 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREP: Resource-Efficient Prompting for On-device Continual Learning
Jun 07, 2024



On-device continual learning (CL) requires the co-optimization of model accuracy and resource efficiency to be practical. This is extremely challenging because it must preserve accuracy while learning new tasks with continuously drifting data and maintain both high energy and memory efficiency to be deployable on real-world devices. Typically, a CL method leverages one of two types of backbone networks: CNN or ViT. It is commonly believed that CNN-based CL excels in resource efficiency, whereas ViT-based CL is superior in model performance, making each option attractive only for a single aspect. In this paper, we revisit this comparison while embracing powerful pre-trained ViT models of various sizes, including ViT-Ti (5.8M parameters). Our detailed analysis reveals that many practical options exist today for making ViT-based methods more suitable for on-device CL, even when accuracy, energy, and memory are all considered. To further expand this impact, we introduce REP, which improves resource efficiency specifically targeting prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs throughout the training process. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing two novel algorithms-adaptive token merging (AToM) and adaptive layer dropping (ALD)-that optimize the prompt updating stage. In particular, AToM and ALD perform selective skipping across the data and model-layer dimensions without compromising task-specific features in vision transformer models. Extensive experiments on three image classification datasets validate REP's superior resource efficiency over current state-of-the-art methods.
Attention or Convolution: Transformer Encoders in Audio Language Models for Inference Efficiency
Nov 05, 2023


In this paper, we show that a simple self-supervised pre-trained audio model can achieve comparable inference efficiency to more complicated pre-trained models with speech transformer encoders. These speech transformers rely on mixing convolutional modules with self-attention modules. They achieve state-of-the-art performance on ASR with top efficiency. We first show that employing these speech transformers as an encoder significantly improves the efficiency of pre-trained audio models as well. However, our study shows that we can achieve comparable efficiency with advanced self-attention solely. We demonstrate that this simpler approach is particularly beneficial with a low-bit weight quantization technique of a neural network to improve efficiency. We hypothesize that it prevents propagating the errors between different quantized modules compared to recent speech transformers mixing quantized convolution and the quantized self-attention modules.
Empirical Study of Drone Sound Detection in Real-Life Environment with Deep Neural Networks
Jan 20, 2017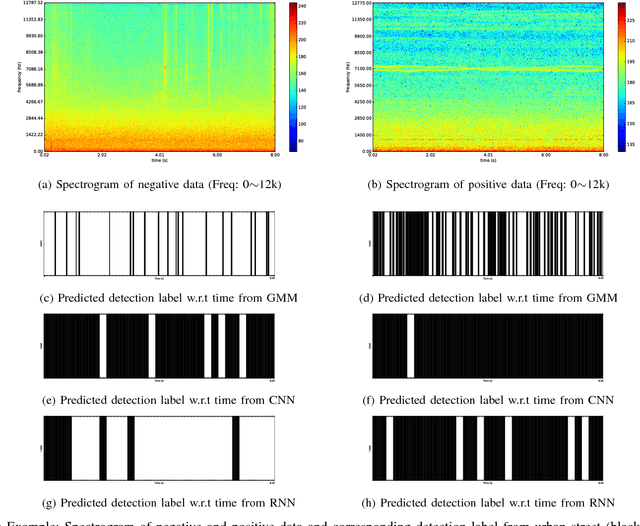
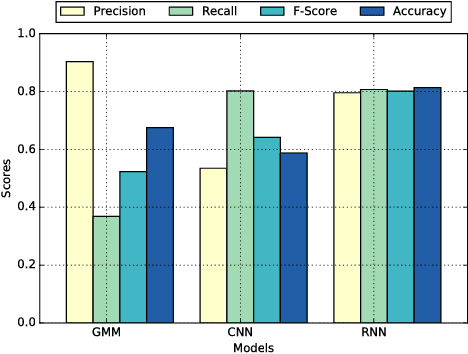
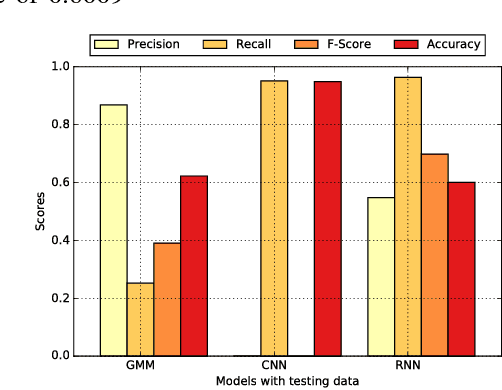

This work aims to investigate the use of deep neural network to detect commercial hobby drones in real-life environments by analyzing their sound data. The purpose of work is to contribute to a system for detecting drones used for malicious purposes, such as for terrorism. Specifically, we present a method capable of detecting the presence of commercial hobby drones as a binary classification problem based on sound event detection. We recorded the sound produced by a few popular commercial hobby drones, and then augmented this data with diverse environmental sound data to remedy the scarcity of drone sound data in diverse environments. We investigated the effectiveness of state-of-the-art event sound classification methods, i.e., a Gaussian Mixture Model (GMM), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), for drone sound detection. Our empirical results, which were obtained with a testing dataset collected on an urban street, confirmed the effectiveness of these models for operating in a real environment. In summary, our RNN models showed the best detection performance with an F-Score of 0.8009 with 240 ms of input audio with a short processing time, indicating their applicability to real-time detection systems.