 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nash Equilibrium Framework For Training-Free Multimodal Step Verification
May 19, 2026Multimodal large language models often generate reasoning chains containing subtle errors that lead to incorrect answers. Current verification approaches have notable limitations. Learned critics need extensive labeled data and show inconsistent performance across different tasks. Meanwhile, existing training-free methods simply average scores from different sources, missing a key insight: when these scores disagree, that disagreement itself carries important information about whether a reasoning step is truly valid or not. We propose a training-free verification approach that treats step-wise verification as a coordination problem among specialized judges. We formalize these judges' interaction as a Nash equilibrium game where agreement signals valid steps while disagreement reveals instability. Our method computes equilibrium scores through a closed-form solution, enabling both disagreement-aware filtering and stability-conscious ranking of reasoning steps. Evaluated across six benchmarks, our approach achieves consistent improvements of 2.4% to 5.2% over baseline models and shows competitive performance against learned critics, demonstrating that cross-modal agreement (not just average confidence) provides robust verification signals without task-specific adaptation.
Faithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
Apr 09, 2026Multimodal reasoning models (MRMs) trained with reinforcement learning with verifiable rewards (RLVR) show improved accuracy on visual reasoning benchmarks. However, we observe that accuracy gains often come at the cost of reasoning quality: generated Chain-of-Thought (CoT) traces are frequently inconsistent with the final answer and poorly grounded in the visual evidence. We systematically study this phenomenon across seven challenging real-world spatial reasoning benchmarks and find that it affects contemporary MRMs such as ViGoRL-Spatial, TreeVGR as well as our own models trained with standard Group Relative Policy Optimization (GRPO). We characterize CoT reasoning quality along two complementary axes: "logical consistency" (does the CoT entail the final answer?) and "visual grounding" (does each reasoning step accurately describe objects, attributes, and spatial relationships in the image?). To address this, we propose Faithful GRPO (FGRPO), a variant of GRPO that enforces consistency and grounding as constraints via Lagrangian dual ascent. FGRPO incorporates batch-level consistency and grounding constraints into the advantage computation within a group, adaptively adjusting the relative importance of constraints during optimization. We evaluate FGRPO on Qwen2.5-VL-7B and 3B backbones across seven spatial datasets. Our results show that FGRPO substantially improves reasoning quality, reducing the inconsistency rate from 24.5% to 1.7% and improving visual grounding scores by +13%. It also improves final answer accuracy over simple GRPO, demonstrating that faithful reasoning enables better answers.
Towards Prosodically Informed Mizo TTS without Explicit Tone Markings
Jan 05, 2026This paper reports on the development of a text-to-speech (TTS) system for Mizo, a low-resource, tonal, and Tibeto-Burman language spoken primarily in the Indian state of Mizoram. The TTS was built with only 5.18 hours of data; however, in terms of subjective and objective evaluations, the outputs were considered perceptually acceptable and intelligible. A baseline model using Tacotron2 was built, and then, with the same data, another TTS model was built with VITS. In both subjective and objective evaluations, the VITS model outperformed the Tacotron2 model. In terms of tone synthesis, the VITS model showed significantly lower tone errors than the Tacotron2 model. The paper demonstrates that a non-autoregressive, end-to-end framework can achieve synthesis of acceptable perceptual quality and intelligibility.
Exploring the Task-agnostic Trait of Self-supervised Learning in the Context of Detecting Mental Disorders
Mar 22, 2024Self-supervised learning (SSL) has been investigated to generate task-agnostic representations across various domains. However, such investigation has not been conducted for detecting multiple mental disorders. The rationale behind the existence of a task-agnostic representation lies in the overlapping symptoms among multiple mental disorders. Consequently, the behavioural data collected for mental health assessment may carry a mixed bag of attributes related to multiple disorders. Motivated by that, in this study, we explore a task-agnostic representation derived through SSL in the context of detecting major depressive disorder (MDD) and post-traumatic stress disorder (PTSD) using audio and video data collected during interactive sessions. This study employs SSL models trained by predicting multiple fixed targets or masked frames. We propose a list of fixed targets to make the generated representation more efficient for detecting MDD and PTSD. Furthermore, we modify the hyper-parameters of the SSL encoder predicting fixed targets to generate global representations that capture varying temporal contexts. Both these innovations are noted to yield improved detection performances for considered mental disorders and exhibit task-agnostic traits. In the context of the SSL model predicting masked frames, the generated global representations are also noted to exhibit task-agnostic traits.
Analyzing the Effect of Data Impurity on the Detection Performances of Mental Disorders
Aug 09, 2023The primary method for identifying mental disorders automatically has traditionally involved using binary classifiers. These classifiers are trained using behavioral data obtained from an interview setup. In this training process, data from individuals with the specific disorder under consideration are categorized as the positive class, while data from all other participants constitute the negative class. In practice, it is widely recognized that certain mental disorders share similar symptoms, causing the collected behavioral data to encompass a variety of attributes associated with multiple disorders. Consequently, attributes linked to the targeted mental disorder might also be present within the negative class. This data impurity may lead to sub-optimal training of the classifier for a mental disorder of interest. In this study, we investigate this hypothesis in the context of major depressive disorder (MDD) and post-traumatic stress disorder detection (PTSD). The results show that upon removal of such data impurity, MDD and PTSD detection performances are significantly improved.
Exploring the Role of Emotion Regulation Difficulties in the Assessment of Mental Disorders
Aug 04, 2022



Several studies have been reported in the literature for the automatic detection of mental disorders. It is reported that mental disorders are highly correlated. The exploration of this fact for the automatic detection of mental disorders is yet to explore. Emotion regulation difficulties (ERD) characterize several mental disorders. Motivated by that, we investigated the use of ERD for the detection of two opted mental disorders in this study. For this, we have collected audio-video data of human subjects while conversing with a computer agent based on a specific questionnaire. Subsequently, a subject's responses are collected to obtain the ground truths of the audio-video data of that subject. The results indicate that the ERD can be used as an intermediate representation of audio-video data for detecting mental disorders.
Significance of Data Augmentation for Improving Cleft Lip and Palate Speech Recognition
Oct 02, 2021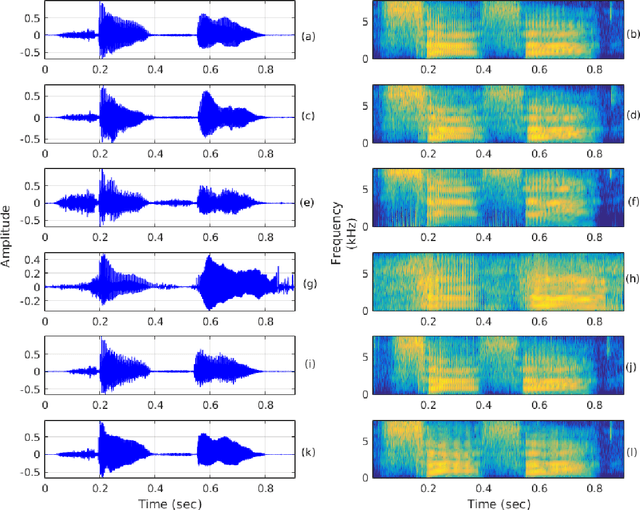
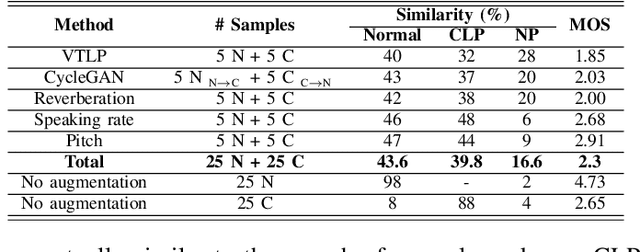
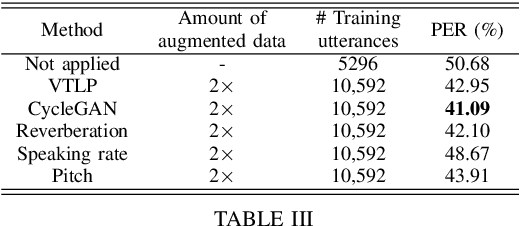
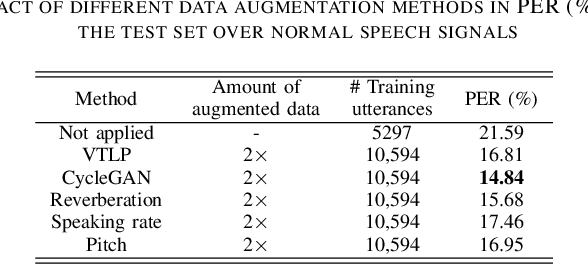
The automatic recognition of pathological speech, particularly from children with any articulatory impairment, is a challenging task due to various reasons. The lack of available domain specific data is one such obstacle that hinders its usage for different speech-based applications targeting pathological speakers. In line with the challenge, in this work, we investigate a few data augmentation techniques to simulate training data for improving the children speech recognition considering the case of cleft lip and palate (CLP) speech. The augmentation techniques explored in this study, include vocal tract length perturbation (VTLP), reverberation, speaking rate, pitch modification, and speech feature modification using cycle consistent adversarial networks (CycleGAN). Our study finds that the data augmentation methods significantly improve the CLP speech recognition performance, which is more evident when we used feature modification using CycleGAN, VTLP and reverberation based methods. More specifically, the results from this study show that our systems produce an improved phone error rate compared to the systems without data augmentation.
Processing Phoneme Specific Segments for Cleft Lip and Palate Speech Enhancement
Oct 02, 2021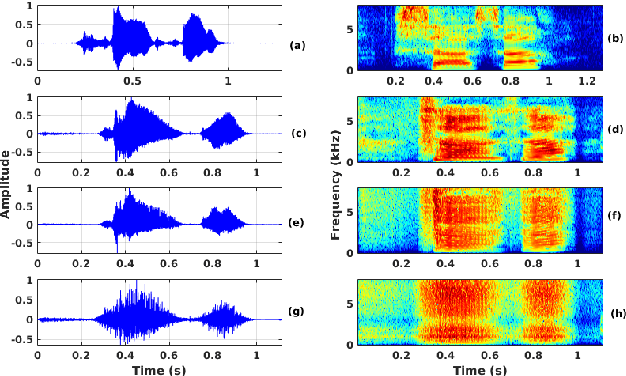
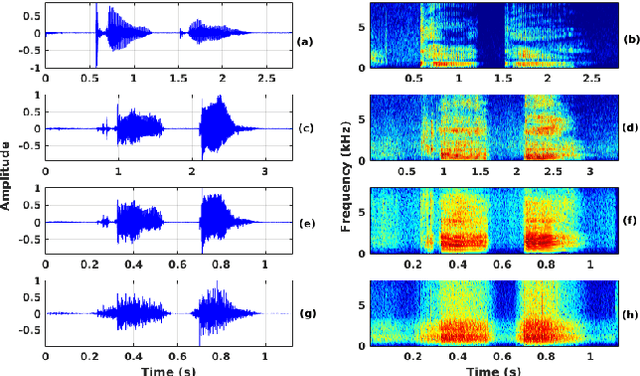
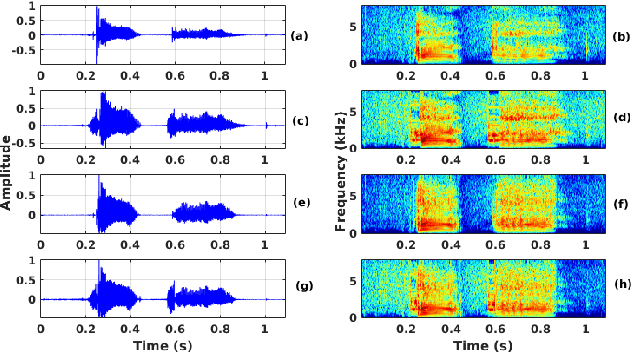
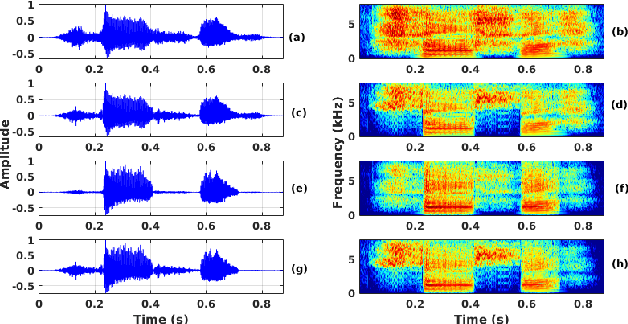
The cleft lip and palate (CLP) speech intelligibility is distorted due to the deformation in their articulatory system. For addressing the same, a few previous works perform phoneme specific modification in CLP speech. In CLP speech, both the articulation error and the nasalization distorts the intelligibility of a word. Consequently, modification of a specific phoneme may not always yield in enhanced entire word-level intelligibility. For such cases, it is important to identify and isolate the phoneme specific error based on the knowledge of acoustic events. Accordingly, the phoneme specific error modification algorithms can be exploited for transforming the specified errors and enhance the word-level intelligibility. Motivated by that, in this work, we combine some of salient phoneme specific enhancement approaches and demonstrate their effectiveness in improving the word-level intelligibility of CLP speech. The enhanced speech samples are evaluated using subjective and objective evaluation metrics.
Enhancing the Intelligibility of Cleft Lip and Palate Speech using Cycle-consistent Adversarial Networks
Jan 30, 2021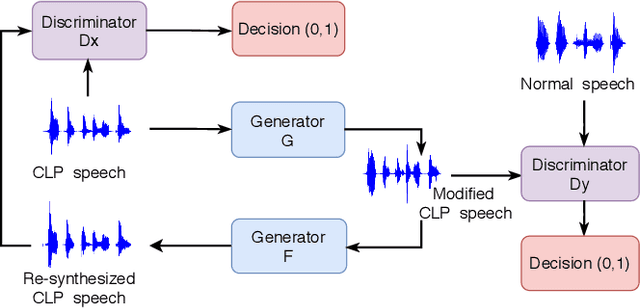
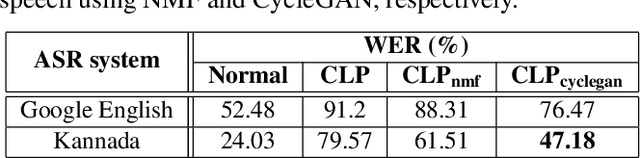
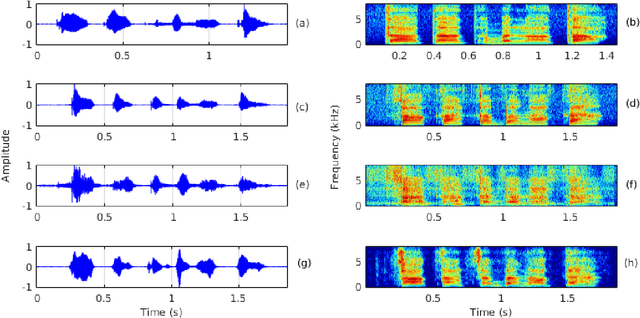
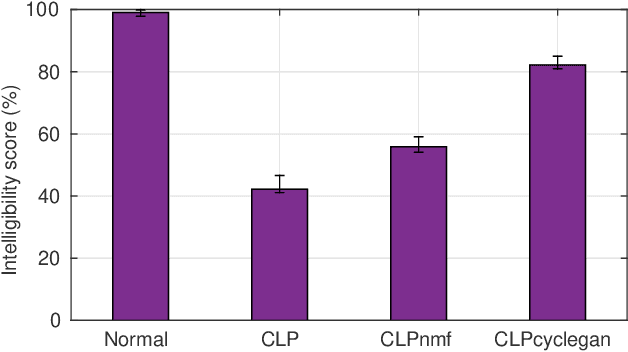
Cleft lip and palate (CLP) refer to a congenital craniofacial condition that causes various speech-related disorders. As a result of structural and functional deformities, the affected subjects' speech intelligibility is significantly degraded, limiting the accessibility and usability of speech-controlled devices. Towards addressing this problem, it is desirable to improve the CLP speech intelligibility. Moreover, it would be useful during speech therapy. In this study, the cycle-consistent adversarial network (CycleGAN) method is exploited for improving CLP speech intelligibility. The model is trained on native Kannada-speaking childrens' speech data. The effectiveness of the proposed approach is also measured using automatic speech recognition performance. Further, subjective evaluation is performed, and those results also confirm the intelligibility improvement in the enhanced speech over the original.
Investigating Target Set Reduction for End-to-End Speech Recognition of Hindi-English Code-Switching Data
Jul 15, 2019
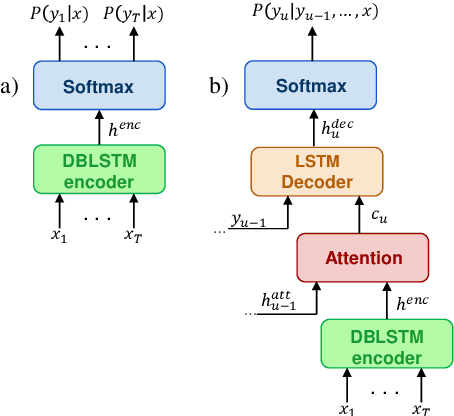

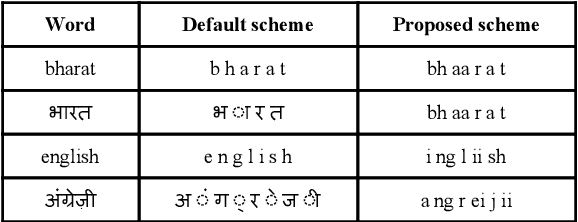
End-to-end (E2E) systems are fast replacing the conventional systems in the domain of automatic speech recognition. As the target labels are learned directly from speech data, the E2E systems need a bigger corpus for effective training. In the context of code-switching task, the E2E systems face two challenges: (i) the expansion of the target set due to multiple languages involved, and (ii) the lack of availability of sufficiently large domain-specific corpus. Towards addressing those challenges, we propose an approach for reducing the number of target labels for reliable training of the E2E systems on limited data. The efficacy of the proposed approach has been demonstrated on two prominent architectures, namely CTC-based and attention-based E2E networks. The experimental validations are performed on a recently created Hindi-English code-switching corpus. For contrast purpose, the results for the full target set based E2E system and a hybrid DNN-HMM system are also reported.