 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-based Graph Privacy Advisor
Oct 20, 2022
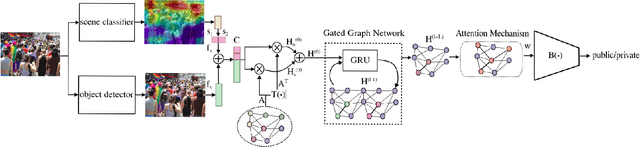


People may be unaware of the privacy risks of uploading an image online. In this paper, we present an image privacy classifier that uses scene information and object cardinality as cues for the prediction of image privacy. Our Graph Privacy Advisor (GPA) model simplifies a state-of-the-art graph model and improves its performance by refining the relevance of the content-based information extracted from the image. We determine the most informative visual features to be used for the privacy classification task and reduce the complexity of the model by replacing high-dimensional image-based feature vectors with lower-dimensional, more effective features. We also address the biased prior information by modelling object co-occurrences instead of the frequency of object occurrences in each class.
Generating gender-ambiguous voices for privacy-preserving speech recognition
Jul 03, 2022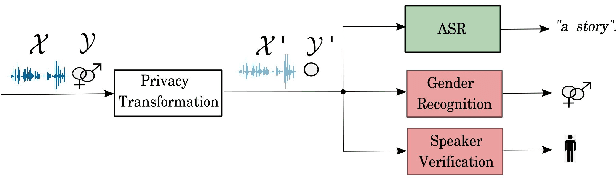
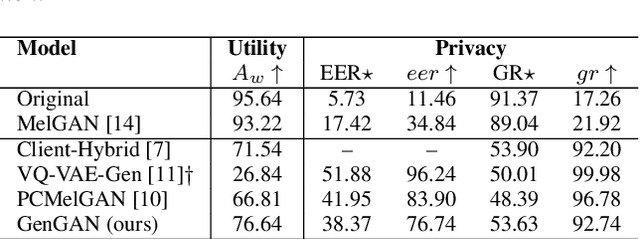
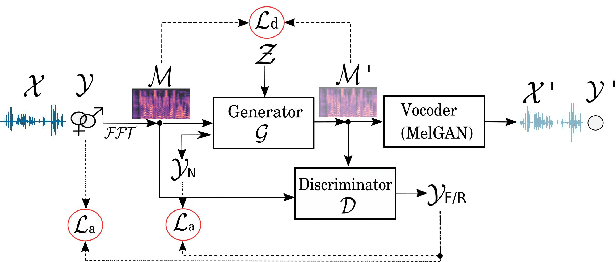
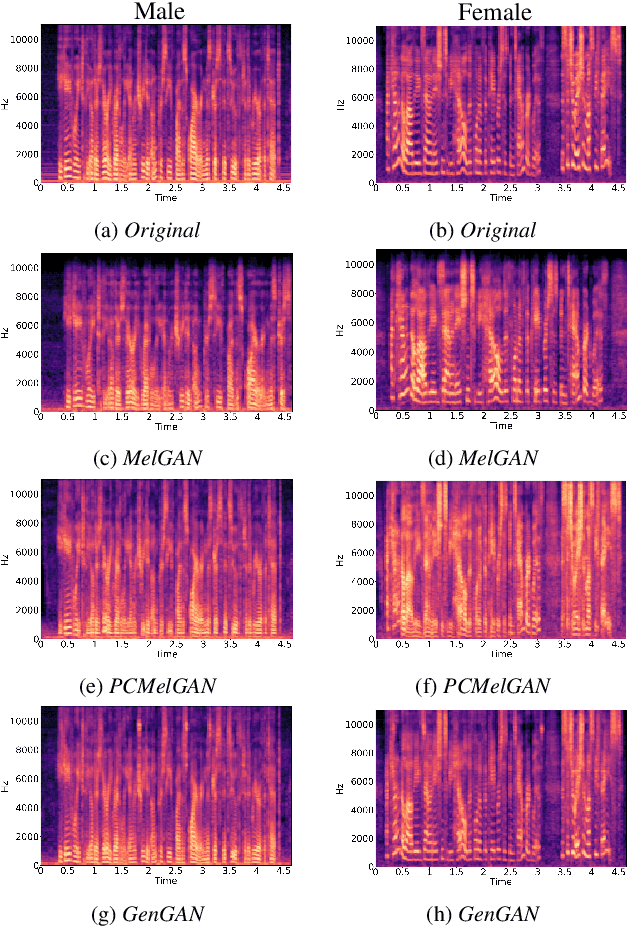
Our voice encodes a uniquely identifiable pattern which can be used to infer private attributes, such as gender or identity, that an individual might wish not to reveal when using a speech recognition service. To prevent attribute inference attacks alongside speech recognition tasks, we present a generative adversarial network, GenGAN, that synthesises voices that conceal the gender or identity of a speaker. The proposed network includes a generator with a U-Net architecture that learns to fool a discriminator. We condition the generator only on gender information and use an adversarial loss between signal distortion and privacy preservation. We show that GenGAN improves the trade-off between privacy and utility compared to privacy-preserving representation learning methods that consider gender information as a sensitive attribute to protect.
Protecting gender and identity with disentangled speech representations
Apr 22, 2021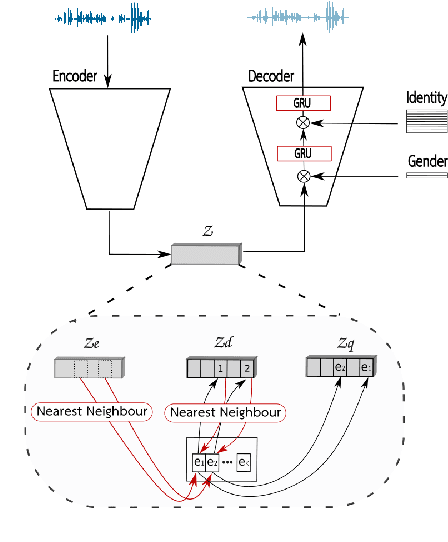
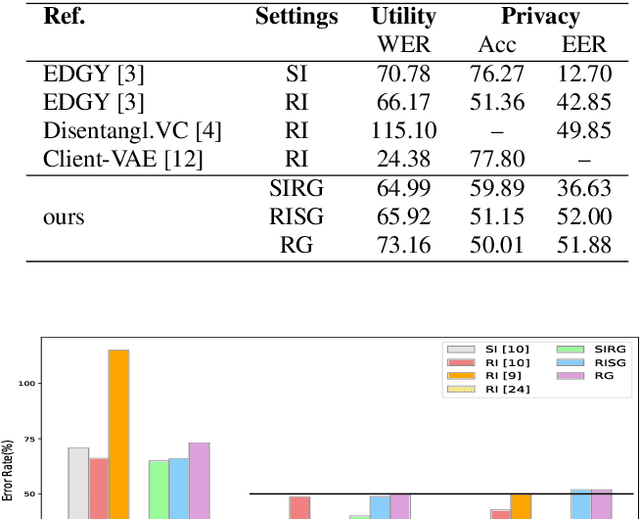
Besides its linguistic content, our speech is rich in biometric information that can be inferred by classifiers. Learning privacy-preserving representations for speech signals enables downstream tasks without sharing unnecessary, private information about an individual. In this paper, we show that protecting gender information in speech is more effective than modelling speaker-identity information only when generating a non-sensitive representation of speech. Our method relies on reconstructing speech by decoding linguistic content along with gender information using a variational autoencoder. Specifically, we exploit disentangled representation learning to encode information about different attributes into separate subspaces that can be factorised independently. We present a novel way to encode gender information and disentangle two sensitive biometric identifiers, namely gender and identity, in a privacy-protecting setting. Experiments on the LibriSpeech dataset show that gender recognition and speaker verification can be reduced to a random guess, protecting against classification-based attacks, while maintaining the utility of the signal for speech recognition.