 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Watermarking of Audio Generative Models
Sep 04, 2024



The advancements in audio generative models have opened up new challenges in their responsible disclosure and the detection of their misuse. In response, we introduce a method to watermark latent generative models by a specific watermarking of their training data. The resulting watermarked models produce latent representations whose decoded outputs are detected with high confidence, regardless of the decoding method used. This approach enables the detection of the generated content without the need for a post-hoc watermarking step. It provides a more secure solution for open-sourced models and facilitates the identification of derivative works that fine-tune or use these models without adhering to their license terms. Our results indicate for instance that generated outputs are detected with an accuracy of more than 75% at a false positive rate of $10^{-3}$, even after fine-tuning the latent generative model.
Fully Reversing the Shoebox Image Source Method: From Impulse Responses to Room Parameters
May 06, 2024We present an algorithm that fully reverses the shoebox image source method (ISM), a popular and widely used room impulse response (RIR) simulator for cuboid rooms introduced by Allen and Berkley in 1979. More precisely, given a discrete multichannel RIR generated by the shoebox ISM for a microphone array of known geometry, the algorithm reliably recovers the 18 input parameters. These are the 3D source position, the 3 dimensions of the room, the 6-degrees-of-freedom room translation and orientation, and an absorption coefficient for each of the 6 room boundaries. The approach builds on a recently proposed gridless image source localization technique combined with new procedures for room axes recovery and first-order-reflection identification. Extensive simulated experiments reveal that near-exact recovery of all parameters is achieved for a 32-element, 8.4-cm-wide spherical microphone array and a sampling rate of 16~kHz using fully randomized input parameters within rooms of size 2X2X2 to 10X10X5 meters. Estimation errors decay towards zero when increasing the array size and sampling rate. The method is also shown to strongly outperform a known baseline, and its ability to extrapolate RIRs at new positions is demonstrated. Crucially, the approach is strictly limited to low-passed discrete RIRs simulated using the vanilla shoebox ISM. Nonetheless, it represents to our knowledge the first algorithmic demonstration that this difficult inverse problem is in-principle fully solvable over a wide range of configurations.
From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Aug 02, 2023



Deep generative models can generate high-fidelity audio conditioned on various types of representations (e.g., mel-spectrograms, Mel-frequency Cepstral Coefficients (MFCC)). Recently, such models have been used to synthesize audio waveforms conditioned on highly compressed representations. Although such methods produce impressive results, they are prone to generate audible artifacts when the conditioning is flawed or imperfect. An alternative modeling approach is to use diffusion models. However, these have mainly been used as speech vocoders (i.e., conditioned on mel-spectrograms) or generating relatively low sampling rate signals. In this work, we propose a high-fidelity multi-band diffusion-based framework that generates any type of audio modality (e.g., speech, music, environmental sounds) from low-bitrate discrete representations. At equal bit rate, the proposed approach outperforms state-of-the-art generative techniques in terms of perceptual quality. Training and, evaluation code, along with audio samples, are available on the facebookresearch/audiocraft Github page.
How to train your sound source localizer
Nov 30, 2022

Learning-based methods have become ubiquitous in sound source localization (SSL). Existing systems rely on simulated training sets for the lack of sufficiently large, diverse and annotated real datasets. Most room acoustic simulators used for this purpose rely on the image source method (ISM) because of its computational efficiency. This paper argues that carefully extending the ISM to incorporate more realistic surface, source and microphone responses into training sets can significantly boost the real-world performance of SSL systems. It is shown that increasing the training-set realism of a state-of-the-art direction-of-arrival estimator yields consistent improvements across three different real test sets featuring human speakers in a variety of rooms and various microphone arrays. An ablation study further reveals that every added layer of realism contributes positively to these improvements.
Signal inpainting from Fourier magnitudes
Oct 28, 2022Signal inpainting is the task of restoring degraded or missing samples in a signal. In this paper we address signal inpainting when Fourier magnitudes are observed. We propose a mathematical formulation of the problem that highlights its connection with phase retrieval, and we introduce two methods for solving it. First, we derive an alternating minimization scheme, which shares similarities with the Gerchberg-Saxton algorithm, a classical phase retrieval method. Second, we propose a convex relaxation of the problem, which is inspired by recent approaches that reformulate phase retrieval into a semidefinite program. We assess the potential of these methods for the task of inpainting gaps in speech signals. Our methods exhibit both a high probability of recovering the original signals and robustness to magnitude noise.
Gridless 3D Recovery of Image Sources from Room Impulse Responses
Aug 30, 2022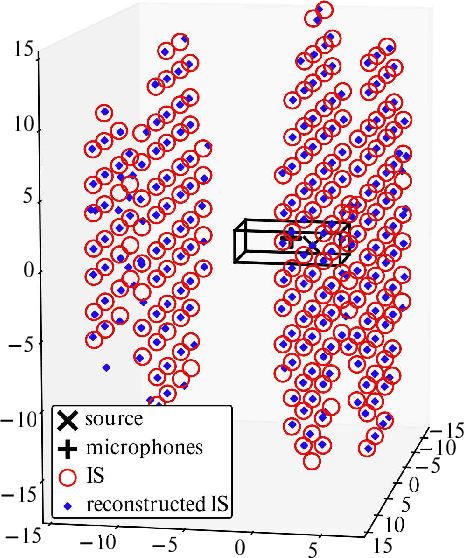
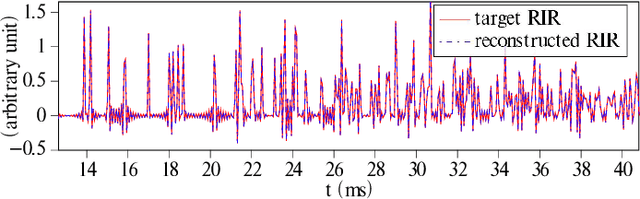
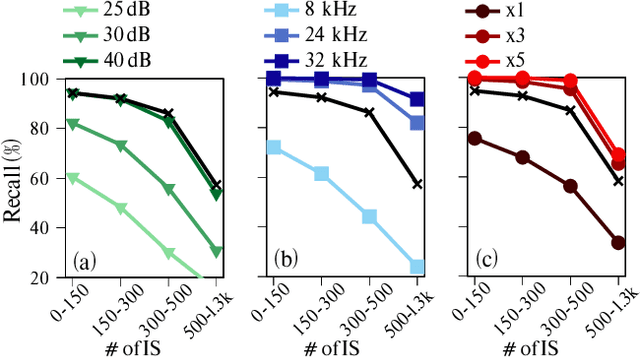
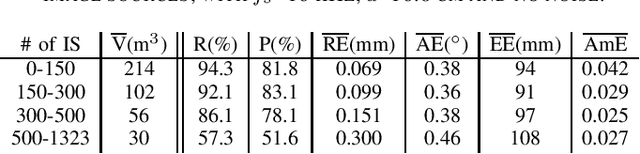
Given a sound field generated by a sparse distribution of impulse image sources, can the continuous 3D positions and amplitudes of these sources be recovered from discrete, bandlimited measurements of the field at a finite set of locations, e.g., a multichannel room impulse response? Borrowing from recent advances in super-resolution imaging, it is shown that this nonlinear, non-convex inverse problem can be efficiently relaxed into a convex linear inverse problem over the space of Radon measures in R3. The linear operator introduced here stems from the fundamental solution of the free-field inhomogenous wave equation combined with the receivers' responses. An adaptation of the Sliding Frank-Wolfe algorithm is proposed to numerically solve the problem off-the-grid, i.e., in continuous 3D space. Simulated experiments show that the approach achieves near-exact recovery of hundreds of image sources using an arbitrarily placed compact 32-channel spherical microphone array in random rectangular rooms. The impact of noise, sampling rate and array diameter on these results is also examined.
Realistic sources, receivers and walls improve the generalisability of virtually-supervised blind acoustic parameter estimators
Jul 19, 2022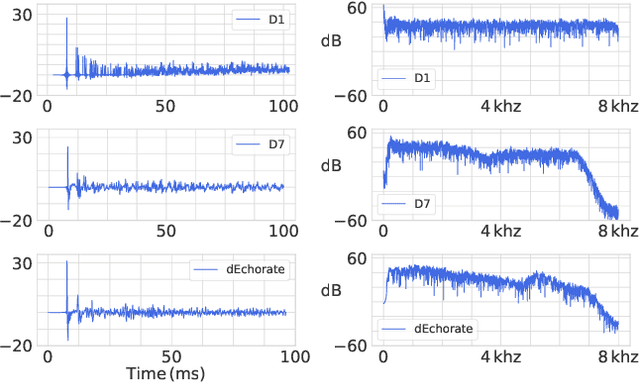

Blind acoustic parameter estimation consists in inferring the acoustic properties of an environment from recordings of unknown sound sources. Recent works in this area have utilized deep neural networks trained either partially or exclusively on simulated data, due to the limited availability of real annotated measurements. In this paper, we study whether a model purely trained using a fast image-source room impulse response simulator can generalize to real data. We present an ablation study on carefully crafted simulated training sets that account for different levels of realism in source, receiver and wall responses. The extent of realism is controlled by the sampling of wall absorption coefficients and by applying measured directivity patterns to microphones and sources. A state-of-the-art model trained on these datasets is evaluated on the task of jointly estimating the room's volume, total surface area, and octave-band reverberation times from multiple, multichannel speech recordings. Results reveal that every added layer of simulation realism at train time significantly improves the estimation of all quantities on real signals.
Detecting acoustic reflectors using a robot's ego-noise
Nov 16, 2021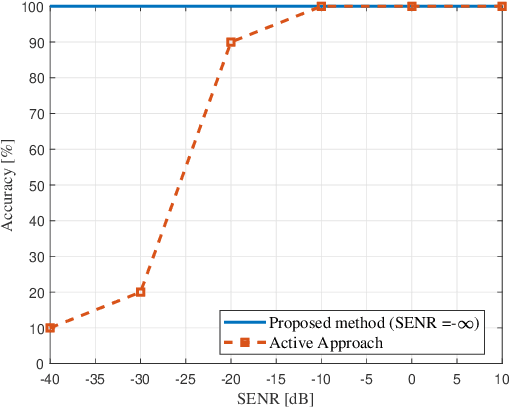
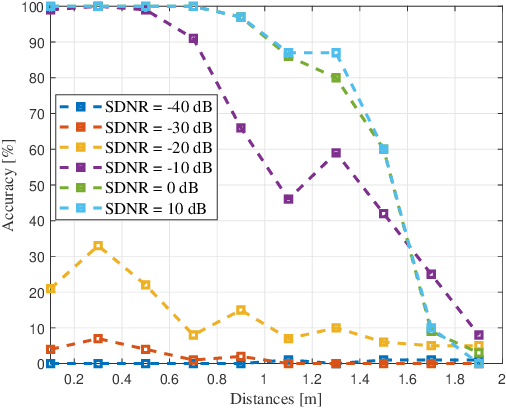
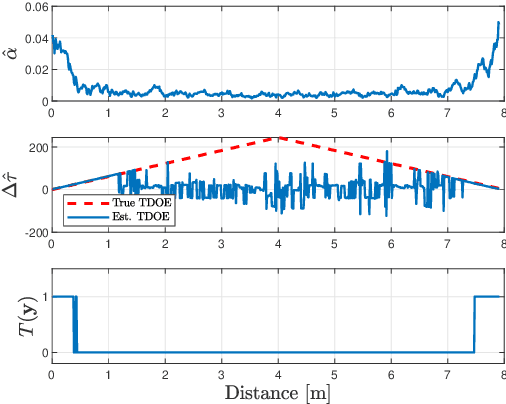
In this paper, we propose a method to estimate the proximity of an acoustic reflector, e.g., a wall, using ego-noise, i.e., the noise produced by the moving parts of a listening robot. This is achieved by estimating the times of arrival of acoustic echoes reflected from the surface. Simulated experiments show that the proposed nonintrusive approach is capable of accurately estimating the distance of a reflector up to 1 meter and outperforms a previously proposed intrusive approach under loud ego-noise conditions. The proposed method is helped by a probabilistic echo detector that estimates whether or not an acoustic reflector is within a short range of the robotic platform. This preliminary investigation paves the way towards a new kind of collision avoidance system that would purely rely on audio sensors rather than conventional proximity sensors.
Mean absorption estimation from room impulse responses using virtually supervised learning
Sep 01, 2021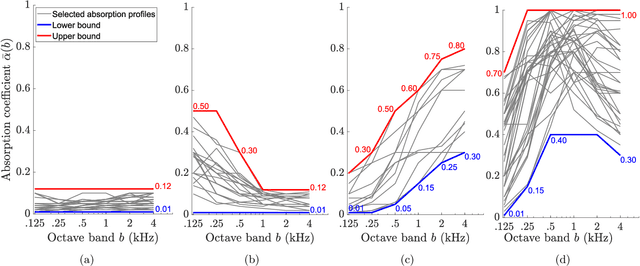
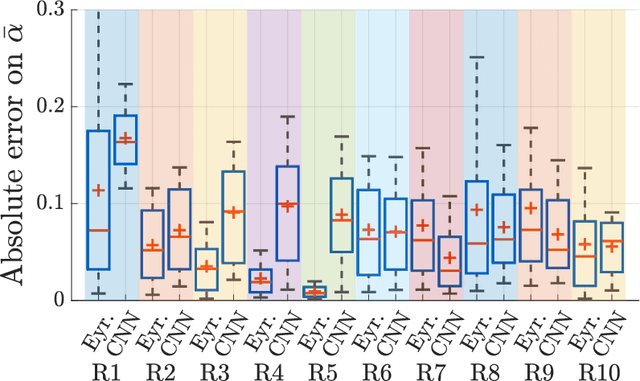
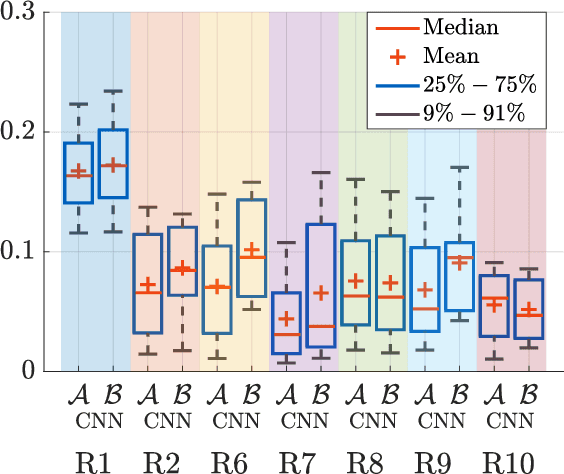
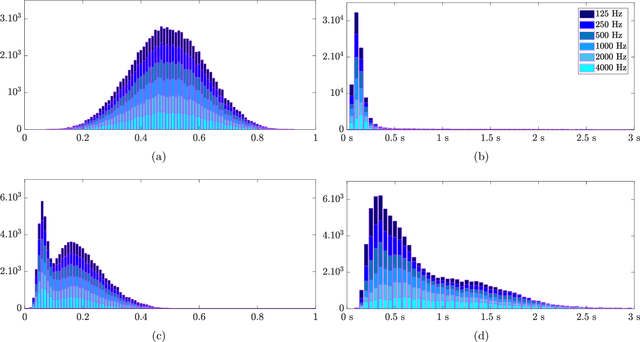
In the context of building acoustics and the acoustic diagnosis of an existing room, this paper introduces and investigates a new approach to estimate mean absorption coefficients solely from a room impulse response (RIR). This inverse problem is tackled via virtually-supervised learning, namely, the RIR-to-absorption mapping is implicitly learned by regression on a simulated dataset using artificial neural networks. We focus on simple models based on well-understood architectures. The critical choices of geometric, acoustic and simulation parameters used to train the models are extensively discussed and studied, while keeping in mind conditions that are representative of the field of building acoustics. Estimation errors from the learned neural models are compared to those obtained with classical formulas that require knowledge of the room's geometry and reverberation times. Extensive comparisons made on a variety of simulated test sets highlight different conditions under which the learned models can overcome the well-known limitations of the diffuse sound field hypothesis underlying these formulas. Results obtained on real RIRs measured in an acoustically configurable room show that at 1~kHz and above, the proposed approach performs comparably to classical models when reverberation times can be reliably estimated, and continues to work even when they cannot.
Blind Room Parameter Estimation Using Multiple-Multichannel Speech Recordings
Jul 29, 2021
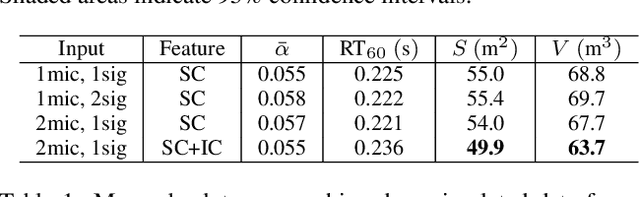
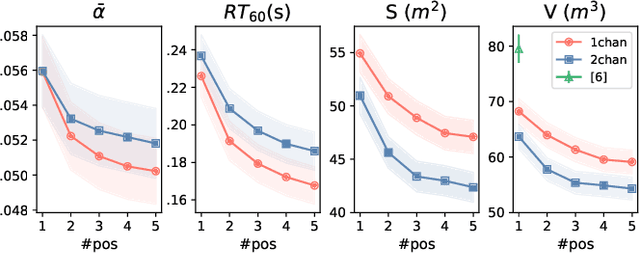
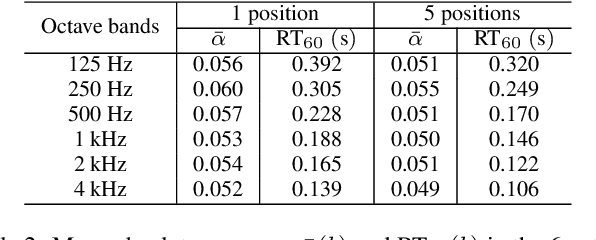
Knowing the geometrical and acoustical parameters of a room may benefit applications such as audio augmented reality, speech dereverberation or audio forensics. In this paper, we study the problem of jointly estimating the total surface area, the volume, as well as the frequency-dependent reverberation time and mean surface absorption of a room in a blind fashion, based on two-channel noisy speech recordings from multiple, unknown source-receiver positions. A novel convolutional neural network architecture leveraging both single- and inter-channel cues is proposed and trained on a large, realistic simulated dataset. Results on both simulated and real data show that using multiple observations in one room significantly reduces estimation errors and variances on all target quantities, and that using two channels helps the estimation of surface and volume. The proposed model outperforms a recently proposed blind volume estimation method on the considered datasets.