 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Non Intrusive Intelligibility Predictor for Hearing Impaired Individuals using Self Supervised Speech Representations
Jul 27, 2023
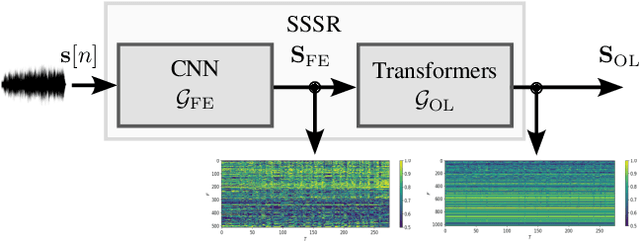
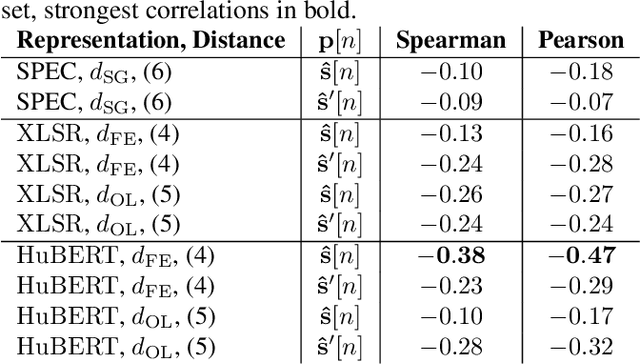
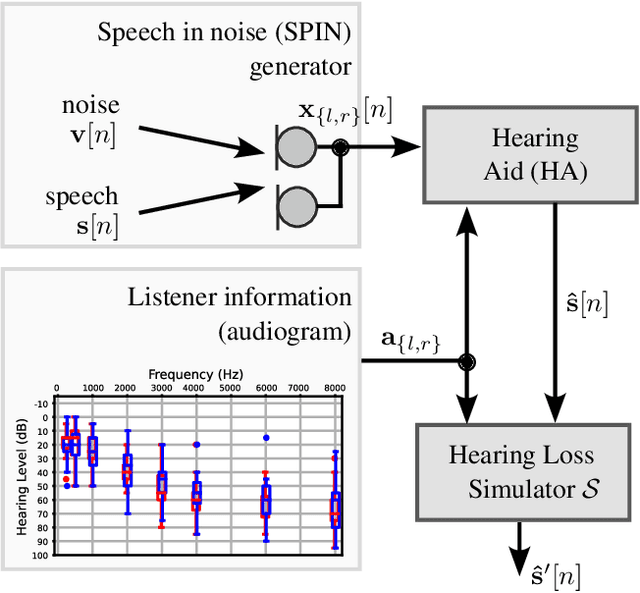
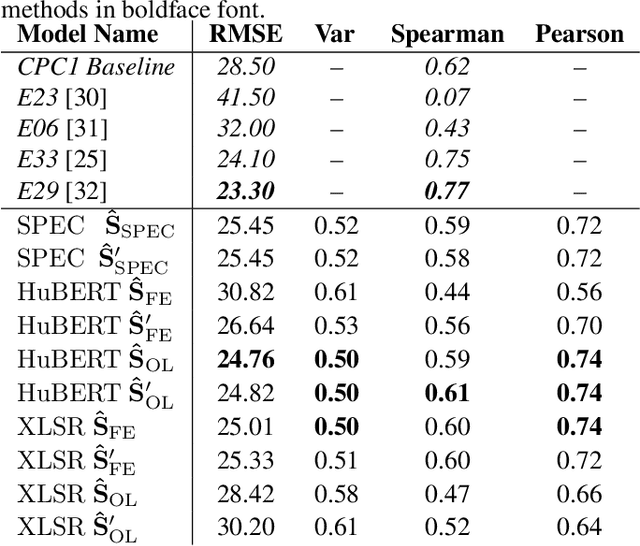
Self-supervised speech representations (SSSRs) have been successfully applied to a number of speech-processing tasks, e.g. as feature extractor for speech quality (SQ) prediction, which is, in turn, relevant for assessment and training speech enhancement systems for users with normal or impaired hearing. However, exact knowledge of why and how quality-related information is encoded well in such representations remains poorly understood. In this work, techniques for non-intrusive prediction of SQ ratings are extended to the prediction of intelligibility for hearing-impaired users. It is found that self-supervised representations are useful as input features to non-intrusive prediction models, achieving competitive performance to more complex systems. A detailed analysis of the performance depending on Clarity Prediction Challenge 1 listeners and enhancement systems indicates that more data might be needed to allow generalisation to unknown systems and (hearing-impaired) individuals
GASS: Generalizing Audio Source Separation with Large-scale Data
Sep 29, 2023
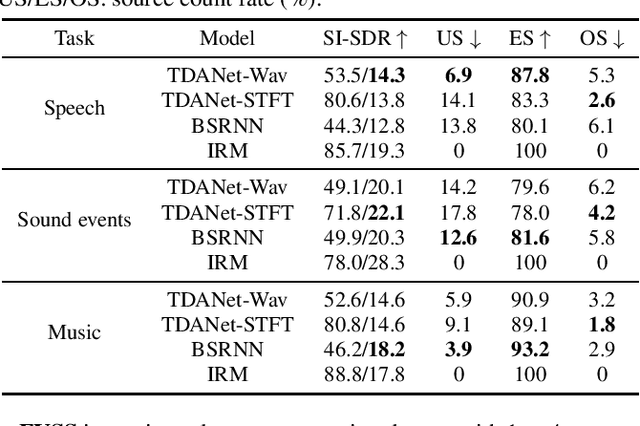
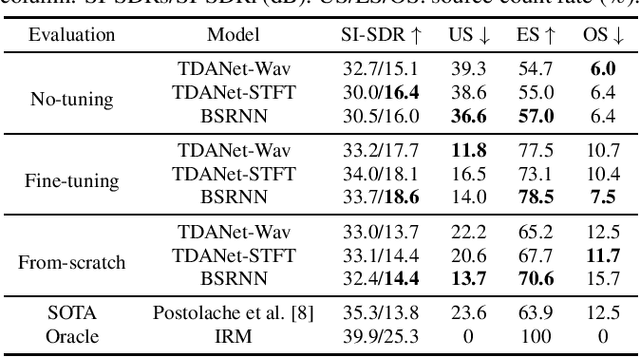
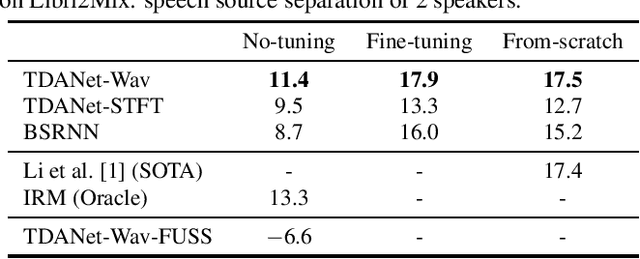
Universal source separation targets at separating the audio sources of an arbitrary mix, removing the constraint to operate on a specific domain like speech or music. Yet, the potential of universal source separation is limited because most existing works focus on mixes with predominantly sound events, and small training datasets also limit its potential for supervised learning. Here, we study a single general audio source separation (GASS) model trained to separate speech, music, and sound events in a supervised fashion with a large-scale dataset. We assess GASS models on a diverse set of tasks. Our strong in-distribution results show the feasibility of GASS models, and the competitive out-of-distribution performance in sound event and speech separation shows its generalization abilities. Yet, it is challenging for GASS models to generalize for separating out-of-distribution cinematic and music content. We also fine-tune GASS models on each dataset and consistently outperform the ones without pre-training. All fine-tuned models (except the music separation one) obtain state-of-the-art results in their respective benchmarks.
UniverSLU: Universal Spoken Language Understanding for Diverse Classification and Sequence Generation Tasks with a Single Network
Oct 04, 2023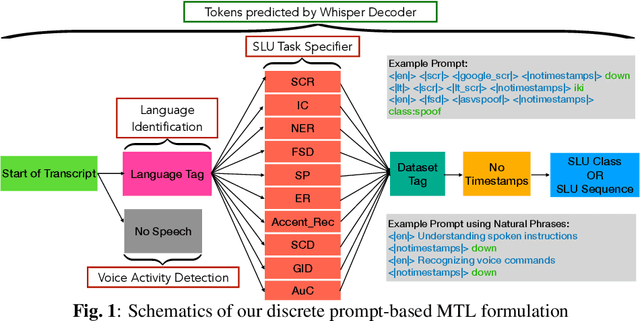
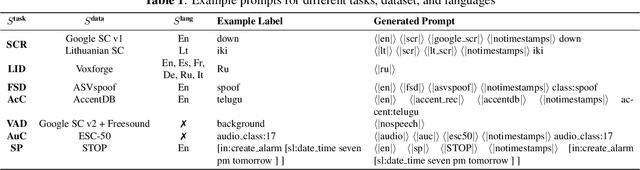


Recent studies have demonstrated promising outcomes by employing large language models with multi-tasking capabilities. They utilize prompts to guide the model's behavior and surpass performance of task-specific models. Motivated by this, we ask: can we build a single model that jointly perform various spoken language understanding (SLU) tasks? To address this, we utilize pre-trained automatic speech recognition (ASR) models and employ various task and dataset specifiers as discrete prompts. We demonstrate efficacy of our single multi-task learning (MTL) model "UniverSLU" for 12 different speech classification and sequence generation tasks across 17 datasets and 9 languages. Results show that UniverSLU achieves competitive performance and even surpasses task-specific models. We also conduct preliminary investigations into enabling human-interpretable natural phrases instead of task specifiers as discrete prompts and test the model's generalization capabilities to new paraphrases.
Improving severity preservation of healthy-to-pathological voice conversion with global style tokens
Oct 04, 2023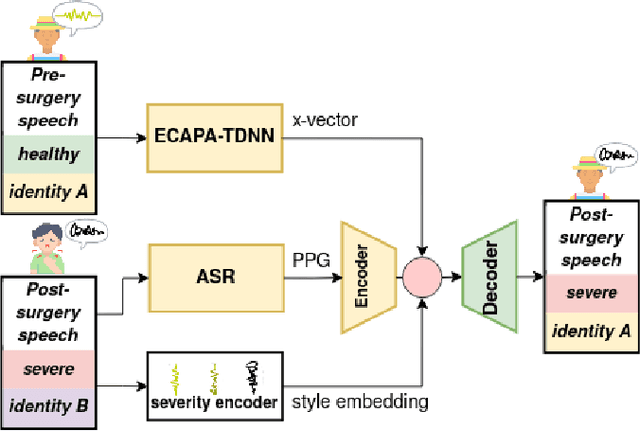


In healthy-to-pathological voice conversion (H2P-VC), healthy speech is converted into pathological while preserving the identity. The paper improves on previous two-stage approach to H2P-VC where (1) speech is created first with the appropriate severity, (2) then the speaker identity of the voice is converted while preserving the severity of the voice. Specifically, we propose improvements to (2) by using phonetic posteriorgrams (PPG) and global style tokens (GST). Furthermore, we present a new dataset that contains parallel recordings of pathological and healthy speakers with the same identity which allows more precise evaluation. Listening tests by expert listeners show that the framework preserves severity of the source sample, while modelling target speaker's voice. We also show that (a) pathology impacts x-vectors but not all speaker information is lost, (b) choosing source speakers based on severity labels alone is insufficient.
Powerset multi-class cross entropy loss for neural speaker diarization
Oct 19, 2023Since its introduction in 2019, the whole end-to-end neural diarization (EEND) line of work has been addressing speaker diarization as a frame-wise multi-label classification problem with permutation-invariant training. Despite EEND showing great promise, a few recent works took a step back and studied the possible combination of (local) supervised EEND diarization with (global) unsupervised clustering. Yet, these hybrid contributions did not question the original multi-label formulation. We propose to switch from multi-label (where any two speakers can be active at the same time) to powerset multi-class classification (where dedicated classes are assigned to pairs of overlapping speakers). Through extensive experiments on 9 different benchmarks, we show that this formulation leads to significantly better performance (mostly on overlapping speech) and robustness to domain mismatch, while eliminating the detection threshold hyperparameter, critical for the multi-label formulation.
HANSEN: Human and AI Spoken Text Benchmark for Authorship Analysis
Oct 25, 2023

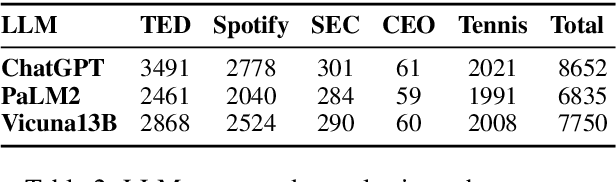
Authorship Analysis, also known as stylometry, has been an essential aspect of Natural Language Processing (NLP) for a long time. Likewise, the recent advancement of Large Language Models (LLMs) has made authorship analysis increasingly crucial for distinguishing between human-written and AI-generated texts. However, these authorship analysis tasks have primarily been focused on written texts, not considering spoken texts. Thus, we introduce the largest benchmark for spoken texts - HANSEN (Human ANd ai Spoken tExt beNchmark). HANSEN encompasses meticulous curation of existing speech datasets accompanied by transcripts, alongside the creation of novel AI-generated spoken text datasets. Together, it comprises 17 human datasets, and AI-generated spoken texts created using 3 prominent LLMs: ChatGPT, PaLM2, and Vicuna13B. To evaluate and demonstrate the utility of HANSEN, we perform Authorship Attribution (AA) & Author Verification (AV) on human-spoken datasets and conducted Human vs. AI spoken text detection using state-of-the-art (SOTA) models. While SOTA methods, such as, character ngram or Transformer-based model, exhibit similar AA & AV performance in human-spoken datasets compared to written ones, there is much room for improvement in AI-generated spoken text detection. The HANSEN benchmark is available at: https://huggingface.co/datasets/HANSEN-REPO/HANSEN.
Intelligible Lip-to-Speech Synthesis with Speech Units
May 31, 2023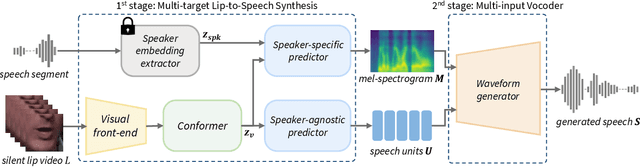
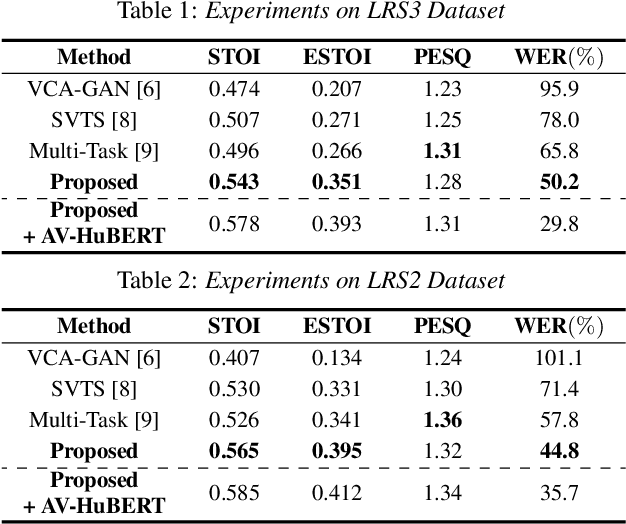
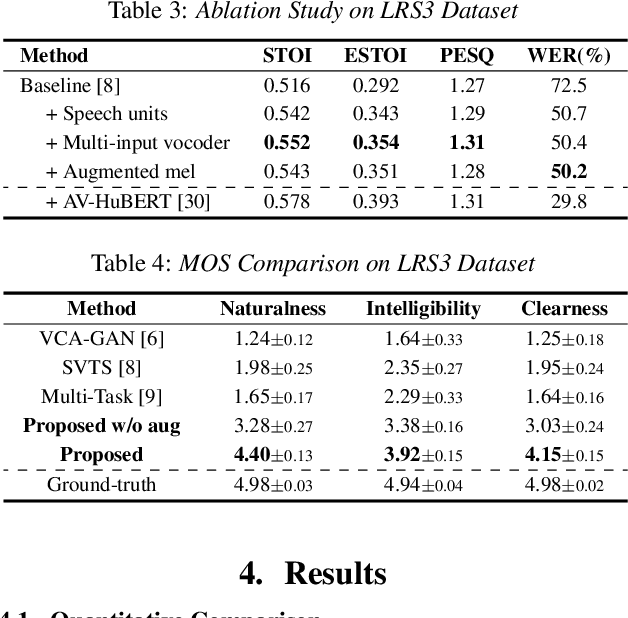
In this paper, we propose a novel Lip-to-Speech synthesis (L2S) framework, for synthesizing intelligible speech from a silent lip movement video. Specifically, to complement the insufficient supervisory signal of the previous L2S model, we propose to use quantized self-supervised speech representations, named speech units, as an additional prediction target for the L2S model. Therefore, the proposed L2S model is trained to generate multiple targets, mel-spectrogram and speech units. As the speech units are discrete while mel-spectrogram is continuous, the proposed multi-target L2S model can be trained with strong content supervision, without using text-labeled data. Moreover, to accurately convert the synthesized mel-spectrogram into a waveform, we introduce a multi-input vocoder that can generate a clear waveform even from blurry and noisy mel-spectrogram by referring to the speech units. Extensive experimental results confirm the effectiveness of the proposed method in L2S.
Classification of Dysarthria based on the Levels of Severity. A Systematic Review
Oct 11, 2023Dysarthria is a neurological speech disorder that can significantly impact affected individuals' communication abilities and overall quality of life. The accurate and objective classification of dysarthria and the determination of its severity are crucial for effective therapeutic intervention. While traditional assessments by speech-language pathologists (SLPs) are common, they are often subjective, time-consuming, and can vary between practitioners. Emerging machine learning-based models have shown the potential to provide a more objective dysarthria assessment, enhancing diagnostic accuracy and reliability. This systematic review aims to comprehensively analyze current methodologies for classifying dysarthria based on severity levels. Specifically, this review will focus on determining the most effective set and type of features that can be used for automatic patient classification and evaluating the best AI techniques for this purpose. We will systematically review the literature on the automatic classification of dysarthria severity levels. Sources of information will include electronic databases and grey literature. Selection criteria will be established based on relevance to the research questions. Data extraction will include methodologies used, the type of features extracted for classification, and AI techniques employed. The findings of this systematic review will contribute to the current understanding of dysarthria classification, inform future research, and support the development of improved diagnostic tools. The implications of these findings could be significant in advancing patient care and improving therapeutic outcomes for individuals affected by dysarthria.
Single-Channel Speech Enhancement with Deep Complex U-Networks and Probabilistic Latent Space Models
Sep 04, 2023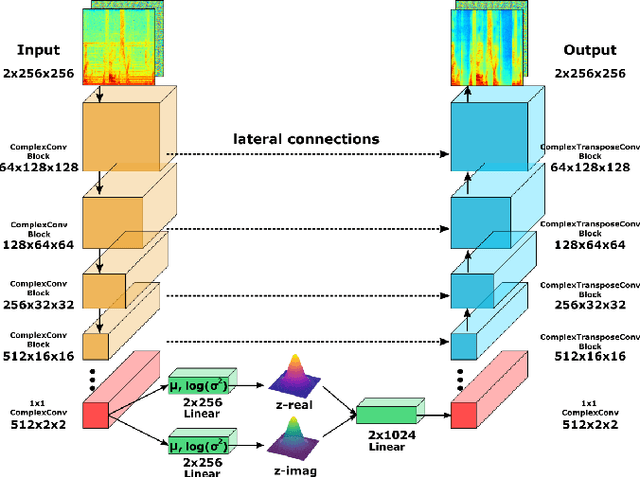
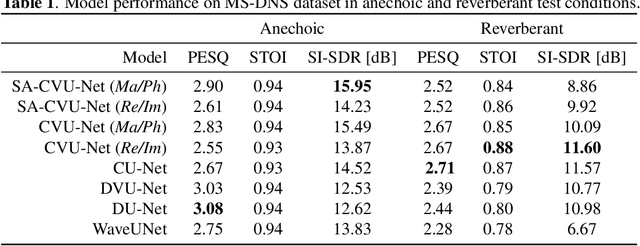
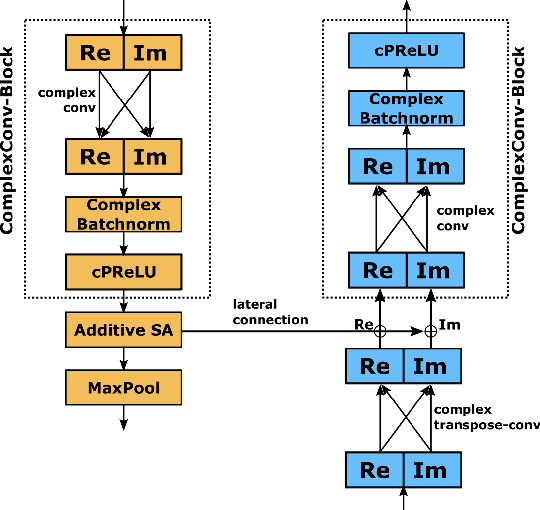
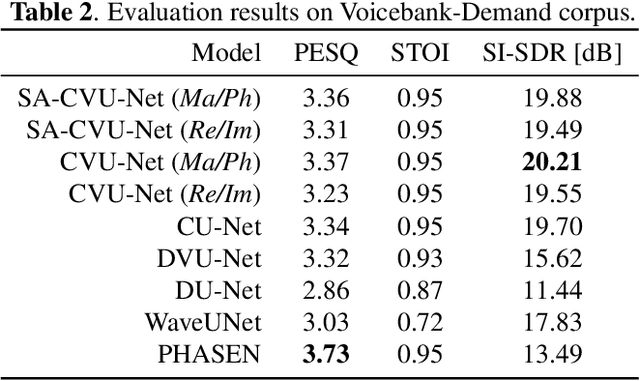
In this paper, we propose to extend the deep, complex U-Network architecture for speech enhancement by incorporating a probabilistic (i.e., variational) latent space model. The proposed model is evaluated against several ablated versions of itself in order to study the effects of the variational latent space model, complex-value processing, and self-attention. Evaluation on the MS-DNS 2020 and Voicebank+Demand datasets yields consistently high performance. E.g., the proposed model achieves an SI-SDR of up to 20.2 dB, about 0.5 to 1.4 dB higher than its ablated version without probabilistic latent space, 2-2.4 dB higher than WaveUNet, and 6.7 dB above PHASEN. Compared to real-valued magnitude spectrogram processing with a variational U-Net, the complex U-Net achieves an improvement of up to 4.5 dB SI-SDR. Complex spectrum encoding as magnitude and phase yields best performance in anechoic conditions whereas real and imaginary part representation results in better generalization to (novel) reverberation conditions, possibly due to the underlying physics of sound.
"We care": Improving Code Mixed Speech Emotion Recognition in Customer-Care Conversations
Aug 06, 2023Speech Emotion Recognition (SER) is the task of identifying the emotion expressed in a spoken utterance. Emotion recognition is essential in building robust conversational agents in domains such as law, healthcare, education, and customer support. Most of the studies published on SER use datasets created by employing professional actors in a noise-free environment. In natural settings such as a customer care conversation, the audio is often noisy with speakers regularly switching between different languages as they see fit. We have worked in collaboration with a leading unicorn in the Conversational AI sector to develop Natural Speech Emotion Dataset (NSED). NSED is a natural code-mixed speech emotion dataset where each utterance in a conversation is annotated with emotion, sentiment, valence, arousal, and dominance (VAD) values. In this paper, we show that by incorporating word-level VAD value we improve on the task of SER by 2%, for negative emotions, over the baseline value for NSED. High accuracy for negative emotion recognition is essential because customers expressing negative opinions/views need to be pacified with urgency, lest complaints and dissatisfaction snowball and get out of hand. Escalation of negative opinions speedily is crucial for business interests. Our study then can be utilized to develop conversational agents which are more polite and empathetic in such situations.