 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A New 27 Class Sign Language Dataset Collected from 173 Individuals
Mar 08, 2022

After the interviews, it has been comprehended that speech-impaired individuals who use sign languages have difficulty communicating with other people who do not know sign language. Due to the communication problems, the sense of independence of speech-impaired individuals could be damaged and lead them to socialize less with society. To contribute to the development of technologies, that can reduce the communication problems of speech-impaired persons, a new dataset was presented with this paper. The dataset was created by processing American Sign Language-based photographs collected from 173 volunteers, published as 27 Class Sign Language Dataset on the Kaggle Datasets web page.
Raw Waveform Encoder with Multi-Scale Globally Attentive Locally Recurrent Networks for End-to-End Speech Recognition
Jun 08, 2021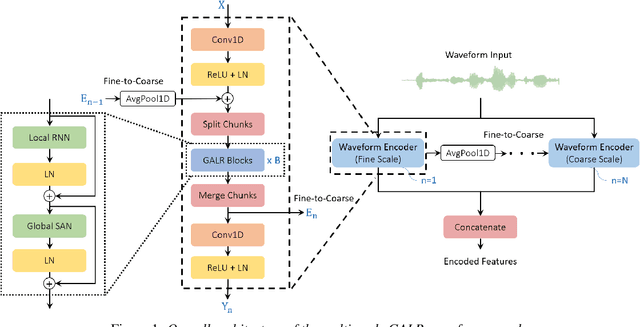
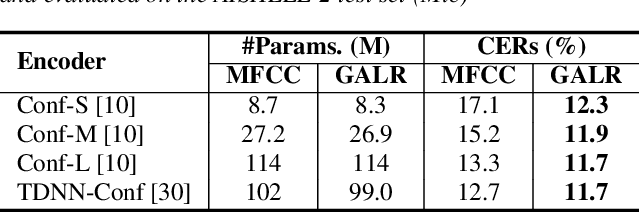
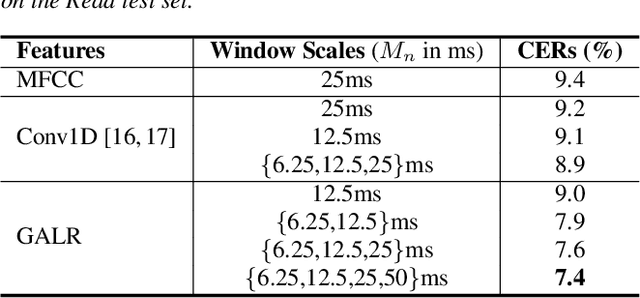
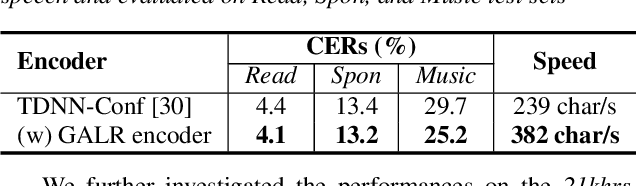
End-to-end speech recognition generally uses hand-engineered acoustic features as input and excludes the feature extraction module from its joint optimization. To extract learnable and adaptive features and mitigate information loss, we propose a new encoder that adopts globally attentive locally recurrent (GALR) networks and directly takes raw waveform as input. We observe improved ASR performance and robustness by applying GALR on different window lengths to aggregate fine-grain temporal information into multi-scale acoustic features. Experiments are conducted on a benchmark dataset AISHELL-2 and two large-scale Mandarin speech corpus of 5,000 hours and 21,000 hours. With faster speed and comparable model size, our proposed multi-scale GALR waveform encoder achieved consistent character error rate reductions (CERRs) from 7.9% to 28.1% relative over strong baselines, including Conformer and TDNN-Conformer. In particular, our approach demonstrated notable robustness than the traditional handcrafted features and outperformed the baseline MFCC-based TDNN-Conformer model by a 15.2% CERR on a music-mixed real-world speech test set.
Quantifying and Maximizing the Benefits of Back-End Noise Adaption on Attention-Based Speech Recognition Models
May 03, 2021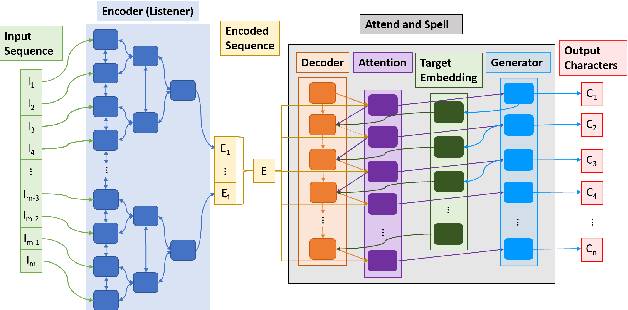

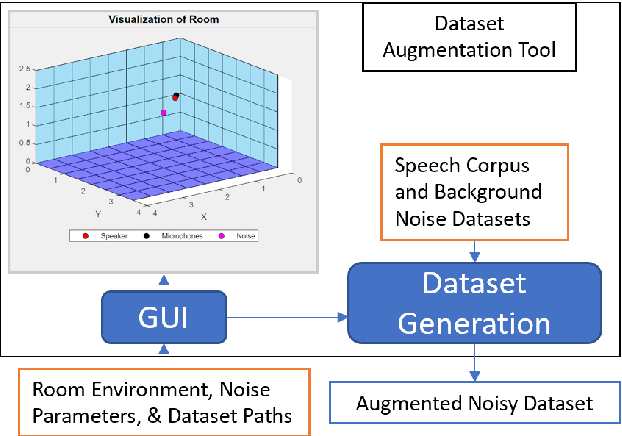
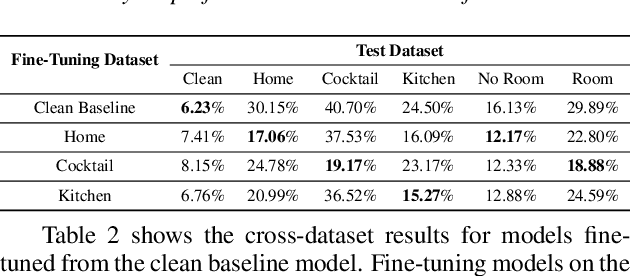
This work analyzes how attention-based Bidirectional Long Short-Term Memory (BLSTM) models adapt to noise-augmented speech. We identify crucial components for noise adaptation in BLSTM models by freezing model components during fine-tuning. We first freeze larger model subnetworks and then pursue a fine-grained freezing approach in the encoder after identifying its importance for noise adaptation. The first encoder layer is shown to be crucial for noise adaptation, and the weights are shown to be more important than the other layers. Appreciable accuracy benefits are identified when fine-tuning on a target noisy environment from a model pretrained with noisy speech relative to fine-tuning from a model pretrained with only clean speech when tested on the target noisy environment. For this analysis, we produce our own dataset augmentation tool and it is open-sourced to encourage future efforts in exploring noise adaptation in ASR.
Transformer with Bidirectional Decoder for Speech Recognition
Aug 11, 2020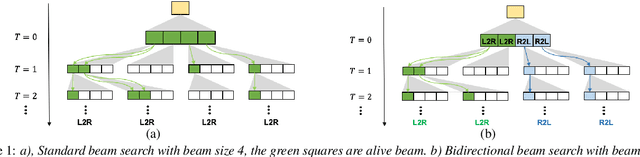
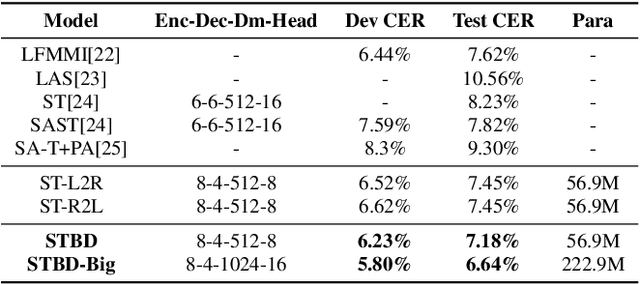
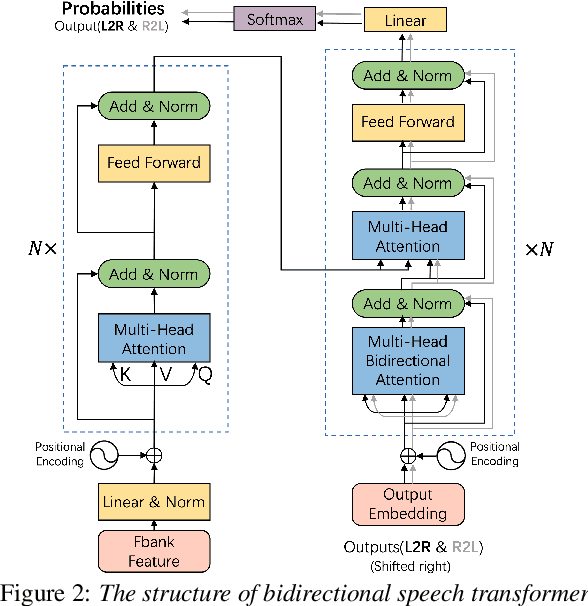

Attention-based models have made tremendous progress on end-to-end automatic speech recognition(ASR) recently. However, the conventional transformer-based approaches usually generate the sequence results token by token from left to right, leaving the right-to-left contexts unexploited. In this work, we introduce a bidirectional speech transformer to utilize the different directional contexts simultaneously. Specifically, the outputs of our proposed transformer include a left-to-right target, and a right-to-left target. In inference stage, we use the introduced bidirectional beam search method, which can not only generate left-to-right candidates but also generate right-to-left candidates, and determine the best hypothesis by the score. To demonstrate our proposed speech transformer with a bidirectional decoder(STBD), we conduct extensive experiments on the AISHELL-1 dataset. The results of experiments show that STBD achieves a 3.6\% relative CER reduction(CERR) over the unidirectional speech transformer baseline. Besides, the strongest model in this paper called STBD-Big can achieve 6.64\% CER on the test set, without language model rescoring and any extra data augmentation strategies.
CarneliNet: Neural Mixture Model for Automatic Speech Recognition
Jul 22, 2021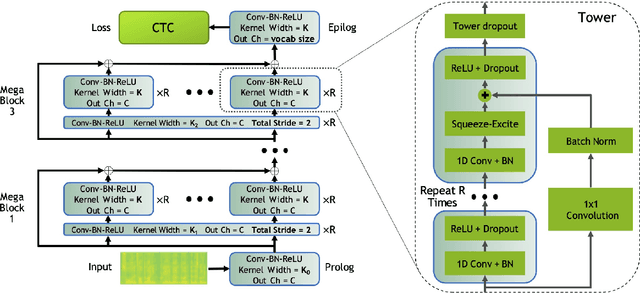
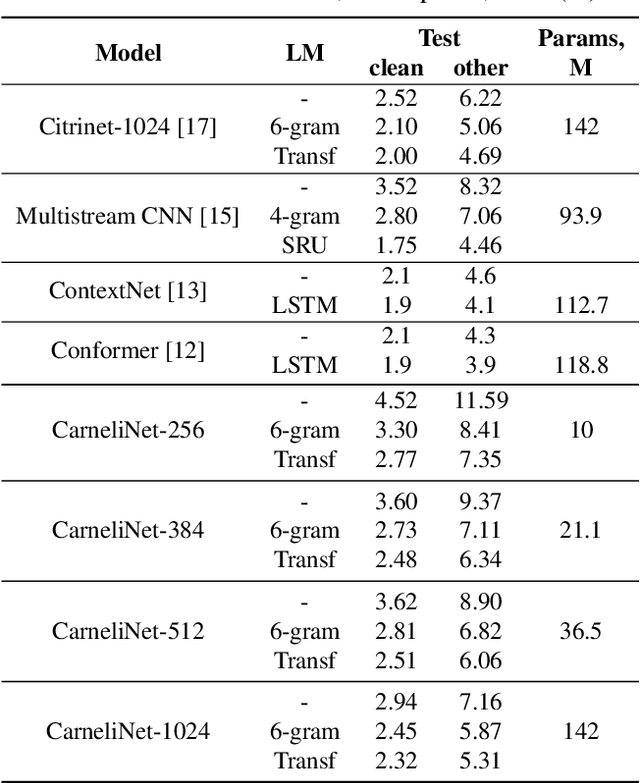
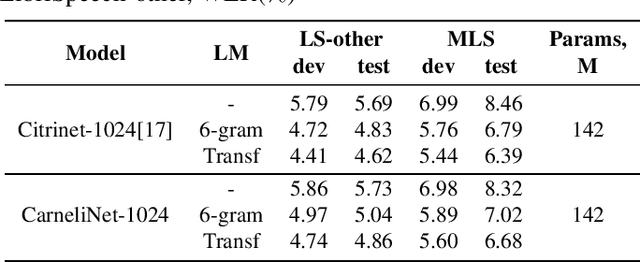
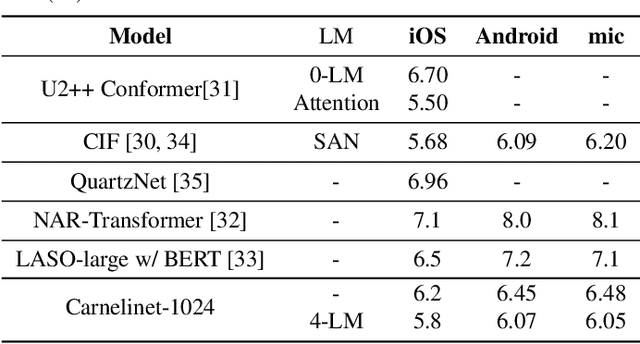
End-to-end automatic speech recognition systems have achieved great accuracy by using deeper and deeper models. However, the increased depth comes with a larger receptive field that can negatively impact model performance in streaming scenarios. We propose an alternative approach that we call Neural Mixture Model. The basic idea is to introduce a parallel mixture of shallow networks instead of a very deep network. To validate this idea we design CarneliNet -- a CTC-based neural network composed of three mega-blocks. Each mega-block consists of multiple parallel shallow sub-networks based on 1D depthwise-separable convolutions. We evaluate the model on LibriSpeech, MLS and AISHELL-2 datasets and achieved close to state-of-the-art results for CTC-based models. Finally, we demonstrate that one can dynamically reconfigure the number of parallel sub-networks to accommodate the computational requirements without retraining.
Deep MOS Predictor for Synthetic Speech Using Cluster-Based Modeling
Aug 09, 2020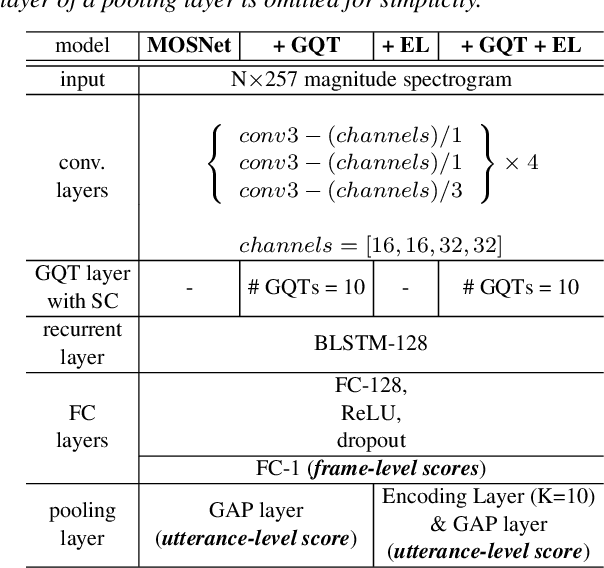

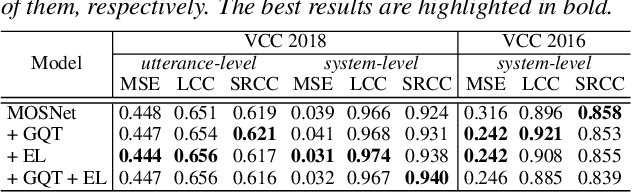
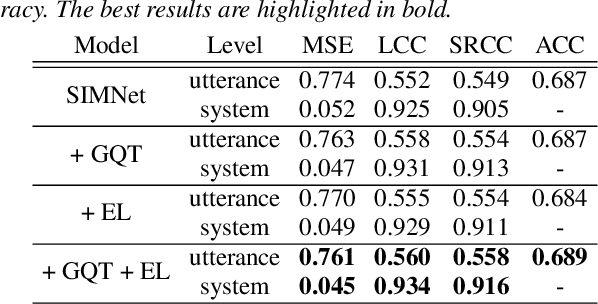
While deep learning has made impressive progress in speech synthesis and voice conversion, the assessment of the synthesized speech is still carried out by human participants. Several recent papers have proposed deep-learning-based assessment models and shown the potential to automate the speech quality assessment. To improve the previously proposed assessment model, MOSNet, we propose three models using cluster-based modeling methods: using a global quality token (GQT) layer, using an Encoding Layer, and using both of them. We perform experiments using the evaluation results of the Voice Conversion Challenge 2018 to predict the mean opinion score of synthesized speech and similarity score between synthesized speech and reference speech. The results show that the GQT layer helps to predict human assessment better by automatically learning the useful quality tokens for the task and that the Encoding Layer helps to utilize frame-level scores more precisely.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020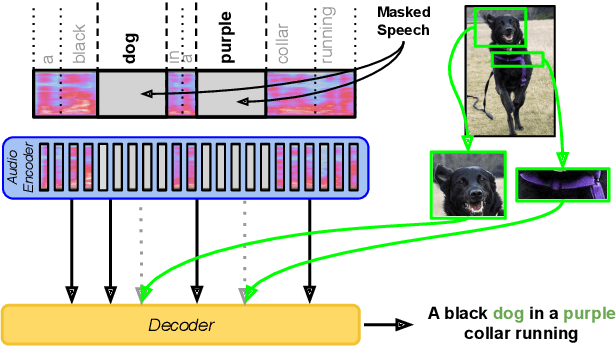
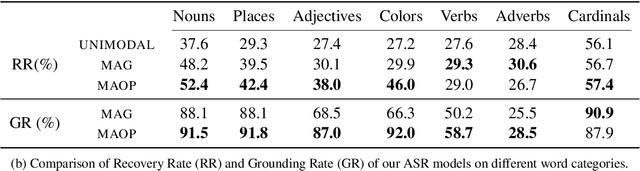
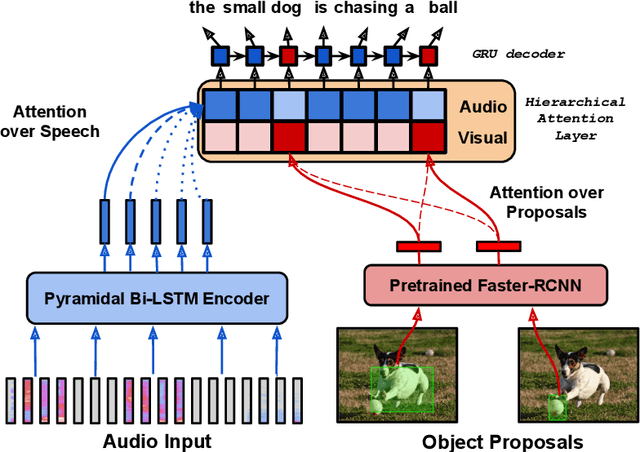
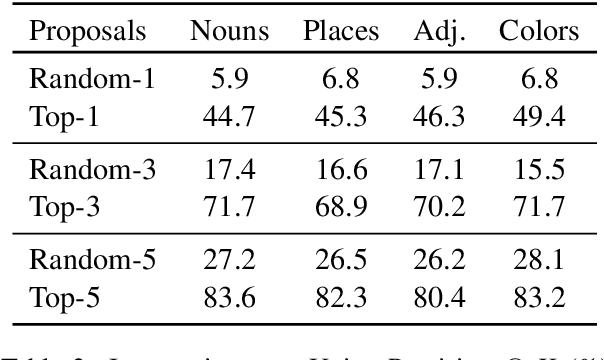
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
Disentangled Speaker Representation Learning via Mutual Information Minimization
Aug 17, 2022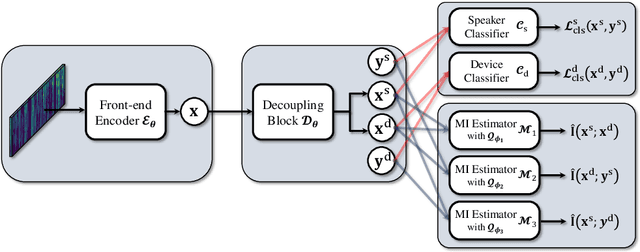
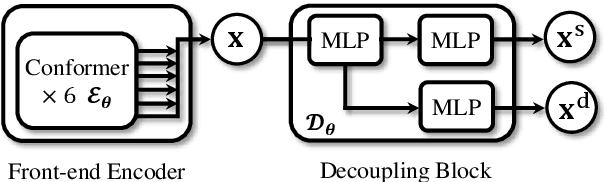
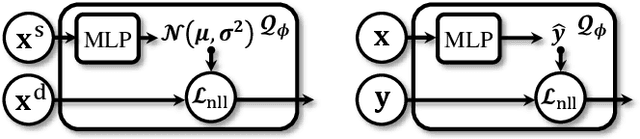
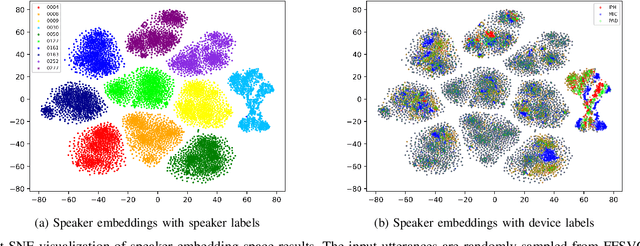
Domain mismatch problem caused by speaker-unrelated feature has been a major topic in speaker recognition. In this paper, we propose an explicit disentanglement framework to unravel speaker-relevant features from speaker-unrelated features via mutual information (MI) minimization. To achieve our goal of minimizing MI between speaker-related and speaker-unrelated features, we adopt a contrastive log-ratio upper bound (CLUB), which exploits the upper bound of MI. Our framework is constructed in a 3-stage structure. First, in the front-end encoder, input speech is encoded into shared initial embedding. Next, in the decoupling block, shared initial embedding is split into separate speaker-related and speaker-unrelated embeddings. Finally, disentanglement is conducted by MI minimization in the last stage. Experiments on Far-Field Speaker Verification Challenge 2022 (FFSVC2022) demonstrate that our proposed framework is effective for disentanglement. Also, to utilize domain-unknown datasets containing numerous speakers, we pre-trained the front-end encoder with VoxCeleb datasets. We then fine-tuned the speaker embedding model in the disentanglement framework with FFSVC 2022 dataset. The experimental results show that fine-tuning with a disentanglement framework on a existing pre-trained model is valid and can further improve performance.
Improving Mandarin End-to-End Speech Recognition with Word N-gram Language Model
Jan 06, 2022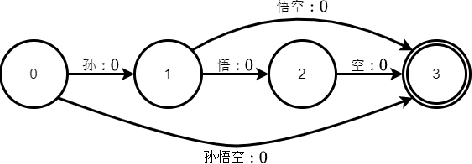
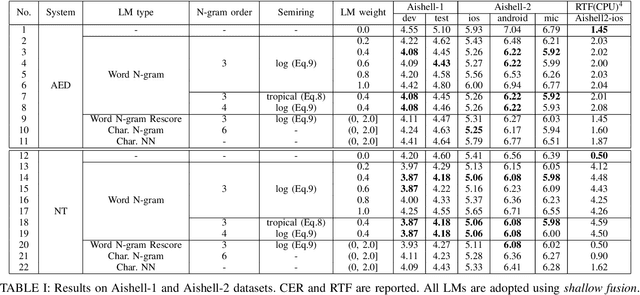
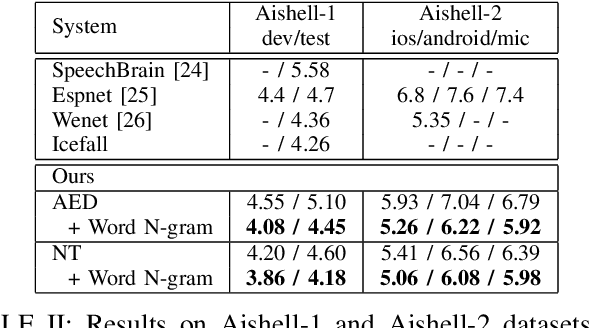
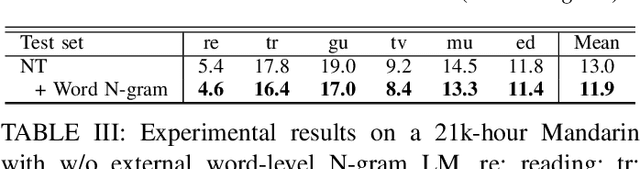
Despite the rapid progress of end-to-end (E2E) automatic speech recognition (ASR), it has been shown that incorporating external language models (LMs) into the decoding can further improve the recognition performance of E2E ASR systems. To align with the modeling units adopted in E2E ASR systems, subword-level (e.g., characters, BPE) LMs are usually used to cooperate with current E2E ASR systems. However, the use of subword-level LMs will ignore the word-level information, which may limit the strength of the external LMs in E2E ASR. Although several methods have been proposed to incorporate word-level external LMs in E2E ASR, these methods are mainly designed for languages with clear word boundaries such as English and cannot be directly applied to languages like Mandarin, in which each character sequence can have multiple corresponding word sequences. To this end, we propose a novel decoding algorithm where a word-level lattice is constructed on-the-fly to consider all possible word sequences for each partial hypothesis. Then, the LM score of the hypothesis is obtained by intersecting the generated lattice with an external word N-gram LM. The proposed method is examined on both Attention-based Encoder-Decoder (AED) and Neural Transducer (NT) frameworks. Experiments suggest that our method consistently outperforms subword-level LMs, including N-gram LM and neural network LM. We achieve state-of-the-art results on both Aishell-1 (CER 4.18%) and Aishell-2 (CER 5.06%) datasets and reduce CER by 14.8% relatively on a 21K-hour Mandarin dataset.
Multi-Channel Speech Enhancement using Graph Neural Networks
Feb 13, 2021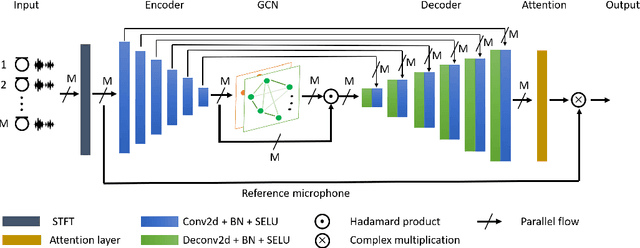
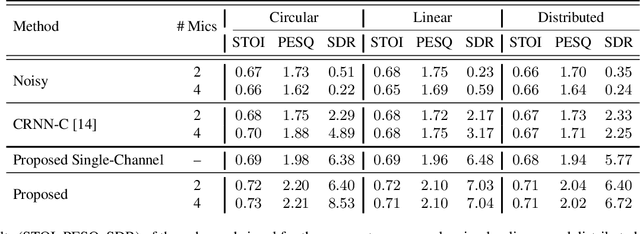

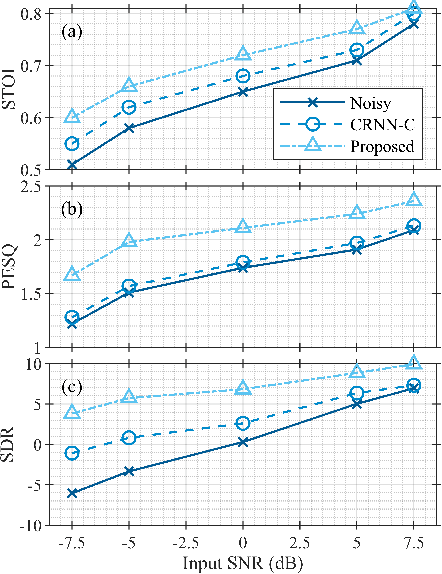
Multi-channel speech enhancement aims to extract clean speech from a noisy mixture using signals captured from multiple microphones. Recently proposed methods tackle this problem by incorporating deep neural network models with spatial filtering techniques such as the minimum variance distortionless response (MVDR) beamformer. In this paper, we introduce a different research direction by viewing each audio channel as a node lying in a non-Euclidean space and, specifically, a graph. This formulation allows us to apply graph neural networks (GNN) to find spatial correlations among the different channels (nodes). We utilize graph convolution networks (GCN) by incorporating them in the embedding space of a U-Net architecture. We use LibriSpeech dataset and simulate room acoustics data to extensively experiment with our approach using different array types, and number of microphones. Results indicate the superiority of our approach when compared to prior state-of-the-art method.