 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Robust Over-the-Air Adversarial Examples Against Automatic Speech Recognition Systems
Aug 05, 2019
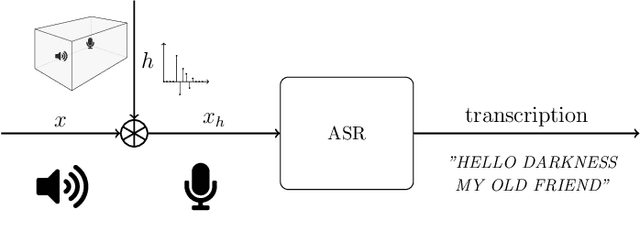
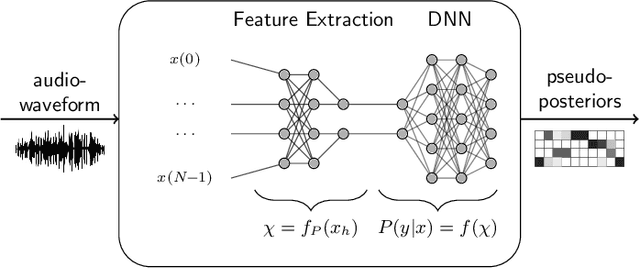
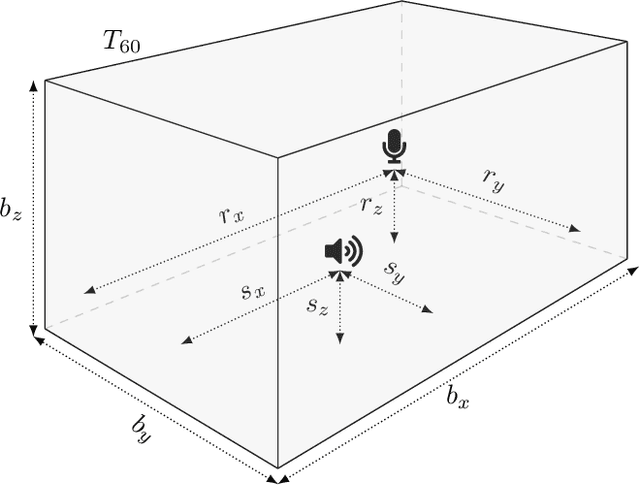
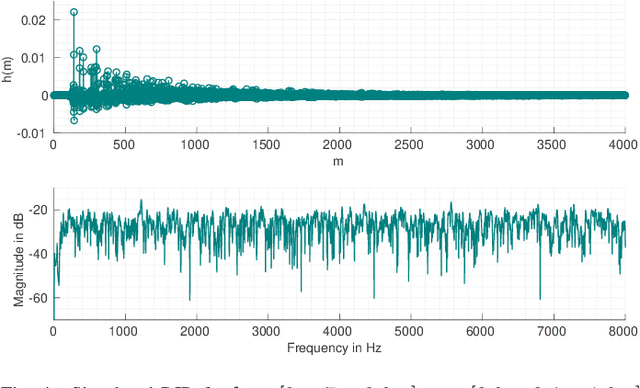
Automatic speech recognition (ASR) systems are possible to fool via targeted adversarial examples. These can induce the ASR to produce arbitrary transcriptions in response to any type of audio signal, be it speech, environmental sounds, or music. However, in general, those adversarial examples did not work in a real-world setup, where the examples are played over the air but have to be fed into the ASR system directly. In some cases, where the adversarial examples could be successfully played over the air, the attacks require precise information about the room where the attack takes place in order to tailor the adversarial examples to a specific setup and are not transferable to other rooms. Other attacks, which are robust in an over-the-air attack, are either handcrafted examples or human listeners can easily recognize the target transcription, once they have been alerted to its content. In this paper, we demonstrate the first generic algorithm that produces adversarial examples which remain robust in an over-the-air attack such that the ASR system transcribes the target transcription after actually being replayed. For the proposed algorithm, guessing a rough approximation of the room characteristics is enough and no actual access to the room is required. We use the ASR system Kaldi to demonstrate the attack and employ a room-impulse-response simulator to harden the adversarial examples against varying room characteristics. Further, the algorithm can also utilize psychoacoustics to hide changes of the original audio signal below the human thresholds of hearing. We show that the adversarial examples work for varying room setups, but also can be tailored to specific room setups. As a result, an attacker can optimize adversarial examples for any target transcription and to arbitrary rooms. Additionally, the adversarial examples remain transferable to varying rooms with a high probability.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022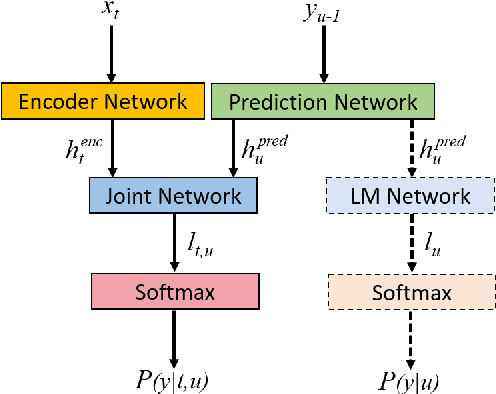
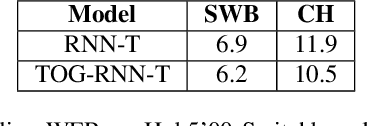
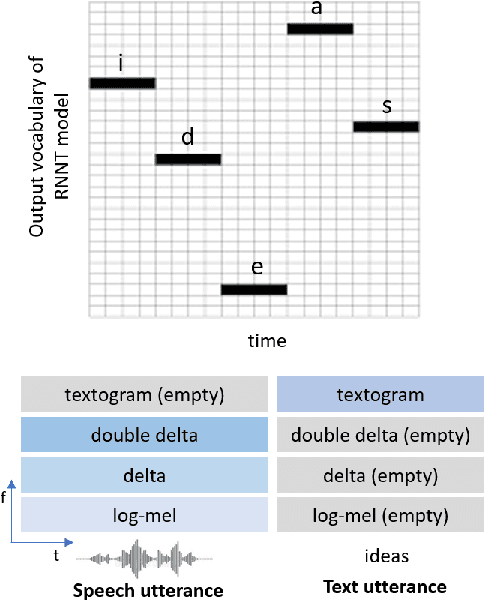
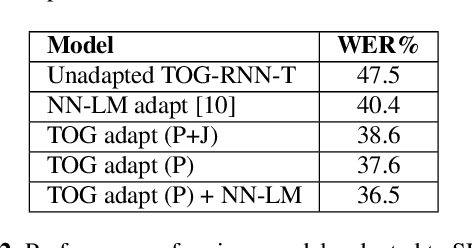
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
Pre-training on high-resource speech recognition improves low-resource speech-to-text translation
Sep 05, 2018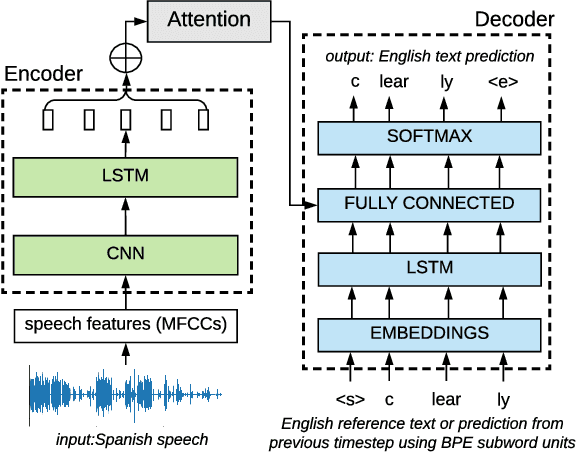

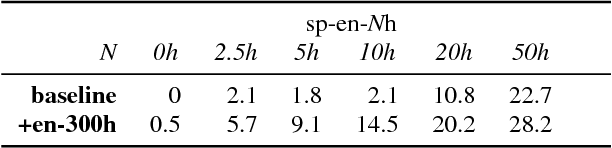
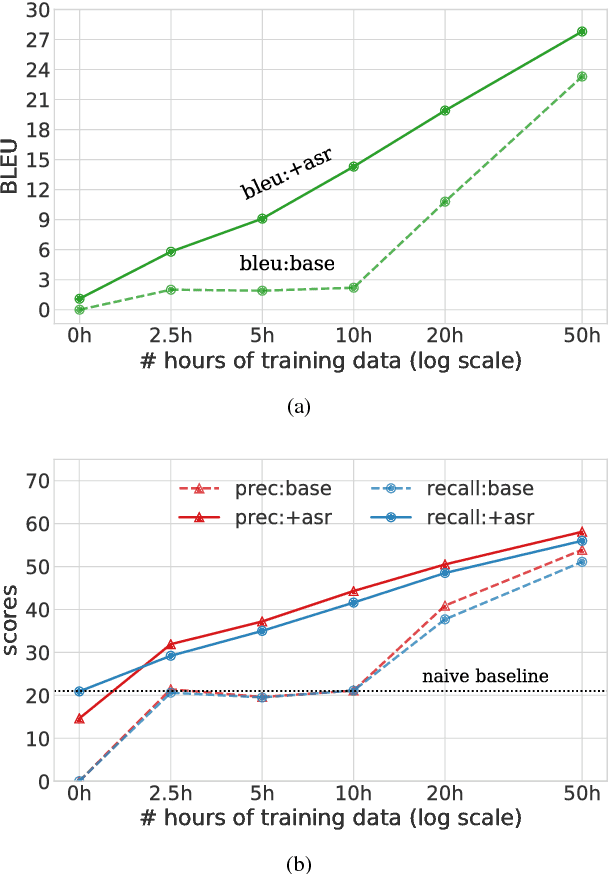
We present a simple approach to improve direct speech-to-text translation (ST) when the source language is low-resource: we pre-train the model on a high-resource automatic speech recognition (ASR) task, and then fine-tune its parameters for ST. We demonstrate that our approach is effective by pre-training on 300 hours of English ASR data to improve Spanish-English ST from 10.8 to 20.2 BLEU when only 20 hours of Spanish-English ST training data is available. Through an ablation study, we find that the pre-trained encoder (acoustic model) accounts for most of the improvement, which is surprising since the shared language in these tasks is the target language (text), and not the source language (audio). Applying this insight, we show that pre-training on ASR helps ST even when the ASR language differs from both source and target ST languages: pre-training on French ASR also improves Spanish-English ST. Finally, we show that the approach improves a true low-resource task: pre-training on a combination of English ASR and French ASR improves Mboshi-French ST, where only 4 hours of data are available, from 3.5 to 7.1 BLEU.
Improved low-resource Somali speech recognition by semi-supervised acoustic and language model training
Jul 06, 2019
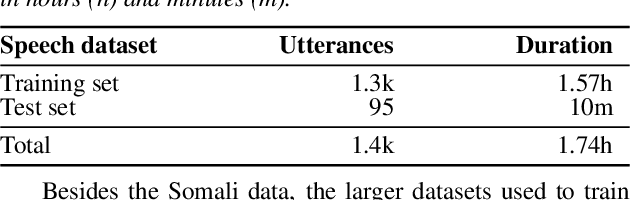
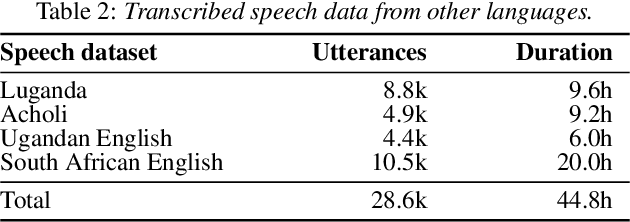
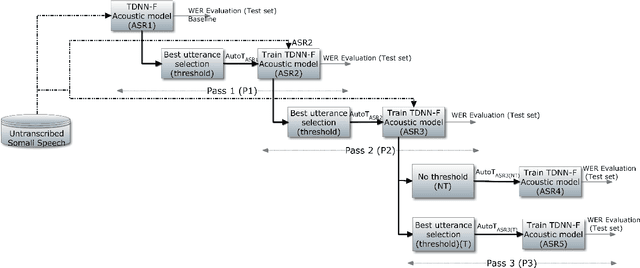
We present improvements in automatic speech recognition (ASR) for Somali, a currently extremely under-resourced language. This forms part of a continuing United Nations (UN) effort to employ ASR-based keyword spotting systems to support humanitarian relief programmes in rural Africa. Using just 1.57 hours of annotated speech data as a seed corpus, we increase the pool of training data by applying semi-supervised training to 17.55 hours of untranscribed speech. We make use of factorised time-delay neural networks (TDNN-F) for acoustic modelling, since these have recently been shown to be effective in resource-scarce situations. Three semi-supervised training passes were performed, where the decoded output from each pass was used for acoustic model training in the subsequent pass. The automatic transcriptions from the best performing pass were used for language model augmentation. To ensure the quality of automatic transcriptions, decoder confidence is used as a threshold. The acoustic and language models obtained from the semi-supervised approach show significant improvement in terms of WER and perplexity compared to the baseline. Incorporating the automatically generated transcriptions yields a 6.55\% improvement in language model perplexity. The use of 17.55 hour of Somali acoustic data in semi-supervised training shows an improvement of 7.74\% relative over the baseline.
Adversarial Black-Box Attacks for Automatic Speech Recognition Systems Using Multi-Objective Genetic Optimization
Nov 04, 2018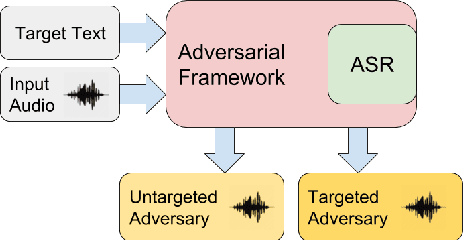

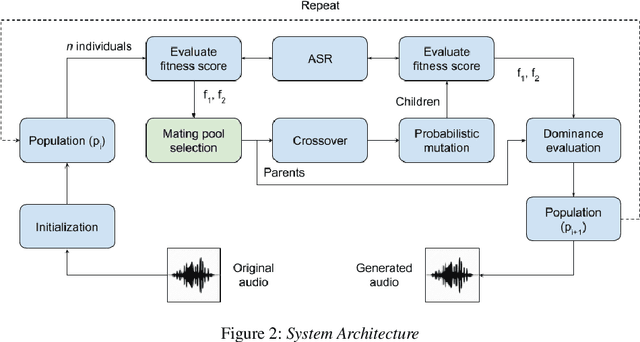
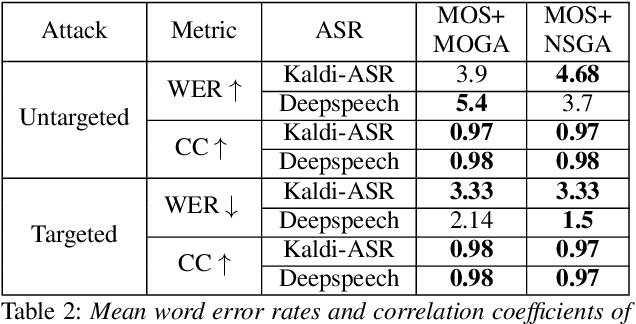
Fooling deep neural networks with adversarial input have exposed a significant vulnerability in current state-of-the-art systems in multiple domains. Both black-box and white-box approaches have been used to either replicate the model itself or to craft examples which cause the model to fail. In this work, we use a multi-objective genetic algorithm based approach to perform both targeted and un-targeted black-box attacks on automatic speech recognition (ASR) systems. The main contribution of this research is the proposal of a generic framework which can be used to attack any ASR system, even if it's internal working is hidden. During the un-targeted attacks, the Word Error Rates (WER) of the ASR degrades from 0.5 to 5.4, indicating the potency of our approach. In targeted attacks, our solution reaches a WER of 2.14. In both attacks, the adversarial samples maintain a high acoustic similarity of 0.98 and 0.97.
Improving Automatic Speech Recognition for Non-Native English with Transfer Learning and Language Model Decoding
Feb 10, 2022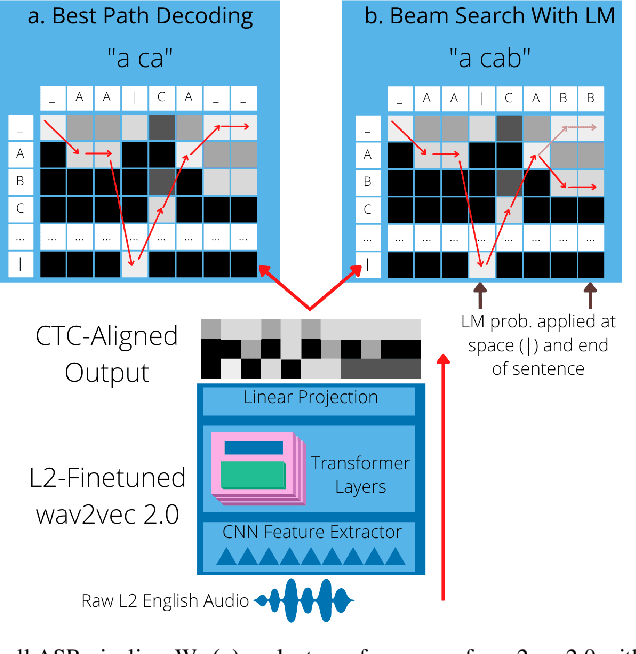

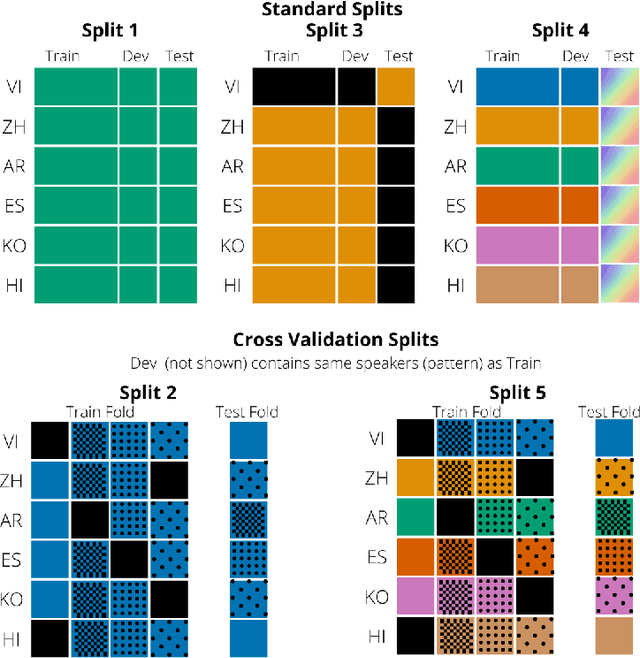
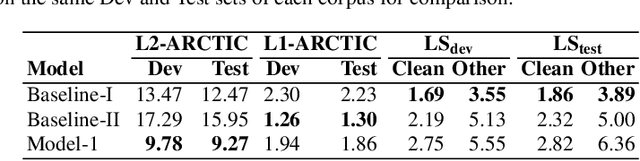
ASR systems designed for native English (L1) usually underperform on non-native English (L2). To address this performance gap, \textbf{(i)} we extend our previous work to investigate fine-tuning of a pre-trained wav2vec 2.0 model \cite{baevski2020wav2vec,xu2021self} under a rich set of L1 and L2 training conditions. We further \textbf{(ii)} incorporate language model decoding in the ASR system, along with the fine-tuning method. Quantifying gains acquired from each of these two approaches separately and an error analysis allows us to identify different sources of improvement within our models. We find that while the large self-trained wav2vec 2.0 may be internalizing sufficient decoding knowledge for clean L1 speech \cite{xu2021self}, this does not hold for L2 speech and accounts for the utility of employing language model decoding on L2 data.
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022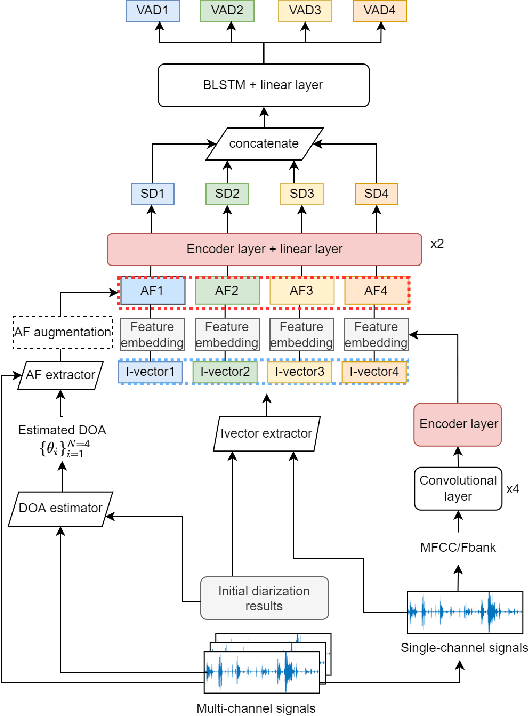
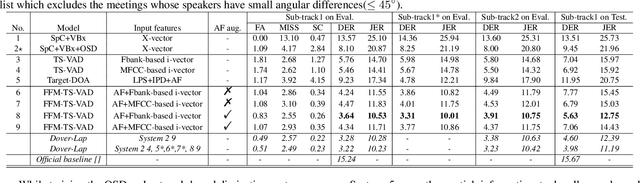
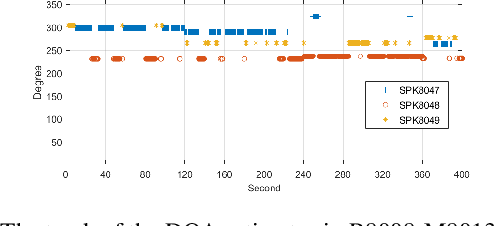
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
Quaternion Convolutional Neural Networks for End-to-End Automatic Speech Recognition
Jun 20, 2018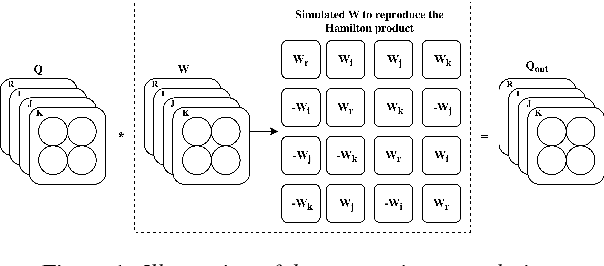
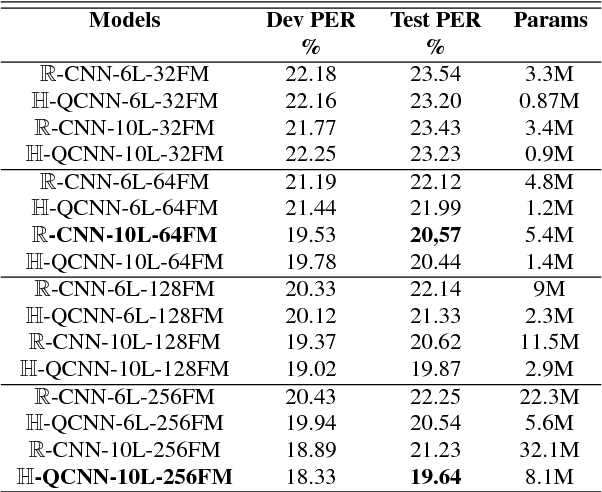
Recently, the connectionist temporal classification (CTC) model coupled with recurrent (RNN) or convolutional neural networks (CNN), made it easier to train speech recognition systems in an end-to-end fashion. However in real-valued models, time frame components such as mel-filter-bank energies and the cepstral coefficients obtained from them, together with their first and second order derivatives, are processed as individual elements, while a natural alternative is to process such components as composed entities. We propose to group such elements in the form of quaternions and to process these quaternions using the established quaternion algebra. Quaternion numbers and quaternion neural networks have shown their efficiency to process multidimensional inputs as entities, to encode internal dependencies, and to solve many tasks with less learning parameters than real-valued models. This paper proposes to integrate multiple feature views in quaternion-valued convolutional neural network (QCNN), to be used for sequence-to-sequence mapping with the CTC model. Promising results are reported using simple QCNNs in phoneme recognition experiments with the TIMIT corpus. More precisely, QCNNs obtain a lower phoneme error rate (PER) with less learning parameters than a competing model based on real-valued CNNs.
Twitter Dataset on the Russo-Ukrainian War
Apr 07, 2022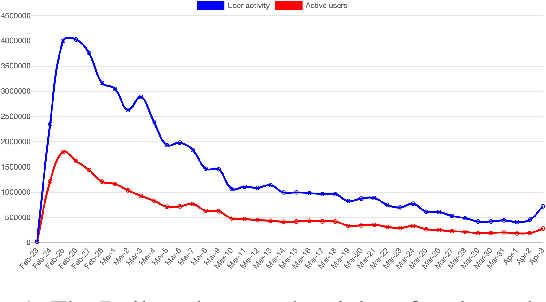
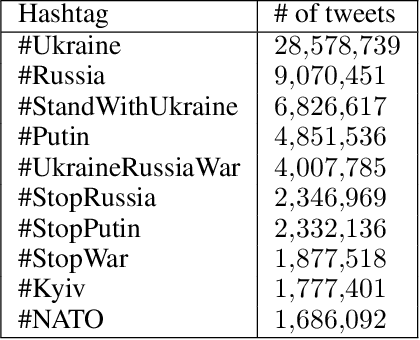
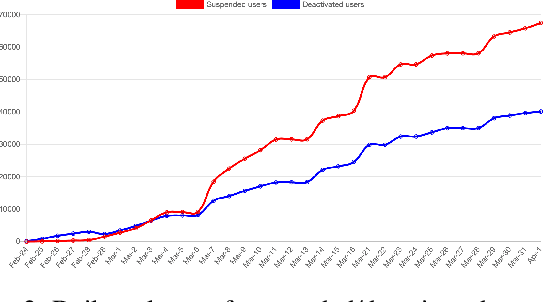
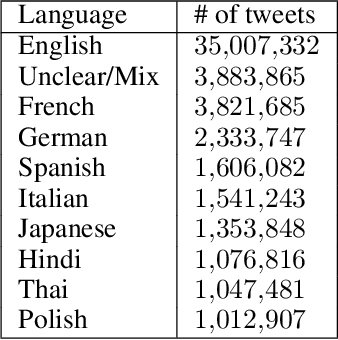
On 24 February 2022, Russia invaded Ukraine, also known now as Russo-Ukrainian War. We have initiated an ongoing dataset acquisition from Twitter API. Until the day this paper was written the dataset has reached the amount of 57.3 million tweets, originating from 7.7 million users. We apply an initial volume and sentiment analysis, while the dataset can be used to further exploratory investigation towards topic analysis, hate speech, propaganda recognition, or even show potential malicious entities like botnets.
A Multi-Task Learning Framework for Overcoming the Catastrophic Forgetting in Automatic Speech Recognition
Apr 17, 2019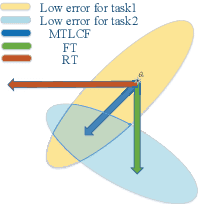
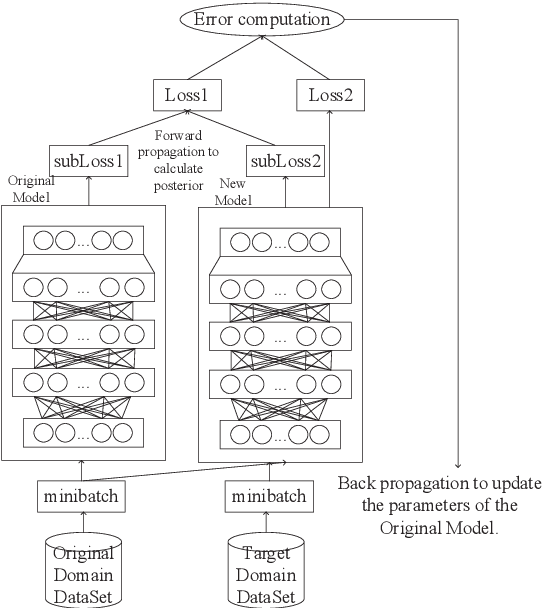
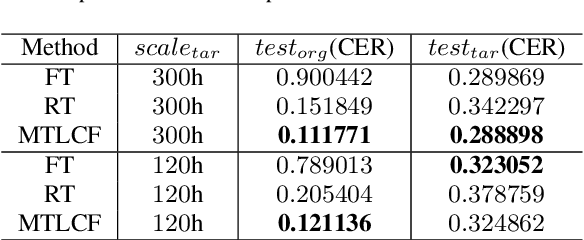
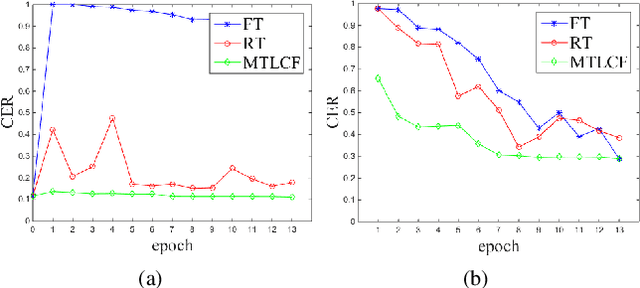
Recently, data-driven based Automatic Speech Recognition (ASR) systems have achieved state-of-the-art results. And transfer learning is often used when those existing systems are adapted to the target domain, e.g., fine-tuning, retraining. However, in the processes, the system parameters may well deviate too much from the previously learned parameters. Thus, it is difficult for the system training process to learn knowledge from target domains meanwhile not forgetting knowledge from the previous learning process, which is called as catastrophic forgetting (CF). In this paper, we attempt to solve the CF problem with the lifelong learning and propose a novel multi-task learning (MTL) training framework for ASR. It considers reserving original knowledge and learning new knowledge as two independent tasks, respectively. On the one hand, we constrain the new parameters not to deviate too far from the original parameters and punish the new system when forgetting original knowledge. On the other hand, we force the new system to solve new knowledge quickly. Then, a MTL mechanism is employed to get the balance between the two tasks. We applied our method to an End2End ASR task and obtained the best performance in both target and original datasets.