 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-ConvNeXt: A Lightweight and Efficient ConvNeXt Variant with Cross-Stage Partial Connections
Aug 28, 2025



Many high-performance networks were not designed with lightweight application scenarios in mind from the outset, which has greatly restricted their scope of application. This paper takes ConvNeXt as the research object and significantly reduces the parameter scale and network complexity of ConvNeXt by integrating the Cross Stage Partial Connections mechanism and a series of optimized designs. The new network is named E-ConvNeXt, which can maintain high accuracy performance under different complexity configurations. The three core innovations of E-ConvNeXt are : (1) integrating the Cross Stage Partial Network (CSPNet) with ConvNeXt and adjusting the network structure, which reduces the model's network complexity by up to 80%; (2) Optimizing the Stem and Block structures to enhance the model's feature expression capability and operational efficiency; (3) Replacing Layer Scale with channel attention. Experimental validation on ImageNet classification demonstrates E-ConvNeXt's superior accuracy-efficiency balance: E-ConvNeXt-mini reaches 78.3% Top-1 accuracy at 0.9GFLOPs. E-ConvNeXt-small reaches 81.9% Top-1 accuracy at 3.1GFLOPs. Transfer learning tests on object detection tasks further confirm its generalization capability.
A Quantitative Approach to Understand Self-Supervised Models as Cross-lingual Feature Extractors
Nov 27, 2023



In this work, we study the features extracted by English self-supervised learning (SSL) models in cross-lingual contexts and propose a new metric to predict the quality of feature representations. Using automatic speech recognition (ASR) as a downstream task, we analyze the effect of model size, training objectives, and model architecture on the models' performance as a feature extractor for a set of topologically diverse corpora. We develop a novel metric, the Phonetic-Syntax Ratio (PSR), to measure the phonetic and synthetic information in the extracted representations using deep generalized canonical correlation analysis. Results show the contrastive loss in the wav2vec2.0 objective facilitates more effective cross-lingual feature extraction. There is a positive correlation between PSR scores and ASR performance, suggesting that phonetic information extracted by monolingual SSL models can be used for downstream tasks in cross-lingual settings. The proposed metric is an effective indicator of the quality of the representations and can be useful for model selection.
Interpretable Charge Predictions for Criminal Cases: Learning to Generate Court Views from Fact Descriptions
Feb 23, 2018
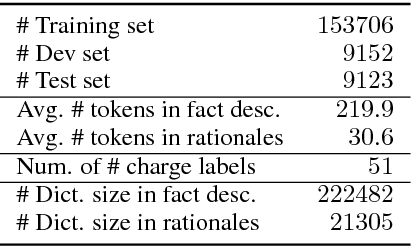
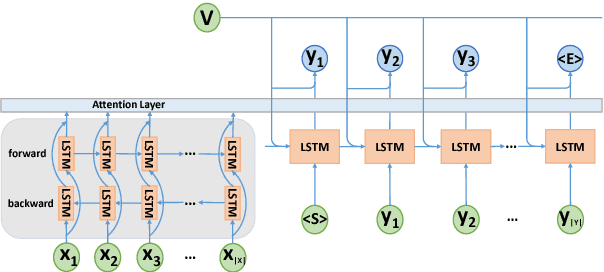
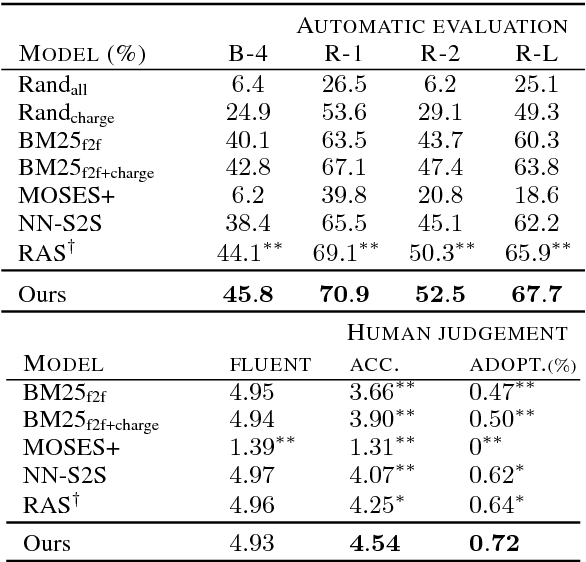
In this paper, we propose to study the problem of COURT VIEW GENeration from the fact description in a criminal case. The task aims to improve the interpretability of charge prediction systems and help automatic legal document generation. We formulate this task as a text-to-text natural language generation (NLG) problem. Sequenceto-sequence model has achieved cutting-edge performances in many NLG tasks. However, due to the non-distinctions of fact descriptions, it is hard for Seq2Seq model to generate charge-discriminative court views. In this work, we explore charge labels to tackle this issue. We propose a label-conditioned Seq2Seq model with attention for this problem, to decode court views conditioned on encoded charge labels. Experimental results show the effectiveness of our method.
Jointly Extracting Relations with Class Ties via Effective Deep Ranking
Aug 05, 2017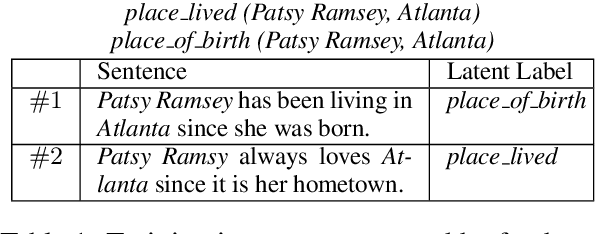
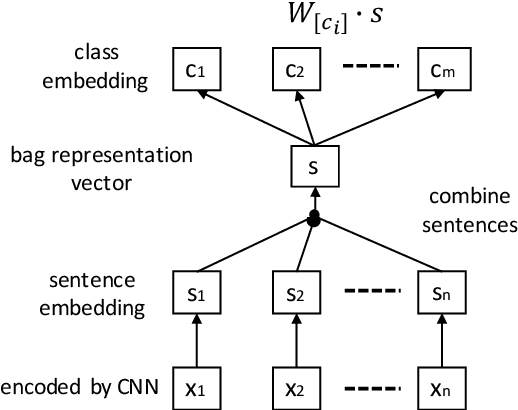
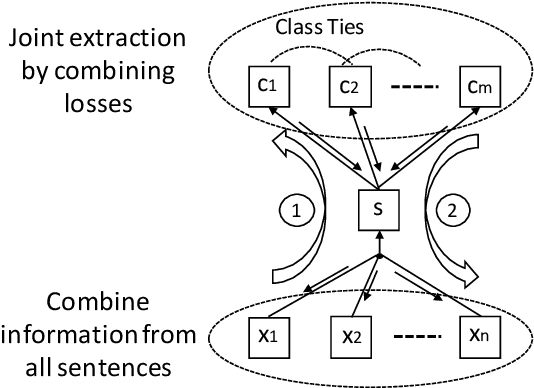
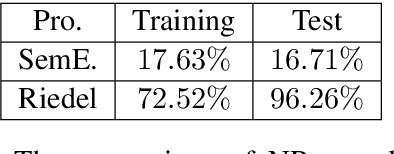
Connections between relations in relation extraction, which we call class ties, are common. In distantly supervised scenario, one entity tuple may have multiple relation facts. Exploiting class ties between relations of one entity tuple will be promising for distantly supervised relation extraction. However, previous models are not effective or ignore to model this property. In this work, to effectively leverage class ties, we propose to make joint relation extraction with a unified model that integrates convolutional neural network (CNN) with a general pairwise ranking framework, in which three novel ranking loss functions are introduced. Additionally, an effective method is presented to relieve the severe class imbalance problem from NR (not relation) for model training. Experiments on a widely used dataset show that leveraging class ties will enhance extraction and demonstrate the effectiveness of our model to learn class ties. Our model outperforms the baselines significantly, achieving state-of-the-art performance.