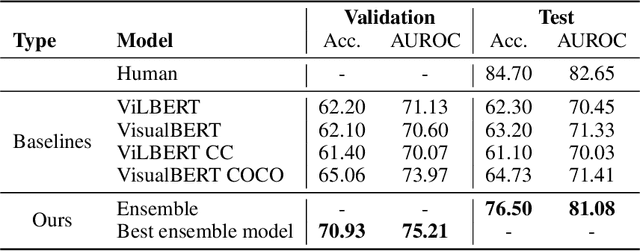
Memes on the Internet are often harmless and sometimes amusing. However, by using certain types of images, text, or combinations of both, the seemingly harmless meme becomes a multimodal type of hate speech -- a hateful meme. The Hateful Memes Challenge is a first-of-its-kind competition which focuses on detecting hate speech in multimodal memes and it proposes a new data set containing 10,000+ new examples of multimodal content. We utilize VisualBERT -- which meant to be the BERT of vision and language -- that was trained multimodally on images and captions and apply Ensemble Learning. Our approach achieves 0.811 AUROC with an accuracy of 0.765 on the challenge test set and placed third out of 3,173 participants in the Hateful Memes Challenge.
Challenging the Boundaries of Speech Recognition: The MALACH Corpus
Aug 09, 2019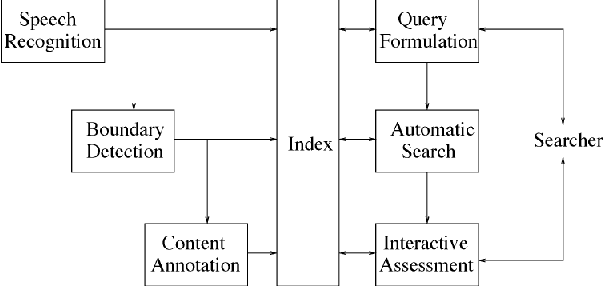
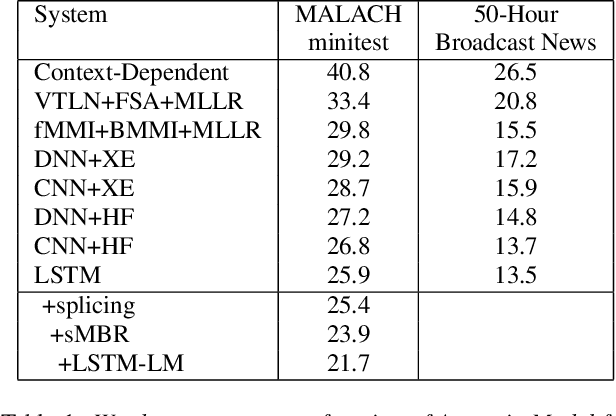
There has been huge progress in speech recognition over the last several years. Tasks once thought extremely difficult, such as SWITCHBOARD, now approach levels of human performance. The MALACH corpus (LDC catalog LDC2012S05), a 375-Hour subset of a large archive of Holocaust testimonies collected by the Survivors of the Shoah Visual History Foundation, presents significant challenges to the speech community. The collection consists of unconstrained, natural speech filled with disfluencies, heavy accents, age-related coarticulations, un-cued speaker and language switching, and emotional speech - all still open problems for speech recognition systems. Transcription is challenging even for skilled human annotators. This paper proposes that the community place focus on the MALACH corpus to develop speech recognition systems that are more robust with respect to accents, disfluencies and emotional speech. To reduce the barrier for entry, a lexicon and training and testing setups have been created and baseline results using current deep learning technologies are presented. The metadata has just been released by LDC (LDC2019S11). It is hoped that this resource will enable the community to build on top of these baselines so that the extremely important information in these and related oral histories becomes accessible to a wider audience.
UniSpeech at scale: An Empirical Study of Pre-training Method on Large-Scale Speech Recognition Dataset
Jul 12, 2021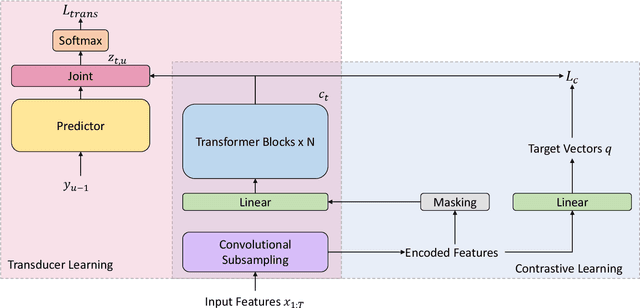
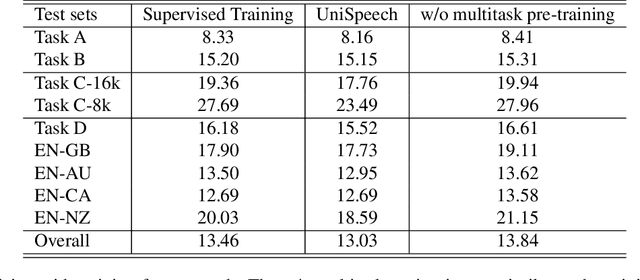
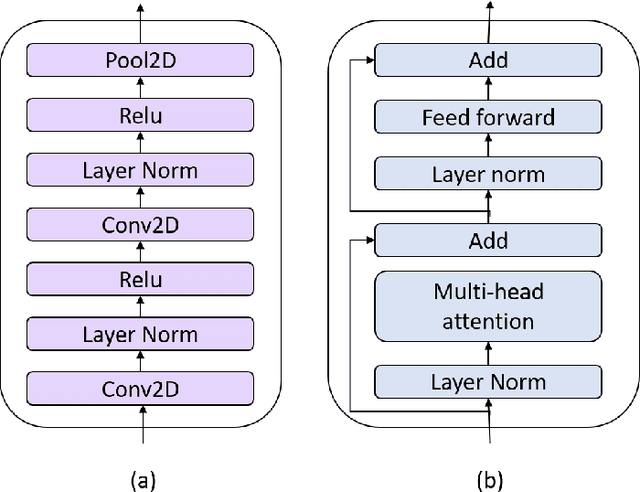
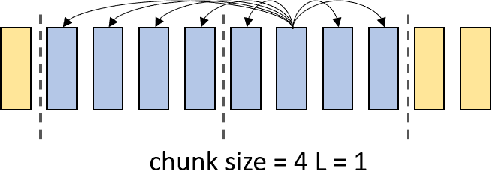
Recently, there has been a vast interest in self-supervised learning (SSL) where the model is pre-trained on large scale unlabeled data and then fine-tuned on a small labeled dataset. The common wisdom is that SSL helps resource-limited tasks in which only a limited amount of labeled data is available. The benefit of SSL keeps diminishing when the labeled training data amount increases. To our best knowledge, at most a few thousand hours of labeled data was used in the study of SSL. In contrast, the industry usually uses tens of thousands of hours of labeled data to build high-accuracy speech recognition (ASR) systems for resource-rich languages. In this study, we take the challenge to investigate whether and how SSL can improve the ASR accuracy of a state-of-the-art production-scale Transformer-Transducer model, which was built with 65 thousand hours of anonymized labeled EN-US data.
Investigating Lexical Replacements for Arabic-English Code-Switched Data Augmentation
May 25, 2022
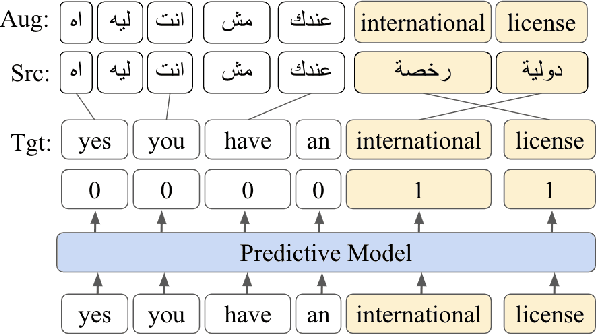

Code-switching (CS) poses several challenges to NLP tasks, where data sparsity is a main problem hindering the development of CS NLP systems. In this paper, we investigate data augmentation techniques for synthesizing Dialectal Arabic-English CS text. We perform lexical replacements using parallel corpora and alignments where CS points are either randomly chosen or learnt using a sequence-to-sequence model. We evaluate the effectiveness of data augmentation on language modeling (LM), machine translation (MT), and automatic speech recognition (ASR) tasks. Results show that in the case of using 1-1 alignments, using trained predictive models produces more natural CS sentences, as reflected in perplexity. By relying on grow-diag-final alignments, we then identify aligning segments and perform replacements accordingly. By replacing segments instead of words, the quality of synthesized data is greatly improved. With this improvement, random-based approach outperforms using trained predictive models on all extrinsic tasks. Our best models achieve 33.6% improvement in perplexity, +3.2-5.6 BLEU points on MT task, and 7% relative improvement on WER for ASR task. We also contribute in filling the gap in resources by collecting and publishing the first Arabic English CS-English parallel corpus.
Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition
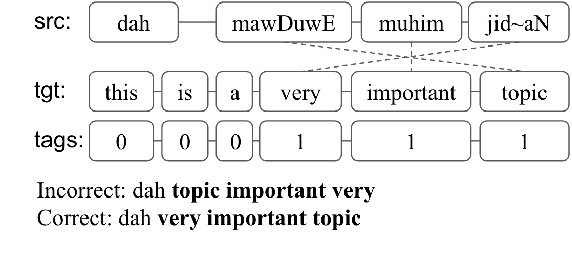
Apr 19, 2021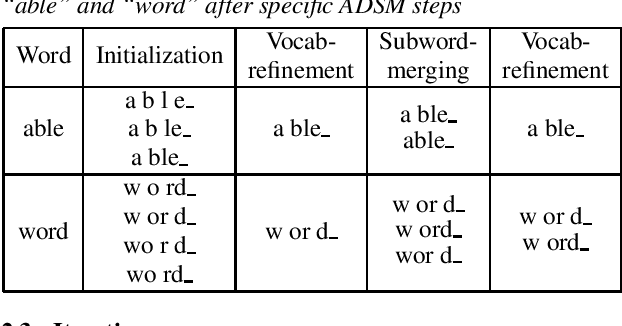
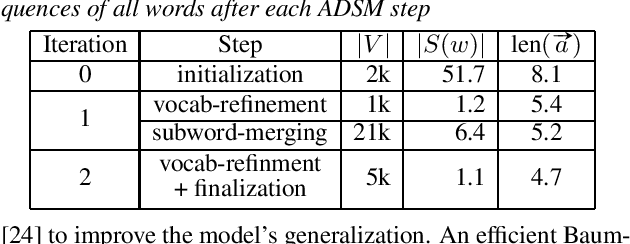
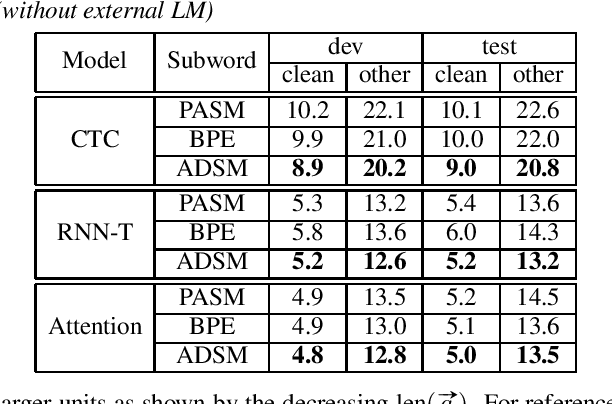

Subword units are commonly used for end-to-end automatic speech recognition (ASR), while a fully acoustic-oriented subword modeling approach is somewhat missing. We propose an acoustic data-driven subword modeling (ADSM) approach that adapts the advantages of several text-based and acoustic-based subword methods into one pipeline. With a fully acoustic-oriented label design and learning process, ADSM produces acoustic-structured subword units and acoustic-matched target sequence for further ASR training. The obtained ADSM labels are evaluated with different end-to-end ASR approaches including CTC, RNN-transducer and attention models. Experiments on the LibriSpeech corpus show that ADSM clearly outperforms both byte pair encoding (BPE) and pronunciation-assisted subword modeling (PASM) in all cases. Detailed analysis shows that ADSM achieves acoustically more logical word segmentation and more balanced sequence length, and thus, is suitable for both time-synchronous and label-synchronous models. We also briefly describe how to apply acoustic-based subword regularization and unseen text segmentation using ADSM.
A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning
Jun 03, 2020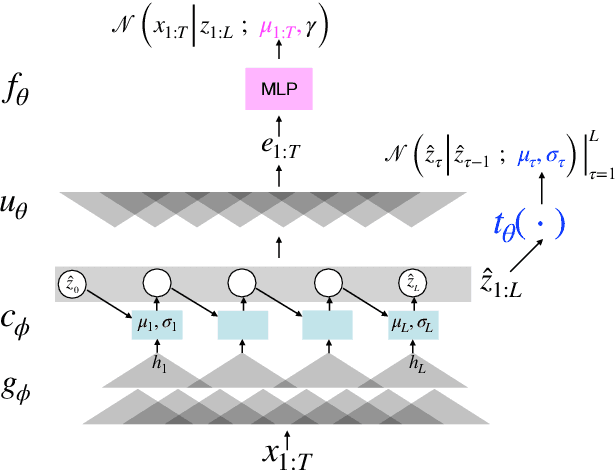
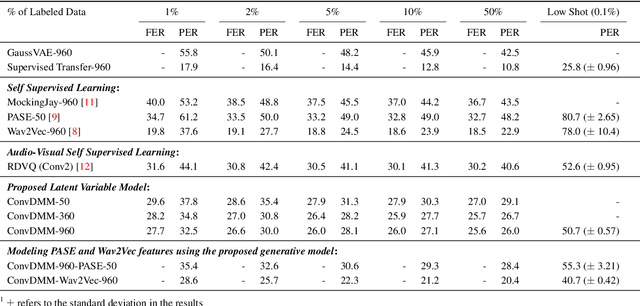
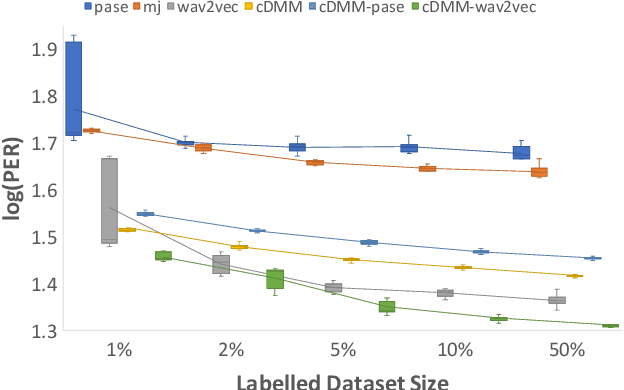
Probabilistic Latent Variable Models (LVMs) provide an alternative to self-supervised learning approaches for linguistic representation learning from speech. LVMs admit an intuitive probabilistic interpretation where the latent structure shapes the information extracted from the signal. Even though LVMs have recently seen a renewed interest due to the introduction of Variational Autoencoders (VAEs), their use for speech representation learning remains largely unexplored. In this work, we propose Convolutional Deep Markov Model (ConvDMM), a Gaussian state-space model with non-linear emission and transition functions modelled by deep neural networks. This unsupervised model is trained using black box variational inference. A deep convolutional neural network is used as an inference network for structured variational approximation. When trained on a large scale speech dataset (LibriSpeech), ConvDMM produces features that significantly outperform multiple self-supervised feature extracting methods on linear phone classification and recognition on the Wall Street Journal dataset. Furthermore, we found that ConvDMM complements self-supervised methods like Wav2Vec and PASE, improving on the results achieved with any of the methods alone. Lastly, we find that ConvDMM features enable learning better phone recognizers than any other features in an extreme low-resource regime with few labeled training examples.
Long-span language modeling for speech recognition
Nov 11, 2019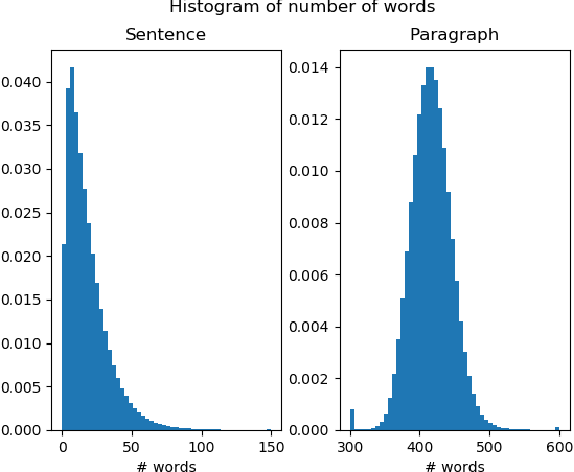
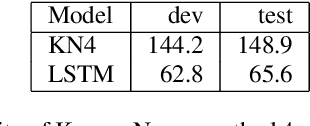
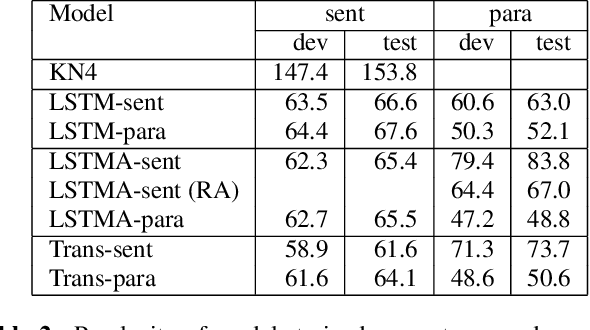
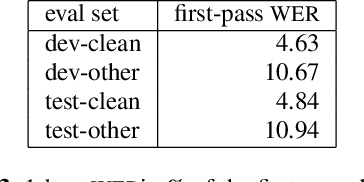
We explore neural language modeling for speech recognition where the context spans multiple sentences. Rather than encode history beyond the current sentence using a cache of words or document-level features, we focus our study on the ability of LSTM and Transformer language models to implicitly learn to carry over context across sentence boundaries. We introduce a new architecture that incorporates an attention mechanism into LSTM to combine the benefits of recurrent and attention architectures. We conduct language modeling and speech recognition experiments on the publicly available LibriSpeech corpus. We show that conventional training on a paragraph-level corpus results in significant reductions in perplexity compared to training on a sentence-level corpus. We also describe speech recognition experiments using long-span language models in second-pass re-ranking, and provide insights into the ability of such models to take advantage of context beyond the current sentence.
Improving CTC-based ASR Models with Gated Interlayer Collaboration
May 25, 2022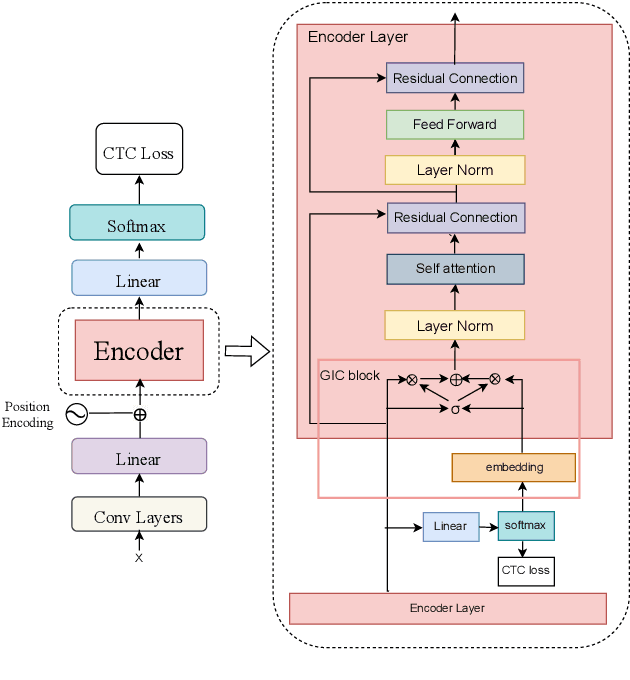
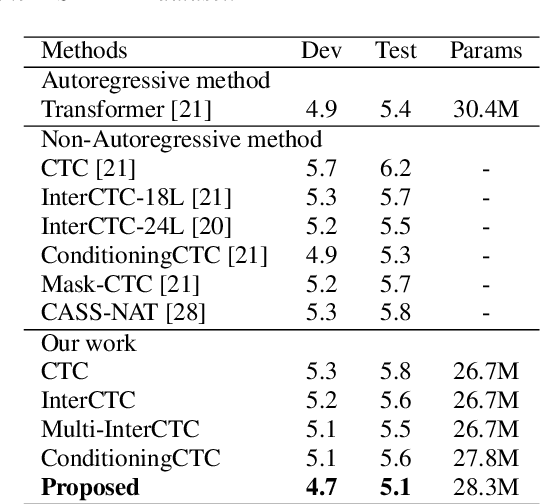
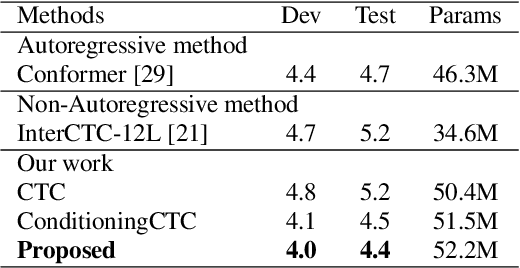
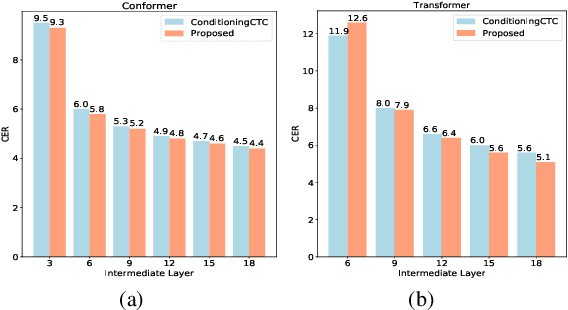
For Automatic Speech Recognition (ASR), the CTC-based methods have become a dominant paradigm due to its simple architecture and efficient non-autoregressive inference manner. However, these methods without external language models usually lack the capacity of modeling the conditional dependencies and the textual interaction. In this work, we present a Gated Interlayer Collaboration (GIC) mechanism which introduces the contextual information into the models and relaxes the conditional independence assumption of the CTC-based models. Specifically, we train the model with intermediate CTC losses calculated by the interlayer outputs of the model, in which the probability distributions of the intermediate layers naturally serve as soft label sequences. The GIC block consists of an embedding layer to obtain the textual embedding of the soft label at each position, and a gate unit to fuse the textual embedding and the acoustic features. Experiments on AISHELL-1 and AIDATATANG benchmarks show that the proposed method outperforms the recently published CTC-based ASR models. Specifically, our method achieves CER of 4.0%/4.4% on AISHELL-1 dev/test sets and CER of 3.8%/4.4% on AIDATATANG dev/test sets using CTC greedy search decoding without external language models.
TuGeBiC: A Turkish German Bilingual Code-Switching Corpus
May 02, 2022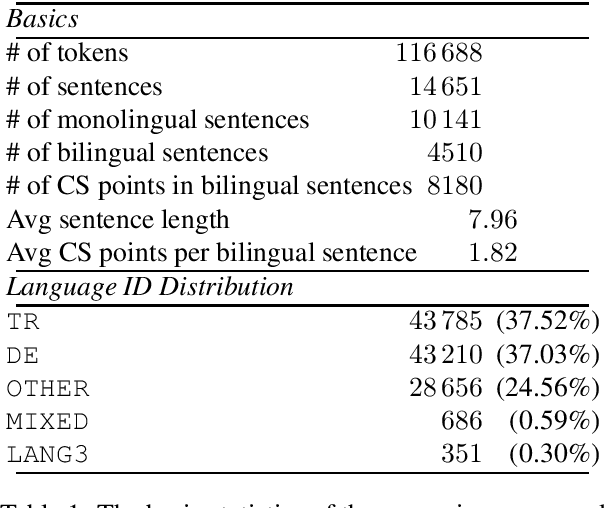
In this paper we describe the process of collection, transcription, and annotation of recordings of spontaneous speech samples from Turkish-German bilinguals, and the compilation of a corpus called TuGeBiC. Participants in the study were adult Turkish-German bilinguals living in Germany or Turkey at the time of recording in the first half of the 1990s. The data were manually tokenised and normalised, and all proper names (names of participants and places mentioned in the conversations) were replaced with pseudonyms. Token-level automatic language identification was performed, which made it possible to establish the proportions of words from each language. The corpus is roughly balanced between both languages. We also present quantitative information about the number of code-switches, and give examples of different types of code-switching found in the data. The resulting corpus has been made freely available to the research community.