 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
MP-SENet: A Speech Enhancement Model with Parallel Denoising of Magnitude and Phase Spectra
May 23, 2023
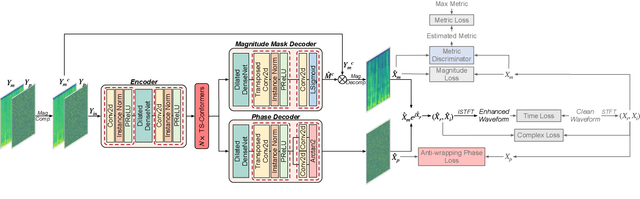
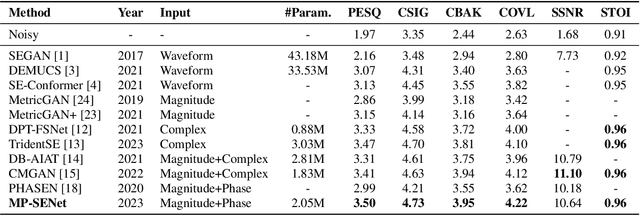
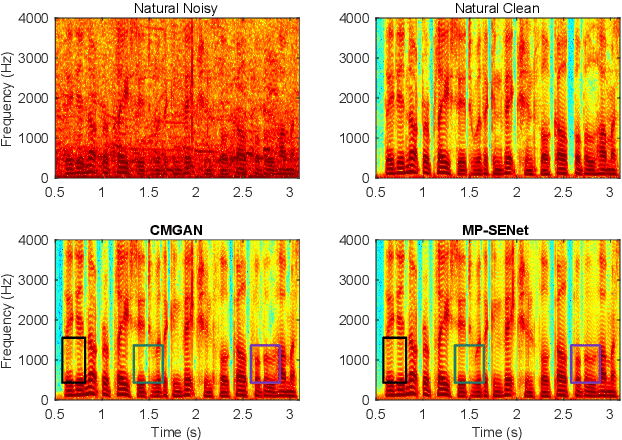
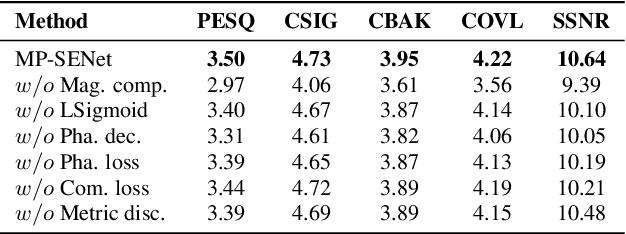
This paper proposes MP-SENet, a novel Speech Enhancement Network which directly denoises Magnitude and Phase spectra in parallel. The proposed MP-SENet adopts a codec architecture in which the encoder and decoder are bridged by convolution-augmented transformers. The encoder aims to encode time-frequency representations from the input noisy magnitude and phase spectra. The decoder is composed of parallel magnitude mask decoder and phase decoder, directly recovering clean magnitude spectra and clean-wrapped phase spectra by incorporating learnable sigmoid activation and parallel phase estimation architecture, respectively. Multi-level losses defined on magnitude spectra, phase spectra, short-time complex spectra, and time-domain waveforms are used to train the MP-SENet model jointly. Experimental results show that our proposed MP-SENet achieves a PESQ of 3.50 on the public VoiceBank+DEMAND dataset and outperforms existing advanced speech enhancement methods.
Speaker-independent Speech Inversion for Estimation of Nasalance
May 31, 2023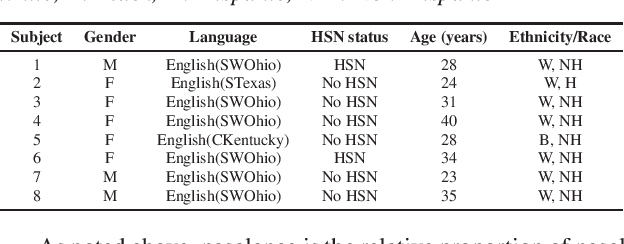

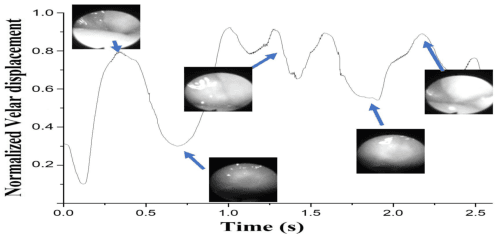

The velopharyngeal (VP) valve regulates the opening between the nasal and oral cavities. This valve opens and closes through a coordinated motion of the velum and pharyngeal walls. Nasalance is an objective measure derived from the oral and nasal acoustic signals that correlate with nasality. In this work, we evaluate the degree to which the nasalance measure reflects fine-grained patterns of VP movement by comparison with simultaneously collected direct measures of VP opening using high-speed nasopharyngoscopy (HSN). We show that nasalance is significantly correlated with the HSN signal, and that both match expected patterns of nasality. We then train a temporal convolution-based speech inversion system in a speaker-independent fashion to estimate VP movement for nasality, using nasalance as the ground truth. In further experiments, we also show the importance of incorporating source features (from glottal activity) to improve nasality prediction.
Home monitoring for frailty detection through sound and speaker diarization analysis
Aug 17, 2023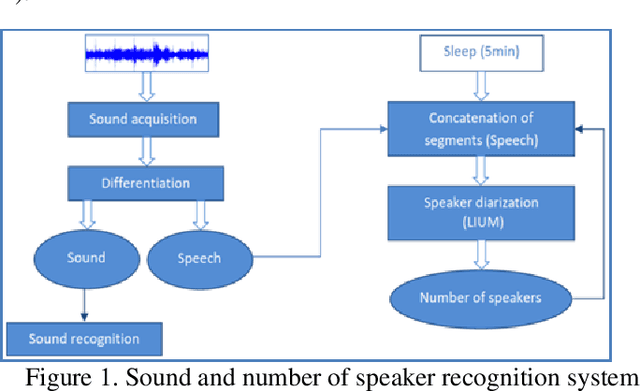
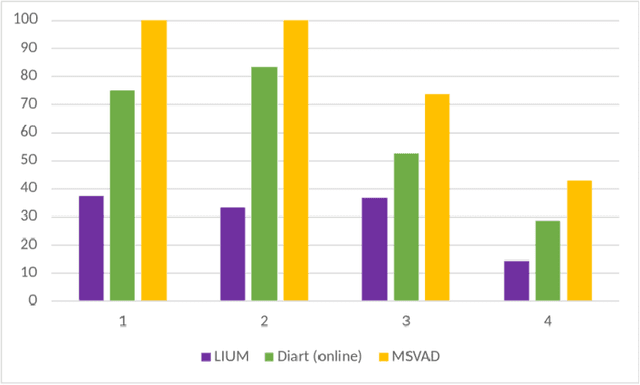
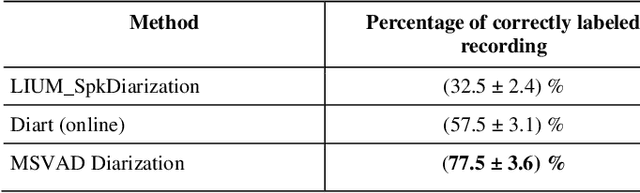
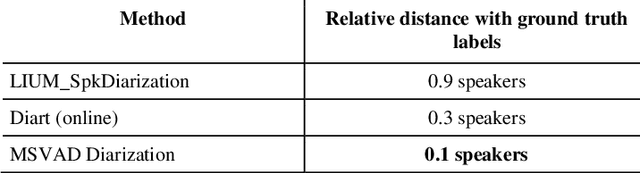
As the French, European and worldwide populations are aging, there is a strong interest for new systems that guarantee a reliable and privacy preserving home monitoring for frailty prevention. This work is a part of a global environmental audio analysis system which aims to help identification of Activities of Daily Life (ADL) through human and everyday life sounds recognition, speech presence and number of speakers detection. The focus is made on the number of speakers detection. In this article, we present how recent advances in sound processing and speaker diarization can improve the existing embedded systems. We study the performances of two new methods and discuss the benefits of DNN based approaches which improve performances by about 100%.
UNSSOR: Unsupervised Neural Speech Separation by Leveraging Over-determined Training Mixtures
May 31, 2023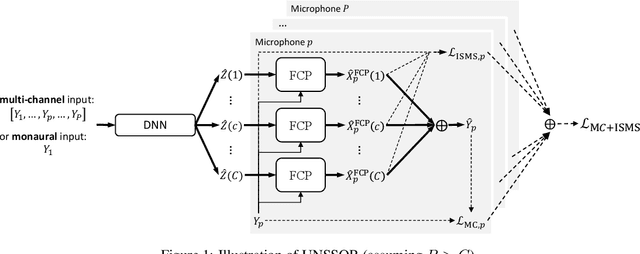
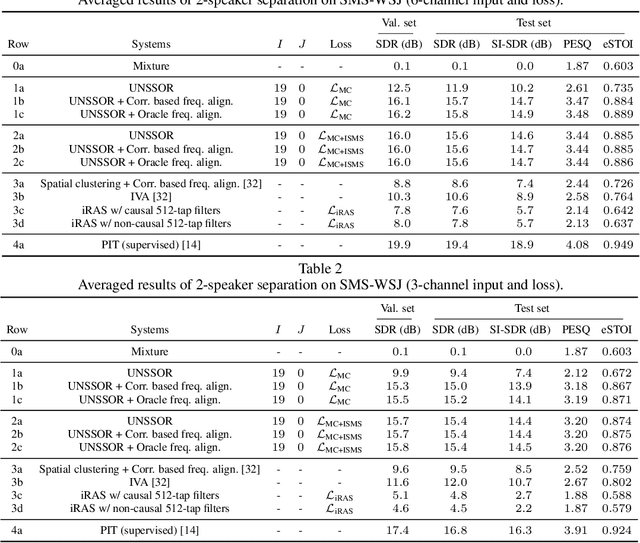
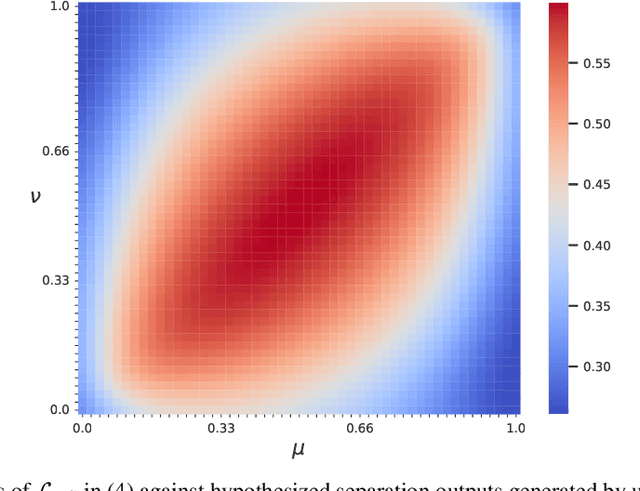
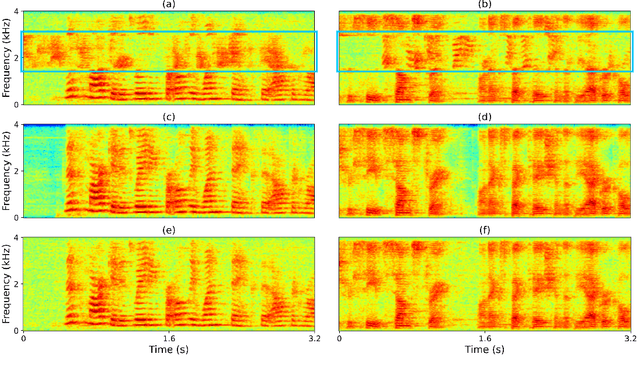
In reverberant conditions with multiple concurrent speakers, each microphone acquires a mixture signal of multiple speakers at a different location. In over-determined conditions where the microphones out-number speakers, we can narrow down the solutions to speaker images and realize unsupervised speech separation by leveraging each mixture signal as a constraint (i.e., the estimated speaker images at a microphone should add up to the mixture). Equipped with this insight, we propose UNSSOR, an algorithm for $\textbf{u}$nsupervised $\textbf{n}$eural $\textbf{s}$peech $\textbf{s}$eparation by leveraging $\textbf{o}$ver-determined training mixtu$\textbf{r}$es. At each training step, we feed an input mixture to a deep neural network (DNN) to produce an intermediate estimate for each speaker, linearly filter the estimates, and optimize a loss so that, at each microphone, the filtered estimates of all the speakers can add up to the mixture to satisfy the above constraint. We show that this loss can promote unsupervised separation of speakers. The linear filters are computed in each sub-band based on the mixture and DNN estimates through the forward convolutive prediction (FCP) algorithm. To address the frequency permutation problem incurred by using sub-band FCP, a loss term based on minimizing intra-source magnitude scattering is proposed. Although UNSSOR requires over-determined training mixtures, we can train DNNs to achieve under-determined separation (e.g., unsupervised monaural speech separation). Evaluation results on two-speaker separation in reverberant conditions show the effectiveness and potential of UNSSOR.
SGEM: Test-Time Adaptation for Automatic Speech Recognition via Sequential-Level Generalized Entropy Minimization
Jun 21, 2023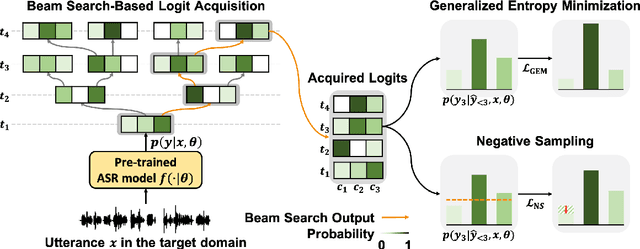
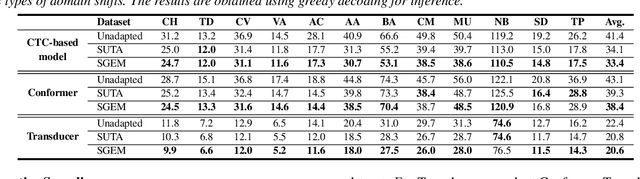

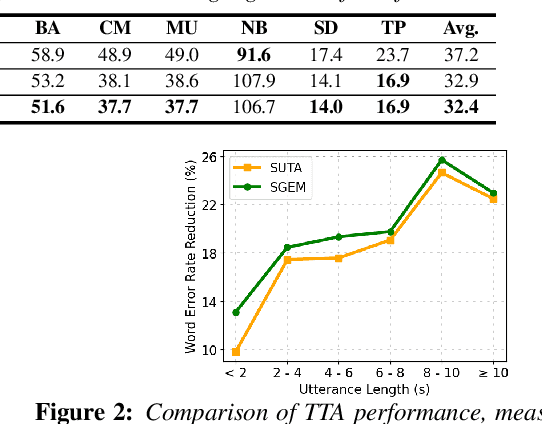
Automatic speech recognition (ASR) models are frequently exposed to data distribution shifts in many real-world scenarios, leading to erroneous predictions. To tackle this issue, an existing test-time adaptation (TTA) method has recently been proposed to adapt the pre-trained ASR model on unlabeled test instances without source data. Despite decent performance gain, this work relies solely on naive greedy decoding and performs adaptation across timesteps at a frame level, which may not be optimal given the sequential nature of the model output. Motivated by this, we propose a novel TTA framework, dubbed SGEM, for general ASR models. To treat the sequential output, SGEM first exploits beam search to explore candidate output logits and selects the most plausible one. Then, it utilizes generalized entropy minimization and negative sampling as unsupervised objectives to adapt the model. SGEM achieves state-of-the-art performance for three mainstream ASR models under various domain shifts.
An analysis on the effects of speaker embedding choice in non auto-regressive TTS
Jul 19, 2023
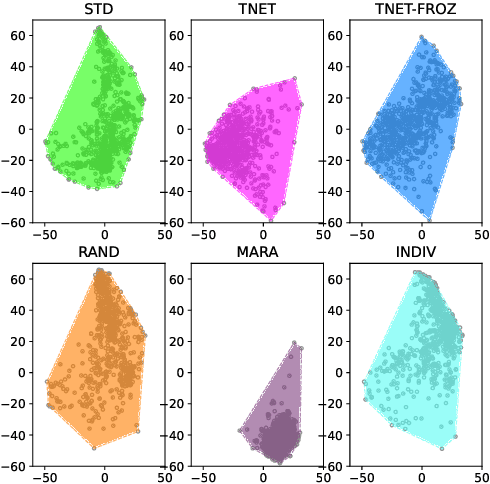
In this paper we introduce a first attempt on understanding how a non-autoregressive factorised multi-speaker speech synthesis architecture exploits the information present in different speaker embedding sets. We analyse if jointly learning the representations, and initialising them from pretrained models determine any quality improvements for target speaker identities. In a separate analysis, we investigate how the different sets of embeddings impact the network's core speech abstraction (i.e. zero conditioned) in terms of speaker identity and representation learning. We show that, regardless of the used set of embeddings and learning strategy, the network can handle various speaker identities equally well, with barely noticeable variations in speech output quality, and that speaker leakage within the core structure of the synthesis system is inevitable in the standard training procedures adopted thus far.
MuAViC: A Multilingual Audio-Visual Corpus for Robust Speech Recognition and Robust Speech-to-Text Translation
Mar 07, 2023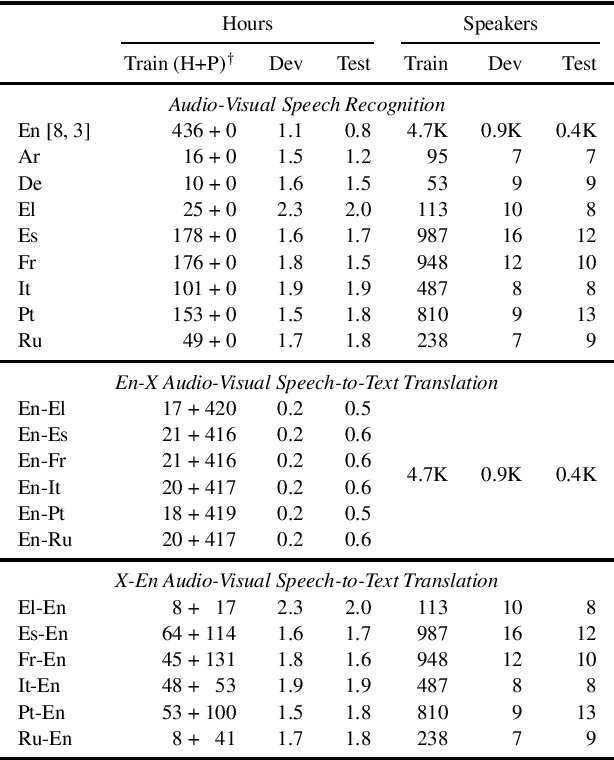
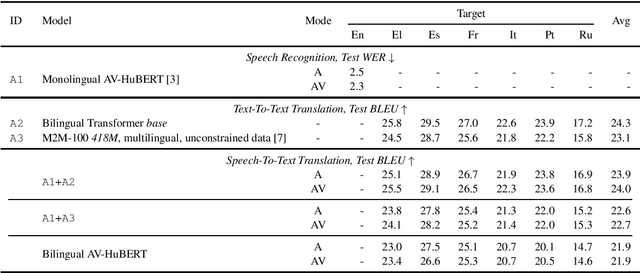

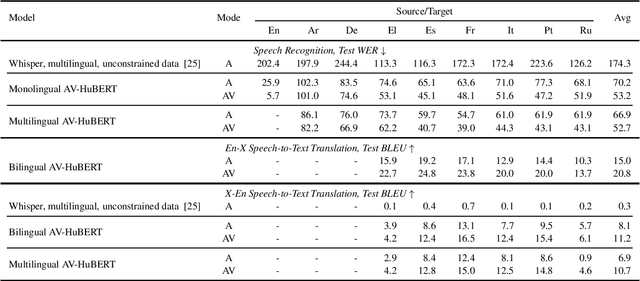
We introduce MuAViC, a multilingual audio-visual corpus for robust speech recognition and robust speech-to-text translation providing 1200 hours of audio-visual speech in 9 languages. It is fully transcribed and covers 6 English-to-X translation as well as 6 X-to-English translation directions. To the best of our knowledge, this is the first open benchmark for audio-visual speech-to-text translation and the largest open benchmark for multilingual audio-visual speech recognition. Our baseline results show that MuAViC is effective for building noise-robust speech recognition and translation models. We make the corpus available at https://github.com/facebookresearch/muavic.
TorchAudio-Squim: Reference-less Speech Quality and Intelligibility measures in TorchAudio
Apr 04, 2023
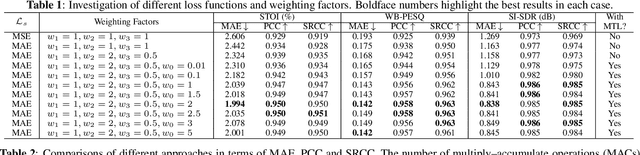

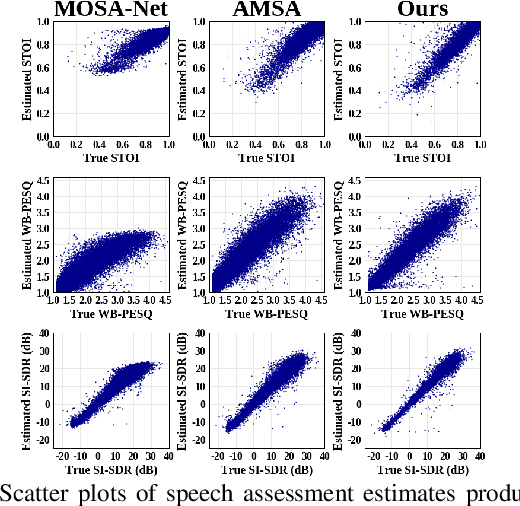
Measuring quality and intelligibility of a speech signal is usually a critical step in development of speech processing systems. To enable this, a variety of metrics to measure quality and intelligibility under different assumptions have been developed. Through this paper, we introduce tools and a set of models to estimate such known metrics using deep neural networks. These models are made available in the well-established TorchAudio library, the core audio and speech processing library within the PyTorch deep learning framework. We refer to it as TorchAudio-Squim, TorchAudio-Speech QUality and Intelligibility Measures. More specifically, in the current version of TorchAudio-squim, we establish and release models for estimating PESQ, STOI and SI-SDR among objective metrics and MOS among subjective metrics. We develop a novel approach for objective metric estimation and use a recently developed approach for subjective metric estimation. These models operate in a ``reference-less" manner, that is they do not require the corresponding clean speech as reference for speech assessment. Given the unavailability of clean speech and the effortful process of subjective evaluation in real-world situations, such easy-to-use tools would greatly benefit speech processing research and development.
From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Aug 02, 2023Deep generative models can generate high-fidelity audio conditioned on various types of representations (e.g., mel-spectrograms, Mel-frequency Cepstral Coefficients (MFCC)). Recently, such models have been used to synthesize audio waveforms conditioned on highly compressed representations. Although such methods produce impressive results, they are prone to generate audible artifacts when the conditioning is flawed or imperfect. An alternative modeling approach is to use diffusion models. However, these have mainly been used as speech vocoders (i.e., conditioned on mel-spectrograms) or generating relatively low sampling rate signals. In this work, we propose a high-fidelity multi-band diffusion-based framework that generates any type of audio modality (e.g., speech, music, environmental sounds) from low-bitrate discrete representations. At equal bit rate, the proposed approach outperforms state-of-the-art generative techniques in terms of perceptual quality. Training and, evaluation code, along with audio samples, are available on the facebookresearch/audiocraft Github page.
FonMTL: Towards Multitask Learning for the Fon Language
Aug 28, 2023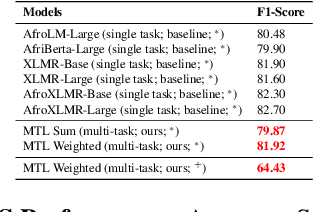
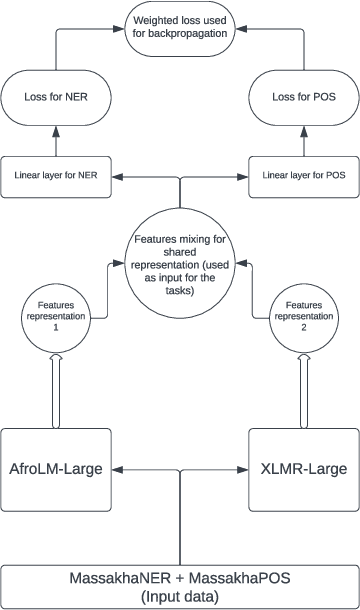
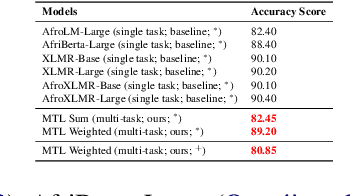
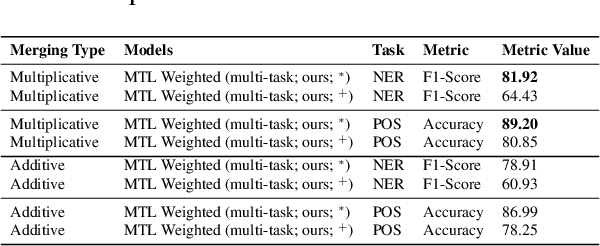
The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.