 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
AKVSR: Audio Knowledge Empowered Visual Speech Recognition by Compressing Audio Knowledge of a Pretrained Model
Aug 15, 2023
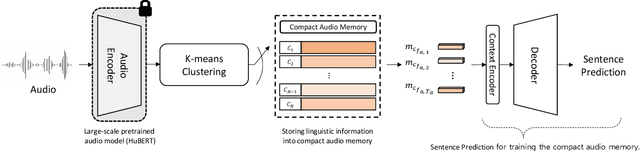
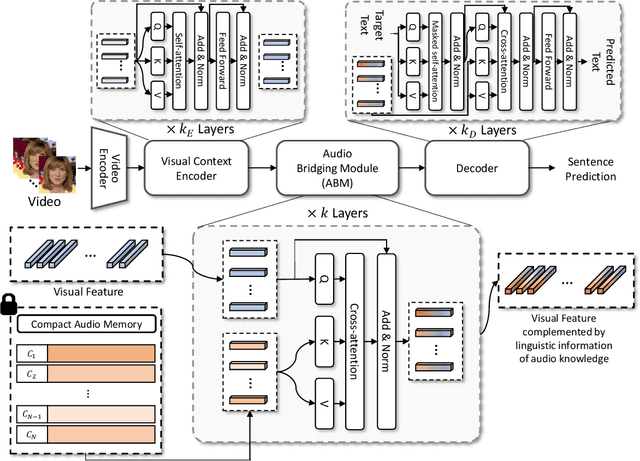
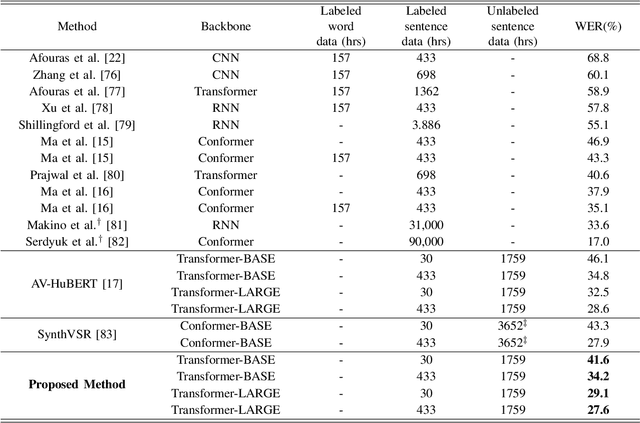
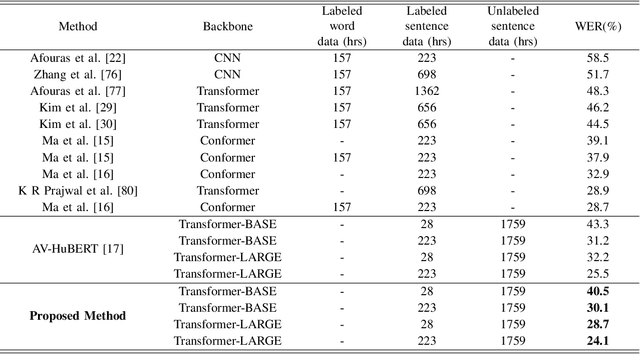
Visual Speech Recognition (VSR) is the task of predicting spoken words from silent lip movements. VSR is regarded as a challenging task because of the insufficient information on lip movements. In this paper, we propose an Audio Knowledge empowered Visual Speech Recognition framework (AKVSR) to complement the insufficient speech information of visual modality by using audio modality. Different from the previous methods, the proposed AKVSR 1) utilizes rich audio knowledge encoded by a large-scale pretrained audio model, 2) saves the linguistic information of audio knowledge in compact audio memory by discarding the non-linguistic information from the audio through quantization, and 3) includes Audio Bridging Module which can find the best-matched audio features from the compact audio memory, which makes our training possible without audio inputs, once after the compact audio memory is composed. We validate the effectiveness of the proposed method through extensive experiments, and achieve new state-of-the-art performances on the widely-used datasets, LRS2 and LRS3.
End-to-End Speech-to-Text Translation: A Survey
Dec 02, 2023Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
Utilizing Speech Emotion Recognition and Recommender Systems for Negative Emotion Handling in Therapy Chatbots
Nov 18, 2023Emotional well-being significantly influences mental health and overall quality of life. As therapy chatbots become increasingly prevalent, their ability to comprehend and respond empathetically to users' emotions remains limited. This paper addresses this limitation by proposing an approach to enhance therapy chatbots with auditory perception, enabling them to understand users' feelings and provide human-like empathy. The proposed method incorporates speech emotion recognition (SER) techniques using Convolutional Neural Network (CNN) models and the ShEMO dataset to accurately detect and classify negative emotions, including anger, fear, and sadness. The SER model achieves a validation accuracy of 88%, demonstrating its effectiveness in recognizing emotional states from speech signals. Furthermore, a recommender system is developed, leveraging the SER model's output to generate personalized recommendations for managing negative emotions, for which a new bilingual dataset was generated as well since there is no such dataset available for this task. The recommender model achieves an accuracy of 98% by employing a combination of global vectors for word representation (GloVe) and LSTM models. To provide a more immersive and empathetic user experience, a text-to-speech model called GlowTTS is integrated, enabling the therapy chatbot to audibly communicate the generated recommendations to users in both English and Persian. The proposed approach offers promising potential to enhance therapy chatbots by providing them with the ability to recognize and respond to users' emotions, ultimately improving the delivery of mental health support for both English and Persian-speaking users.
A Quantitative Approach to Understand Self-Supervised Models as Cross-lingual Feature Extractors
Nov 27, 2023In this work, we study the features extracted by English self-supervised learning (SSL) models in cross-lingual contexts and propose a new metric to predict the quality of feature representations. Using automatic speech recognition (ASR) as a downstream task, we analyze the effect of model size, training objectives, and model architecture on the models' performance as a feature extractor for a set of topologically diverse corpora. We develop a novel metric, the Phonetic-Syntax Ratio (PSR), to measure the phonetic and synthetic information in the extracted representations using deep generalized canonical correlation analysis. Results show the contrastive loss in the wav2vec2.0 objective facilitates more effective cross-lingual feature extraction. There is a positive correlation between PSR scores and ASR performance, suggesting that phonetic information extracted by monolingual SSL models can be used for downstream tasks in cross-lingual settings. The proposed metric is an effective indicator of the quality of the representations and can be useful for model selection.
Phonetic-aware speaker embedding for far-field speaker verification
Nov 27, 2023When a speaker verification (SV) system operates far from the sound sourced, significant challenges arise due to the interference of noise and reverberation. Studies have shown that incorporating phonetic information into speaker embedding can improve the performance of text-independent SV. Inspired by this observation, we propose a joint-training speech recognition and speaker recognition (JTSS) framework to exploit phonetic content for far-field SV. The framework encourages speaker embeddings to preserve phonetic information by matching the frame-based feature maps of a speaker embedding network with wav2vec's vectors. The intuition is that phonetic information can preserve low-level acoustic dynamics with speaker information and thus partly compensate for the degradation due to noise and reverberation. Results show that the proposed framework outperforms the standard speaker embedding on the VOiCES Challenge 2019 evaluation set and the VoxCeleb1 test set. This indicates that leveraging phonetic information under far-field conditions is effective for learning robust speaker representations.
End-to-end Joint Rich and Normalized ASR with a limited amount of rich training data
Nov 29, 2023Joint rich and normalized automatic speech recognition (ASR), that produces transcriptions both with and without punctuation and capitalization, remains a challenge. End-to-end (E2E) ASR models offer both convenience and the ability to perform such joint transcription of speech. Training such models requires paired speech and rich text data, which is not widely available. In this paper, we compare two different approaches to train a stateless Transducer-based E2E joint rich and normalized ASR system, ready for streaming applications, with a limited amount of rich labeled data. The first approach uses a language model to generate pseudo-rich transcriptions of normalized training data. The second approach uses a single decoder conditioned on the type of the output. The first approach leads to E2E rich ASR which perform better on out-of-domain data, with up to 9% relative reduction in errors. The second approach demonstrates the feasibility of an E2E joint rich and normalized ASR system using as low as 5% rich training data with moderate (2.42% absolute) increase in errors.
Discrete Audio Representation as an Alternative to Mel-Spectrograms for Speaker and Speech Recognition
Sep 19, 2023Discrete audio representation, aka audio tokenization, has seen renewed interest driven by its potential to facilitate the application of text language modeling approaches in audio domain. To this end, various compression and representation-learning based tokenization schemes have been proposed. However, there is limited investigation into the performance of compression-based audio tokens compared to well-established mel-spectrogram features across various speaker and speech related tasks. In this paper, we evaluate compression based audio tokens on three tasks: Speaker Verification, Diarization and (Multi-lingual) Speech Recognition. Our findings indicate that (i) the models trained on audio tokens perform competitively, on average within $1\%$ of mel-spectrogram features for all the tasks considered, and do not surpass them yet. (ii) these models exhibit robustness for out-of-domain narrowband data, particularly in speaker tasks. (iii) audio tokens allow for compression to 20x compared to mel-spectrogram features with minimal loss of performance in speech and speaker related tasks, which is crucial for low bit-rate applications, and (iv) the examined Residual Vector Quantization (RVQ) based audio tokenizer exhibits a low-pass frequency response characteristic, offering a plausible explanation for the observed results, and providing insight for future tokenizer designs.
Mask-CTC-based Encoder Pre-training for Streaming End-to-End Speech Recognition
Sep 09, 2023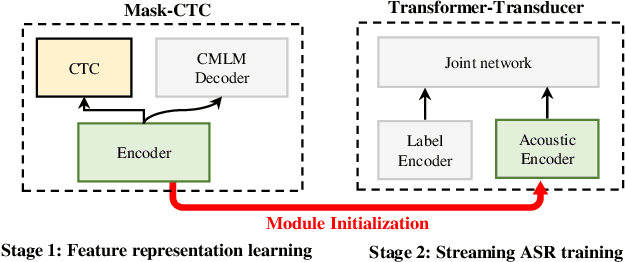
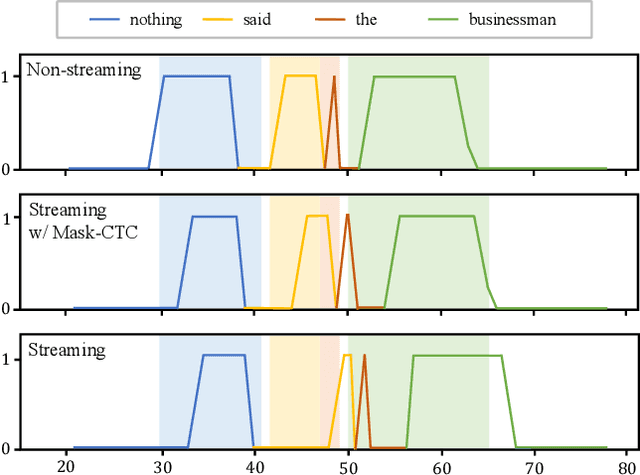
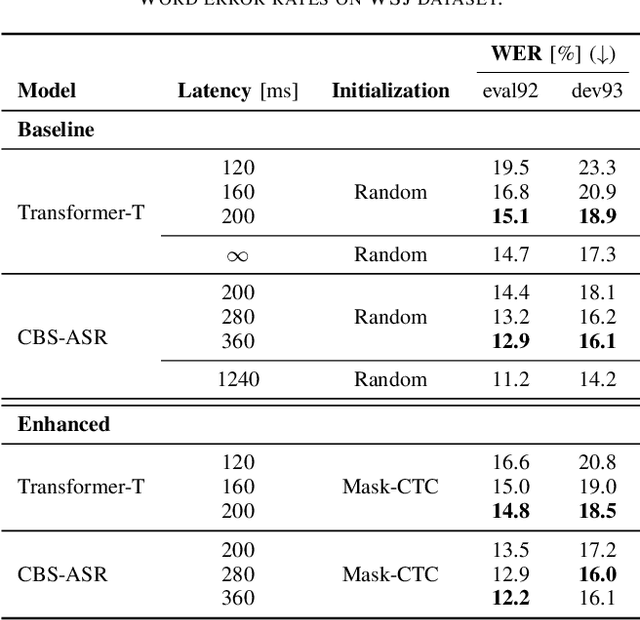

Achieving high accuracy with low latency has always been a challenge in streaming end-to-end automatic speech recognition (ASR) systems. By attending to more future contexts, a streaming ASR model achieves higher accuracy but results in larger latency, which hurts the streaming performance. In the Mask-CTC framework, an encoder network is trained to learn the feature representation that anticipates long-term contexts, which is desirable for streaming ASR. Mask-CTC-based encoder pre-training has been shown beneficial in achieving low latency and high accuracy for triggered attention-based ASR. However, the effectiveness of this method has not been demonstrated for various model architectures, nor has it been verified that the encoder has the expected look-ahead capability to reduce latency. This study, therefore, examines the effectiveness of Mask-CTCbased pre-training for models with different architectures, such as Transformer-Transducer and contextual block streaming ASR. We also discuss the effect of the proposed pre-training method on obtaining accurate output spike timing.
Self Generated Wargame AI: Double Layer Agent Task Planning Based on Large Language Model
Dec 02, 2023The big language model represented by ChatGPT has had a disruptive impact on the field of artificial intelligence. But it mainly focuses on Natural language processing, speech recognition, machine learning and natural-language understanding. This paper innovatively applies the big language model to the field of intelligent decision-making, places the big language model in the decision-making center, and constructs an agent architecture with the big language model as the core. Based on this, it further proposes a two-layer agent task planning, issues and executes decision commands through the interaction of natural language, and carries out simulation verification through the wargame simulation environment. Through the game confrontation simulation experiment, it is found that the intelligent decision-making ability of the big language model is significantly stronger than the commonly used reinforcement learning AI and rule AI, and the intelligence, understandability and generalization are all better. And through experiments, it was found that the intelligence of the large language model is closely related to prompt. This work also extends the large language model from previous human-computer interaction to the field of intelligent decision-making, which has important reference value and significance for the development of intelligent decision-making.
Unsupervised Active Learning: Optimizing Labeling Cost-Effectiveness for Automatic Speech Recognition
Aug 28, 2023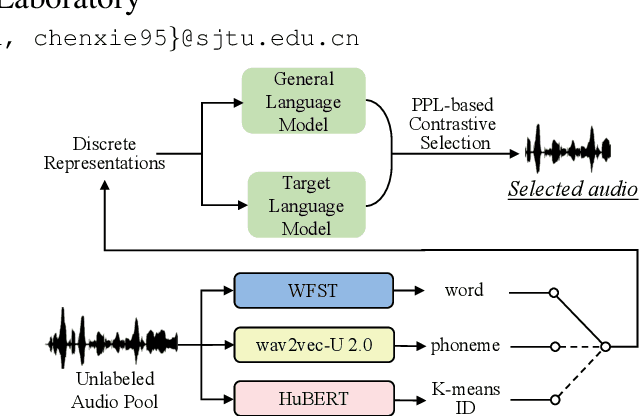
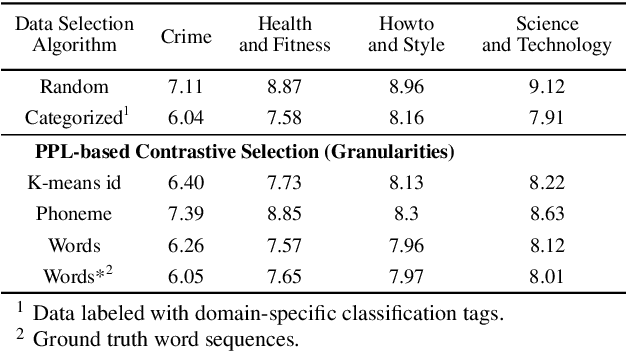
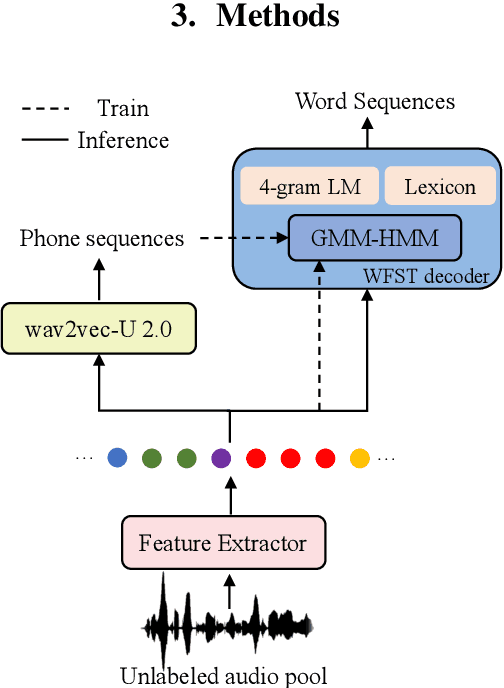
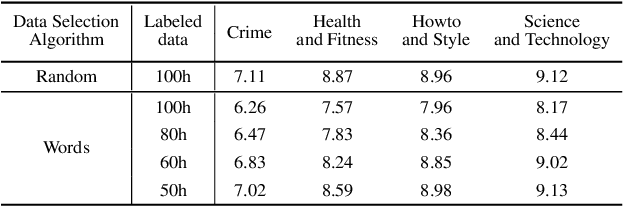
In recent years, speech-based self-supervised learning (SSL) has made significant progress in various tasks, including automatic speech recognition (ASR). An ASR model with decent performance can be realized by fine-tuning an SSL model with a small fraction of labeled data. Reducing the demand for labeled data is always of great practical value. In this paper, we further extend the use of SSL to cut down labeling costs with active learning. Three types of units on different granularities are derived from speech signals in an unsupervised way, and their effects are compared by applying a contrastive data selection method. The experimental results show that our proposed data selection framework can effectively improve the word error rate (WER) by more than 11% with the same amount of labeled data, or halve the labeling cost while maintaining the same WER, compared to random selection.