 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LC4SV: A Denoising Framework Learning to Compensate for Unseen Speaker Verification Models
Nov 28, 2023
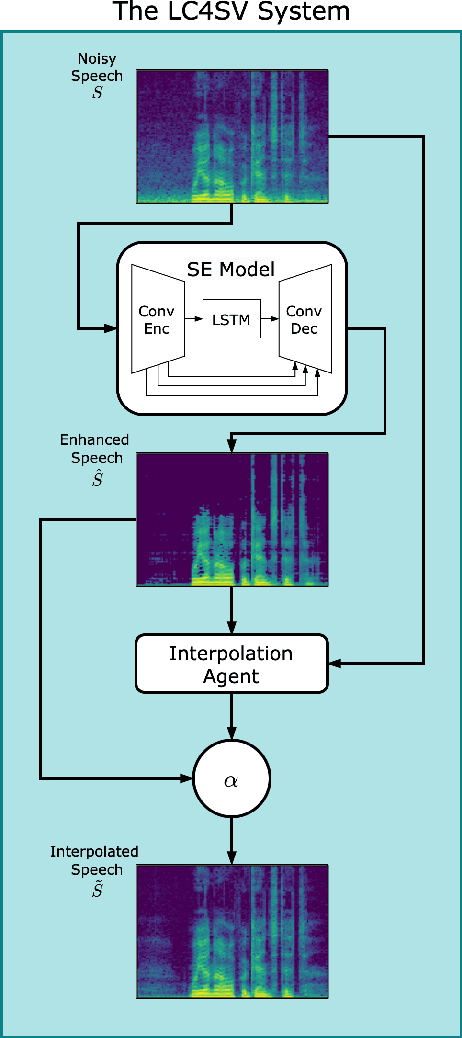
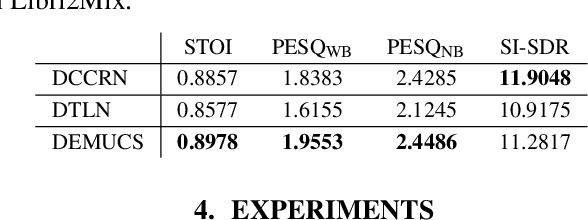
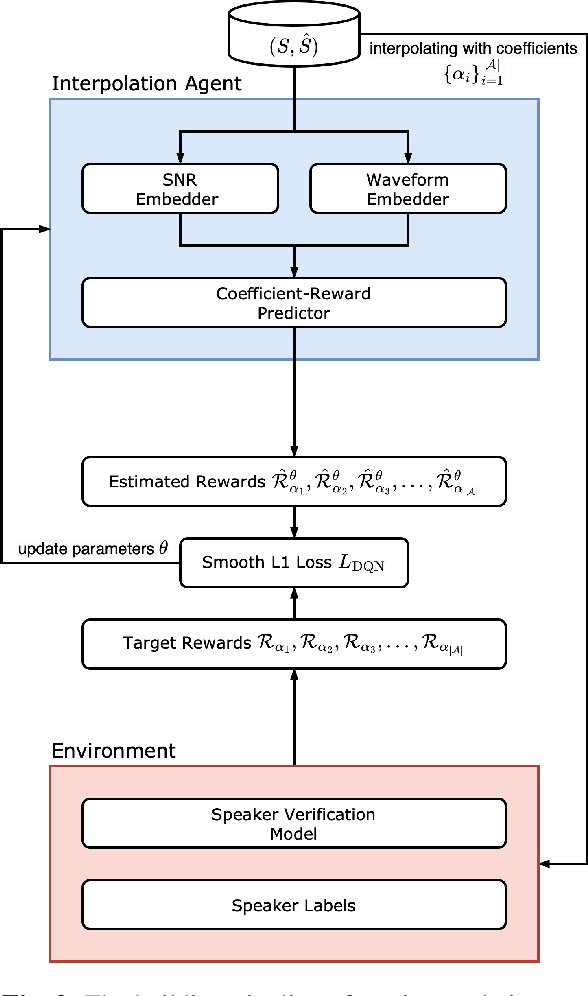
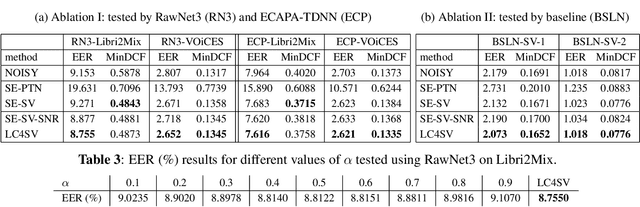
The performance of speaker verification (SV) models may drop dramatically in noisy environments. A speech enhancement (SE) module can be used as a front-end strategy. However, existing SE methods may fail to bring performance improvements to downstream SV systems due to artifacts in the predicted signals of SE models. To compensate for artifacts, we propose a generic denoising framework named LC4SV, which can serve as a pre-processor for various unknown downstream SV models. In LC4SV, we employ a learning-based interpolation agent to automatically generate the appropriate coefficients between the enhanced signal and its noisy input to improve SV performance in noisy environments. Our experimental results demonstrate that LC4SV consistently improves the performance of various unseen SV systems. To the best of our knowledge, this work is the first attempt to develop a learning-based interpolation scheme aiming at improving SV performance in noisy environments.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
Dec 02, 2023The big language model represented by ChatGPT has had a disruptive impact on the field of artificial intelligence. But it mainly focuses on Natural language processing, speech recognition, machine learning and natural-language understanding. This paper innovatively applies the big language model to the field of intelligent decision-making, places the big language model in the decision-making center, and constructs an agent architecture with the big language model as the core. Based on this, it further proposes a two-layer agent task planning, issues and executes decision commands through the interaction of natural language, and carries out simulation verification through the wargame simulation environment. Through the game confrontation simulation experiment, it is found that the intelligent decision-making ability of the big language model is significantly stronger than the commonly used reinforcement learning AI and rule AI, and the intelligence, understandability and generalization are all better. And through experiments, it was found that the intelligence of the large language model is closely related to prompt. This work also extends the large language model from previous human-computer interaction to the field of intelligent decision-making, which has important reference value and significance for the development of intelligent decision-making.
A Multiscale Autoencoder (MSAE) Framework for End-to-End Neural Network Speech Enhancement
Sep 21, 2023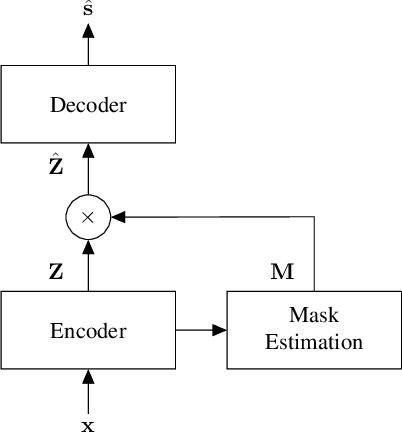
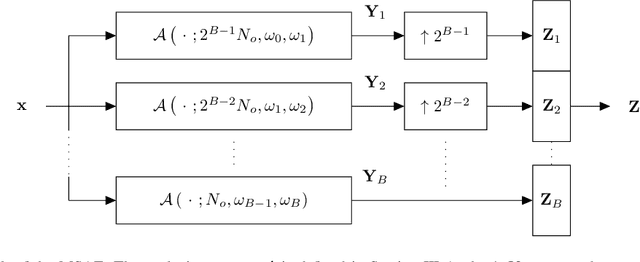
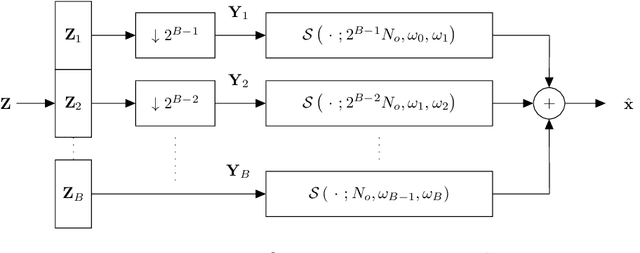
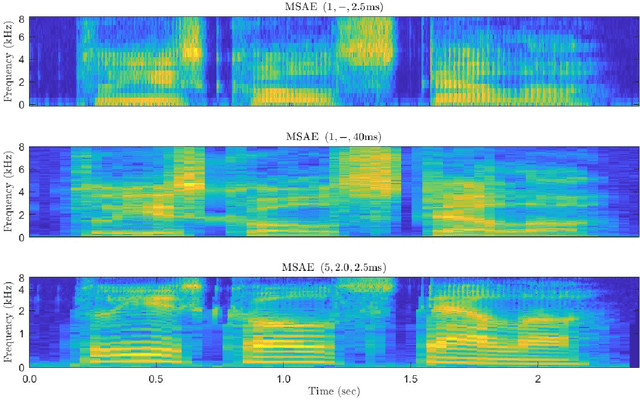
Neural network approaches to single-channel speech enhancement have received much recent attention. In particular, mask-based architectures have achieved significant performance improvements over conventional methods. This paper proposes a multiscale autoencoder (MSAE) for mask-based end-to-end neural network speech enhancement. The MSAE performs spectral decomposition of an input waveform within separate band-limited branches, each operating with a different rate and scale, to extract a sequence of multiscale embeddings. The proposed framework features intuitive parameterization of the autoencoder, including a flexible spectral band design based on the Constant-Q transform. Additionally, the MSAE is constructed entirely of differentiable operators, allowing it to be implemented within an end-to-end neural network, and be discriminatively trained. The MSAE draws motivation both from recent multiscale network topologies and from traditional multiresolution transforms in speech processing. Experimental results show the MSAE to provide clear performance benefits relative to conventional single-branch autoencoders. Additionally, the proposed framework is shown to outperform a variety of state-of-the-art enhancement systems, both in terms of objective speech quality metrics and automatic speech recognition accuracy.
FluentEditor: Text-based Speech Editing by Considering Acoustic and Prosody Consistency
Sep 22, 2023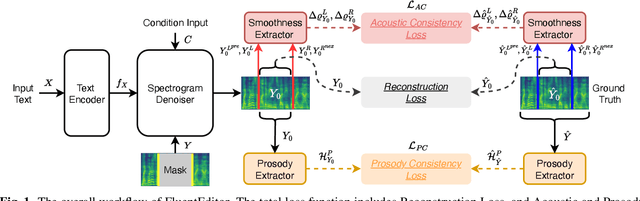
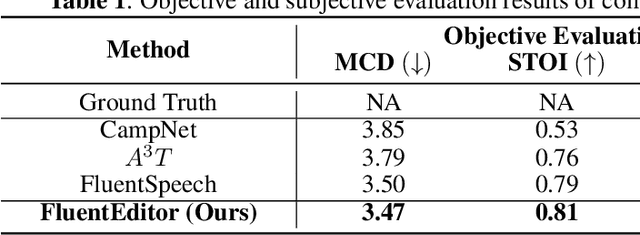
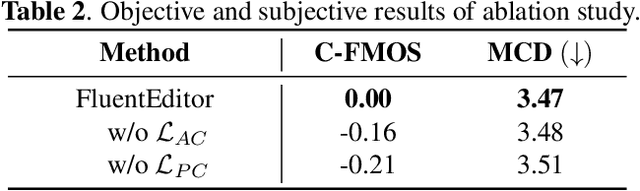
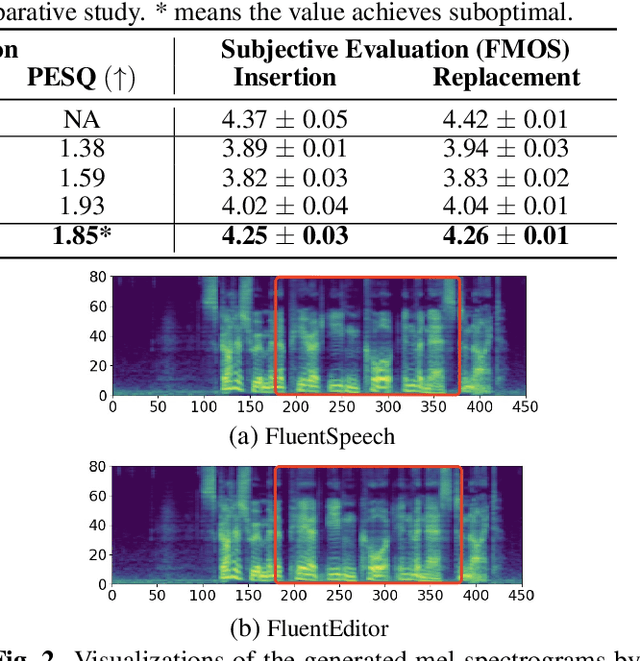
Text-based speech editing (TSE) techniques are designed to enable users to edit the output audio by modifying the input text transcript instead of the audio itself. Despite much progress in neural network-based TSE techniques, the current techniques have focused on reducing the difference between the generated speech segment and the reference target in the editing region, ignoring its local and global fluency in the context and original utterance. To maintain the speech fluency, we propose a fluency speech editing model, termed \textit{FluentEditor}, by considering fluency-aware training criterion in the TSE training. Specifically, the \textit{acoustic consistency constraint} aims to smooth the transition between the edited region and its neighboring acoustic segments consistent with the ground truth, while the \textit{prosody consistency constraint} seeks to ensure that the prosody attributes within the edited regions remain consistent with the overall style of the original utterance. The subjective and objective experimental results on VCTK demonstrate that our \textit{FluentEditor} outperforms all advanced baselines in terms of naturalness and fluency. The audio samples and code are available at \url{https://github.com/Ai-S2-Lab/FluentEditor}.
Acoustic and linguistic representations for speech continuous emotion recognition in call center conversations
Oct 06, 2023The goal of our research is to automatically retrieve the satisfaction and the frustration in real-life call-center conversations. This study focuses an industrial application in which the customer satisfaction is continuously tracked down to improve customer services. To compensate the lack of large annotated emotional databases, we explore the use of pre-trained speech representations as a form of transfer learning towards AlloSat corpus. Moreover, several studies have pointed out that emotion can be detected not only in speech but also in facial trait, in biological response or in textual information. In the context of telephone conversations, we can break down the audio information into acoustic and linguistic by using the speech signal and its transcription. Our experiments confirms the large gain in performance obtained with the use of pre-trained features. Surprisingly, we found that the linguistic content is clearly the major contributor for the prediction of satisfaction and best generalizes to unseen data. Our experiments conclude to the definitive advantage of using CamemBERT representations, however the benefit of the fusion of acoustic and linguistic modalities is not as obvious. With models learnt on individual annotations, we found that fusion approaches are more robust to the subjectivity of the annotation task. This study also tackles the problem of performances variability and intends to estimate this variability from different views: weights initialization, confidence intervals and annotation subjectivity. A deep analysis on the linguistic content investigates interpretable factors able to explain the high contribution of the linguistic modality for this task.
Learning from Flawed Data: Weakly Supervised Automatic Speech Recognition
Sep 26, 2023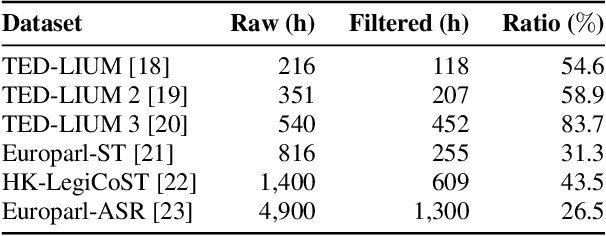
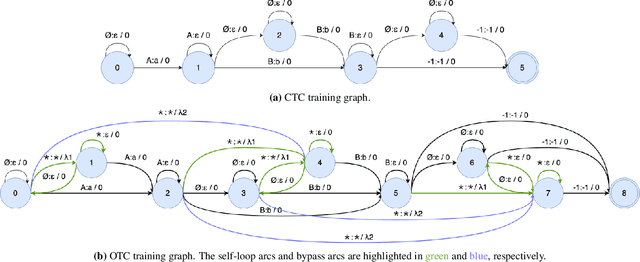
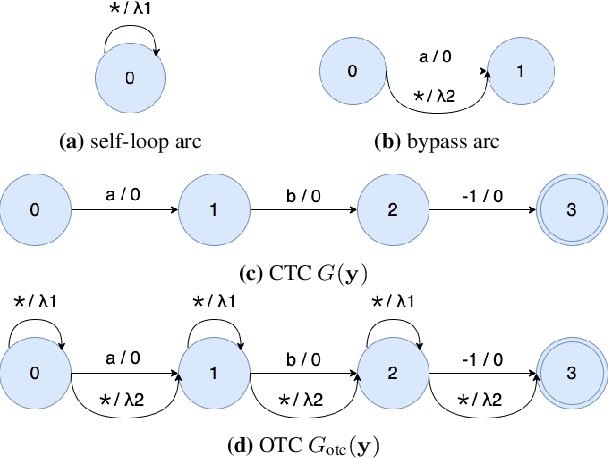

Training automatic speech recognition (ASR) systems requires large amounts of well-curated paired data. However, human annotators usually perform "non-verbatim" transcription, which can result in poorly trained models. In this paper, we propose Omni-temporal Classification (OTC), a novel training criterion that explicitly incorporates label uncertainties originating from such weak supervision. This allows the model to effectively learn speech-text alignments while accommodating errors present in the training transcripts. OTC extends the conventional CTC objective for imperfect transcripts by leveraging weighted finite state transducers. Through experiments conducted on the LibriSpeech and LibriVox datasets, we demonstrate that training ASR models with OTC avoids performance degradation even with transcripts containing up to 70% errors, a scenario where CTC models fail completely. Our implementation is available at https://github.com/k2-fsa/icefall.
Average Token Delay: A Duration-aware Latency Metric for Simultaneous Translation
Nov 27, 2023Simultaneous translation is a task in which the translation begins before the end of an input speech segment. Its evaluation should be conducted based on latency in addition to quality, and for users, the smallest possible amount of latency is preferable. Most existing metrics measure latency based on the start timings of partial translations and ignore their duration. This means such metrics do not penalize the latency caused by long translation output, which delays the comprehension of users and subsequent translations. In this work, we propose a novel latency evaluation metric for simultaneous translation called \emph{Average Token Delay} (ATD) that focuses on the duration of partial translations. We demonstrate its effectiveness through analyses simulating user-side latency based on Ear-Voice Span (EVS). In our experiment, ATD had the highest correlation with EVS among baseline latency metrics under most conditions.
Overview of the VLSP 2022 -- Abmusu Shared Task: A Data Challenge for Vietnamese Abstractive Multi-document Summarization
Nov 27, 2023This paper reports the overview of the VLSP 2022 - Vietnamese abstractive multi-document summarization (Abmusu) shared task for Vietnamese News. This task is hosted at the 9$^{th}$ annual workshop on Vietnamese Language and Speech Processing (VLSP 2022). The goal of Abmusu shared task is to develop summarization systems that could create abstractive summaries automatically for a set of documents on a topic. The model input is multiple news documents on the same topic, and the corresponding output is a related abstractive summary. In the scope of Abmusu shared task, we only focus on Vietnamese news summarization and build a human-annotated dataset of 1,839 documents in 600 clusters, collected from Vietnamese news in 8 categories. Participated models are evaluated and ranked in terms of \texttt{ROUGE2-F1} score, the most typical evaluation metric for document summarization problem.
Hate speech detection in algerian dialect using deep learning
Sep 20, 2023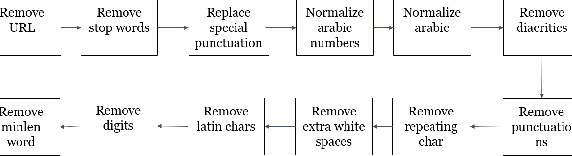
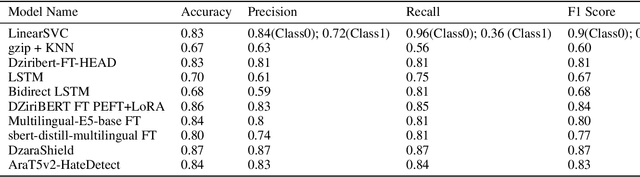
With the proliferation of hate speech on social networks under different formats, such as abusive language, cyberbullying, and violence, etc., people have experienced a significant increase in violence, putting them in uncomfortable situations and threats. Plenty of efforts have been dedicated in the last few years to overcome this phenomenon to detect hate speech in different structured languages like English, French, Arabic, and others. However, a reduced number of works deal with Arabic dialects like Tunisian, Egyptian, and Gulf, mainly the Algerian ones. To fill in the gap, we propose in this work a complete approach for detecting hate speech on online Algerian messages. Many deep learning architectures have been evaluated on the corpus we created from some Algerian social networks (Facebook, YouTube, and Twitter). This corpus contains more than 13.5K documents in Algerian dialect written in Arabic, labeled as hateful or non-hateful. Promising results are obtained, which show the efficiency of our approach.