 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Framework for the Assessment of the Schizophrenia Spectrum
Jun 14, 2024This paper presents a novel multimodal framework to distinguish between different symptom classes of subjects in the schizophrenia spectrum and healthy controls using audio, video, and text modalities. We implemented Convolution Neural Network and Long Short Term Memory based unimodal models and experimented on various multimodal fusion approaches to come up with the proposed framework. We utilized a minimal Gated multimodal unit (mGMU) to obtain a bi-modal intermediate fusion of the features extracted from the input modalities before finally fusing the outputs of the bimodal fusions to perform subject-wise classifications. The use of mGMU units in the multimodal framework improved the performance in both weighted f1-score and weighted AUC-ROC scores.
Accent Conversion with Articulatory Representations
Jun 10, 2024



Conversion of non-native accented speech to native (American) English has a wide range of applications such as improving intelligibility of non-native speech. Previous work on this domain has used phonetic posteriograms as the target speech representation to train an acoustic model which is then used to extract a compact representation of input speech for accent conversion. In this work, we introduce the idea of using an effective articulatory speech representation, extracted from an acoustic-to-articulatory speech inversion system, to improve the acoustic model used in accent conversion. The idea to incorporate articulatory representations originates from their ability to well characterize accents in speech. To incorporate articulatory representations with conventional phonetic posteriograms, a multi-task learning based acoustic model is proposed. Objective and subjective evaluations show that the use of articulatory representations can improve the effectiveness of accent conversion.
A multi-modal approach for identifying schizophrenia using cross-modal attention
Sep 26, 2023This study focuses on how different modalities of human communication can be used to distinguish between healthy controls and subjects with schizophrenia who exhibit strong positive symptoms. We developed a multi-modal schizophrenia classification system using audio, video, and text. Facial action units and vocal tract variables were extracted as low-level features from video and audio respectively, which were then used to compute high-level coordination features that served as the inputs to the audio and video modalities. Context-independent text embeddings extracted from transcriptions of speech were used as the input for the text modality. The multi-modal system is developed by fusing a segment-to-session-level classifier for video and audio modalities with a text model based on a Hierarchical Attention Network (HAN) with cross-modal attention. The proposed multi-modal system outperforms the previous state-of-the-art multi-modal system by 8.53% in the weighted average F1 score.
Improving Speech Inversion Through Self-Supervised Embeddings and Enhanced Tract Variables
Sep 17, 2023



The performance of deep learning models depends significantly on their capacity to encode input features efficiently and decode them into meaningful outputs. Better input and output representation has the potential to boost models' performance and generalization. In the context of acoustic-to-articulatory speech inversion (SI) systems, we study the impact of utilizing speech representations acquired via self-supervised learning (SSL) models, such as HuBERT compared to conventional acoustic features. Additionally, we investigate the incorporation of novel tract variables (TVs) through an improved geometric transformation model. By combining these two approaches, we improve the Pearson product-moment correlation (PPMC) scores which evaluate the accuracy of TV estimation of the SI system from 0.7452 to 0.8141, a 6.9% increase. Our findings underscore the profound influence of rich feature representations from SSL models and improved geometric transformations with target TVs on the enhanced functionality of SI systems.
Speaker-independent Speech Inversion for Estimation of Nasalance
May 31, 2023



The velopharyngeal (VP) valve regulates the opening between the nasal and oral cavities. This valve opens and closes through a coordinated motion of the velum and pharyngeal walls. Nasalance is an objective measure derived from the oral and nasal acoustic signals that correlate with nasality. In this work, we evaluate the degree to which the nasalance measure reflects fine-grained patterns of VP movement by comparison with simultaneously collected direct measures of VP opening using high-speed nasopharyngoscopy (HSN). We show that nasalance is significantly correlated with the HSN signal, and that both match expected patterns of nasality. We then train a temporal convolution-based speech inversion system in a speaker-independent fashion to estimate VP movement for nasality, using nasalance as the ground truth. In further experiments, we also show the importance of incorporating source features (from glottal activity) to improve nasality prediction.
The Secret Source : Incorporating Source Features to Improve Acoustic-to-Articulatory Speech Inversion
Oct 29, 2022



In this work, we incorporated acoustically derived source features, aperiodicity, periodicity and pitch as additional targets to an acoustic-to-articulatory speech inversion (SI) system. We also propose a Temporal Convolution based SI system, which uses auditory spectrograms as the input speech representation, to learn long-range dependencies and complex interactions between the source and vocal tract, to improve the SI task. The experiments are conducted with both the Wisconsin X-ray microbeam (XRMB) and Haskins Production Rate Comparison (HPRC) datasets, with comparisons done with respect to three baseline SI model architectures. The proposed SI system with the HPRC dataset gains an improvement of close to 28% when the source features are used as additional targets. The same SI system outperforms the current best performing SI models by around 9% on the XRMB dataset.
Learning to Compute the Articulatory Representations of Speech with the MIRRORNET
Oct 29, 2022



Most organisms including humans function by coordinating and integrating sensory signals with motor actions to survive and accomplish desired tasks. Learning these complex sensorimotor mappings proceeds simultaneously and often in an unsupervised or semi-supervised fashion. An autoencoder architecture (MirrorNet) inspired by this sensorimotor learning paradigm is explored in this work to learn how to control an articulatory synthesizer. The synthesizer takes as input control signals consisting of six vocal Tract Variables (TVs) and source features (voicing indicators and pitch), and generates the corresponding auditory spectrograms. Due to the non-linear structure of the synthesizer, the control parameters that produce a target speech signal are not readily computable nor are they always unique. Here we demonstrate how to initialize the MirrorNet learning so as to produce a meaningful range of articulatory values. Once trained, the MirrorNet successfully estimates the TVs and source features needed to synthesize any arbitrary speech utterance. This approach outperforms the best previously designed `speech inversion' systems on the Wisconsin X-ray microbeam (XRMB) dataset.
Acoustic-to-articulatory Speech Inversion with Multi-task Learning
May 27, 2022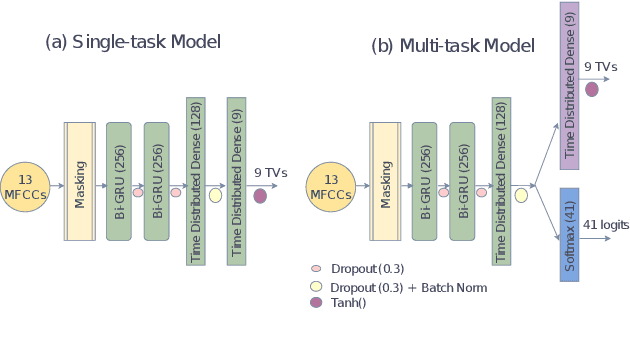


Multi-task learning (MTL) frameworks have proven to be effective in diverse speech related tasks like automatic speech recognition (ASR) and speech emotion recognition. This paper proposes a MTL framework to perform acoustic-to-articulatory speech inversion by simultaneously learning an acoustic to phoneme mapping as a shared task. We use the Haskins Production Rate Comparison (HPRC) database which has both the electromagnetic articulography (EMA) data and the corresponding phonetic transcriptions. Performance of the system was measured by computing the correlation between estimated and actual tract variables (TVs) from the acoustic to articulatory speech inversion task. The proposed MTL based Bidirectional Gated Recurrent Neural Network (RNN) model learns to map the input acoustic features to nine TVs while outperforming the baseline model trained to perform only acoustic to articulatory inversion.
Audio Data Augmentation for Acoustic-to-articulatory Speech Inversion using Bidirectional Gated RNNs
May 25, 2022
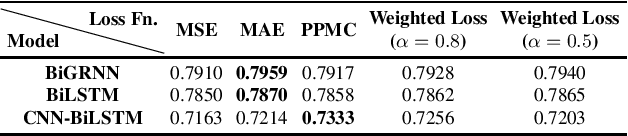
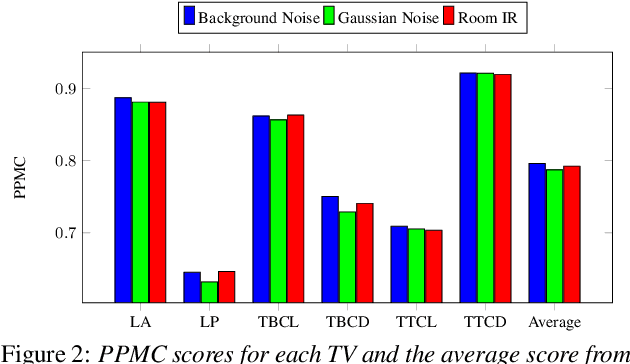
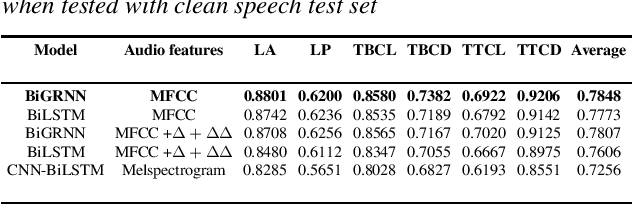
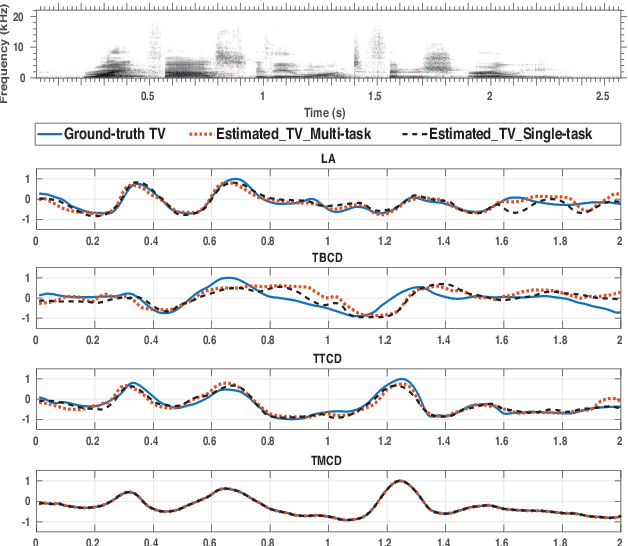
Data augmentation has proven to be a promising prospect in improving the performance of deep learning models by adding variability to training data. In previous work with developing a noise robust acoustic-to-articulatory speech inversion system, we have shown the importance of noise augmentation to improve the performance of speech inversion in noisy speech. In this work, we compare and contrast different ways of doing data augmentation and show how this technique improves the performance of articulatory speech inversion not only on noisy speech, but also on clean speech data. We also propose a Bidirectional Gated Recurrent Neural Network as the speech inversion system instead of the previously used feed forward neural network. The inversion system uses mel-frequency cepstral coefficients (MFCCs) as the input acoustic features and six vocal tract-variables (TVs) as the output articulatory features. The Performance of the system was measured by computing the correlation between estimated and actual TVs on the U. Wisc. X-ray Microbeam database. The proposed speech inversion system shows a 5% relative improvement in correlation over the baseline noise robust system for clean speech data. The pre-trained model, when adapted to each unseen speaker in the test set, improves the average correlation by another 6%.
The Mirrornet : Learning Audio Synthesizer Controls Inspired by Sensorimotor Interaction
Oct 18, 2021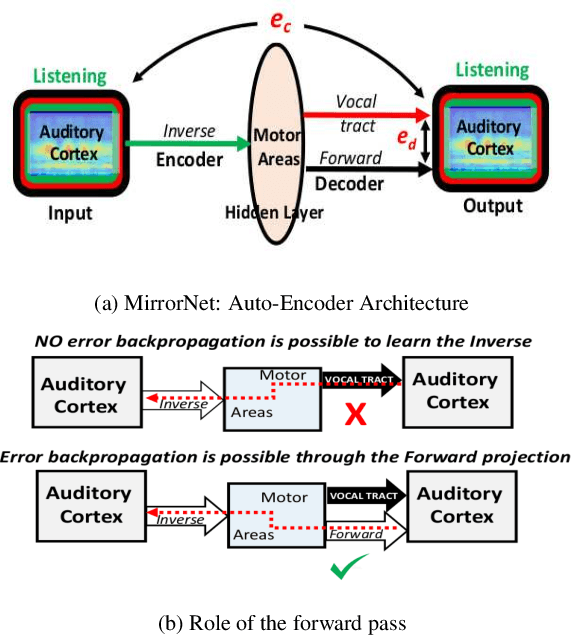
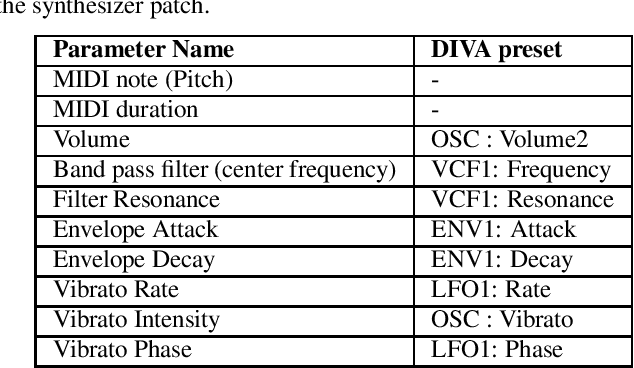
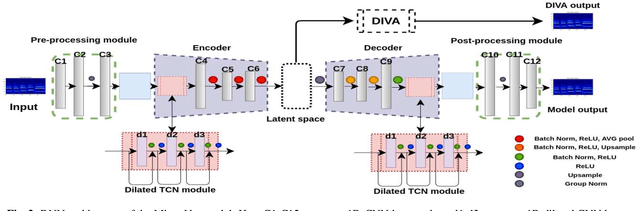
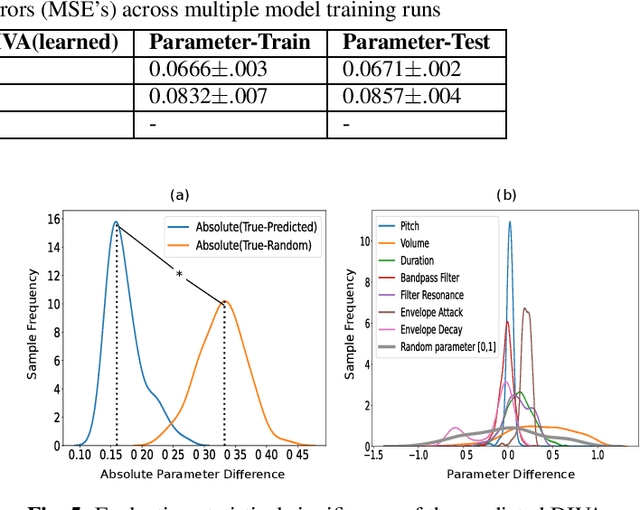
Experiments to understand the sensorimotor neural interactions in the human cortical speech system support the existence of a bidirectional flow of interactions between the auditory and motor regions. Their key function is to enable the brain to 'learn' how to control the vocal tract for speech production. This idea is the impetus for the recently proposed "MirrorNet", a constrained autoencoder architecture. In this paper, the MirrorNet is applied to learn, in an unsupervised manner, the controls of a specific audio synthesizer (DIVA) to produce melodies only from their auditory spectrograms. The results demonstrate how the MirrorNet discovers the synthesizer parameters to generate the melodies that closely resemble the original and those of unseen melodies, and even determine the best set parameters to approximate renditions of complex piano melodies generated by a different synthesizer. This generalizability of the MirrorNet illustrates its potential to discover from sensory data the controls of arbitrary motor-plants such as autonomous vehicles.