 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Language Model Integration for RNN Transducer based Speech Recognition
Oct 13, 2021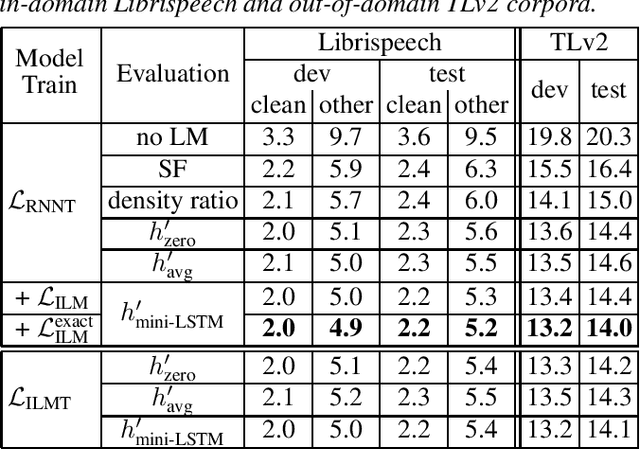
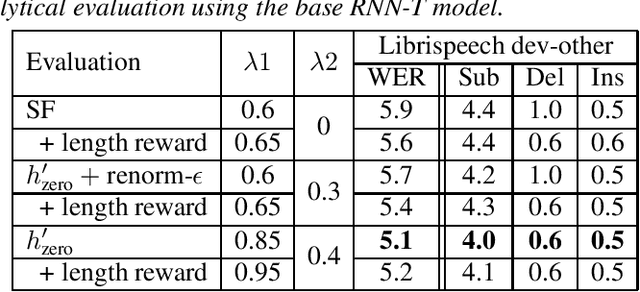
The mismatch between an external language model (LM) and the implicitly learned internal LM (ILM) of RNN-Transducer (RNN-T) can limit the performance of LM integration such as simple shallow fusion. A Bayesian interpretation suggests to remove this sequence prior as ILM correction. In this work, we study various ILM correction-based LM integration methods formulated in a common RNN-T framework. We provide a decoding interpretation on two major reasons for performance improvement with ILM correction, which is further experimentally verified with detailed analysis. We also propose an exact-ILM training framework by extending the proof given in the hybrid autoregressive transducer, which enables a theoretical justification for other ILM approaches. Systematic comparison is conducted for both in-domain and cross-domain evaluation on the Librispeech and TED-LIUM Release 2 corpora, respectively. Our proposed exact-ILM training can further improve the best ILM method.
Acoustic Data-Driven Subword Modeling for End-to-End Speech Recognition
Apr 19, 2021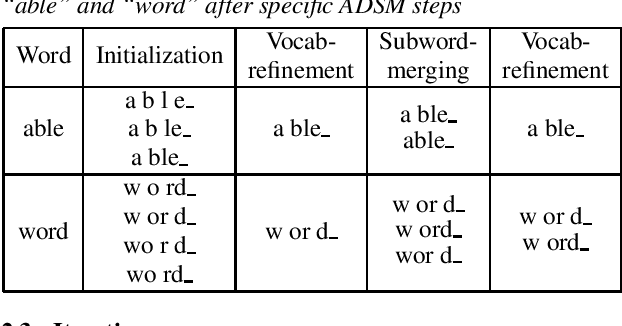
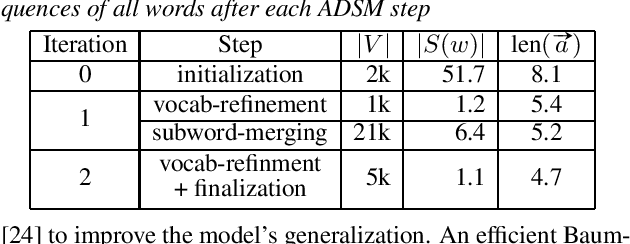
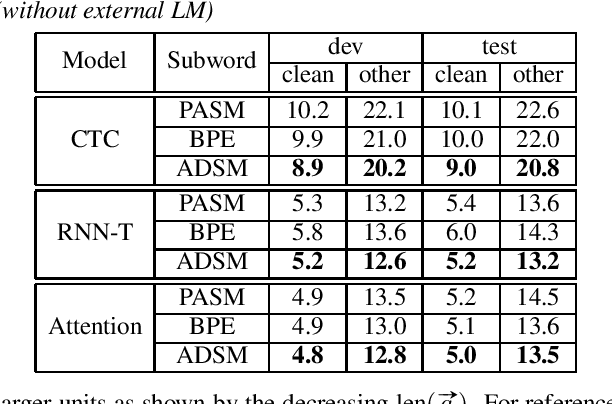

Subword units are commonly used for end-to-end automatic speech recognition (ASR), while a fully acoustic-oriented subword modeling approach is somewhat missing. We propose an acoustic data-driven subword modeling (ADSM) approach that adapts the advantages of several text-based and acoustic-based subword methods into one pipeline. With a fully acoustic-oriented label design and learning process, ADSM produces acoustic-structured subword units and acoustic-matched target sequence for further ASR training. The obtained ADSM labels are evaluated with different end-to-end ASR approaches including CTC, RNN-transducer and attention models. Experiments on the LibriSpeech corpus show that ADSM clearly outperforms both byte pair encoding (BPE) and pronunciation-assisted subword modeling (PASM) in all cases. Detailed analysis shows that ADSM achieves acoustically more logical word segmentation and more balanced sequence length, and thus, is suitable for both time-synchronous and label-synchronous models. We also briefly describe how to apply acoustic-based subword regularization and unseen text segmentation using ADSM.