 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Array Configuration-Agnostic Personalized Speech Enhancement using Long-Short-Term Spatial Coherence
Nov 16, 2022
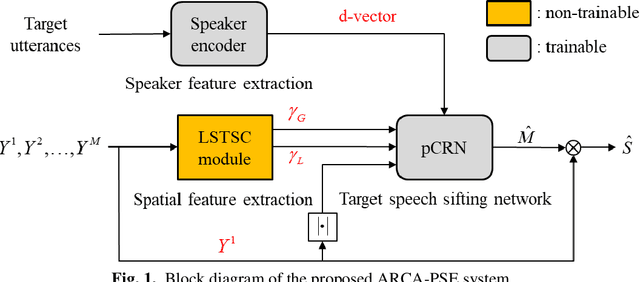
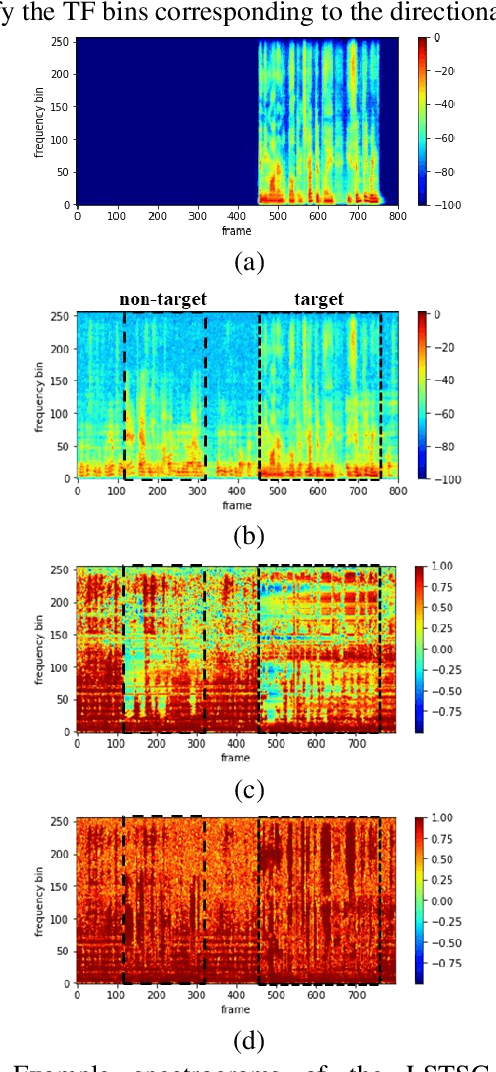
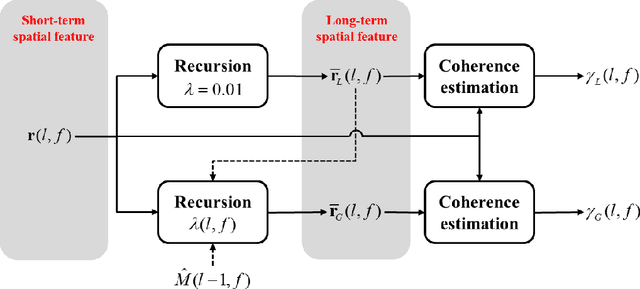
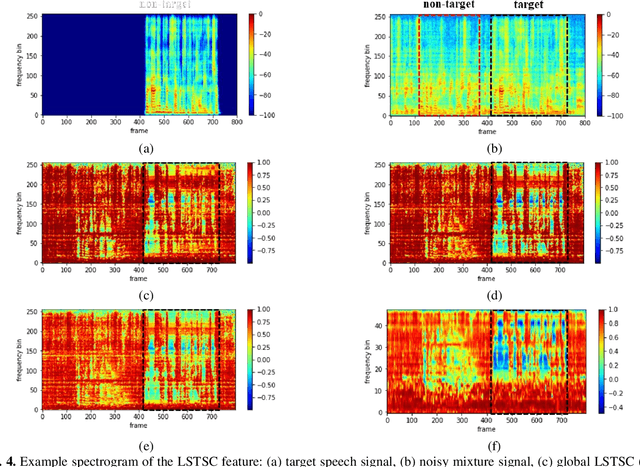
Personalized speech enhancement has been a field of active research for suppression of speechlike interferers such as competing speakers or TV dialogues. Compared with single channel approaches, multichannel PSE systems can be more effective in adverse acoustic conditions by leveraging the spatial information in microphone signals. However, the implementation of multichannel PSEs to accommodate a wide range of array topology in household applications can be challenging. To develop an array configuration agnostic PSE system, we define a spatial feature termed the long short term spatial coherence as the input feature to a convolutional recurrent network to monitor the voice activity of the target speaker. As another refinement, an equivalent rectangular bandwidth scaled LSTSC feature can be used to reduce the computational cost. Experiments were conducted to compare the proposed PSE systems, including the complete and the simplified versions with two baselines using unseen room responses and array configurations in the presence of TV noise and competing speakers. The results demonstrated that the proposed multichannel PSE network trained with the LSTSC feature achieved superior enhancement performance without precise knowledge of the array configurations and room responses.
Improving Speech Recognition on Noisy Speech via Speech Enhancement with Multi-Discriminators CycleGAN
Dec 12, 2021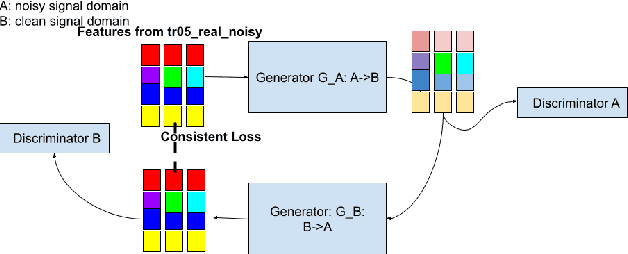
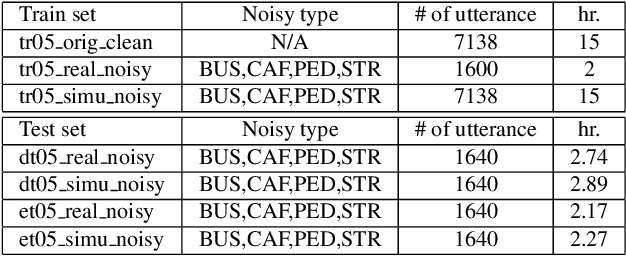
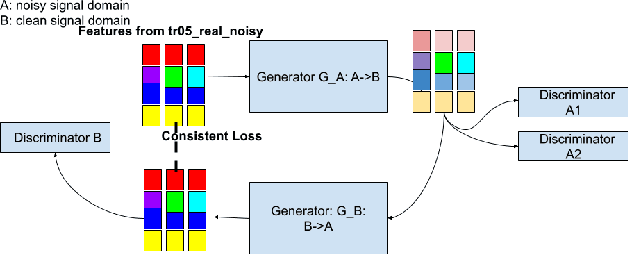
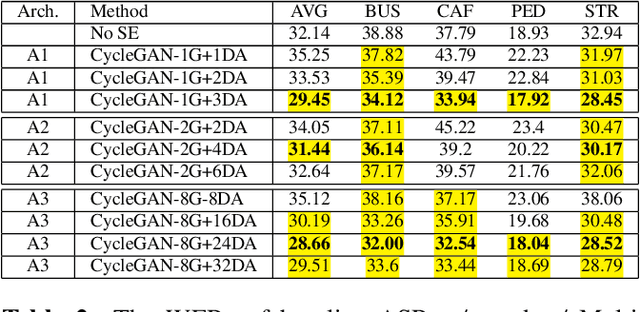
This paper presents our latest investigations on improving automatic speech recognition for noisy speech via speech enhancement. We propose a novel method named Multi-discriminators CycleGAN to reduce noise of input speech and therefore improve the automatic speech recognition performance. Our proposed method leverages the CycleGAN framework for speech enhancement without any parallel data and improve it by introducing multiple discriminators that check different frequency areas. Furthermore, we show that training multiple generators on homogeneous subset of the training data is better than training one generator on all the training data. We evaluate our method on CHiME-3 data set and observe up to 10.03% relatively WER improvement on the development set and up to 14.09% on the evaluation set.
Direct simultaneous speech to speech translation
Oct 15, 2021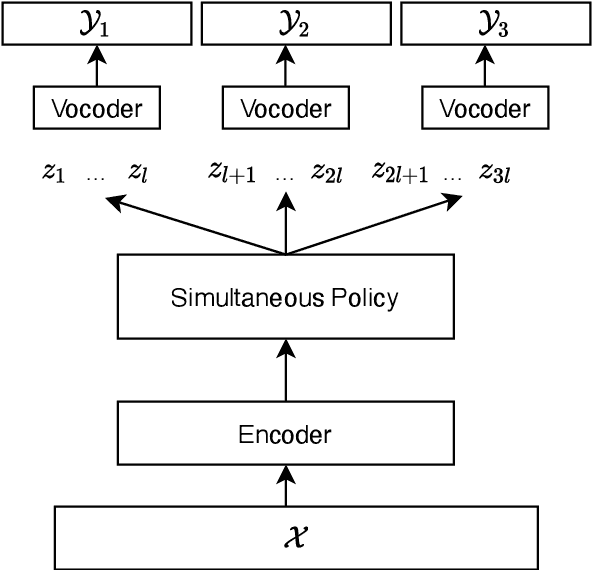
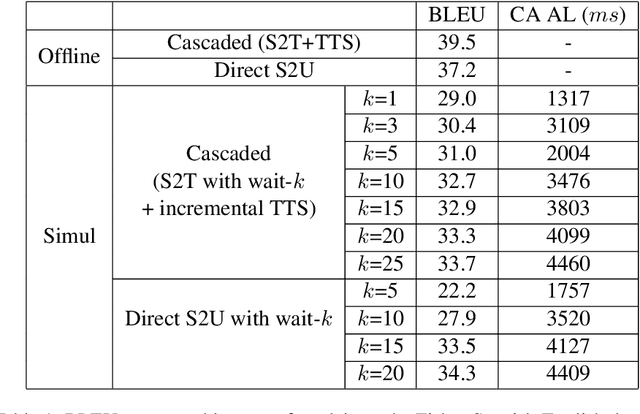
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
FaceChat: An Emotion-Aware Face-to-face Dialogue Framework
Mar 08, 2023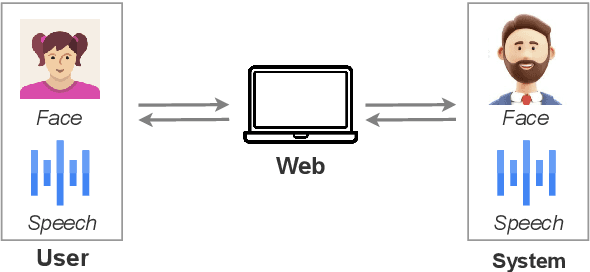
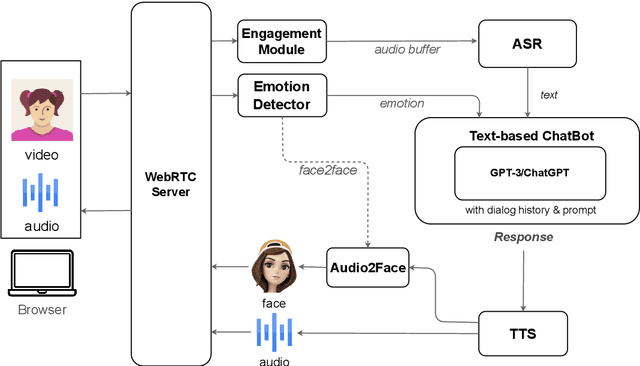
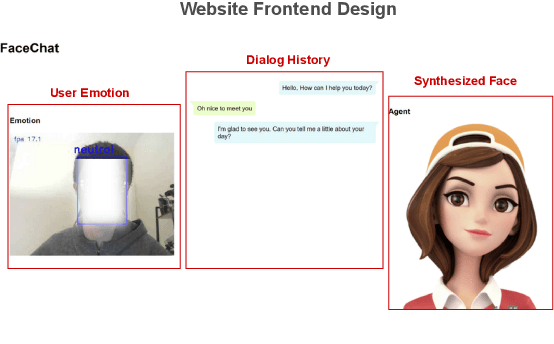
While current dialogue systems like ChatGPT have made significant advancements in text-based interactions, they often overlook the potential of other modalities in enhancing the overall user experience. We present FaceChat, a web-based dialogue framework that enables emotionally-sensitive and face-to-face conversations. By seamlessly integrating cutting-edge technologies in natural language processing, computer vision, and speech processing, FaceChat delivers a highly immersive and engaging user experience. FaceChat framework has a wide range of potential applications, including counseling, emotional support, and personalized customer service. The system is designed to be simple and flexible as a platform for future researchers to advance the field of multimodal dialogue systems. The code is publicly available at https://github.com/qywu/FaceChat.
Guided-TTS:Text-to-Speech with Untranscribed Speech
Nov 23, 2021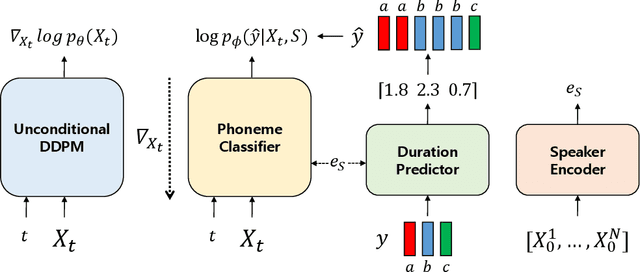

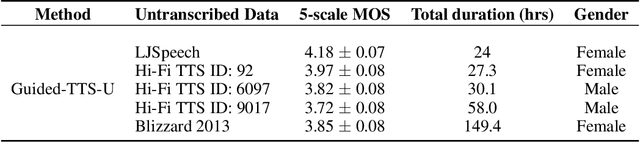
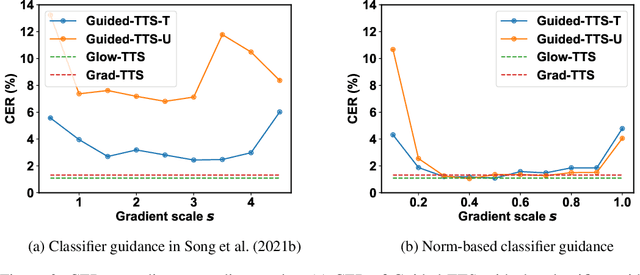
Most neural text-to-speech (TTS) models require <speech, transcript> paired data from the desired speaker for high-quality speech synthesis, which limits the usage of large amounts of untranscribed data for training. In this work, we present Guided-TTS, a high-quality TTS model that learns to generate speech from untranscribed speech data. Guided-TTS combines an unconditional diffusion probabilistic model with a separately trained phoneme classifier for text-to-speech. By modeling the unconditional distribution for speech, our model can utilize the untranscribed data for training. For text-to-speech synthesis, we guide the generative process of the unconditional DDPM via phoneme classification to produce mel-spectrograms from the conditional distribution given transcript. We show that Guided-TTS achieves comparable performance with the existing methods without any transcript for LJSpeech. Our results further show that a single speaker-dependent phoneme classifier trained on multispeaker large-scale data can guide unconditional DDPMs for various speakers to perform TTS.
IRFL: Image Recognition of Figurative Language
Mar 27, 2023
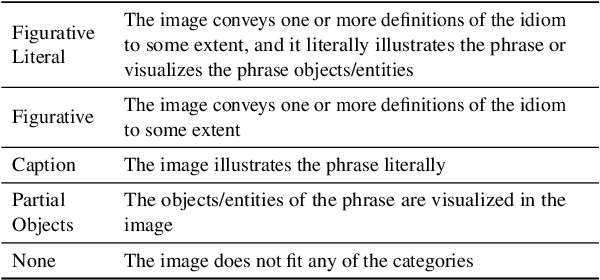

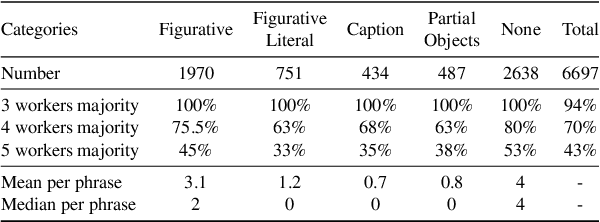
Figures of speech such as metaphors, similes, and idioms allow language to be expressive, invoke emotion, and communicate abstract ideas that might otherwise be difficult to visualize. These figurative forms are often conveyed through multiple modes, such as text and images, and frequently appear in advertising, news, social media, etc. Understanding multimodal figurative language is an essential component of human communication, and it plays a significant role in our daily interactions. While humans can intuitively understand multimodal figurative language, this poses a challenging task for machines that requires the cognitive ability to map between domains, abstraction, commonsense, and profound language and cultural knowledge. In this work, we propose the Image Recognition of Figurative Language dataset to examine vision and language models' understanding of figurative language. We leverage human annotation and an automatic pipeline we created to generate a multimodal dataset and introduce two novel tasks as a benchmark for multimodal figurative understanding. We experiment with several baseline models and find that all perform substantially worse than humans. We hope our dataset and benchmark will drive the development of models that will better understand figurative language.
AI-Based Automated Speech Therapy Tools for persons with Speech Sound Disorders: A Systematic Literature Review
Apr 21, 2022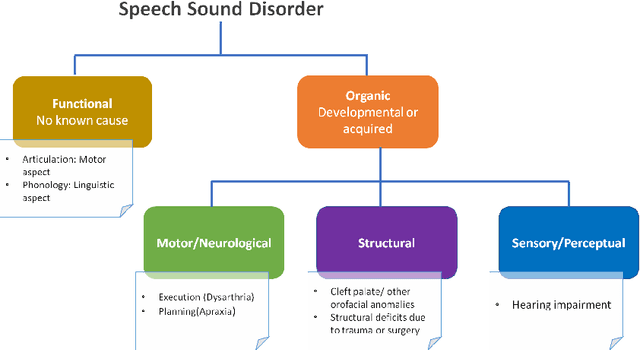
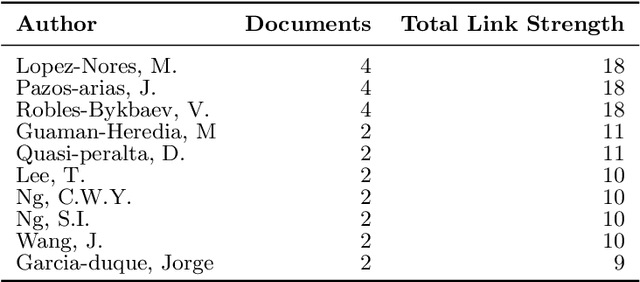
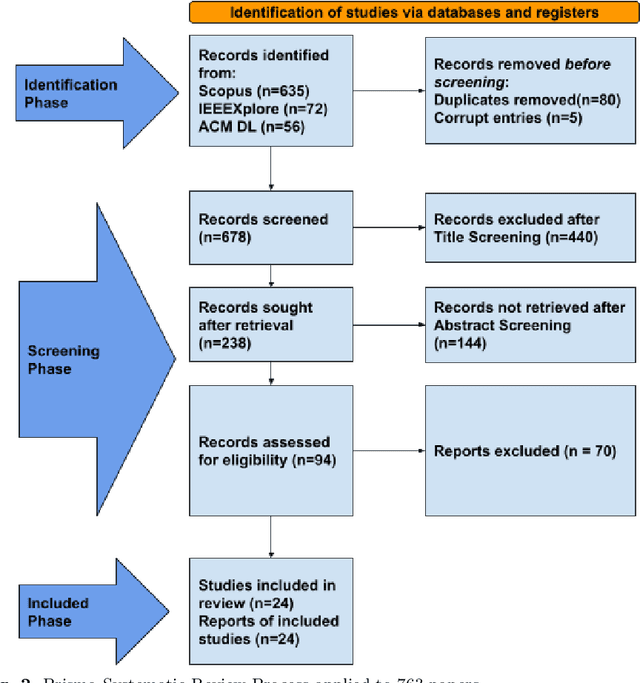
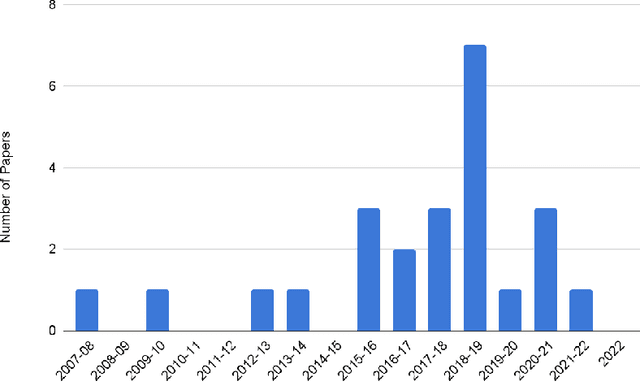
This paper presents a systematic literature review of published studies on AI-based automated speech therapy tools for persons with speech sound disorders (SSD). The COVID-19 pandemic has initiated the requirement for automated speech therapy tools for persons with SSD making speech therapy accessible and affordable. However, there are no guidelines for designing such automated tools and their required degree of automation compared to human experts. In this systematic review, we followed the PRISMA framework to address four research questions: 1) what types of SSD do AI-based automated speech therapy tools address, 2) what is the level of autonomy achieved by such tools, 3) what are the different modes of intervention, and 4) how effective are such tools in comparison with human experts. An extensive search was conducted on digital libraries to find research papers relevant to our study from 2007 to 2022. The results show that AI-based automated speech therapy tools for persons with SSD are increasingly gaining attention among researchers. Articulation disorders were the most frequently addressed SSD based on the reviewed papers. Further, our analysis shows that most researchers proposed fully automated tools without considering the role of other stakeholders. Our review indicates that mobile-based and gamified applications were the most frequent mode of intervention. The results further show that only a few studies compared the effectiveness of such tools compared to expert Speech-Language Pathologists (SLP). Our paper presents the state-of-the-art in the field, contributes significant insights based on the research questions, and provides suggestions for future research directions.
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
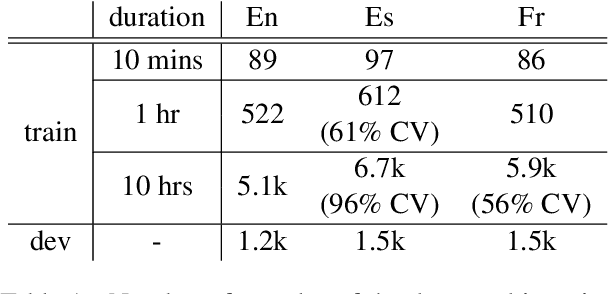
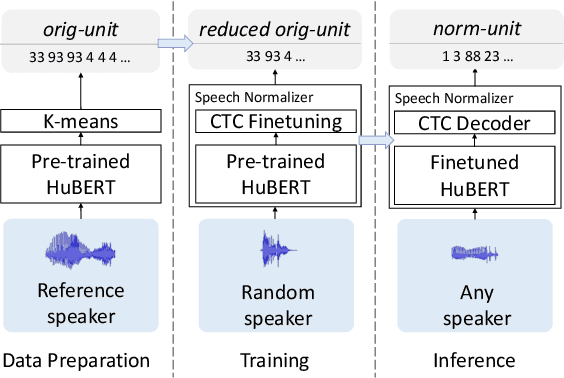
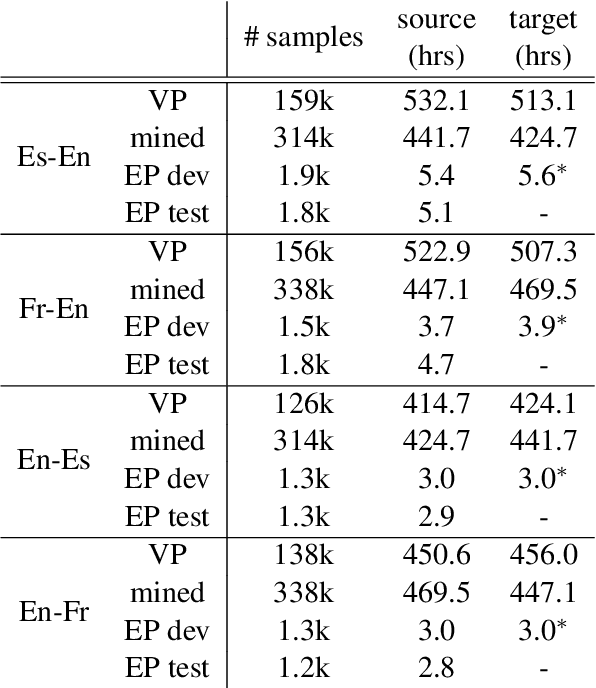
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.
PATCorrect: Non-autoregressive Phoneme-augmented Transformer for ASR Error Correction
Feb 10, 2023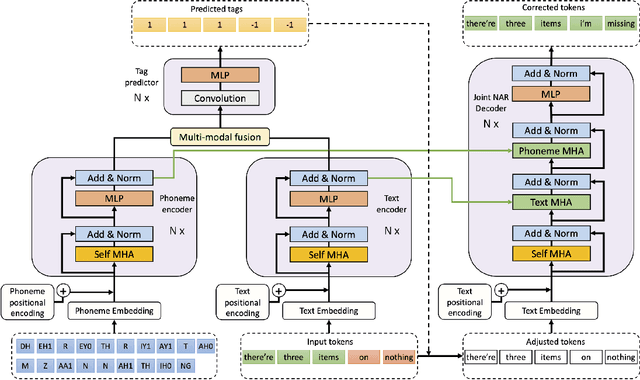
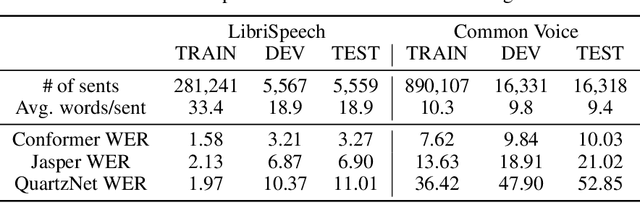
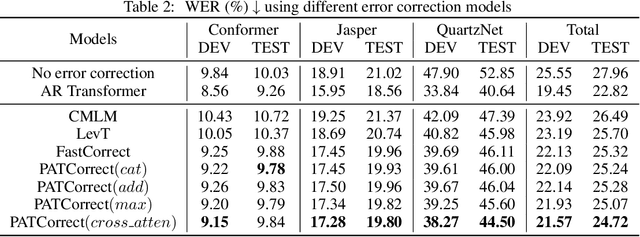
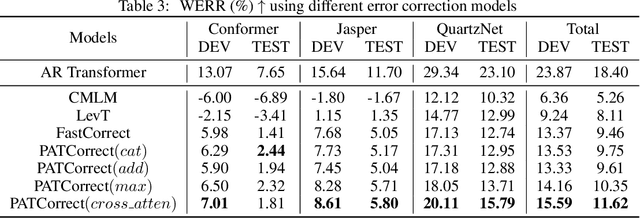
Speech-to-text errors made by automatic speech recognition (ASR) system negatively impact downstream models relying on ASR transcriptions. Language error correction models as a post-processing text editing approach have been recently developed for refining the source sentences. However, efficient models for correcting errors in ASR transcriptions that meet the low latency requirements of industrial grade production systems have not been well studied. In this work, we propose a novel non-autoregressive (NAR) error correction approach to improve the transcription quality by reducing word error rate (WER) and achieve robust performance across different upstream ASR systems. Our approach augments the text encoding of the Transformer model with a phoneme encoder that embeds pronunciation information. The representations from phoneme encoder and text encoder are combined via multi-modal fusion before feeding into the length tagging predictor for predicting target sequence lengths. The joint encoders also provide inputs to the attention mechanism in the NAR decoder. We experiment on 3 open-source ASR systems with varying speech-to-text transcription quality and their erroneous transcriptions on 2 public English corpus datasets. Results show that our PATCorrect (Phoneme Augmented Transformer for ASR error Correction) consistently outperforms state-of-the-art NAR error correction method on English corpus across different upstream ASR systems. For example, PATCorrect achieves 11.62% WER reduction (WERR) averaged on 3 ASR systems compared to 9.46% WERR achieved by other method using text only modality and also achieves an inference latency comparable to other NAR models at tens of millisecond scale, especially on GPU hardware, while still being 4.2 - 6.7x times faster than autoregressive models on Common Voice and LibriSpeech datasets.
Simultaneous Speech Extraction for Multiple Target Speakers under the Meeting Scenarios(V1)
Jun 17, 2022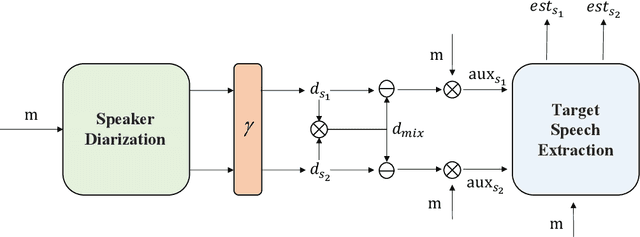
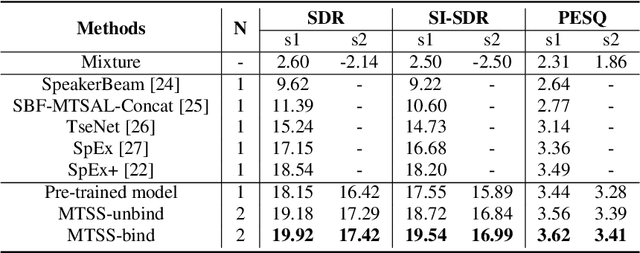
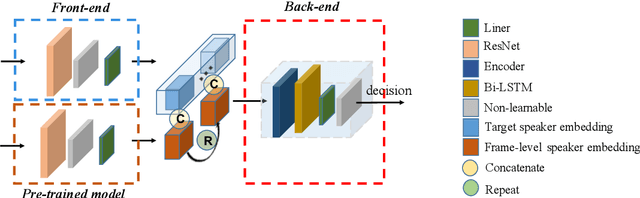
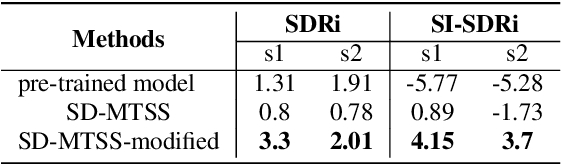
Recently, the target speech separation or extraction techniques under the meeting scenario have become a hot research trend. We propose a speaker diarization aware multiple target speech separation system (SD-MTSS) to simultaneously extract the voice of each speaker from the mixed speech, rather than requiring a succession of independent processes as presented in previous solutions. SD-MTSS consists of a speaker diarization (SD) module and a multiple target speech separation (MTSS) module. The former one infers the target speaker voice activity detection (TSVAD) states of the mixture, as well as gets different speakers' single-talker audio segments as the reference speech. The latter one employs both the mixed audio and reference speech as inputs, and then it generates an estimated mask. By exploiting the TSVAD decision and the estimated mask, our SD-MTSS model can extract the speech of each speaker concurrently in a conversion recording without additional enrollment audio in advance.Experimental results show that our MTSS model outperforms our baselines with a large margin, achieving 1.38dB SDR, 1.34dB SI-SNR, and 0.13 PESQ improvements over the state-of-the-art SpEx+ baseline on the WSJ0-2mix-extr dataset, respectively. The SD-MTSS system makes a significant improvement than the baseline on the Alimeeting dataset as well.