 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Dec 20, 2022
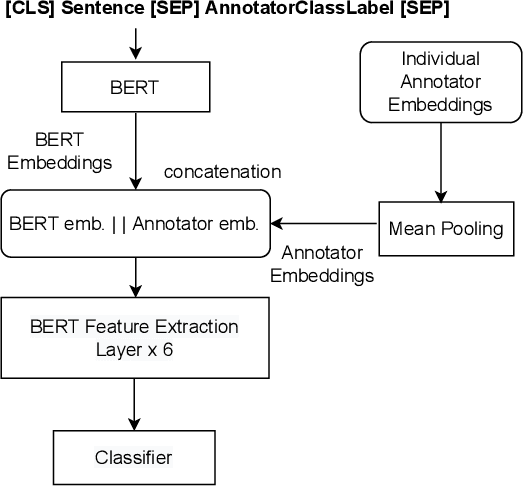

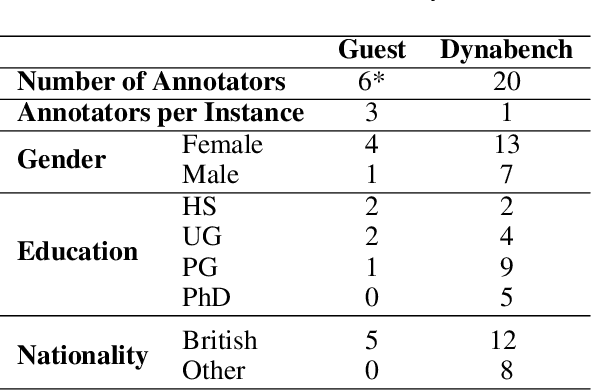
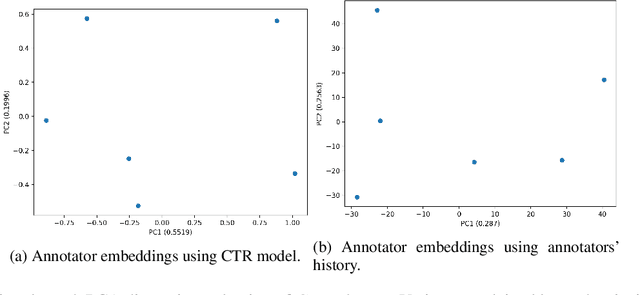
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Competitive and Resource Efficient Factored Hybrid HMM Systems are Simpler Than You Think
Jun 15, 2023
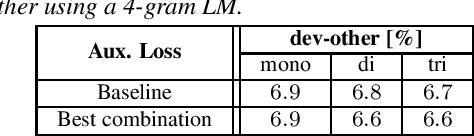

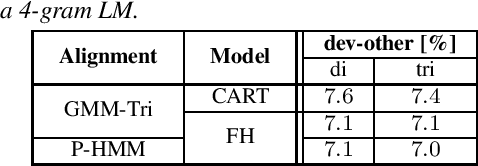
Building competitive hybrid hidden Markov model~(HMM) systems for automatic speech recognition~(ASR) requires a complex multi-stage pipeline consisting of several training criteria. The recent sequence-to-sequence models offer the advantage of having simpler pipelines that can start from-scratch. We propose a purely neural based single-stage from-scratch pipeline for a context-dependent hybrid HMM that offers similar simplicity. We use an alignment from a full-sum trained zero-order posterior HMM with a BLSTM encoder. We show that with this alignment we can build a Conformer factored hybrid that performs even better than both a state-of-the-art classic hybrid and a factored hybrid trained with alignments taken from more complex Gaussian mixture based systems. Our finding is confirmed on Switchboard 300h and LibriSpeech 960h tasks with comparable results to other approaches in the literature, and by additionally relying on a responsible choice of available computational resources.
Requirements for Explainability and Acceptance of Artificial Intelligence in Collaborative Work
Jun 27, 2023
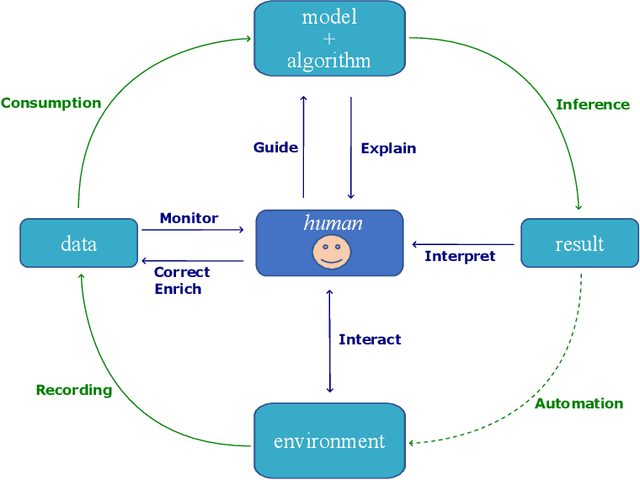
The increasing prevalence of Artificial Intelligence (AI) in safety-critical contexts such as air-traffic control leads to systems that are practical and efficient, and to some extent explainable to humans to be trusted and accepted. The present structured literature analysis examines n = 236 articles on the requirements for the explainability and acceptance of AI. Results include a comprehensive review of n = 48 articles on information people need to perceive an AI as explainable, the information needed to accept an AI, and representation and interaction methods promoting trust in an AI. Results indicate that the two main groups of users are developers who require information about the internal operations of the model and end users who require information about AI results or behavior. Users' information needs vary in specificity, complexity, and urgency and must consider context, domain knowledge, and the user's cognitive resources. The acceptance of AI systems depends on information about the system's functions and performance, privacy and ethical considerations, as well as goal-supporting information tailored to individual preferences and information to establish trust in the system. Information about the system's limitations and potential failures can increase acceptance and trust. Trusted interaction methods are human-like, including natural language, speech, text, and visual representations such as graphs, charts, and animations. Our results have significant implications for future human-centric AI systems being developed. Thus, they are suitable as input for further application-specific investigations of user needs.
Whisper-KDQ: A Lightweight Whisper via Guided Knowledge Distillation and Quantization for Efficient ASR
May 18, 2023
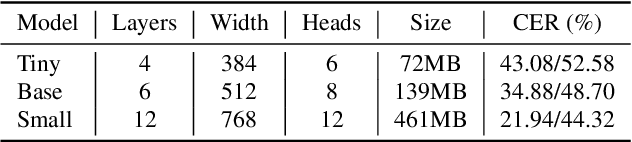
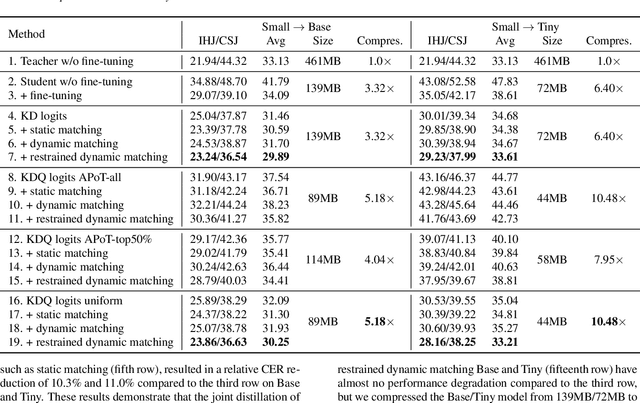
Due to the rapid development of computing hardware resources and the dramatic growth of data, pre-trained models in speech recognition, such as Whisper, have significantly improved the performance of speech recognition tasks. However, these models usually have a high computational overhead, making it difficult to execute effectively on resource-constrained devices. To speed up inference and reduce model size while maintaining performance, we propose a novel guided knowledge distillation and quantization for large pre-trained model Whisper. The student model selects distillation and quantization layers based on quantization loss and distillation loss, respectively. We compressed $\text{Whisper}_\text{small}$ to $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$ levels, making $\text{Whisper}_\text{small}$ 5.18x/10.48x smaller, respectively. Moreover, compared to the original $\text{Whisper}_\text{base}$ and $\text{Whisper}_\text{tiny}$, there is also a relative character error rate~(CER) reduction of 11.3% and 14.0% for the new compressed model respectively.
On Batching Variable Size Inputs for Training End-to-End Speech Enhancement Systems
Jan 25, 2023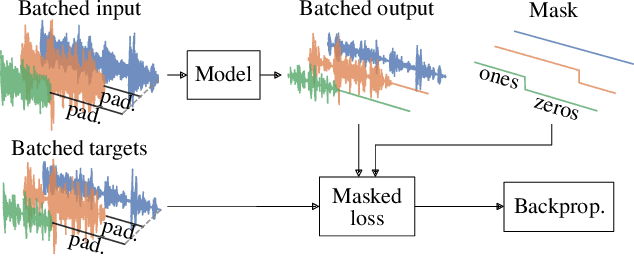
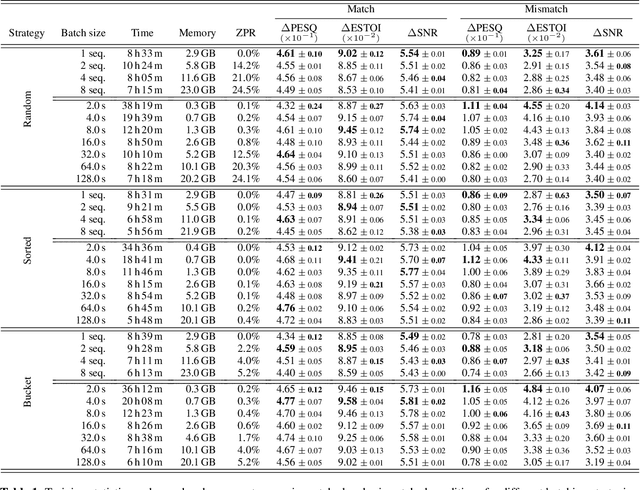
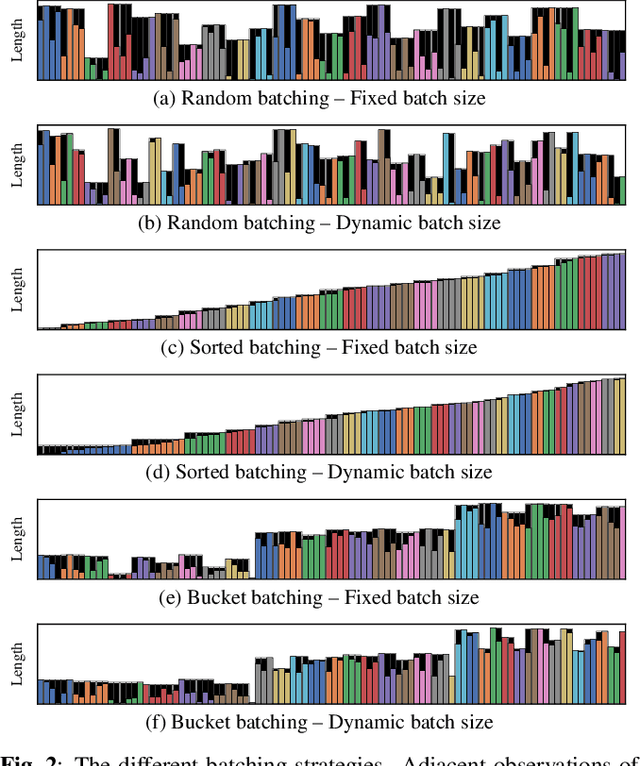
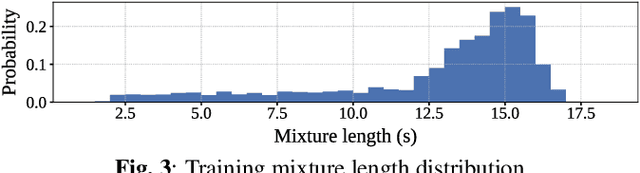
The performance of neural network-based speech enhancement systems is primarily influenced by the model architecture, whereas training times and computational resource utilization are primarily affected by training parameters such as the batch size. Since noisy and reverberant speech mixtures can have different duration, a batching strategy is required to handle variable size inputs during training, in particular for state-of-the-art end-to-end systems. Such strategies usually strive a compromise between zero-padding and data randomization, and can be combined with a dynamic batch size for a more consistent amount of data in each batch. However, the effect of these practices on resource utilization and more importantly network performance is not well documented. This paper is an empirical study of the effect of different batching strategies and batch sizes on the training statistics and speech enhancement performance of a Conv-TasNet, evaluated in both matched and mismatched conditions. We find that using a small batch size during training improves performance in both conditions for all batching strategies. Moreover, using sorted or bucket batching with a dynamic batch size allows for reduced training time and GPU memory usage while achieving similar performance compared to random batching with a fixed batch size.
Gaussian-smoothed Imbalance Data Improves Speech Emotion Recognition
Feb 17, 2023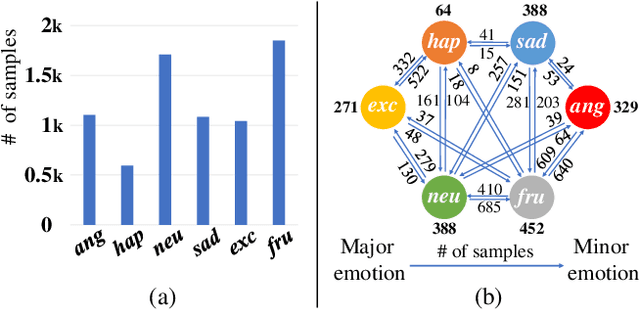
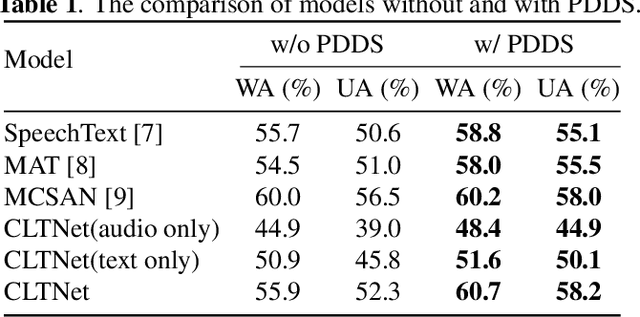
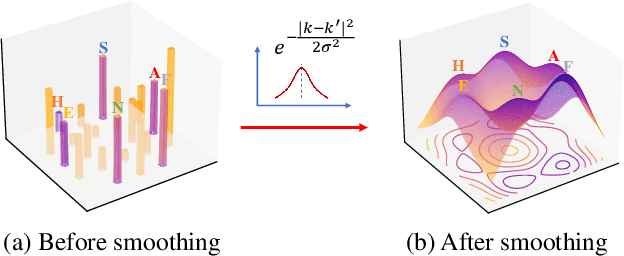

In speech emotion recognition tasks, models learn emotional representations from datasets. We find the data distribution in the IEMOCAP dataset is very imbalanced, which may harm models to learn a better representation. To address this issue, we propose a novel Pairwise-emotion Data Distribution Smoothing (PDDS) method. PDDS considers that the distribution of emotional data should be smooth in reality, then applies Gaussian smoothing to emotion-pairs for constructing a new training set with a smoother distribution. The required new data are complemented using the mixup augmentation. As PDDS is model and modality agnostic, it is evaluated with three SOTA models on the IEMOCAP dataset. The experimental results show that these models are improved by 0.2\% - 4.8\% and 1.5\% - 5.9\% in terms of WA and UA. In addition, an ablation study demonstrates that the key advantage of PDDS is the reasonable data distribution rather than a simple data augmentation.
Findings of the VarDial Evaluation Campaign 2023
May 31, 2023

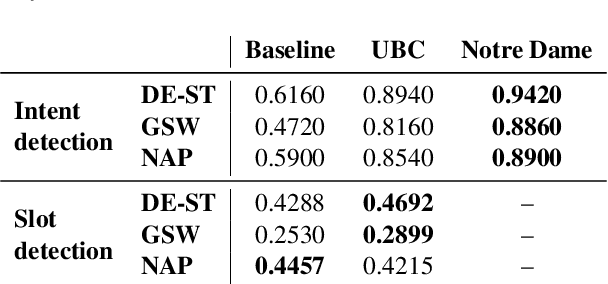

This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2023. The campaign is part of the tenth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with EACL 2023. Three separate shared tasks were included this year: Slot and intent detection for low-resource language varieties (SID4LR), Discriminating Between Similar Languages -- True Labels (DSL-TL), and Discriminating Between Similar Languages -- Speech (DSL-S). All three tasks were organized for the first time this year.
Evaluating OpenAI's Whisper ASR for Punctuation Prediction and Topic Modeling of life histories of the Museum of the Person
May 26, 2023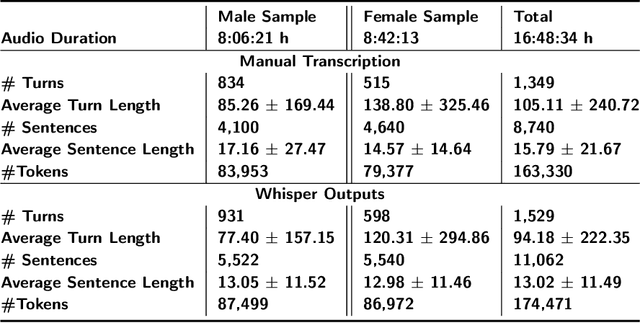
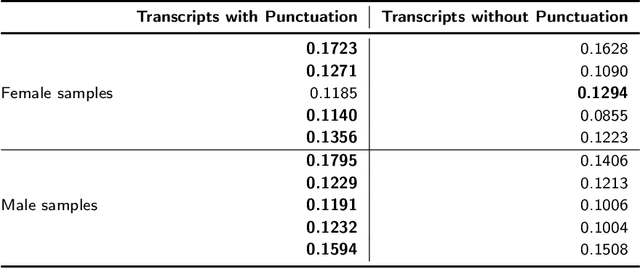
Automatic speech recognition (ASR) systems play a key role in applications involving human-machine interactions. Despite their importance, ASR models for the Portuguese language proposed in the last decade have limitations in relation to the correct identification of punctuation marks in automatic transcriptions, which hinder the use of transcriptions by other systems, models, and even by humans. However, recently Whisper ASR was proposed by OpenAI, a general-purpose speech recognition model that has generated great expectations in dealing with such limitations. This chapter presents the first study on the performance of Whisper for punctuation prediction in the Portuguese language. We present an experimental evaluation considering both theoretical aspects involving pausing points (comma) and complete ideas (exclamation, question, and fullstop), as well as practical aspects involving transcript-based topic modeling - an application dependent on punctuation marks for promising performance. We analyzed experimental results from videos of Museum of the Person, a virtual museum that aims to tell and preserve people's life histories, thus discussing the pros and cons of Whisper in a real-world scenario. Although our experiments indicate that Whisper achieves state-of-the-art results, we conclude that some punctuation marks require improvements, such as exclamation, semicolon and colon.
Expressive Speech-driven Facial Animation with controllable emotions
Jan 05, 2023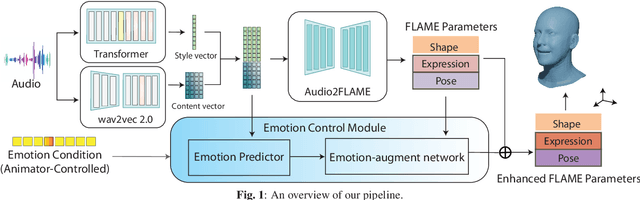

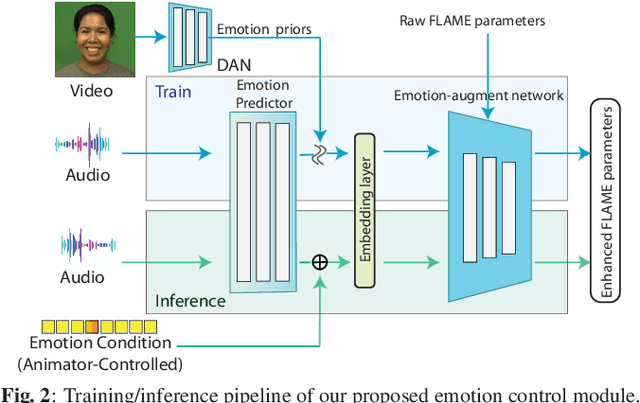
It is in high demand to generate facial animation with high realism, but it remains a challenging task. Existing approaches of speech-driven facial animation can produce satisfactory mouth movement and lip synchronization, but show weakness in dramatic emotional expressions and flexibility in emotion control. This paper presents a novel deep learning-based approach for expressive facial animation generation from speech that can exhibit wide-spectrum facial expressions with controllable emotion type and intensity. We propose an emotion controller module to learn the relationship between the emotion variations (e.g., types and intensity) and the corresponding facial expression parameters. It enables emotion-controllable facial animation, where the target expression can be continuously adjusted as desired. The qualitative and quantitative evaluations show that the animation generated by our method is rich in facial emotional expressiveness while retaining accurate lip movement, outperforming other state-of-the-art methods.
L2 proficiency assessment using self-supervised speech representations
Nov 16, 2022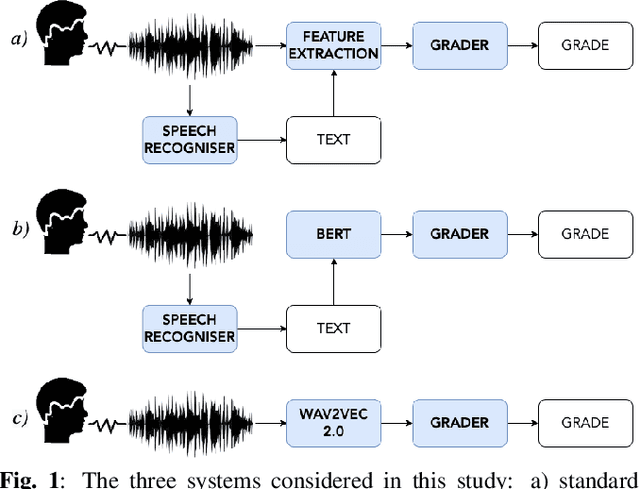
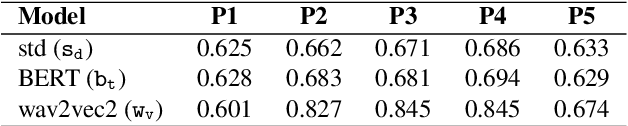
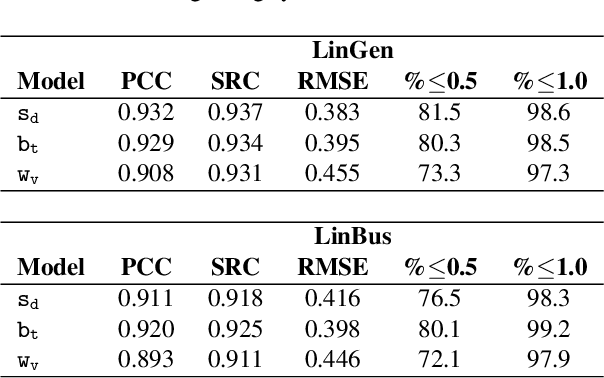
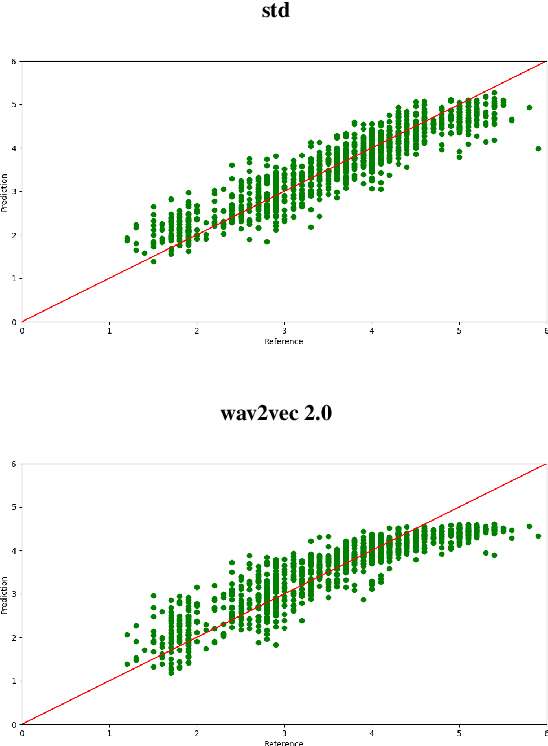
There has been a growing demand for automated spoken language assessment systems in recent years. A standard pipeline for this process is to start with a speech recognition system and derive features, either hand-crafted or based on deep-learning, that exploit the transcription and audio. Though these approaches can yield high performance systems, they require speech recognition systems that can be used for L2 speakers, and preferably tuned to the specific form of test being deployed. Recently a self-supervised speech representation based scheme, requiring no speech recognition, was proposed. This work extends the initial analysis conducted on this approach to a large scale proficiency test, Linguaskill, that comprises multiple parts, each designed to assess different attributes of a candidate's speaking proficiency. The performance of the self-supervised, wav2vec 2.0, system is compared to a high performance hand-crafted assessment system and a BERT-based text system both of which use speech transcriptions. Though the wav2vec 2.0 based system is found to be sensitive to the nature of the response, it can be configured to yield comparable performance to systems requiring a speech transcription, and yields gains when appropriately combined with standard approaches.