 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Spartus: A 9.4 TOp/s FPGA-based LSTM Accelerator Exploiting Spatio-temporal Sparsity
Aug 11, 2021
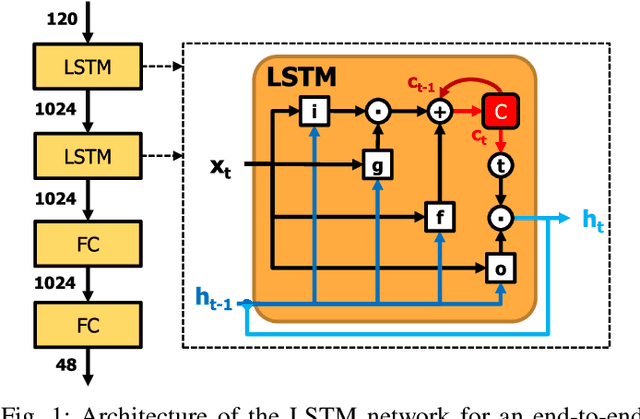
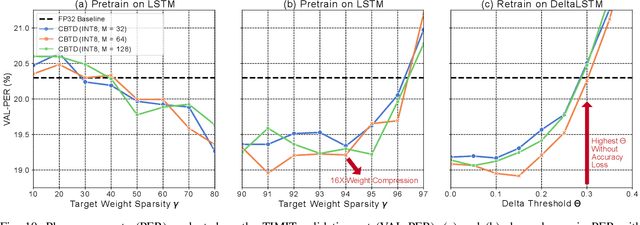
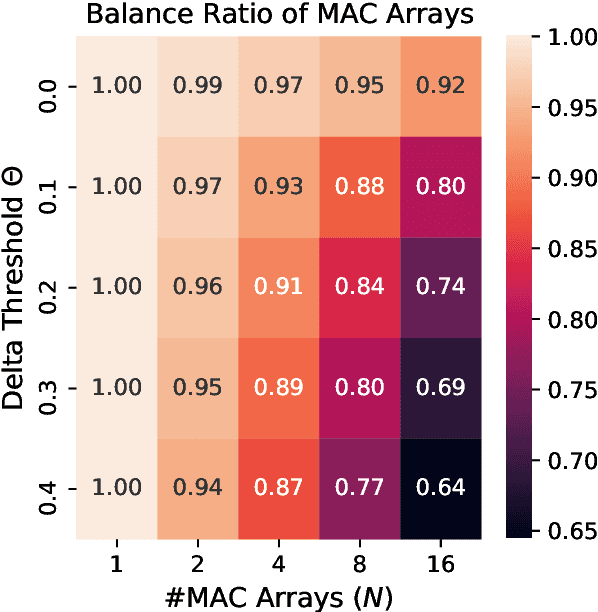
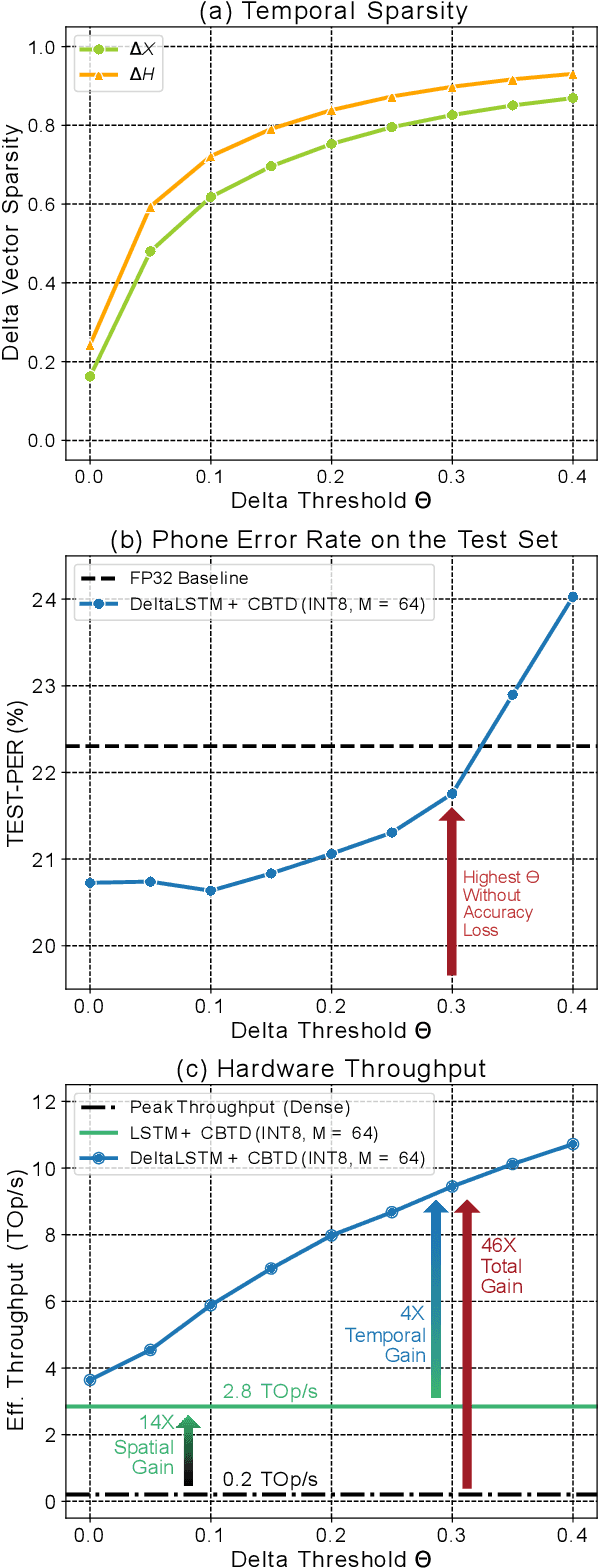
Long Short-Term Memory (LSTM) recurrent networks are frequently used for tasks involving time sequential data such as speech recognition. However, it is difficult to deploy these networks on hardware to achieve high throughput and low latency because the fully-connected structure makes LSTM networks a memory-bounded algorithm. Previous work in LSTM accelerators either exploited weight spatial sparsity or temporal sparsity. In this paper, we present a new accelerator called "Spartus" that exploits spatio-temporal sparsity to achieve ultra-low latency inference. The spatial sparsity was induced using our proposed pruning method called Column-Balanced Targeted Dropout (CBTD) that leads to structured sparse weight matrices benefiting workload balance. It achieved up to 96% weight sparsity with negligible accuracy difference for an LSTM network trained on a TIMIT phone recognition task. To induce temporal sparsity in LSTM, we create the DeltaLSTM by extending the previous DeltaGRU method to the LSTM network. This combined sparsity saves on weight memory access and associated arithmetic operations simultaneously. Spartus was implemented on a Xilinx Zynq-7100 FPGA. The per-sample latency for a single DeltaLSTM layer of 1024 neurons running on Spartus is 1 us. Spartus achieved 9.4 TOp/s effective batch-1 throughput and 1.1 TOp/J energy efficiency, which are respectively 4X and 7X higher than the previous state-of-the-art.
Protecting gender and identity with disentangled speech representations
Apr 22, 2021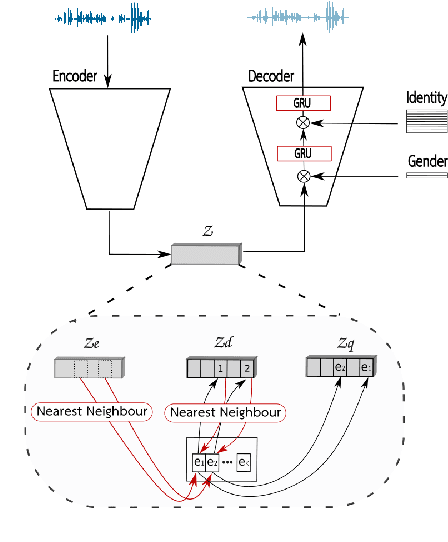
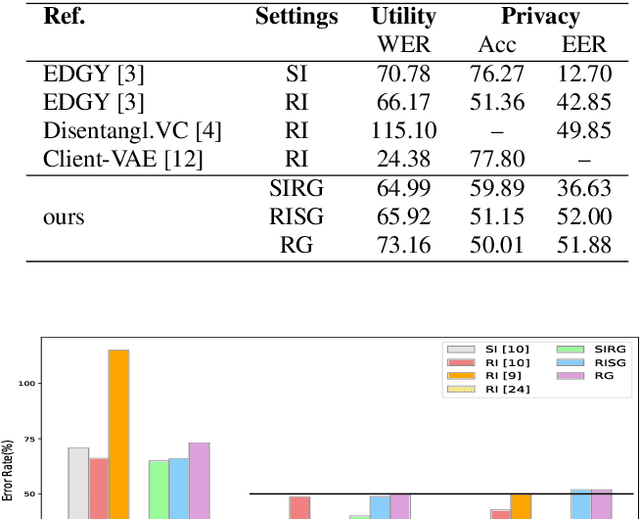
Besides its linguistic content, our speech is rich in biometric information that can be inferred by classifiers. Learning privacy-preserving representations for speech signals enables downstream tasks without sharing unnecessary, private information about an individual. In this paper, we show that protecting gender information in speech is more effective than modelling speaker-identity information only when generating a non-sensitive representation of speech. Our method relies on reconstructing speech by decoding linguistic content along with gender information using a variational autoencoder. Specifically, we exploit disentangled representation learning to encode information about different attributes into separate subspaces that can be factorised independently. We present a novel way to encode gender information and disentangle two sensitive biometric identifiers, namely gender and identity, in a privacy-protecting setting. Experiments on the LibriSpeech dataset show that gender recognition and speaker verification can be reduced to a random guess, protecting against classification-based attacks, while maintaining the utility of the signal for speech recognition.
Zero-Shot Joint Modeling of Multiple Spoken-Text-Style Conversion Tasks using Switching Tokens
Jun 23, 2021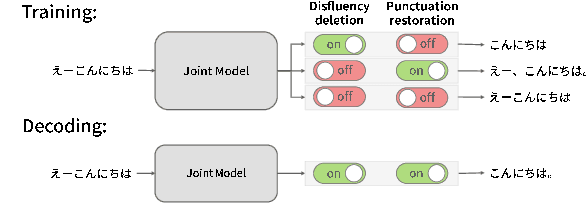
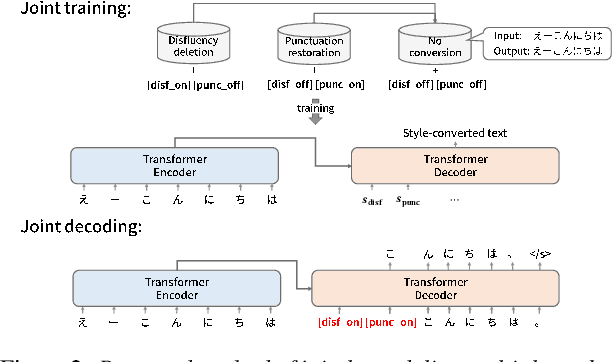
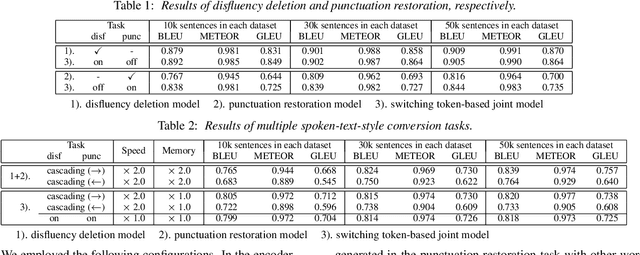
In this paper, we propose a novel spoken-text-style conversion method that can simultaneously execute multiple style conversion modules such as punctuation restoration and disfluency deletion without preparing matched datasets. In practice, transcriptions generated by automatic speech recognition systems are not highly readable because they often include many disfluencies and do not include punctuation marks. To improve their readability, multiple spoken-text-style conversion modules that individually model a single conversion task are cascaded because matched datasets that simultaneously handle multiple conversion tasks are often unavailable. However, the cascading is unstable against the order of tasks because of the chain of conversion errors. Besides, the computation cost of the cascading must be higher than the single conversion. To execute multiple conversion tasks simultaneously without preparing matched datasets, our key idea is to distinguish individual conversion tasks using the on-off switch. In our proposed zero-shot joint modeling, we switch the individual tasks using multiple switching tokens, enabling us to utilize a zero-shot learning approach to executing simultaneous conversions. Our experiments on joint modeling of disfluency deletion and punctuation restoration demonstrate the effectiveness of our method.
Disfluency Detection with Unlabeled Data and Small BERT Models
Apr 21, 2021
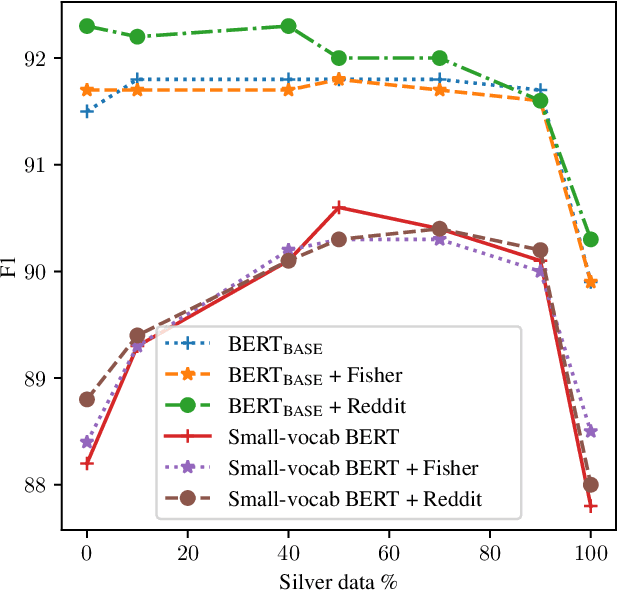
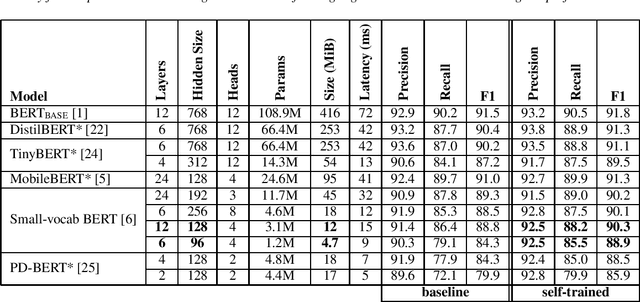
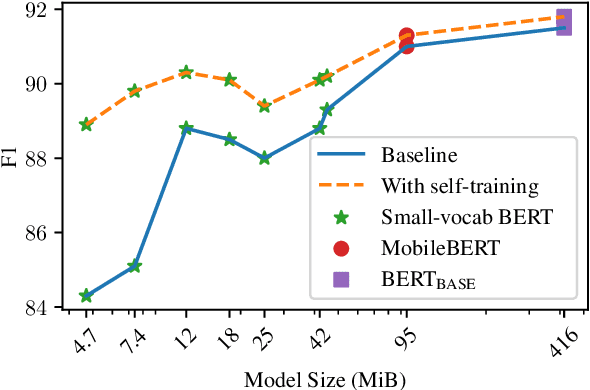
Disfluency detection models now approach high accuracy on English text. However, little exploration has been done in improving the size and inference time of the model. At the same time, automatic speech recognition (ASR) models are moving from server-side inference to local, on-device inference. Supporting models in the transcription pipeline (like disfluency detection) must follow suit. In this work we concentrate on the disfluency detection task, focusing on small, fast, on-device models based on the BERT architecture. We demonstrate it is possible to train disfluency detection models as small as 1.3 MiB, while retaining high performance. We build on previous work that showed the benefit of data augmentation approaches such as self-training. Then, we evaluate the effect of domain mismatch between conversational and written text on model performance. We find that domain adaptation and data augmentation strategies have a more pronounced effect on these smaller models, as compared to conventional BERT models.
Enhancing the Intelligibility of Cleft Lip and Palate Speech using Cycle-consistent Adversarial Networks
Jan 30, 2021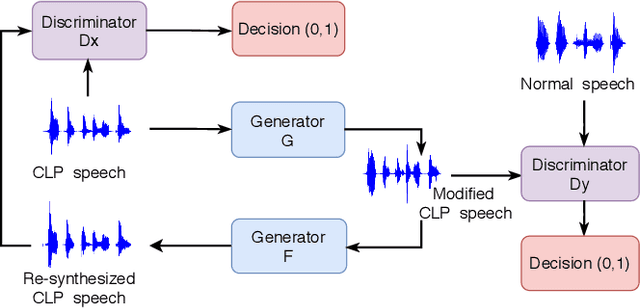
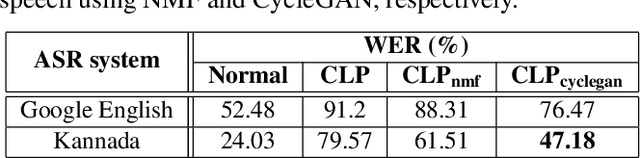
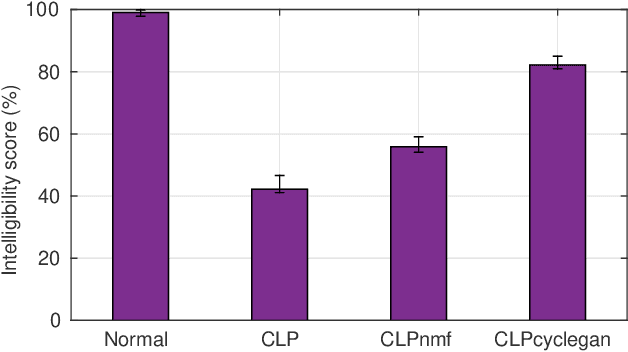
Cleft lip and palate (CLP) refer to a congenital craniofacial condition that causes various speech-related disorders. As a result of structural and functional deformities, the affected subjects' speech intelligibility is significantly degraded, limiting the accessibility and usability of speech-controlled devices. Towards addressing this problem, it is desirable to improve the CLP speech intelligibility. Moreover, it would be useful during speech therapy. In this study, the cycle-consistent adversarial network (CycleGAN) method is exploited for improving CLP speech intelligibility. The model is trained on native Kannada-speaking childrens' speech data. The effectiveness of the proposed approach is also measured using automatic speech recognition performance. Further, subjective evaluation is performed, and those results also confirm the intelligibility improvement in the enhanced speech over the original.
FedScale: Benchmarking Model and System Performance of Federated Learning
May 24, 2021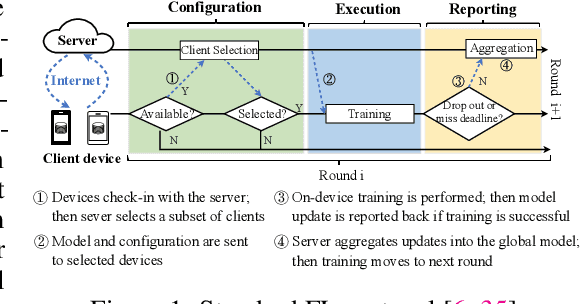
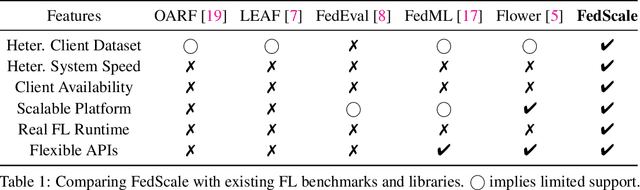
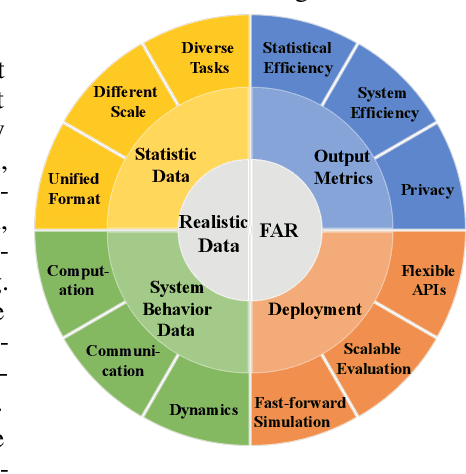
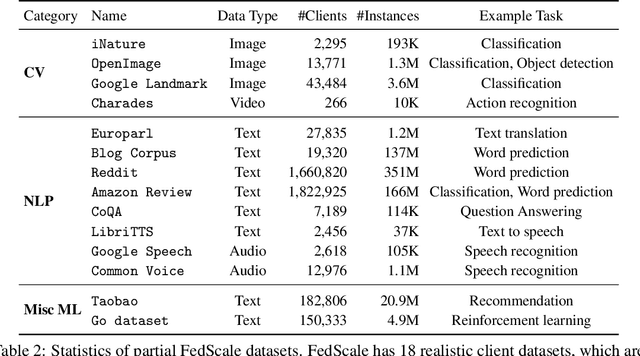
We present FedScale, a diverse set of challenging and realistic benchmark datasets to facilitate scalable, comprehensive, and reproducible federated learning (FL) research. FedScale datasets are large-scale, encompassing a diverse range of important FL tasks, such as image classification, object detection, language modeling, speech recognition, and reinforcement learning. For each dataset, we provide a unified evaluation protocol using realistic data splits and evaluation metrics. To meet the pressing need for reproducing realistic FL at scale, we have also built an efficient evaluation platform to simplify and standardize the process of FL experimental setup and model evaluation. Our evaluation platform provides flexible APIs to implement new FL algorithms and include new execution backends with minimal developer efforts. Finally, we perform indepth benchmark experiments on these datasets. Our experiments suggest that FedScale presents significant challenges of heterogeneity-aware co-optimizations of the system and statistical efficiency under realistic FL characteristics, indicating fruitful opportunities for future research. FedScale is open-source with permissive licenses and actively maintained, and we welcome feedback and contributions from the community.
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
Jun 21, 2021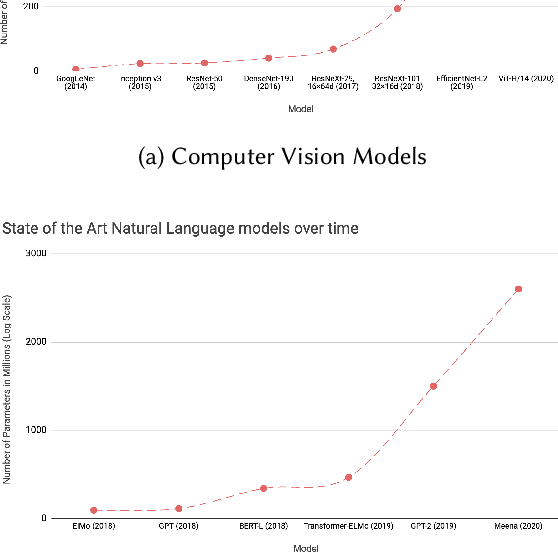
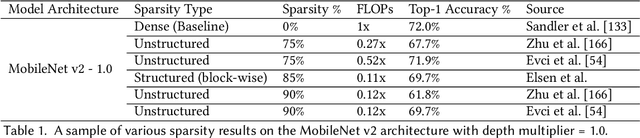
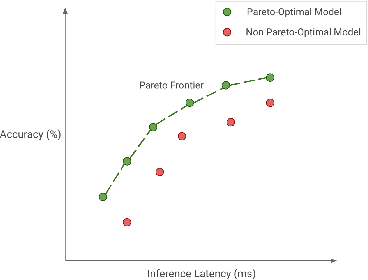

Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. However, with the progressive improvements in deep learning models, their number of parameters, latency, resources required to train, etc. have all have increased significantly. Consequently, it has become important to pay attention to these footprint metrics of a model as well, not just its quality. We present and motivate the problem of efficiency in deep learning, followed by a thorough survey of the five core areas of model efficiency (spanning modeling techniques, infrastructure, and hardware) and the seminal work there. We also present an experiment-based guide along with code, for practitioners to optimize their model training and deployment. We believe this is the first comprehensive survey in the efficient deep learning space that covers the landscape of model efficiency from modeling techniques to hardware support. Our hope is that this survey would provide the reader with the mental model and the necessary understanding of the field to apply generic efficiency techniques to immediately get significant improvements, and also equip them with ideas for further research and experimentation to achieve additional gains.
Convo: What does conversational programming need? An exploration of machine learning interface design
Mar 03, 2020
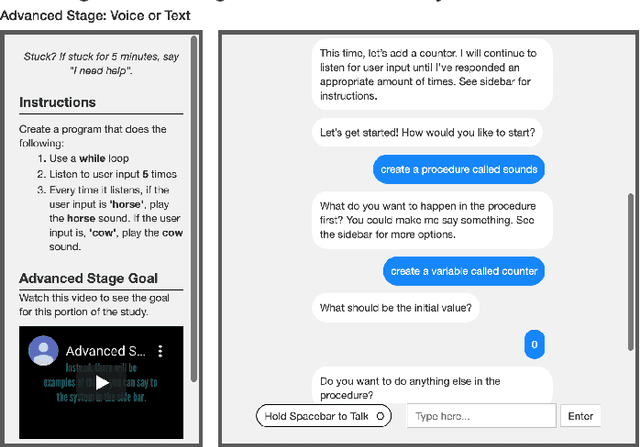
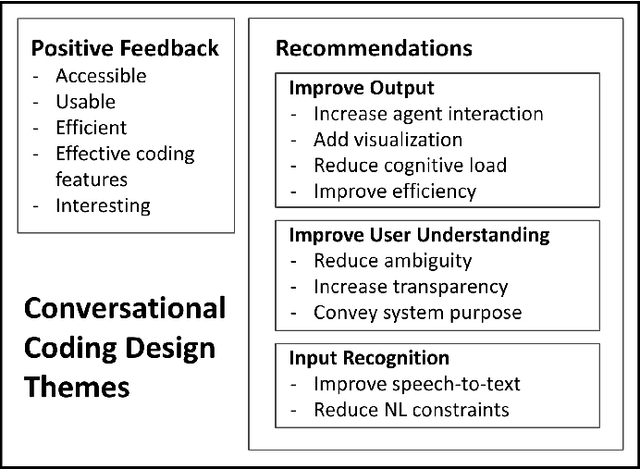
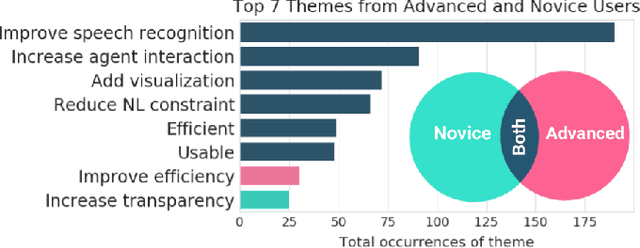
Vast improvements in natural language understanding and speech recognition have paved the way for conversational interaction with computers. While conversational agents have often been used for short goal-oriented dialog, we know little about agents for developing computer programs. To explore the utility of natural language for programming, we conducted a study ($n$=45) comparing different input methods to a conversational programming system we developed. Participants completed novice and advanced tasks using voice-based, text-based, and voice-or-text-based systems. We found that users appreciated aspects of each system (e.g., voice-input efficiency, text-input precision) and that novice users were more optimistic about programming using voice-input than advanced users. Our results show that future conversational programming tools should be tailored to users' programming experience and allow users to choose their preferred input mode. To reduce cognitive load, future interfaces can incorporate visualizations and possess custom natural language understanding and speech recognition models for programming.
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020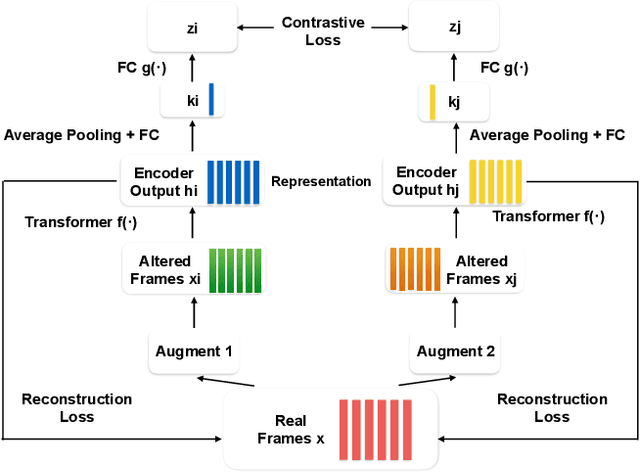

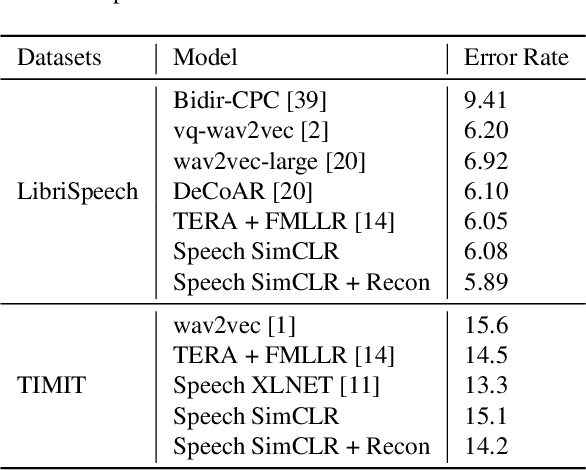

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.
Multi-task Learning with Cross Attention for Keyword Spotting
Jul 15, 2021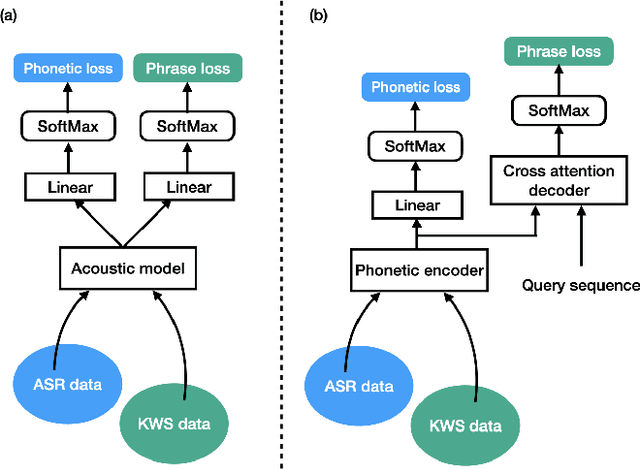
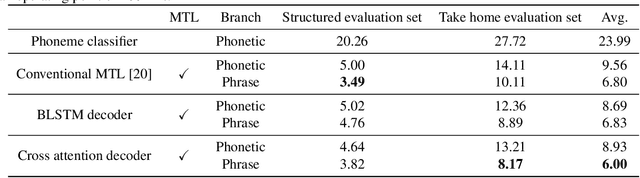
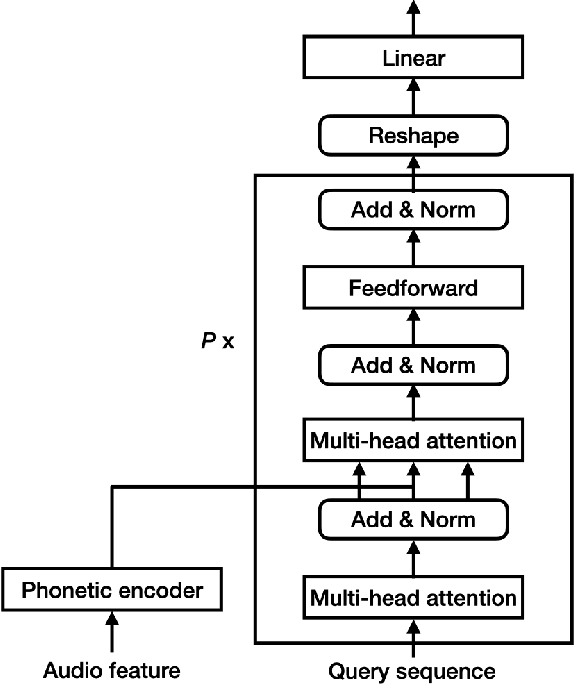
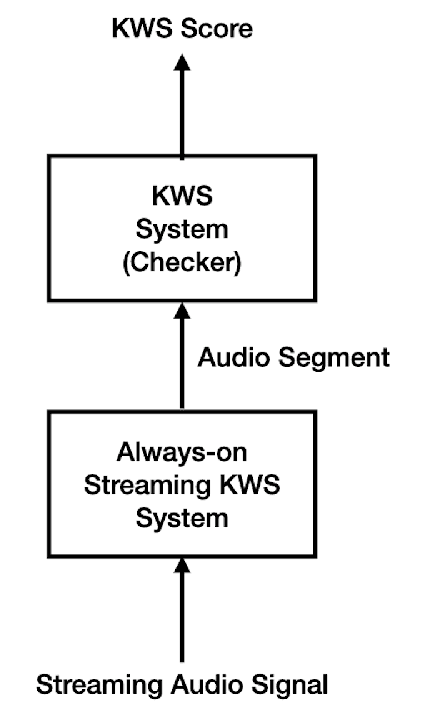
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase. Although a phoneme classifier can be used for KWS, exploiting a large amount of transcribed data for automatic speech recognition (ASR), there is a mismatch between the training criterion (phoneme recognition) and the target task (KWS). Recently, multi-task learning has been applied to KWS to exploit both ASR and KWS training data. In this approach, an output of an acoustic model is split into two branches for the two tasks, one for phoneme transcription trained with the ASR data and one for keyword classification trained with the KWS data. In this paper, we introduce a cross attention decoder in the multi-task learning framework. Unlike the conventional multi-task learning approach with the simple split of the output layer, the cross attention decoder summarizes information from a phonetic encoder by performing cross attention between the encoder outputs and a trainable query sequence to predict a confidence score for the KWS task. Experimental results on KWS tasks show that the proposed approach outperformed the conventional multi-task learning with split branches and a bi-directional long short-team memory decoder by 12% on average.