 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning
Jan 31, 2017
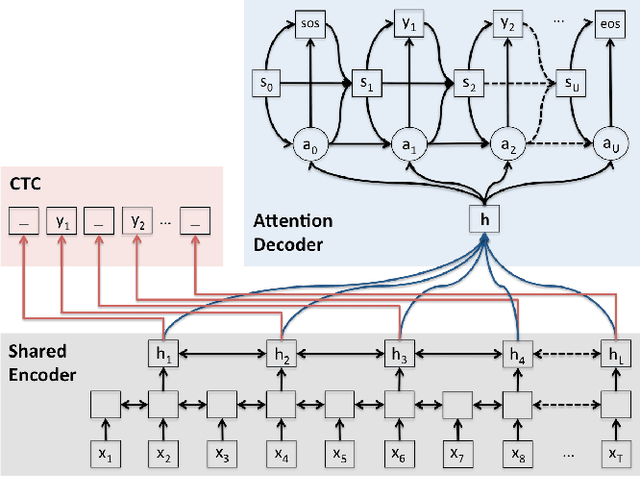
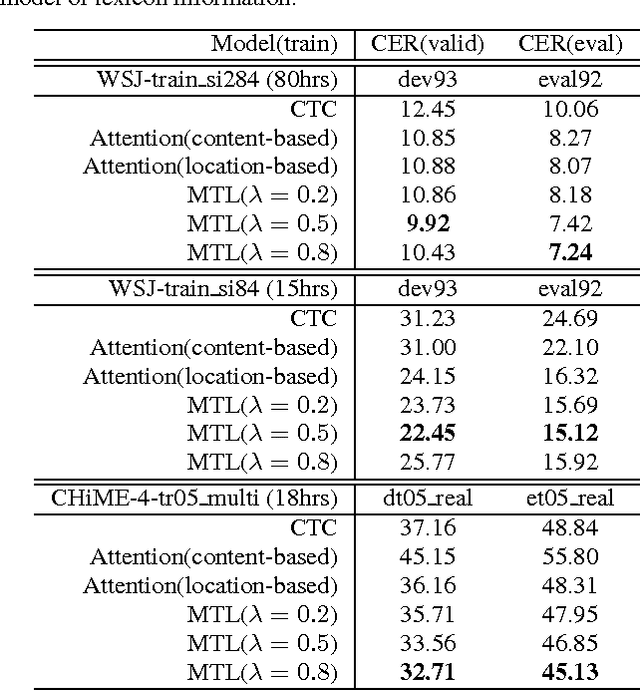
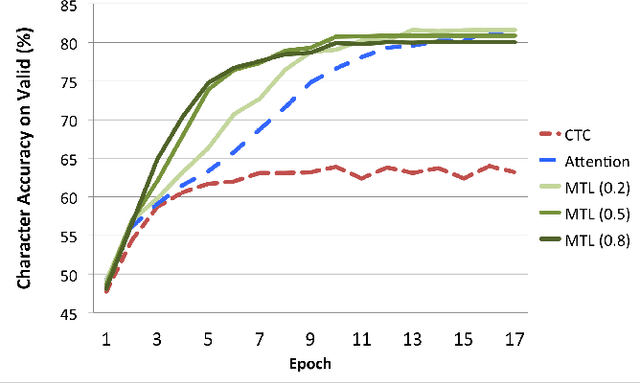
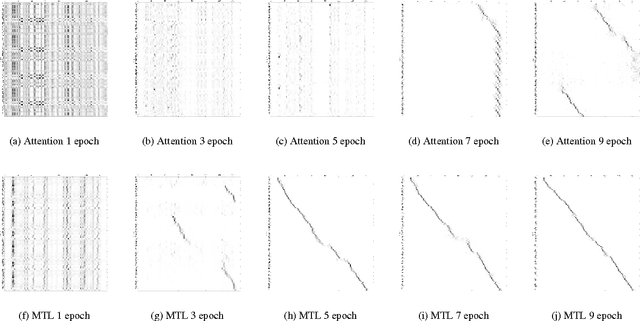
Recently, there has been an increasing interest in end-to-end speech recognition that directly transcribes speech to text without any predefined alignments. One approach is the attention-based encoder-decoder framework that learns a mapping between variable-length input and output sequences in one step using a purely data-driven method. The attention model has often been shown to improve the performance over another end-to-end approach, the Connectionist Temporal Classification (CTC), mainly because it explicitly uses the history of the target character without any conditional independence assumptions. However, we observed that the performance of the attention has shown poor results in noisy condition and is hard to learn in the initial training stage with long input sequences. This is because the attention model is too flexible to predict proper alignments in such cases due to the lack of left-to-right constraints as used in CTC. This paper presents a novel method for end-to-end speech recognition to improve robustness and achieve fast convergence by using a joint CTC-attention model within the multi-task learning framework, thereby mitigating the alignment issue. An experiment on the WSJ and CHiME-4 tasks demonstrates its advantages over both the CTC and attention-based encoder-decoder baselines, showing 5.4-14.6% relative improvements in Character Error Rate (CER).
Short-Term Word-Learning in a Dynamically Changing Environment
Mar 29, 2022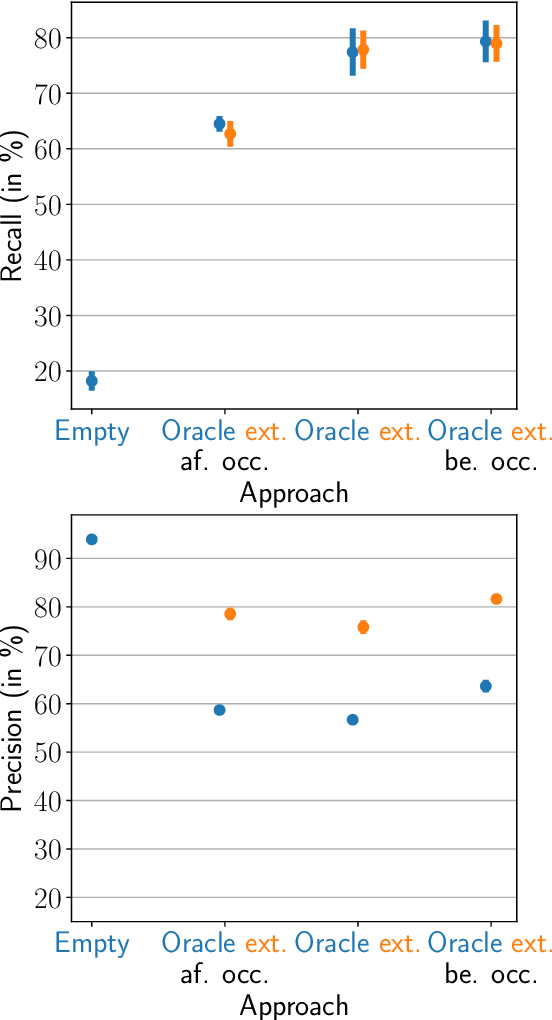
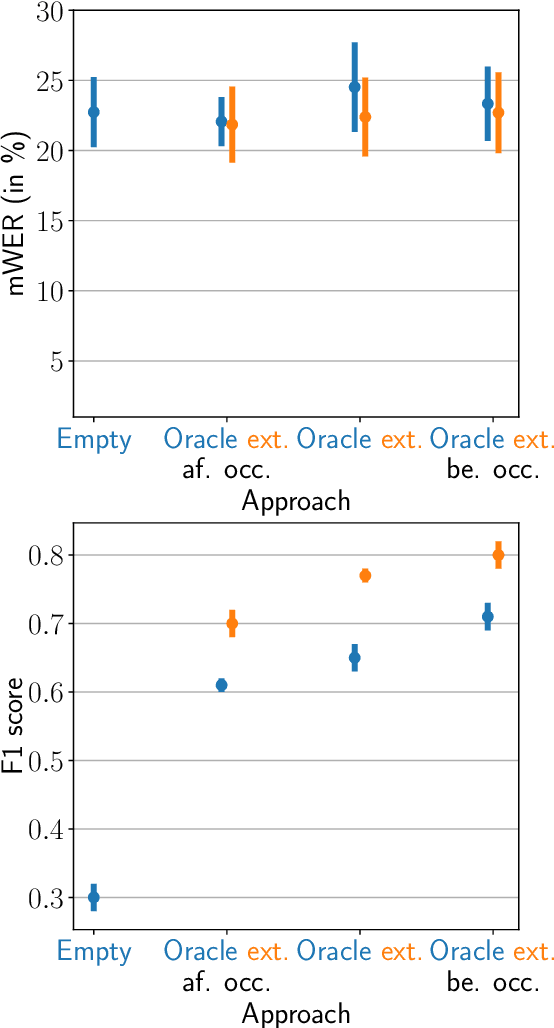
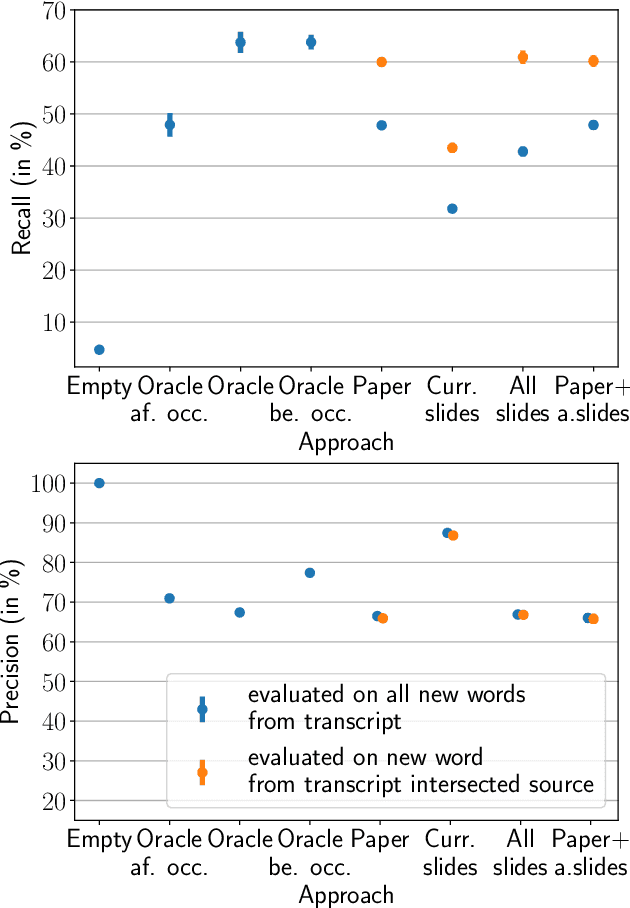
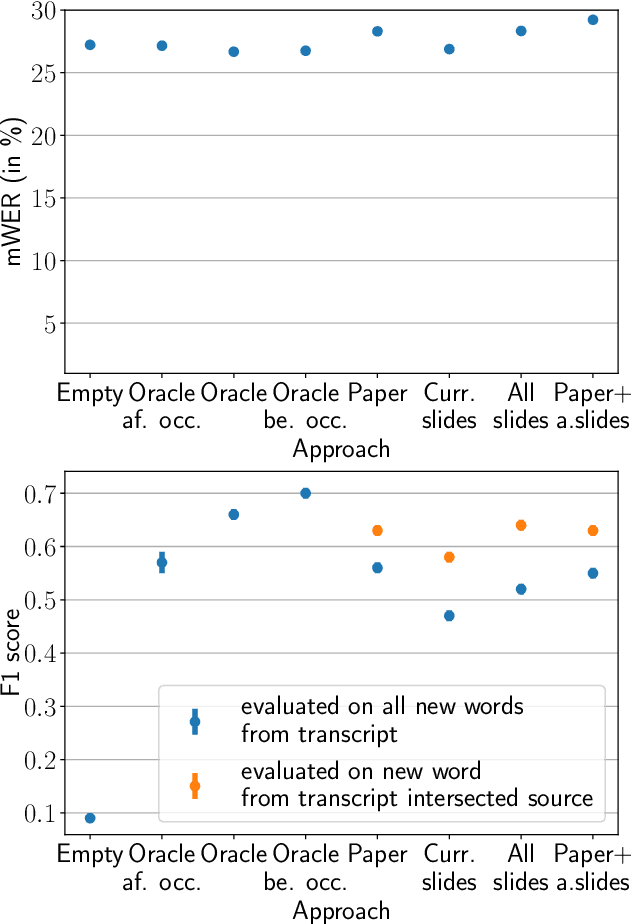
Neural sequence-to-sequence automatic speech recognition (ASR) systems are in principle open vocabulary systems, when using appropriate modeling units. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, numbers or technical terms. To alleviate this problem, Huber et al. proposed to supplement an end-to-end ASR system with a word/phrase memory and a mechanism to access this memory to recognize the words and phrases correctly. In this paper we study, a) methods to acquire important words for this memory dynamically and, b) the trade-off between improvement in recognition accuracy of new words and the potential danger of false alarms for those added words. We demonstrate significant improvements in the detection rate of new words with only a minor increase in false alarms (F1 score 0.30 $\rightarrow$ 0.80), when using an appropriate number of new words. In addition, we show that important keywords can be extracted from supporting documents and used effectively.
Improved training for online end-to-end speech recognition systems
Aug 30, 2018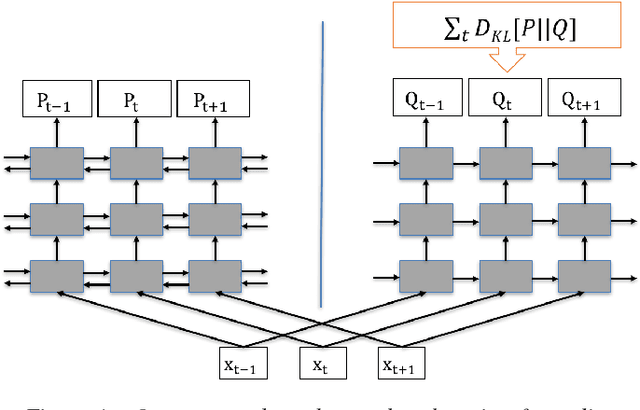
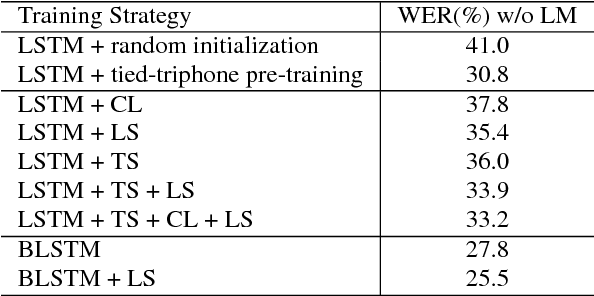
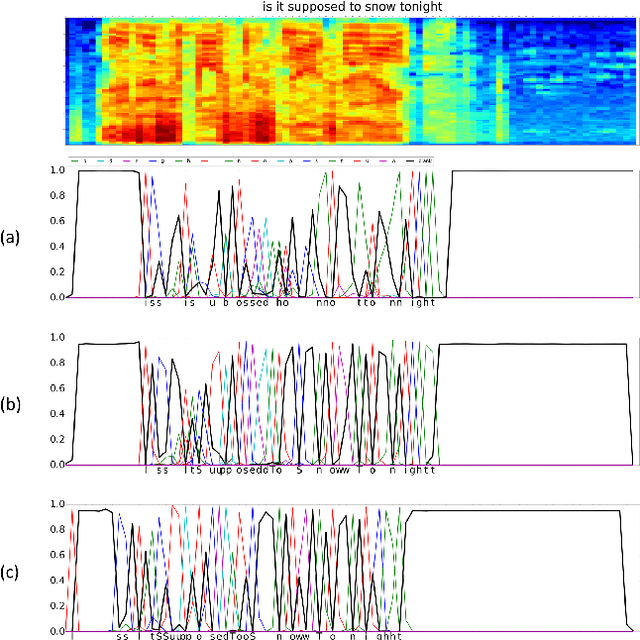
Achieving high accuracy with end-to-end speech recognizers requires careful parameter initialization prior to training. Otherwise, the networks may fail to find a good local optimum. This is particularly true for online networks, such as unidirectional LSTMs. Currently, the best strategy to train such systems is to bootstrap the training from a tied-triphone system. However, this is time consuming, and more importantly, is impossible for languages without a high-quality pronunciation lexicon. In this work, we propose an initialization strategy that uses teacher-student learning to transfer knowledge from a large, well-trained, offline end-to-end speech recognition model to an online end-to-end model, eliminating the need for a lexicon or any other linguistic resources. We also explore curriculum learning and label smoothing and show how they can be combined with the proposed teacher-student learning for further improvements. We evaluate our methods on a Microsoft Cortana personal assistant task and show that the proposed method results in a 19 % relative improvement in word error rate compared to a randomly-initialized baseline system.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
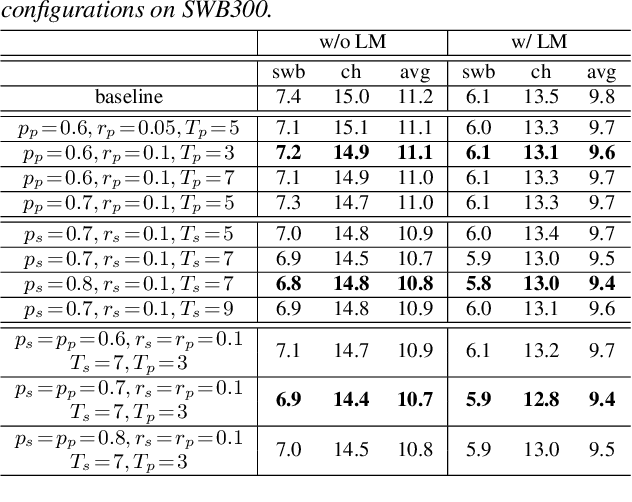

We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Pseudo Label Is Better Than Human Label
Mar 28, 2022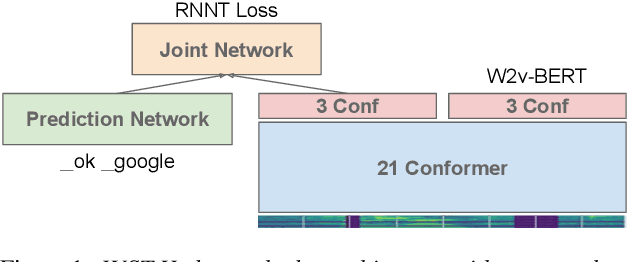

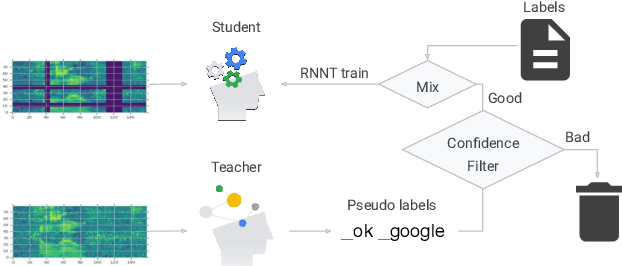
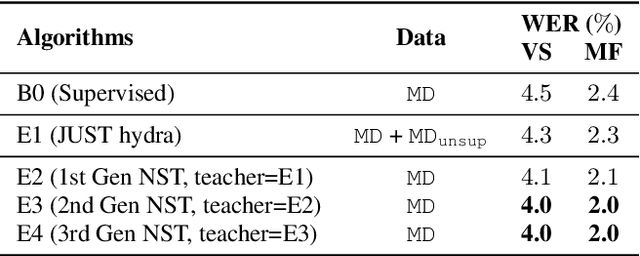
State-of-the-art automatic speech recognition (ASR) systems are trained with tens of thousands of hours of labeled speech data. Human transcription is expensive and time consuming. Factors such as the quality and consistency of the transcription can greatly affect the performance of the ASR models trained with these data. In this paper, we show that we can train a strong teacher model to produce high quality pseudo labels by utilizing recent self-supervised and semi-supervised learning techniques. Specifically, we use JUST (Joint Unsupervised/Supervised Training) and iterative noisy student teacher training to train a 600 million parameter bi-directional teacher model. This model achieved 4.0% word error rate (WER) on a voice search task, 11.1% relatively better than a baseline. We further show that by using this strong teacher model to generate high-quality pseudo labels for training, we can achieve 13.6% relative WER reduction (5.9% to 5.1%) for a streaming model compared to using human labels.
An Adaptive Psychoacoustic Model for Automatic Speech Recognition
Sep 14, 2016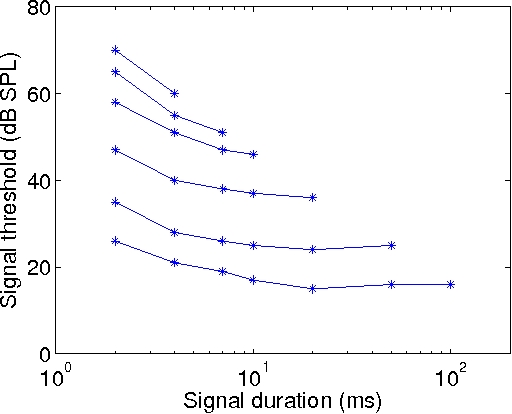
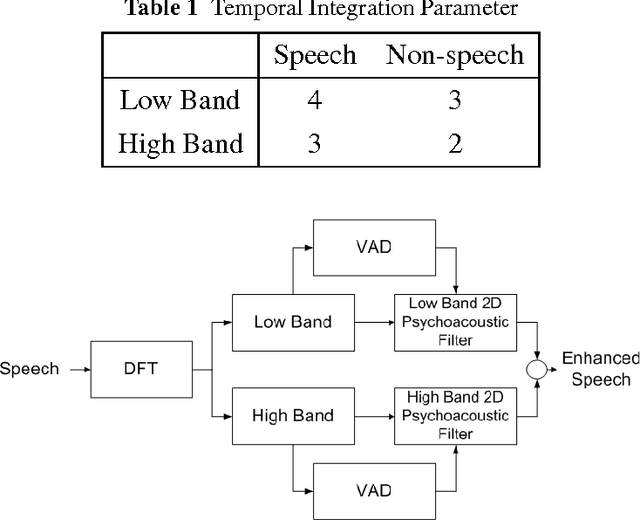
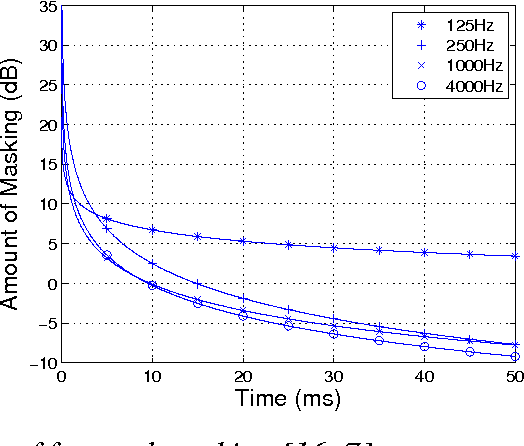
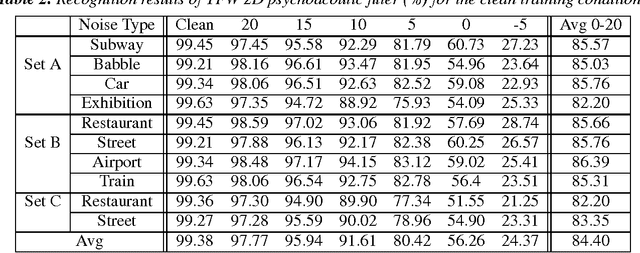
Compared with automatic speech recognition (ASR), the human auditory system is more adept at handling noise-adverse situations, including environmental noise and channel distortion. To mimic this adeptness, auditory models have been widely incorporated in ASR systems to improve their robustness. This paper proposes a novel auditory model which incorporates psychoacoustics and otoacoustic emissions (OAEs) into ASR. In particular, we successfully implement the frequency-dependent property of psychoacoustic models and effectively improve resulting system performance. We also present a novel double-transform spectrum-analysis technique, which can qualitatively predict ASR performance for different noise types. Detailed theoretical analysis is provided to show the effectiveness of the proposed algorithm. Experiments are carried out on the AURORA2 database and show that the word recognition rate using our proposed feature extraction method is significantly increased over the baseline. Given models trained with clean speech, our proposed method achieves up to 85.39% word recognition accuracy on noisy data.
Improved Consistency Training for Semi-Supervised Sequence-to-Sequence ASR via Speech Chain Reconstruction and Self-Transcribing
May 14, 2022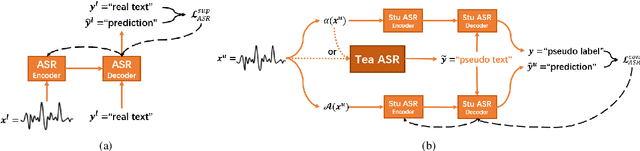
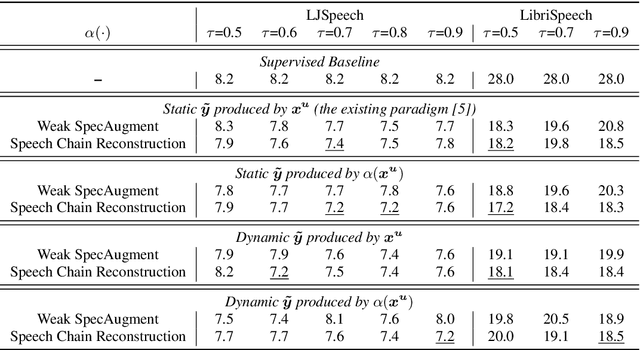
Consistency regularization has recently been applied to semi-supervised sequence-to-sequence (S2S) automatic speech recognition (ASR). This principle encourages an ASR model to output similar predictions for the same input speech with different perturbations. The existing paradigm of semi-supervised S2S ASR utilizes SpecAugment as data augmentation and requires a static teacher model to produce pseudo transcripts for untranscribed speech. However, this paradigm fails to take full advantage of consistency regularization. First, the masking operations of SpecAugment may damage the linguistic contents of the speech, thus influencing the quality of pseudo labels. Second, S2S ASR requires both input speech and prefix tokens to make the next prediction. The static prefix tokens made by the offline teacher model cannot match dynamic pseudo labels during consistency training. In this work, we propose an improved consistency training paradigm of semi-supervised S2S ASR. We utilize speech chain reconstruction as the weak augmentation to generate high-quality pseudo labels. Moreover, we demonstrate that dynamic pseudo transcripts produced by the student ASR model benefit the consistency training. Experiments on LJSpeech and LibriSpeech corpora show that compared to supervised baselines, our improved paradigm achieves a 12.2% CER improvement in the single-speaker setting and 38.6% in the multi-speaker setting.
Cascaded CNN-resBiLSTM-CTC: An End-to-End Acoustic Model For Speech Recognition
Oct 30, 2018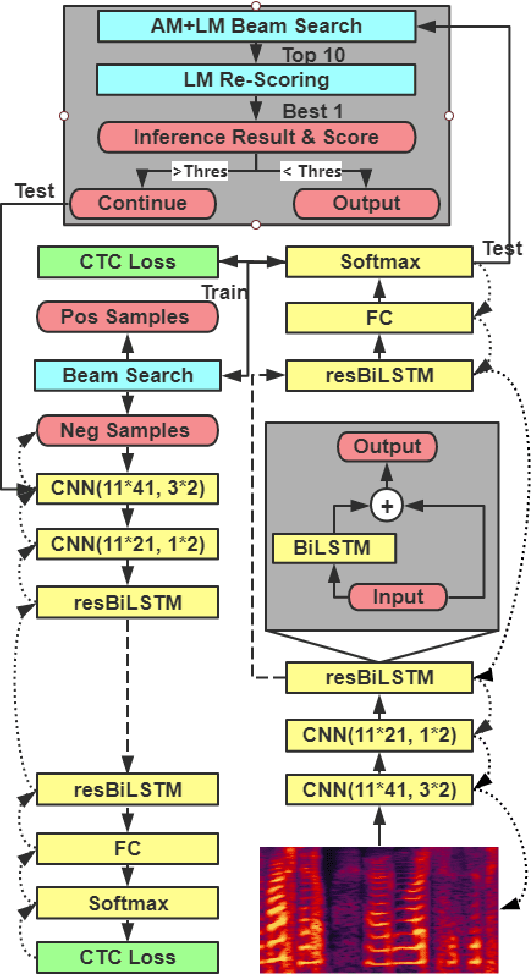
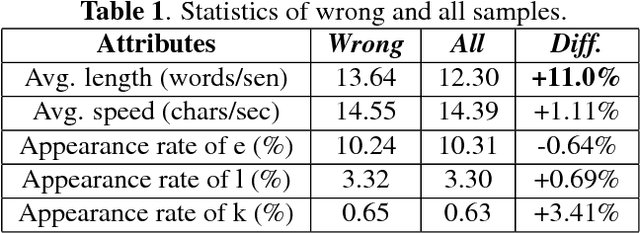
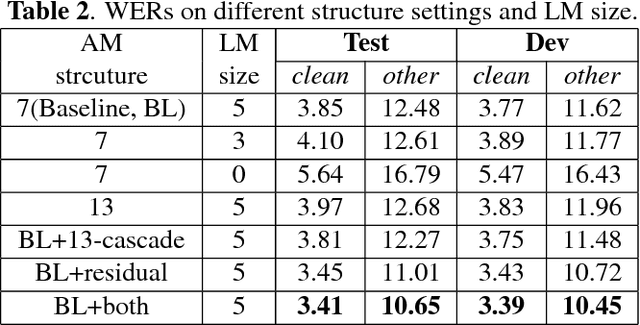
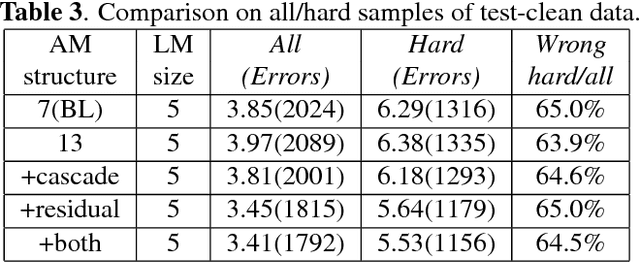
Automatic speech recognition (ASR) tasks are resolved by end-to-end deep learning models, which benefits us by less preparation of raw data, and easier transformation between languages. We propose a novel end-to-end deep learning model architecture namely cascaded CNN-resBiLSTM-CTC. In the proposed model, we add residual blocks in BiLSTM layers to extract sophisticated phoneme and semantic information together, and apply cascaded structure to pay more attention mining information of hard negative samples. By applying both simple Fast Fourier Transform (FFT) technique and n-gram language model (LM) rescoring method, we manage to achieve word error rate (WER) of 3.41% on LibriSpeech test clean corpora. Furthermore, we propose a new batch-varied method to speed up the training process in length-varied tasks, which result in 25% less training time.
Graph based manifold regularized deep neural networks for automatic speech recognition
Jun 19, 2016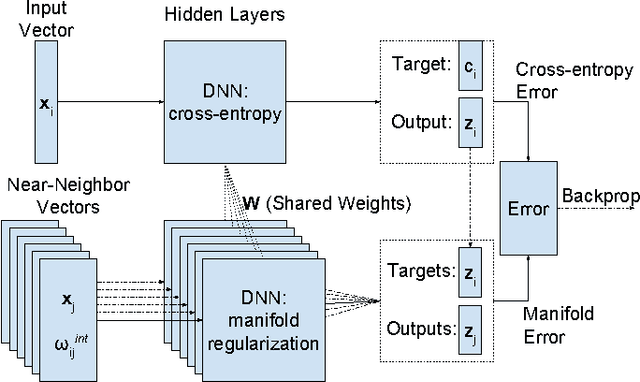
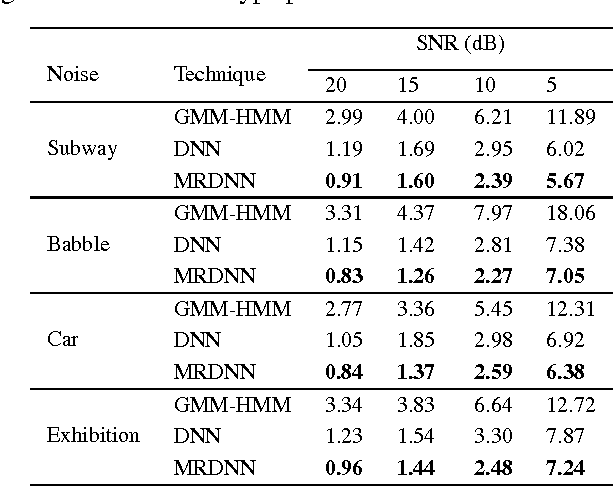
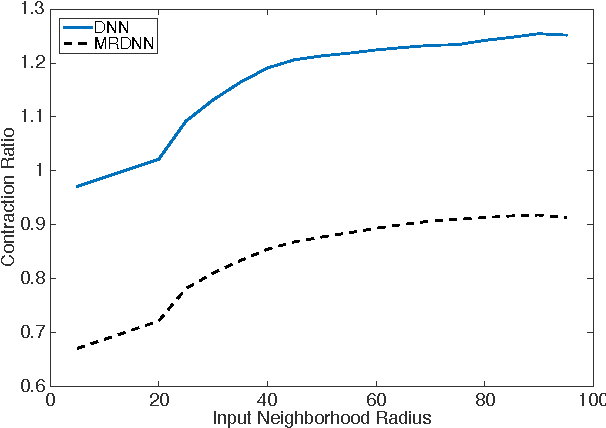
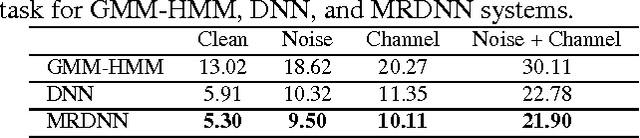
Deep neural networks (DNNs) have been successfully applied to a wide variety of acoustic modeling tasks in recent years. These include the applications of DNNs either in a discriminative feature extraction or in a hybrid acoustic modeling scenario. Despite the rapid progress in this area, a number of challenges remain in training DNNs. This paper presents an effective way of training DNNs using a manifold learning based regularization framework. In this framework, the parameters of the network are optimized to preserve underlying manifold based relationships between speech feature vectors while minimizing a measure of loss between network outputs and targets. This is achieved by incorporating manifold based locality constraints in the objective criterion of DNNs. Empirical evidence is provided to demonstrate that training a network with manifold constraints preserves structural compactness in the hidden layers of the network. Manifold regularization is applied to train bottleneck DNNs for feature extraction in hidden Markov model (HMM) based speech recognition. The experiments in this work are conducted on the Aurora-2 spoken digits and the Aurora-4 read news large vocabulary continuous speech recognition tasks. The performance is measured in terms of word error rate (WER) on these tasks. It is shown that the manifold regularized DNNs result in up to 37% reduction in WER relative to standard DNNs.
A Bayesian Network View on Acoustic Model-Based Techniques for Robust Speech Recognition
Sep 22, 2014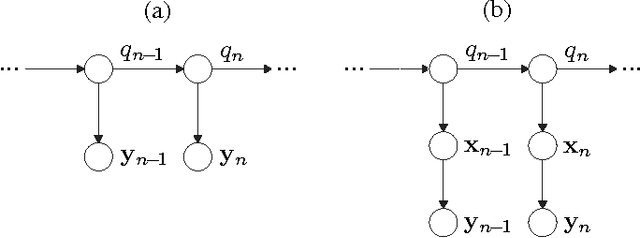
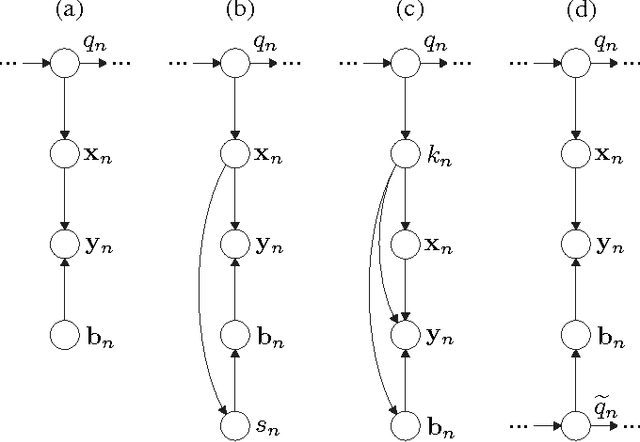
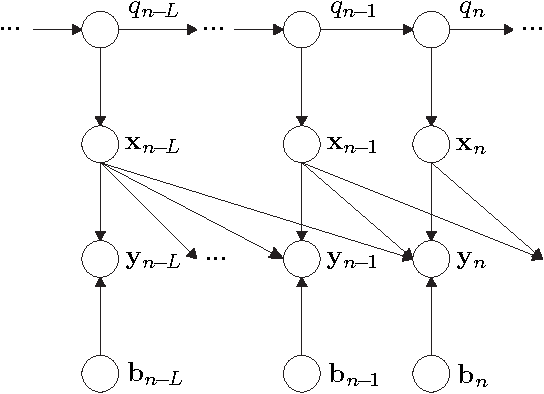
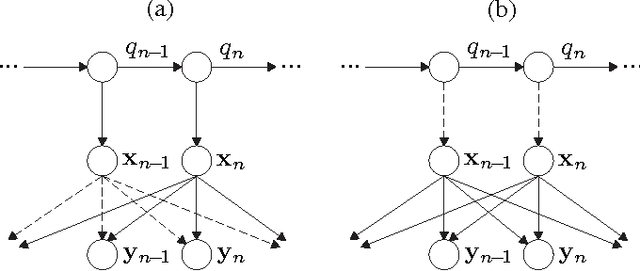
This article provides a unifying Bayesian network view on various approaches for acoustic model adaptation, missing feature, and uncertainty decoding that are well-known in the literature of robust automatic speech recognition. The representatives of these classes can often be deduced from a Bayesian network that extends the conventional hidden Markov models used in speech recognition. These extensions, in turn, can in many cases be motivated from an underlying observation model that relates clean and distorted feature vectors. By converting the observation models into a Bayesian network representation, we formulate the corresponding compensation rules leading to a unified view on known derivations as well as to new formulations for certain approaches. The generic Bayesian perspective provided in this contribution thus highlights structural differences and similarities between the analyzed approaches.