 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Novel Interpretable and Generalizable Re-synchronization Model for Cued Speech based on a Multi-Cuer Corpus
Jun 05, 2023
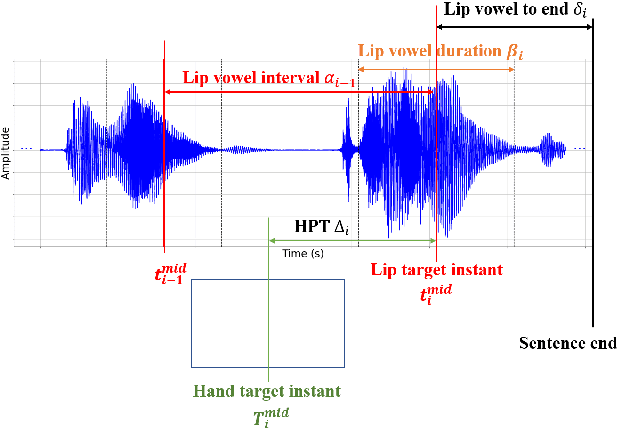
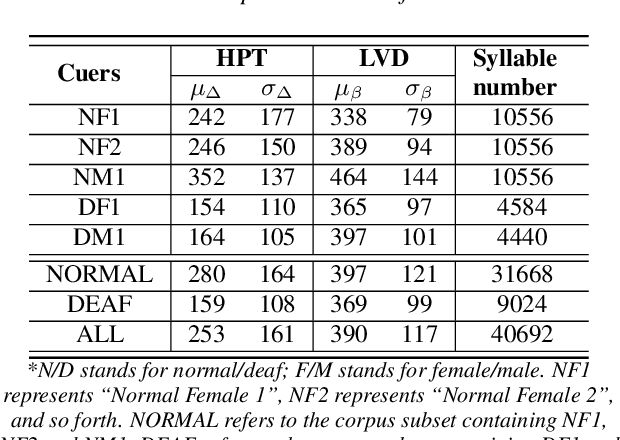
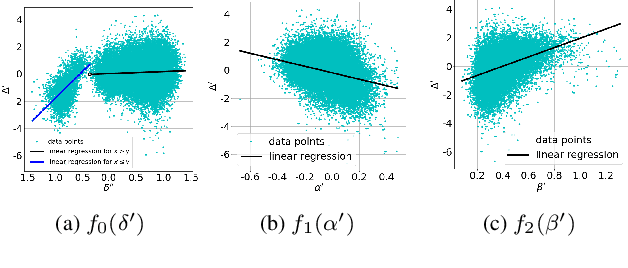
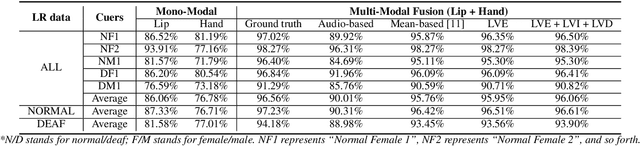
Cued Speech (CS) is a multi-modal visual coding system combining lip reading with several hand cues at the phonetic level to make the spoken language visible to the hearing impaired. Previous studies solved asynchronous problems between lip and hand movements by a cuer\footnote{The people who perform Cued Speech are called the cuer.}-dependent piecewise linear model for English and French CS. In this work, we innovatively propose three statistical measure on the lip stream to build an interpretable and generalizable model for predicting hand preceding time (HPT), which achieves cuer-independent by a proper normalization. Particularly, we build the first Mandarin CS corpus comprising annotated videos from five speakers including three normal and two hearing impaired individuals. Consequently, we show that the hand preceding phenomenon exists in Mandarin CS production with significant differences between normal and hearing impaired people. Extensive experiments demonstrate that our model outperforms the baseline and the previous state-of-the-art methods.
Flowchase: a Mobile Application for Pronunciation Training
Jul 05, 2023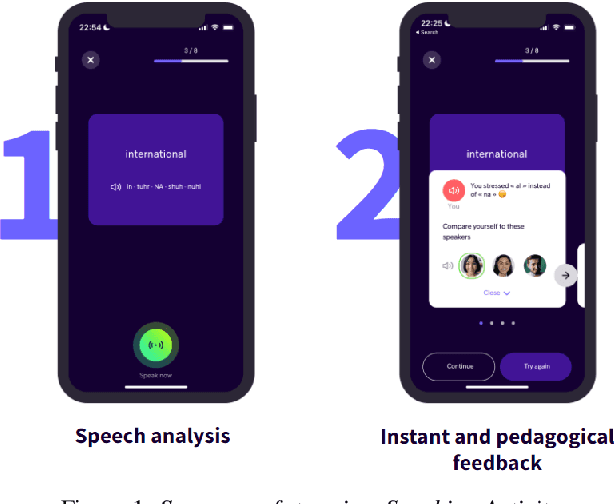
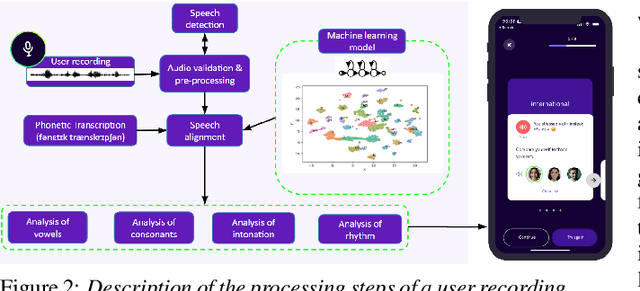

In this paper, we present a solution for providing personalized and instant feedback to English learners through a mobile application, called Flowchase, that is connected to a speech technology able to segment and analyze speech segmental and supra-segmental features. The speech processing pipeline receives linguistic information corresponding to an utterance to analyze along with a speech sample. After validation of the speech sample, a joint forced-alignment and phonetic recognition is performed thanks to a combination of machine learning models based on speech representation learning that provides necessary information for designing a feedback on a series of segmental and supra-segmental pronunciation aspects.
Multi-perspective Information Fusion Res2Net with RandomSpecmix for Fake Speech Detection
Jun 27, 2023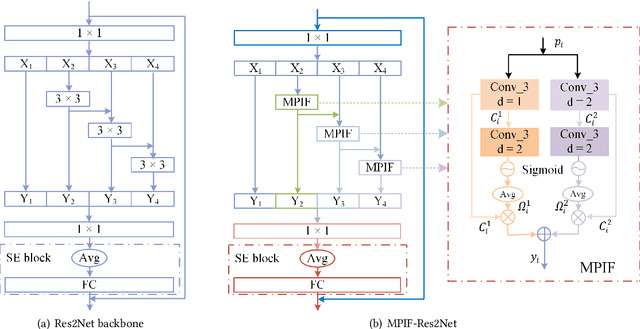

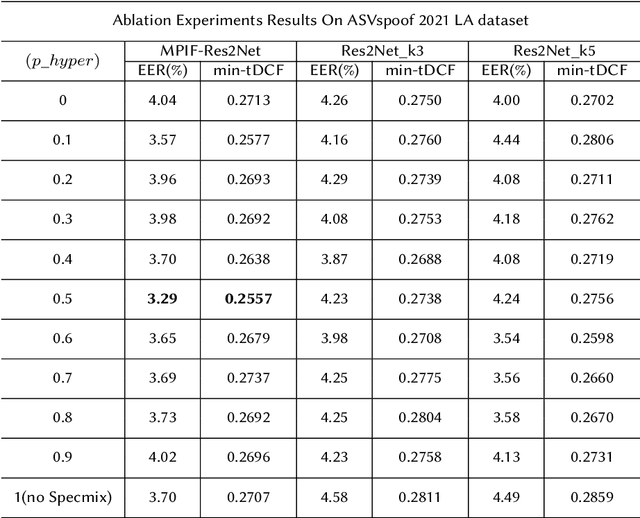
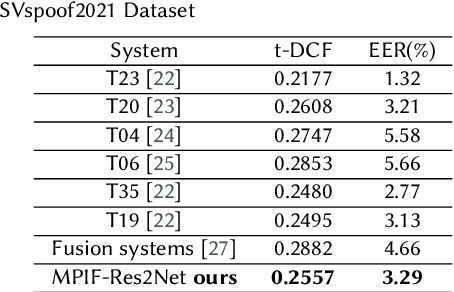
In this paper, we propose the multi-perspective information fusion (MPIF) Res2Net with random Specmix for fake speech detection (FSD). The main purpose of this system is to improve the model's ability to learn precise forgery information for FSD task in low-quality scenarios. The task of random Specmix, a data augmentation, is to improve the generalization ability of the model and enhance the model's ability to locate discriminative information. Specmix cuts and pastes the frequency dimension information of the spectrogram in the same batch of samples without introducing other data, which helps the model to locate the really useful information. At the same time, we randomly select samples for augmentation to reduce the impact of data augmentation directly changing all the data. Once the purpose of helping the model to locate information is achieved, it is also important to reduce unnecessary information. The role of MPIF-Res2Net is to reduce redundant interference information. Deceptive information from a single perspective is always similar, so the model learning this similar information will produce redundant spoofing clues and interfere with truly discriminative information. The proposed MPIF-Res2Net fuses information from different perspectives, making the information learned by the model more diverse, thereby reducing the redundancy caused by similar information and avoiding interference with the learning of discriminative information. The results on the ASVspoof 2021 LA dataset demonstrate the effectiveness of our proposed method, achieving EER and min-tDCF of 3.29% and 0.2557, respectively.
A Survey on Deep Multi-modal Learning for Body Language Recognition and Generation
Aug 17, 2023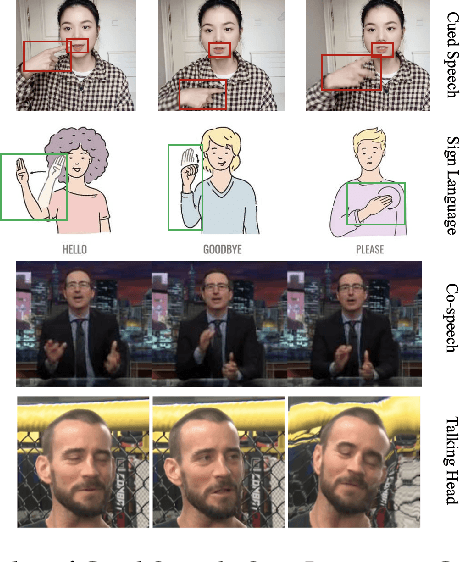
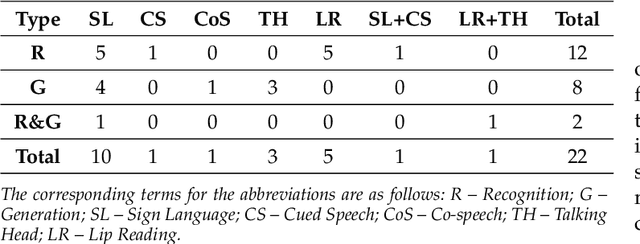
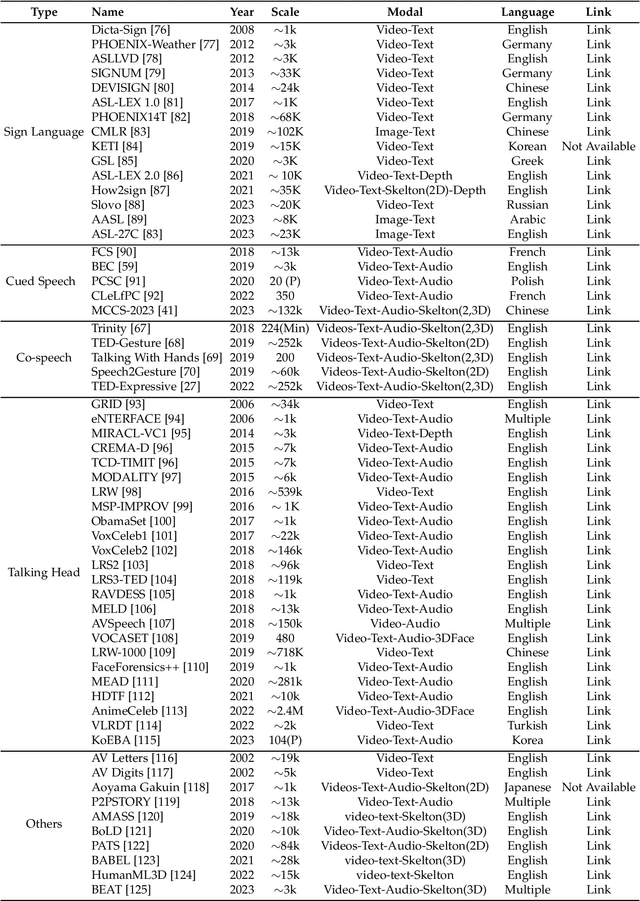
Body language (BL) refers to the non-verbal communication expressed through physical movements, gestures, facial expressions, and postures. It is a form of communication that conveys information, emotions, attitudes, and intentions without the use of spoken or written words. It plays a crucial role in interpersonal interactions and can complement or even override verbal communication. Deep multi-modal learning techniques have shown promise in understanding and analyzing these diverse aspects of BL. The survey emphasizes their applications to BL generation and recognition. Several common BLs are considered i.e., Sign Language (SL), Cued Speech (CS), Co-speech (CoS), and Talking Head (TH), and we have conducted an analysis and established the connections among these four BL for the first time. Their generation and recognition often involve multi-modal approaches. Benchmark datasets for BL research are well collected and organized, along with the evaluation of SOTA methods on these datasets. The survey highlights challenges such as limited labeled data, multi-modal learning, and the need for domain adaptation to generalize models to unseen speakers or languages. Future research directions are presented, including exploring self-supervised learning techniques, integrating contextual information from other modalities, and exploiting large-scale pre-trained multi-modal models. In summary, this survey paper provides a comprehensive understanding of deep multi-modal learning for various BL generations and recognitions for the first time. By analyzing advancements, challenges, and future directions, it serves as a valuable resource for researchers and practitioners in advancing this field. n addition, we maintain a continuously updated paper list for deep multi-modal learning for BL recognition and generation: https://github.com/wentaoL86/awesome-body-language.
Federated learning for secure development of AI models for Parkinson's disease detection using speech from different languages
May 18, 2023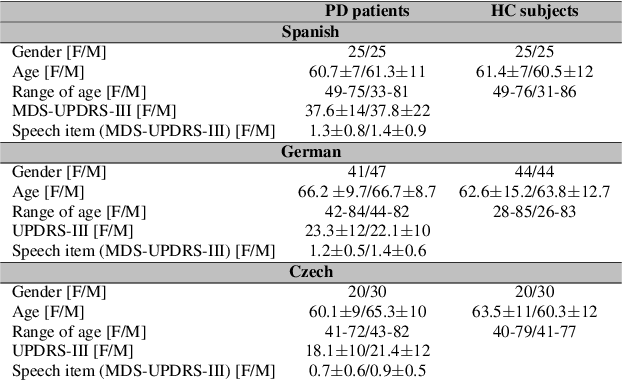
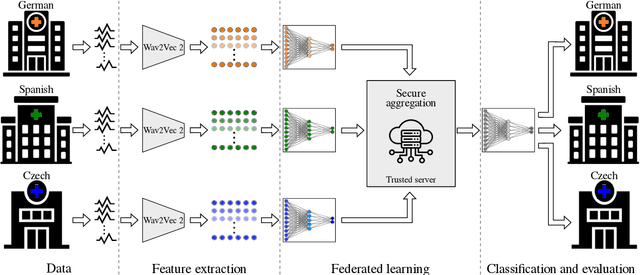
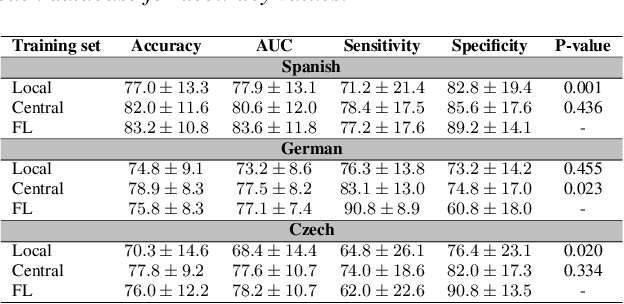
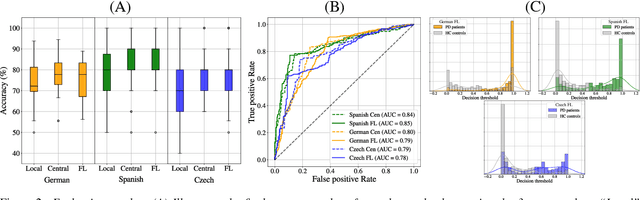
Parkinson's disease (PD) is a neurological disorder impacting a person's speech. Among automatic PD assessment methods, deep learning models have gained particular interest. Recently, the community has explored cross-pathology and cross-language models which can improve diagnostic accuracy even further. However, strict patient data privacy regulations largely prevent institutions from sharing patient speech data with each other. In this paper, we employ federated learning (FL) for PD detection using speech signals from 3 real-world language corpora of German, Spanish, and Czech, each from a separate institution. Our results indicate that the FL model outperforms all the local models in terms of diagnostic accuracy, while not performing very differently from the model based on centrally combined training sets, with the advantage of not requiring any data sharing among collaborators. This will simplify inter-institutional collaborations, resulting in enhancement of patient outcomes.
ChatGPT-EDSS: Empathetic Dialogue Speech Synthesis Trained from ChatGPT-derived Context Word Embeddings
May 23, 2023
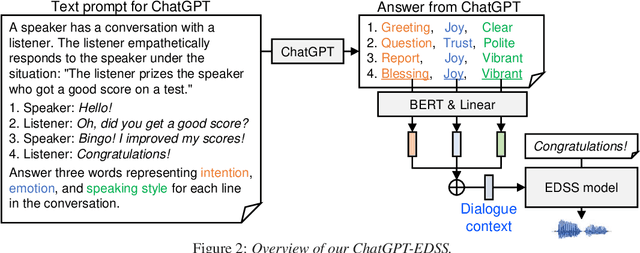
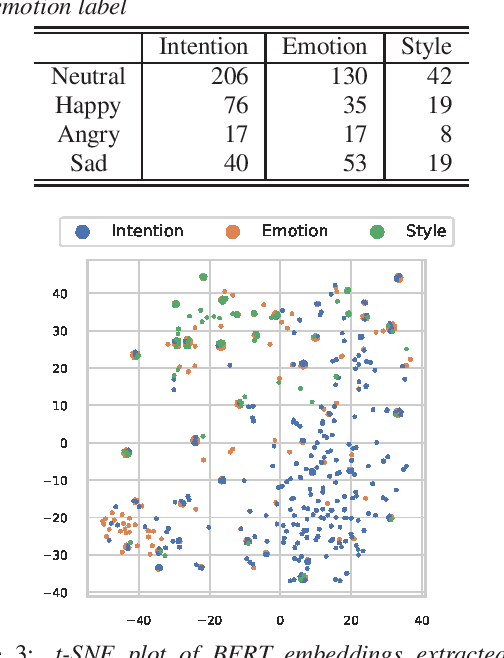
We propose ChatGPT-EDSS, an empathetic dialogue speech synthesis (EDSS) method using ChatGPT for extracting dialogue context. ChatGPT is a chatbot that can deeply understand the content and purpose of an input prompt and appropriately respond to the user's request. We focus on ChatGPT's reading comprehension and introduce it to EDSS, a task of synthesizing speech that can empathize with the interlocutor's emotion. Our method first gives chat history to ChatGPT and asks it to generate three words representing the intention, emotion, and speaking style for each line in the chat. Then, it trains an EDSS model using the embeddings of ChatGPT-derived context words as the conditioning features. The experimental results demonstrate that our method performs comparably to ones using emotion labels or neural network-derived context embeddings learned from chat histories. The collected ChatGPT-derived context information is available at https://sarulab-speech.github.io/demo_ChatGPT_EDSS/.
Context-aware Coherent Speaking Style Prediction with Hierarchical Transformers for Audiobook Speech Synthesis
Apr 13, 2023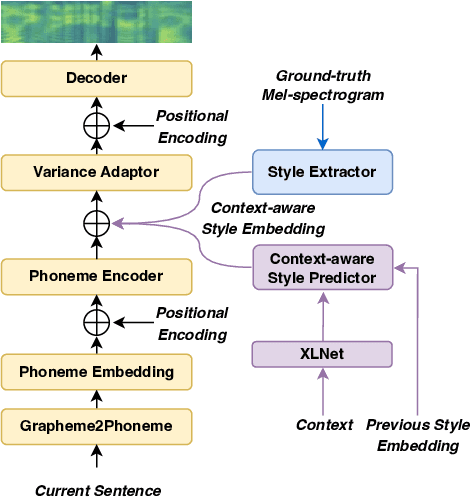
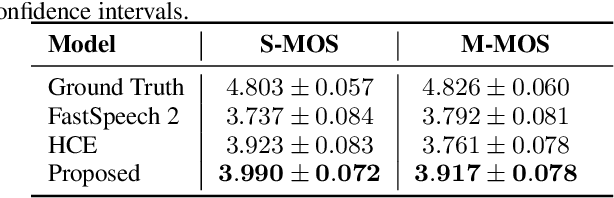
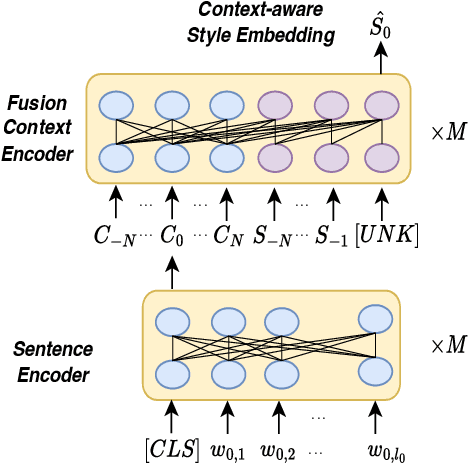
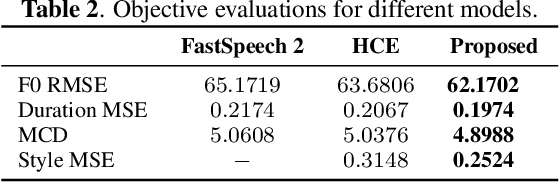
Recent advances in text-to-speech have significantly improved the expressiveness of synthesized speech. However, it is still challenging to generate speech with contextually appropriate and coherent speaking style for multi-sentence text in audiobooks. In this paper, we propose a context-aware coherent speaking style prediction method for audiobook speech synthesis. To predict the style embedding of the current utterance, a hierarchical transformer-based context-aware style predictor with a mixture attention mask is designed, considering both text-side context information and speech-side style information of previous speeches. Based on this, we can generate long-form speech with coherent style and prosody sentence by sentence. Objective and subjective evaluations on a Mandarin audiobook dataset demonstrate that our proposed model can generate speech with more expressive and coherent speaking style than baselines, for both single-sentence and multi-sentence test.
Toward Generalizable Machine Learning Models in Speech, Language, and Hearing Sciences: Sample Size Estimation and Reducing Overfitting
Aug 30, 2023
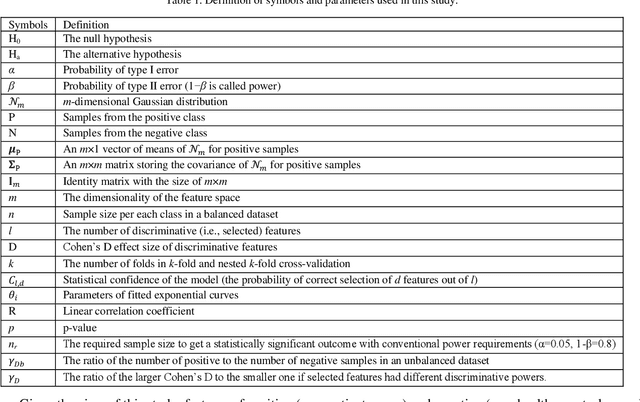
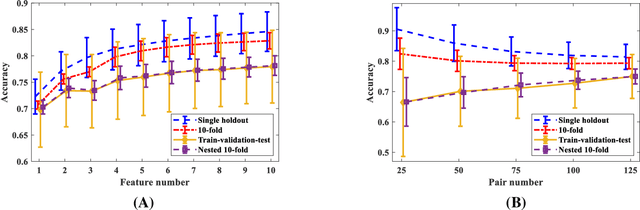

This study's first purpose is to provide quantitative evidence that would incentivize researchers to instead use the more robust method of nested cross-validation. The second purpose is to present methods and MATLAB codes for doing power analysis for ML-based analysis during the design of a study. Monte Carlo simulations were used to quantify the interactions between the employed cross-validation method, the discriminative power of features, the dimensionality of the feature space, and the dimensionality of the model. Four different cross-validations (single holdout, 10-fold, train-validation-test, and nested 10-fold) were compared based on the statistical power and statistical confidence of the ML models. Distributions of the null and alternative hypotheses were used to determine the minimum required sample size for obtaining a statistically significant outcome ({\alpha}=0.05, 1-\b{eta}=0.8). Statistical confidence of the model was defined as the probability of correct features being selected and hence being included in the final model. Our analysis showed that the model generated based on the single holdout method had very low statistical power and statistical confidence and that it significantly overestimated the accuracy. Conversely, the nested 10-fold cross-validation resulted in the highest statistical confidence and the highest statistical power, while providing an unbiased estimate of the accuracy. The required sample size with a single holdout could be 50% higher than what would be needed if nested cross-validation were used. Confidence in the model based on nested cross-validation was as much as four times higher than the confidence in the single holdout-based model. A computational model, MATLAB codes, and lookup tables are provided to assist researchers with estimating the sample size during the design of their future studies.
Parts of Speech-Grounded Subspaces in Vision-Language Models
May 23, 2023

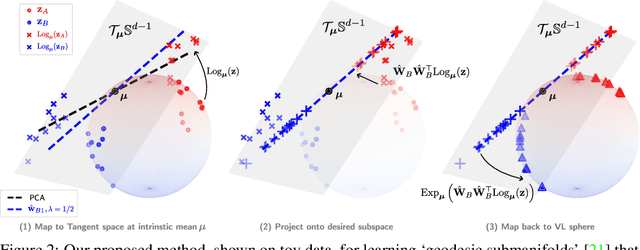
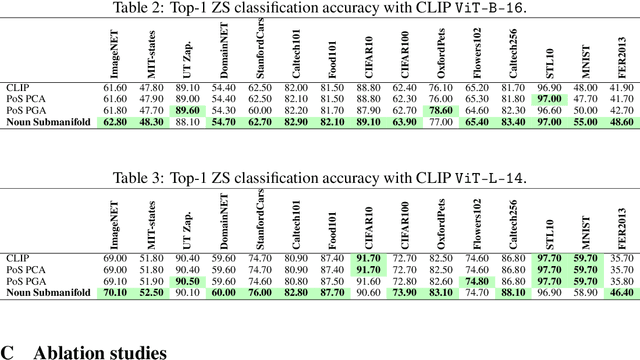
Latent image representations arising from vision-language models have proved immensely useful for a variety of downstream tasks. However, their utility is limited by their entanglement with respect to different visual attributes. For instance, recent work has shown that CLIP image representations are often biased toward specific visual properties (such as objects or actions) in an unpredictable manner. In this paper, we propose to separate representations of the different visual modalities in CLIP's joint vision-language space by leveraging the association between parts of speech and specific visual modes of variation (e.g. nouns relate to objects, adjectives describe appearance). This is achieved by formulating an appropriate component analysis model that learns subspaces capturing variability corresponding to a specific part of speech, while jointly minimising variability to the rest. Such a subspace yields disentangled representations of the different visual properties of an image or text in closed form while respecting the underlying geometry of the manifold on which the representations lie. What's more, we show the proposed model additionally facilitates learning subspaces corresponding to specific visual appearances (e.g. artists' painting styles), which enables the selective removal of entire visual themes from CLIP-based text-to-image synthesis. We validate the model both qualitatively, by visualising the subspace projections with a text-to-image model and by preventing the imitation of artists' styles, and quantitatively, through class invariance metrics and improvements to baseline zero-shot classification. Our code is available at: https://github.com/james-oldfield/PoS-subspaces.
Predicting EEG Responses to Attended Speech via Deep Neural Networks for Speech
Feb 27, 2023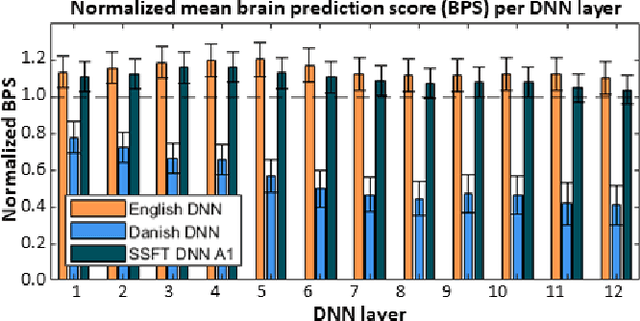
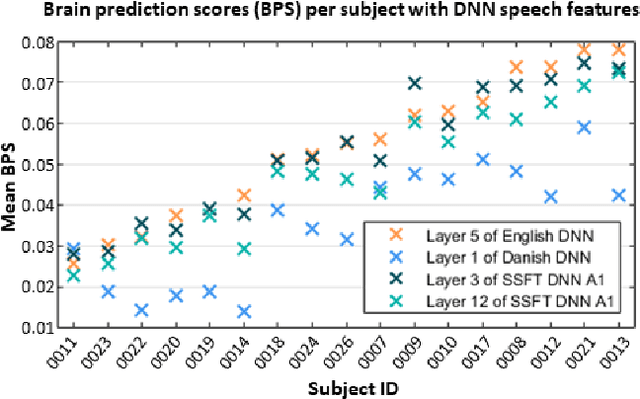
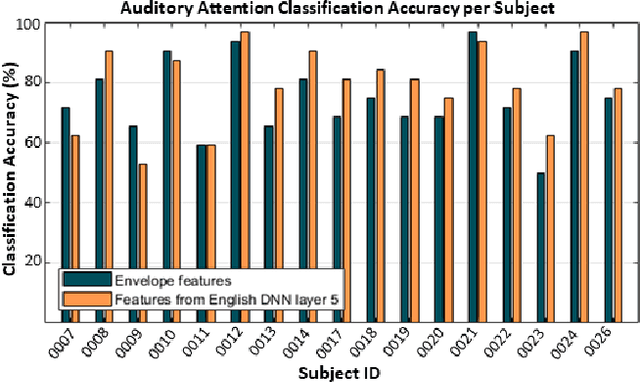
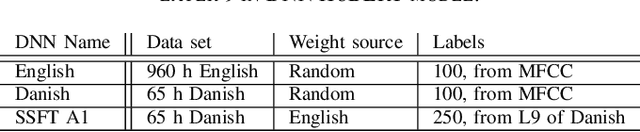
Attending to the speech stream of interest in multi-talker environments can be a challenging task, particularly for listeners with hearing impairment. Research suggests that neural responses assessed with electroencephalography (EEG) are modulated by listener`s auditory attention, revealing selective neural tracking (NT) of the attended speech. NT methods mostly rely on hand-engineered acoustic and linguistic speech features to predict the neural response. Only recently, deep neural network (DNN) models without specific linguistic information have been used to extract speech features for NT, demonstrating that speech features in hierarchical DNN layers can predict neural responses throughout the auditory pathway. In this study, we go one step further to investigate the suitability of similar DNN models for speech to predict neural responses to competing speech observed in EEG. We recorded EEG data using a 64-channel acquisition system from 17 listeners with normal hearing instructed to attend to one of two competing talkers. Our data revealed that EEG responses are significantly better predicted by DNN-extracted speech features than by hand-engineered acoustic features. Furthermore, analysis of hierarchical DNN layers showed that early layers yielded the highest predictions. Moreover, we found a significant increase in auditory attention classification accuracies with the use of DNN-extracted speech features over the use of hand-engineered acoustic features. These findings open a new avenue for development of new NT measures to evaluate and further advance hearing technology.