 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Make More of Your Data: Minimal Effort Data Augmentation for Automatic Speech Recognition and Translation
Oct 27, 2022

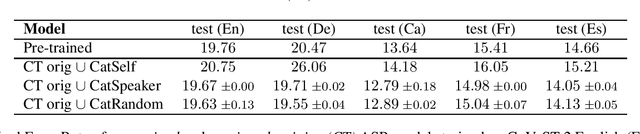

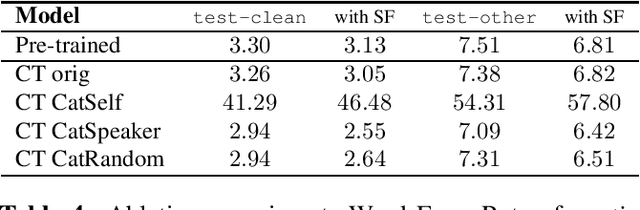
Data augmentation is a technique to generate new training data based on existing data. We evaluate the simple and cost-effective method of concatenating the original data examples to build new training instances. Continued training with such augmented data is able to improve off-the-shelf Transformer and Conformer models that were optimized on the original data only. We demonstrate considerable improvements on the LibriSpeech-960h test sets (WER 2.83 and 6.87 for test-clean and test-other), which carry over to models combined with shallow fusion (WER 2.55 and 6.27). Our method of continued training also leads to improvements of up to 0.9 WER on the ASR part of CoVoST-2 for four non English languages, and we observe that the gains are highly dependent on the size of the original training data. We compare different concatenation strategies and found that our method does not need speaker information to achieve its improvements. Finally, we demonstrate on two datasets that our methods also works for speech translation tasks.
Audio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Nov 20, 2022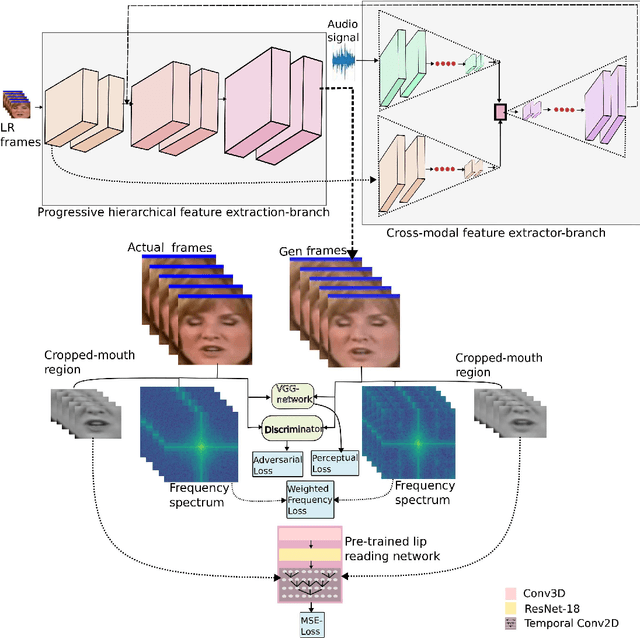
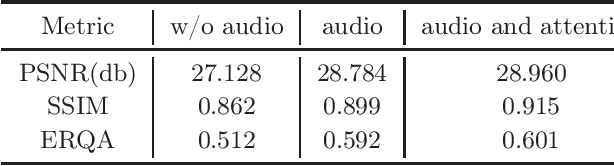

Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.
A Comparative Study on multichannel Speaker-attributed automatic speech recognition in Multi-party Meetings
Nov 01, 2022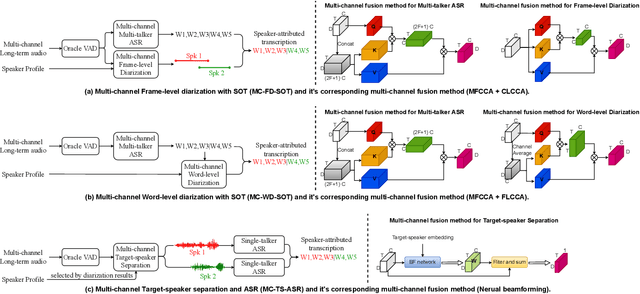


Speaker-attributed automatic speech recognition (SA-ASR) in multiparty meeting scenarios is one of the most valuable and challenging ASR task. It was shown that single-channel frame-level diarization with serialized output training (SC-FD-SOT), single-channel word-level diarization with SOT (SC-WD-SOT) and joint training of single-channel target-speaker separation and ASR (SC-TS-ASR) can be exploited to partially solve this problem. SC-FD-SOT obtains the speaker-attributed transcriptions by aligning the speaker diarization results with the ASR hypotheses, SC-WD-SOT uses word-level diarization to get rid of the alignment dependence on timestamps, and SC-TS-ASR jointly trains target-speaker separation and ASR modules, which achieves the best performance. In this paper, we propose three corresponding multichannel (MC) SA-ASR approaches, namely MC-FD-SOT, MC-WD-SOT and MC-TS-ASR. For different tasks/models, different multichannel data fusion strategies are considered, including channel-level cross-channel attention for MC-FD-SOT, frame-level cross-channel attention for MC-WD-SOT and neural beamforming for MC-TS-ASR. Experimental results on the AliMeeting corpus reveal that our proposed multichannel SA-ASR models can consistently outperform the corresponding single-channel counterparts in terms of the speaker-dependent character error rate (SD-CER).
Tiny-Sepformer: A Tiny Time-Domain Transformer Network for Speech Separation
Jun 30, 2022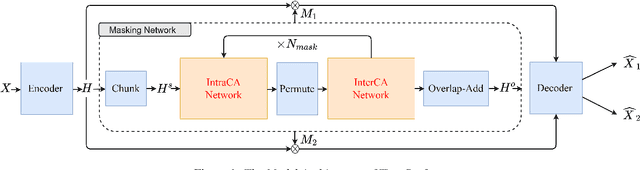

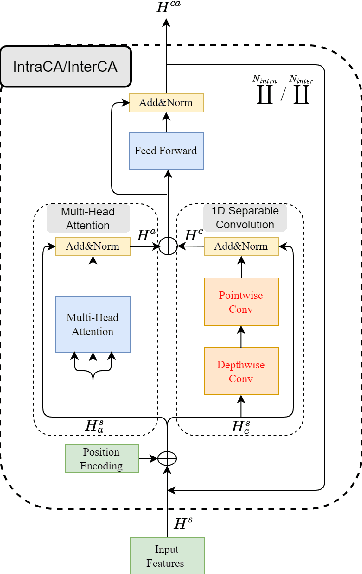
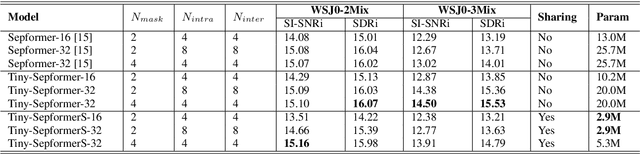
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a large number of network parameters, thus often encountering the problem of GPU memory explosion. In this paper, we proposed Tiny-Sepformer, a tiny version of Transformer network for speech separation. We present two techniques to reduce the model parameters and memory consumption: (1) Convolution-Attention (CA) block, spliting the vanilla Transformer to two paths, multi-head attention and 1D depthwise separable convolution, (2) parameter sharing, sharing the layer parameters within the CA block. In our experiments, Tiny-Sepformer could greatly reduce the model size, and achieves comparable separation performance with vanilla Sepformer on WSJ0-2/3Mix datasets.
An Investigation on Applying Acoustic Feature Conversion to ASR of Adult and Child Speech
May 25, 2022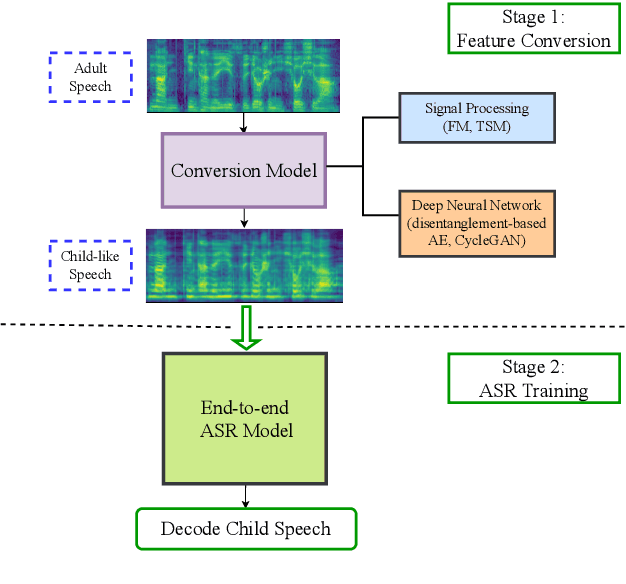
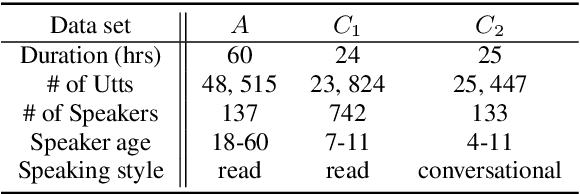
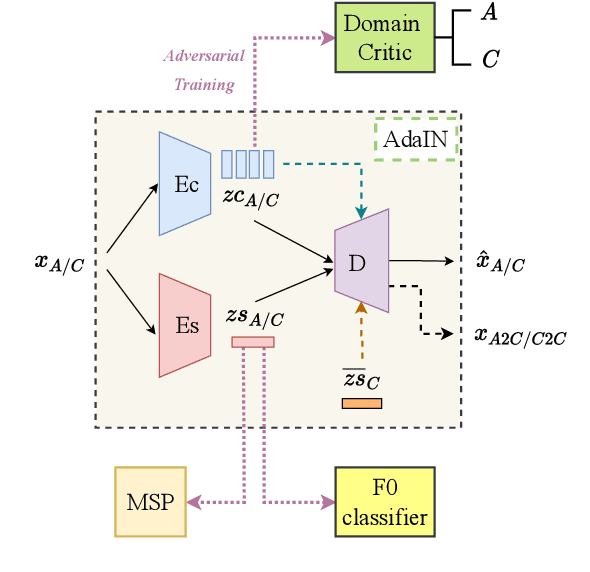
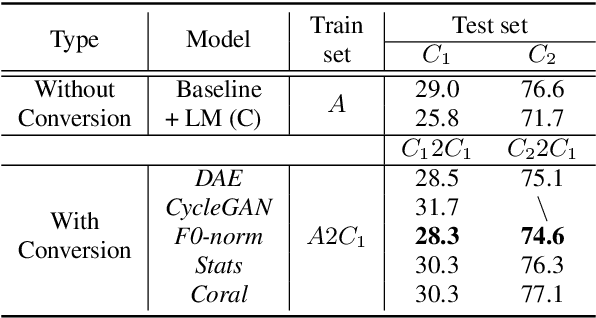
The performance of child speech recognition is generally less satisfactory compared to adult speech due to limited amount of training data. Significant performance degradation is expected when applying an automatic speech recognition (ASR) system trained on adult speech to child speech directly, as a result of domain mismatch. The present study is focused on adult-to-child acoustic feature conversion to alleviate this mismatch. Different acoustic feature conversion approaches, including deep neural network based and signal processing based, are investigated and compared under a fair experimental setting, in which converted acoustic features from the same amount of labeled adult speech are used to train the ASR models from scratch. Experimental results reveal that not all of the conversion methods lead to ASR performance gain. Specifically, as a classic unsupervised domain adaptation method, the statistic matching does not show an effectiveness. A disentanglement-based auto-encoder (DAE) conversion framework is found to be useful and the approach of F0 normalization achieves the best performance. It is noted that the F0 distribution of converted features is an important attribute to reflect the conversion quality, while utilizing an adult-child deep classification model to make judgment is shown to be inappropriate.
Low-Resource End-to-end Sanskrit TTS using Tacotron2, WaveGlow and Transfer Learning
Dec 07, 2022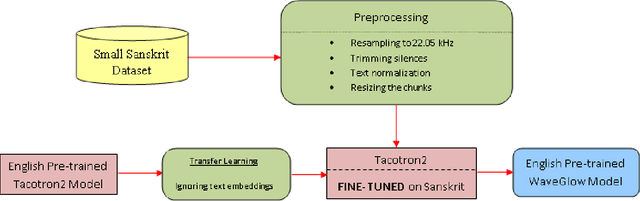
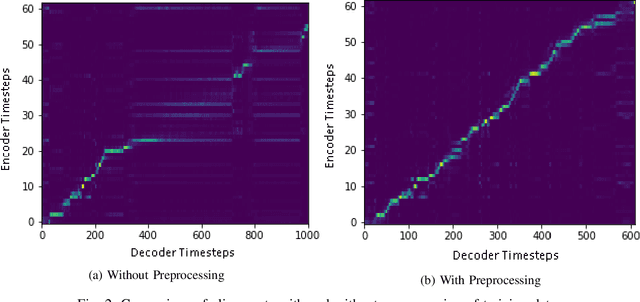
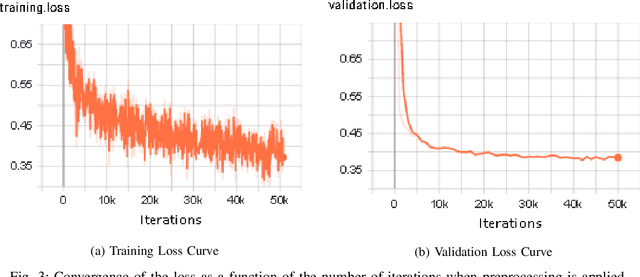

End-to-end text-to-speech (TTS) systems have been developed for European languages like English and Spanish with state-of-the-art speech quality, prosody, and naturalness. However, development of end-to-end TTS for Indian languages is lagging behind in terms of quality. The challenges involved in such a task are: 1) scarcity of quality training data; 2) low efficiency during training and inference; 3) slow convergence in the case of large vocabulary size. In our work reported in this paper, we have investigated the use of fine-tuning the English-pretrained Tacotron2 model with limited Sanskrit data to synthesize natural sounding speech in Sanskrit in low resource settings. Our experiments show encouraging results, achieving an overall MOS of 3.38 from 37 evaluators with good Sanskrit spoken knowledge. This is really a very good result, considering the fact that the speech data we have used is of duration 2.5 hours only.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023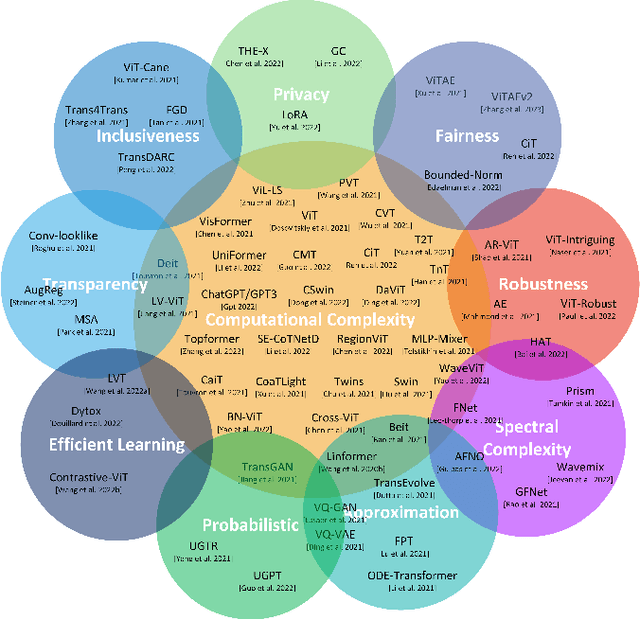
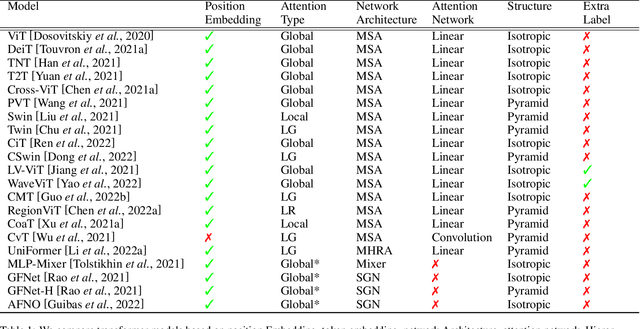
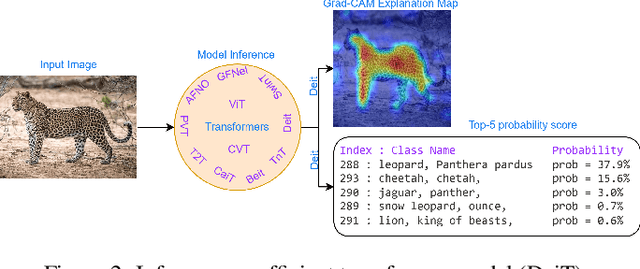
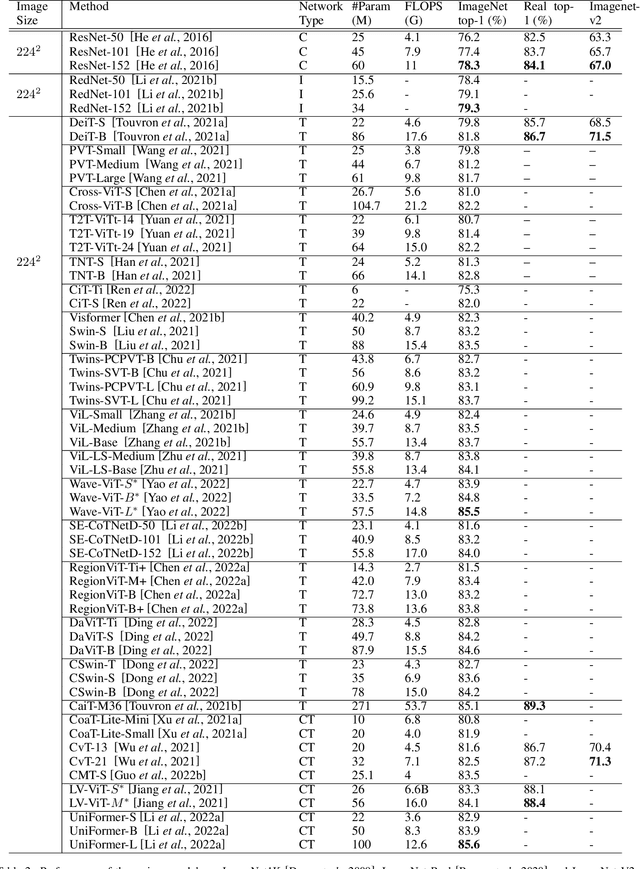
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
EmoGator: A New Open Source Vocal Burst Dataset with Baseline Machine Learning Classification Methodologies
Jan 02, 2023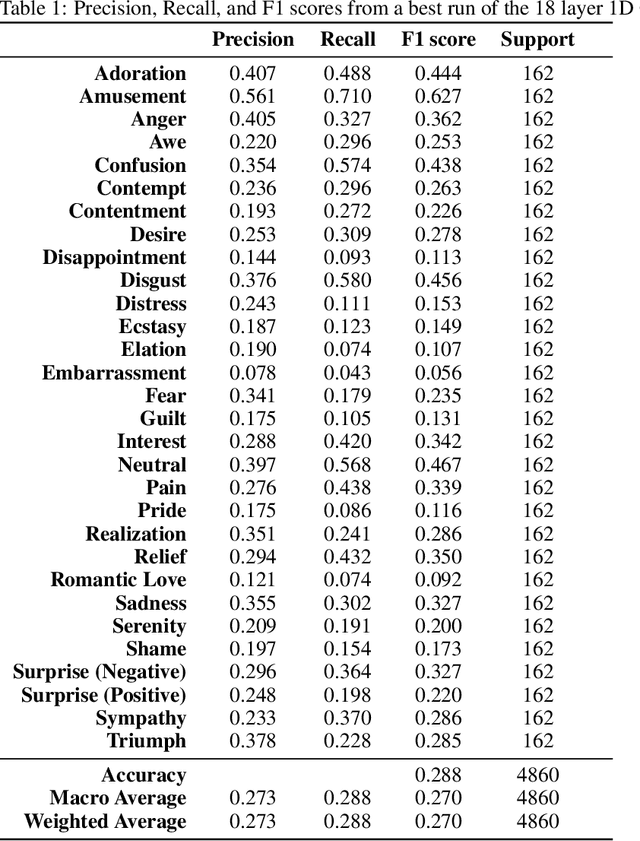
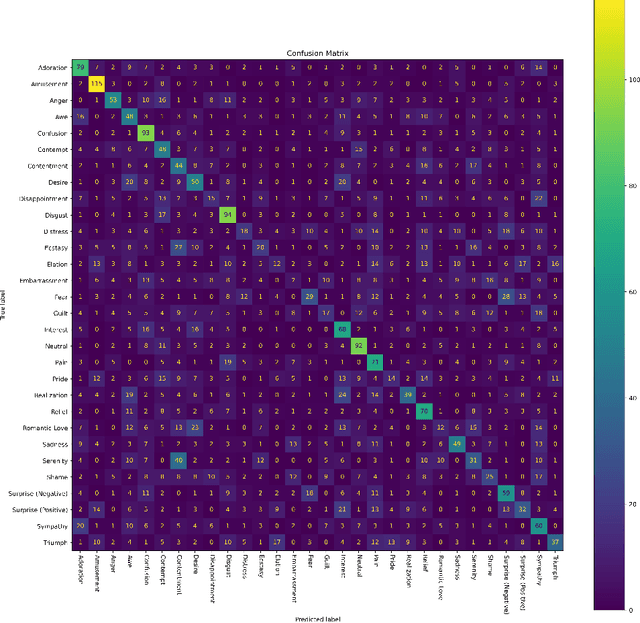

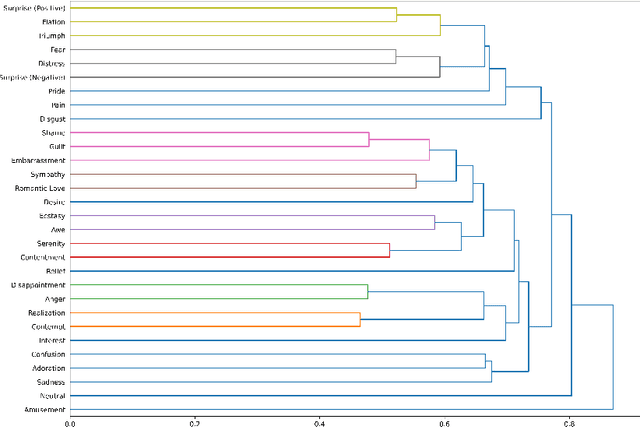
Vocal Bursts -- short, non-speech vocalizations that convey emotions, such as laughter, cries, sighs, moans, and groans -- are an often-overlooked aspect of speech emotion recognition, but an important aspect of human vocal communication. One barrier to study of these interesting vocalizations is a lack of large datasets. I am pleased to introduce the EmoGator dataset, which consists of 32,040 samples from 365 speakers, 16.91 hours of audio; each sample classified into one of 30 distinct emotion categories by the speaker. Several different approaches to construct classifiers to identify emotion categories will be discussed, and directions for future research will be suggested. Data set is available for download from https://github.com/fredbuhl/EmoGator.
TDASS: Target Domain Adaptation Speech Synthesis Framework for Multi-speaker Low-Resource TTS
May 24, 2022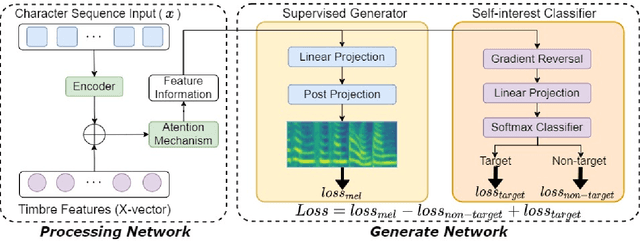
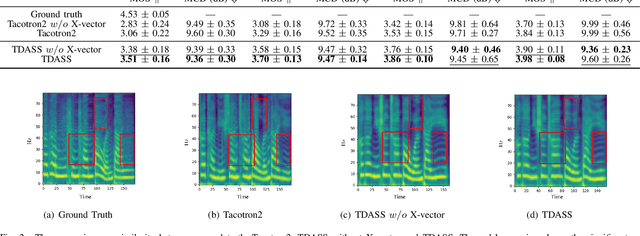
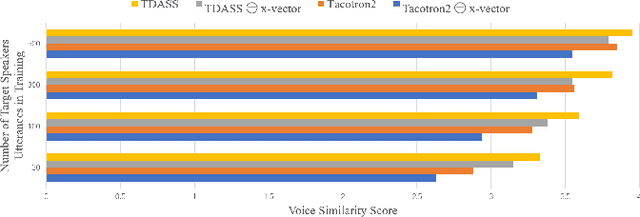
Recently, synthesizing personalized speech by text-to-speech (TTS) application is highly demanded. But the previous TTS models require a mass of target speaker speeches for training. It is a high-cost task, and hard to record lots of utterances from the target speaker. Data augmentation of the speeches is a solution but leads to the low-quality synthesis speech problem. Some multi-speaker TTS models are proposed to address the issue. But the quantity of utterances of each speaker imbalance leads to the voice similarity problem. We propose the Target Domain Adaptation Speech Synthesis Network (TDASS) to address these issues. Based on the backbone of the Tacotron2 model, which is the high-quality TTS model, TDASS introduces a self-interested classifier for reducing the non-target influence. Besides, a special gradient reversal layer with different operations for target and non-target is added to the classifier. We evaluate the model on a Chinese speech corpus, the experiments show the proposed method outperforms the baseline method in terms of voice quality and voice similarity.
Knowledge-Based Counterfactual Queries for Visual Question Answering
Mar 05, 2023
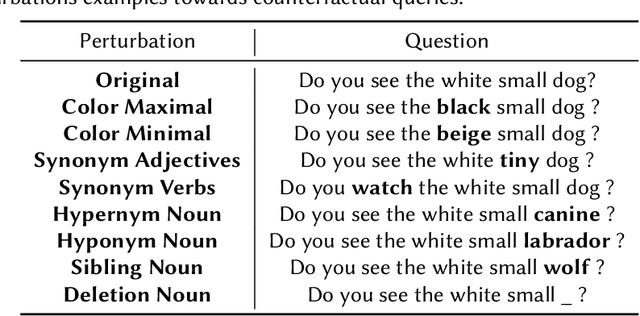
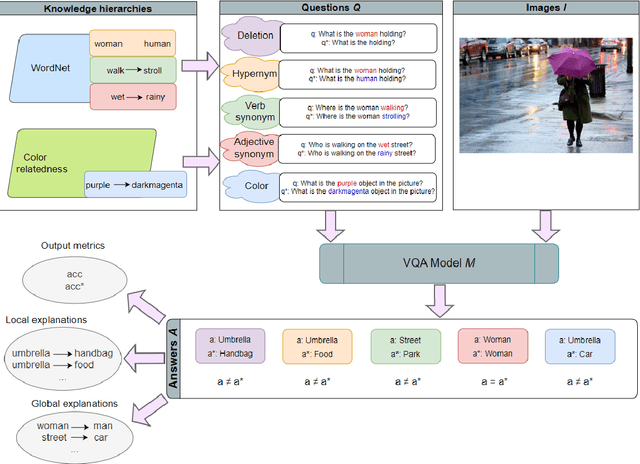

Visual Question Answering (VQA) has been a popular task that combines vision and language, with numerous relevant implementations in literature. Even though there are some attempts that approach explainability and robustness issues in VQA models, very few of them employ counterfactuals as a means of probing such challenges in a model-agnostic way. In this work, we propose a systematic method for explaining the behavior and investigating the robustness of VQA models through counterfactual perturbations. For this reason, we exploit structured knowledge bases to perform deterministic, optimal and controllable word-level replacements targeting the linguistic modality, and we then evaluate the model's response against such counterfactual inputs. Finally, we qualitatively extract local and global explanations based on counterfactual responses, which are ultimately proven insightful towards interpreting VQA model behaviors. By performing a variety of perturbation types, targeting different parts of speech of the input question, we gain insights to the reasoning of the model, through the comparison of its responses in different adversarial circumstances. Overall, we reveal possible biases in the decision-making process of the model, as well as expected and unexpected patterns, which impact its performance quantitatively and qualitatively, as indicated by our analysis.